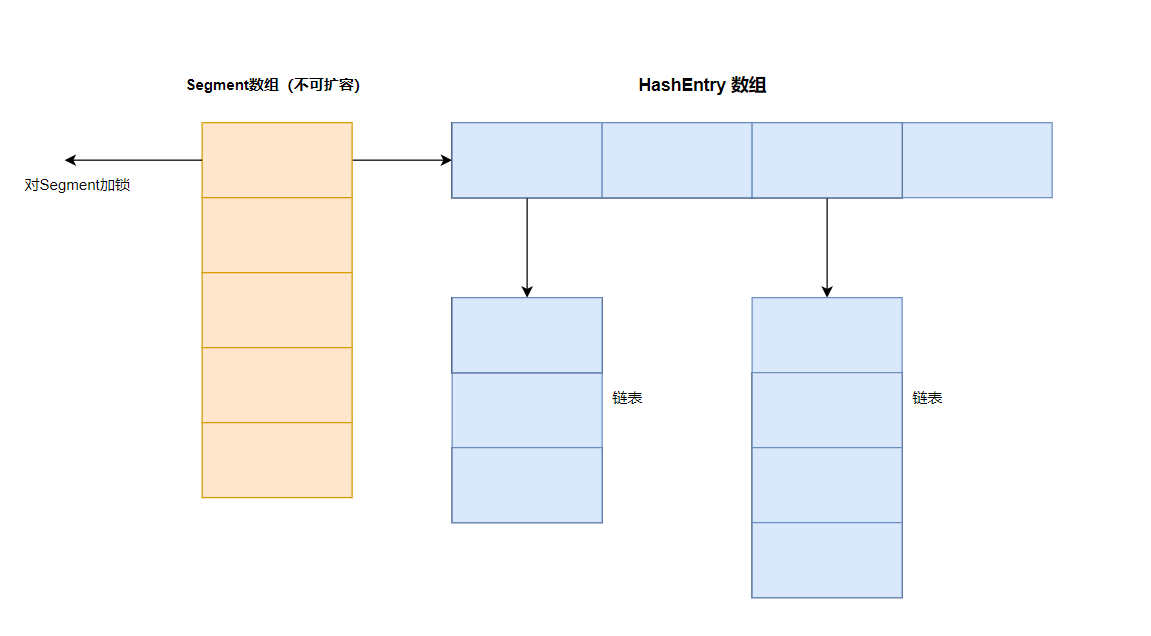
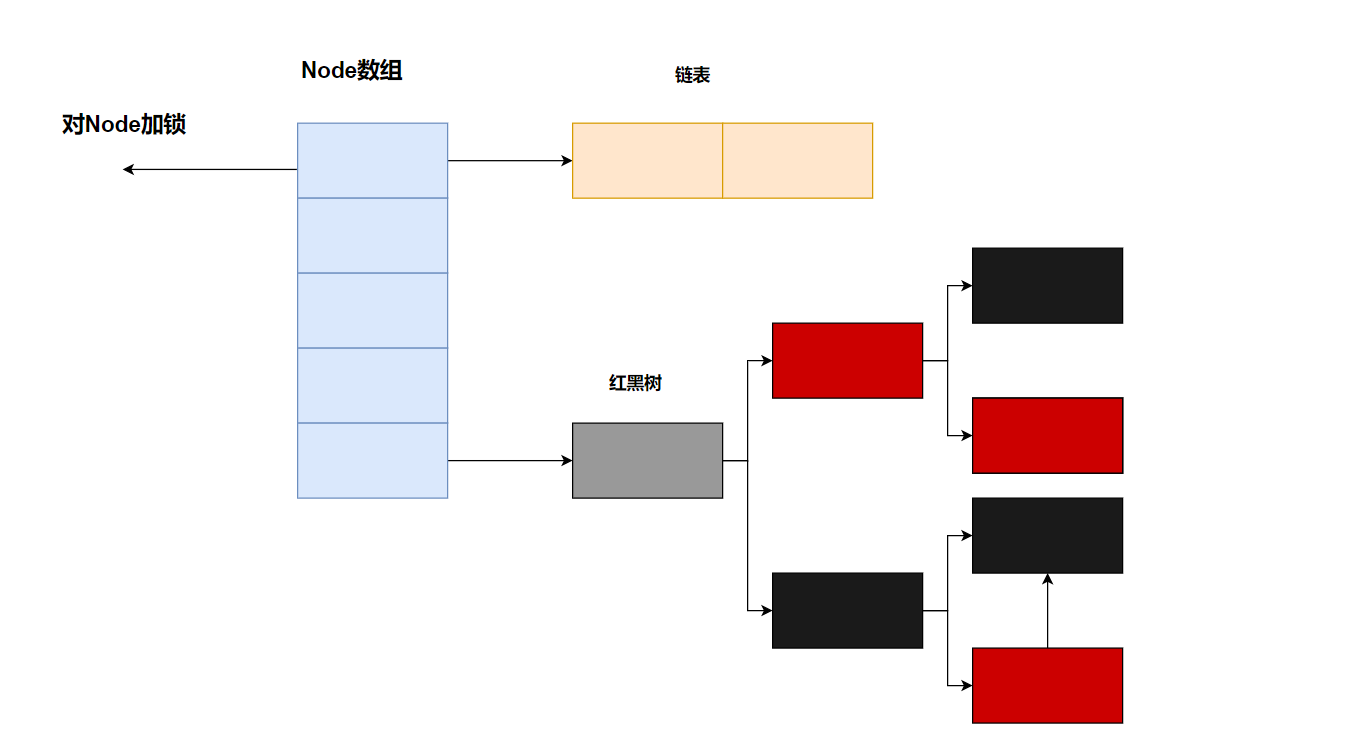
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
| /**
* Moves and/or copies the nodes in each bin to new table. See
* above for explanation.
* 把数组中的节点复制到新的数组的相同位置,或者移动到扩张部分的相同位置
* 在这里首先会计算一个步长,表示一个线程处理的数组长度,用来控制对CPU的使用,
* 每个CPU最少处理16个长度的数组元素,也就是说,如果一个数组的长度只有16,那只有一个线程会对其进行扩容的复制移动操作
* 扩容的时候会一直遍历,知道复制完所有节点,没处理一个节点的时候会在链表的头部设置一个fwd节点,这样其他线程就会跳过他,
* 复制后在新数组中的链表不是绝对的反序的
*/
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE) //MIN_TRANSFER_STRIDE 用来控制不要占用太多CPU
stride = MIN_TRANSFER_STRIDE; // subdivide range //MIN_TRANSFER_STRIDE=16
/*
* 如果复制的目标nextTab为null的话,则初始化一个table两倍长的nextTab
* 此时nextTable被设置值了(在初始情况下是为null的)
* 因为如果有一个线程开始了表的扩张的时候,其他线程也会进来帮忙扩张,
* 而只是第一个开始扩张的线程需要初始化下目标数组
*/
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n;
}
int nextn = nextTab.length;
/*
* 创建一个fwd节点,这个是用来控制并发的,当一个节点为空或已经被转移之后,就设置为fwd节点
* 这是一个空的标志节点
*/
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
boolean advance = true; //是否继续向前查找的标志位
boolean finishing = false; // to ensure sweep(清扫) before committing nextTab,在完成之前重新在扫描一遍数组,看看有没完成的没
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing) {
advance = false;
}
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) { //已经完成转移
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1); //设置sizeCtl为扩容后的0.75
return;
}
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT) {
return;
}
finishing = advance = true;
i = n; // recheck before commit
}
}
else if ((f = tabAt(tab, i)) == null) //数组中把null的元素设置为ForwardingNode节点(hash值为MOVED[-1])
advance = casTabAt(tab, i, null, fwd);
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
synchronized (f) { //加锁操作
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
if (fh >= 0) { //该节点的hash值大于等于0,说明是一个Node节点
/*
* 因为n的值为数组的长度,且是power(2,x)的,所以,在&操作的结果只可能是0或者n
* 根据这个规则
* 0--> 放在新表的相同位置
* n--> 放在新表的(n+原来位置)
*/
int runBit = fh & n;
Node<K,V> lastRun = f;
/*
* lastRun 表示的是需要复制的最后一个节点
* 每当新节点的hash&n -> b 发生变化的时候,就把runBit设置为这个结果b
* 这样for循环之后,runBit的值就是最后不变的hash&n的值
* 而lastRun的值就是最后一次导致hash&n 发生变化的节点(假设为p节点)
* 为什么要这么做呢?因为p节点后面的节点的hash&n 值跟p节点是一样的,
* 所以在复制到新的table的时候,它肯定还是跟p节点在同一个位置
* 在复制完p节点之后,p节点的next节点还是指向它原来的节点,就不需要进行复制了,自己就被带过去了
* 这也就导致了一个问题就是复制后的链表的顺序并不一定是原来的倒序
*/
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n; //n的值为扩张前的数组的长度
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
/*
* 构造两个链表,顺序大部分和原来是反的
* 分别放到原来的位置和新增加的长度的相同位置(i/n+i)
*/
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
/*
* 假设runBit的值为0,
* 则第一次进入这个设置的时候相当于把旧的序列的最后一次发生hash变化的节点(该节点后面可能还有hash计算后同为0的节点)设置到旧的table的第一个hash计算后为0的节点下一个节点
* 并且把自己返回,然后在下次进来的时候把它自己设置为后面节点的下一个节点
*/
ln = new Node<K,V>(ph, pk, pv, ln);
else
/*
* 假设runBit的值不为0,
* 则第一次进入这个设置的时候相当于把旧的序列的最后一次发生hash变化的节点(该节点后面可能还有hash计算后同不为0的节点)设置到旧的table的第一个hash计算后不为0的节点下一个节点
* 并且把自己返回,然后在下次进来的时候把它自己设置为后面节点的下一个节点
*/
hn = new Node<K,V>(ph, pk, pv, hn);
}
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
else if (f instanceof TreeBin) { //否则的话是一个树节点
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
/*
* 在复制完树节点之后,判断该节点处构成的树还有几个节点,
* 如果≤6个的话,就转回为一个链表
*/
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}
|