
1. 介绍
make stream processing easier~
一个神奇的框架,让流处理更简单
1.1 概念
实时即未来,在实时处理流域 Apache Spark 和 Apache Flink 是一个伟大的进步,尤其是 Apache Flink 被普遍认为是下一代大数据流计算引擎, 我们在使用 Flink & Spark 时发现从编程模型, 启动配置到运维管理都有很多可以抽象共用的地方, 我们将一些好的经验固化下来并结合业内的最佳实践, 通过不断努力诞生了今天的框架 —— StreamPark, 项目的初衷是 —— 让流处理更简单, 使用 StreamPark 开发流处理作业, 可以极大降低学习成本和开发门槛, 让开发者只用关心最核心的业务,StreamPark 规范了项目的配置,鼓励函数式编程,定义了最佳的编程方式,提供了一系列开箱即用的Connectors,标准化了配置、开发、测试、部署、监控、运维的整个过程, 提供了scala和java两套 Api, 并且提供了一个一站式的流处理作业开发管理平台, 从流处理作业开发到上线全生命周期都 做了支持, 是一个一站式的流处理计算平台.
1.2 特性
- Apache Flink & Apache Spark 应用程序开发脚手架
- 支持多个版本的 Flink & Spark
- 一系列开箱即用的connectors
- 一站式流处理运营平台
- 支持catalog、olap、streaming-warehouse等
- …
1.3 组成部分
Apache StreamPark 核心由streampark-core 和 streampark-console 组成
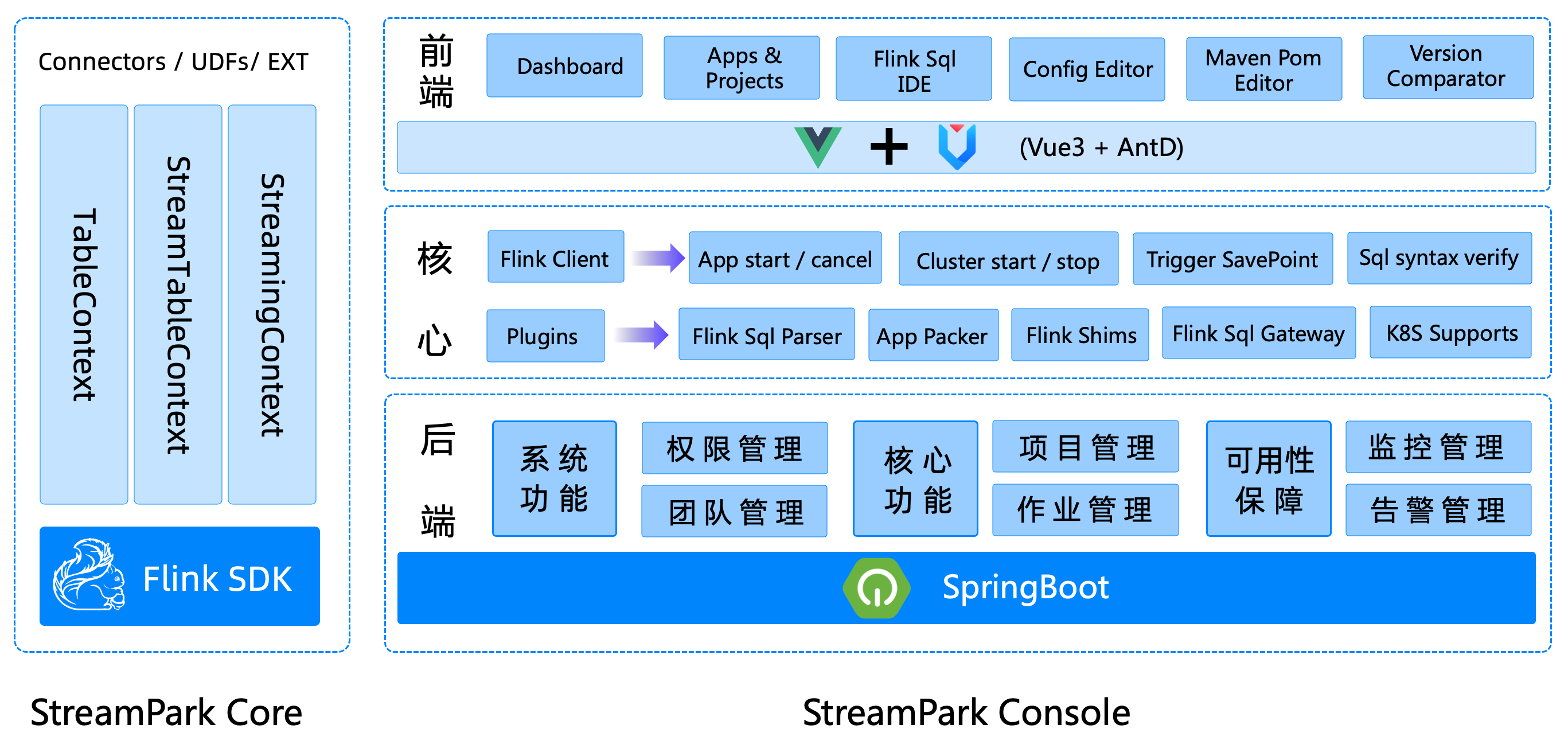
- streampark-core
streampark-core 定位是一个开发时框架,关注编码开发,规范了配置文件,按照约定优于配置的方式进行开发,提供了一个开发时 RunTime Content和一系列开箱即用的Connector,扩展了DataStream相关的方法,融合了DataStream和Flink sql api,简化繁琐的操作,聚焦业务本身,提高开发效率和开发体验
- streampark-console
streampark-console 是一个综合实时数据平台,低代码(Low Code)平台,可以较好的管理Flink任务,集成了项目编译、发布、参数配置、启动、savepoint,火焰图(flame graph),Flink SQL, 监控等诸多功能于一体, 大大简化了 Flink 任务的日常操作和维护,融合了诸多最佳实践。旧时王谢堂前燕,飞入寻常百姓家,让大公司有能力研发使用的项目,现在人人可以使用, 其最终目标是打造成一个实时数仓,流批一体的一站式大数据解决方案,该平台使用但不仅限以下技术:
- Apache Flink
- Apache Spark
- Apache YARN
- Spring Boot
- Mybatis
- Mybatis-Plus
- Vue
- VuePress
- Ant Design of Vue
- ANTD PRO VUE
- xterm.js
- Monaco Editor
- …
2. 安装(物理机部署-不配置数据源)
2.1 目前软硬件环境
linux的版本:3.10.0-693.el7.x86_64
软件要求:
| 机器 | ip | java | mysql | hadoop2.7.2 | flink1.14.3 | Streampark |
|---|---|---|---|---|---|---|
| hadoop101 | 192.168.100.200 | 1.8.0_144 | 5.6.24 | nm、nn、dn、JobHistoryServer | standaloneSessionCluster | StreamParkConsoleBootstrap |
| hadoop102 | 192.168.100.201 | 1.8.0_144 | / | dn、rm、nm | taskManagerRunner | |
| hadoop103 | 192.168.100.202 | 1.8.0_144 | / | dn、nm、sn | taskManagerRunner |
主要组件依赖关系:
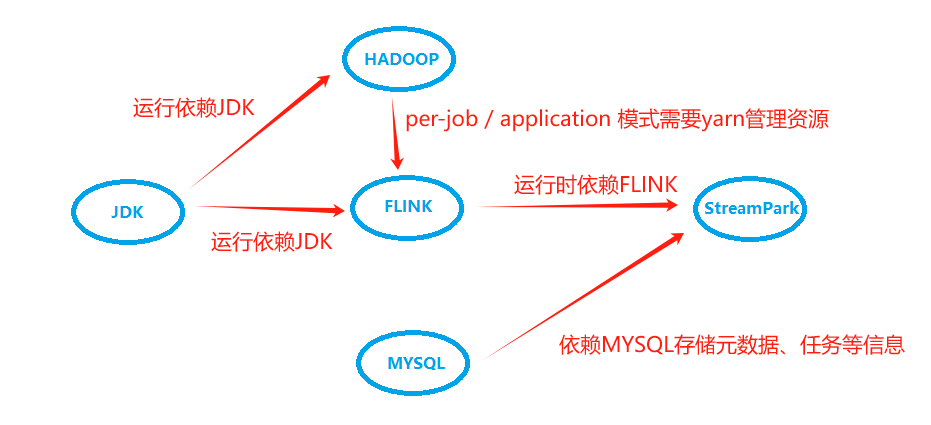
StreamPark是单机版本,hadoop101-hadoop103部署了flink集群
2.2 下载Apache StreamPark
1 | wget https://dlcdn.apache.org/incubator/streampark/2.0.0/apache-streampark_2.12-2.0.0-incubating-bin.tar.gz |
2.3 初始化系统数据
streamlib配置mysql的连接器jar包
1 | cd /opt/module/streampark/srcipts/schema/ |
2.4 配置Apache StreamPark
1 | vi /opt/module/streampark/conf/application.yml |
2.5 启动Apache Streampark
1 | ./opt/module/streampark/bin/startup.sh |
3. 快速上手
3.1 配置FLINK_HOME
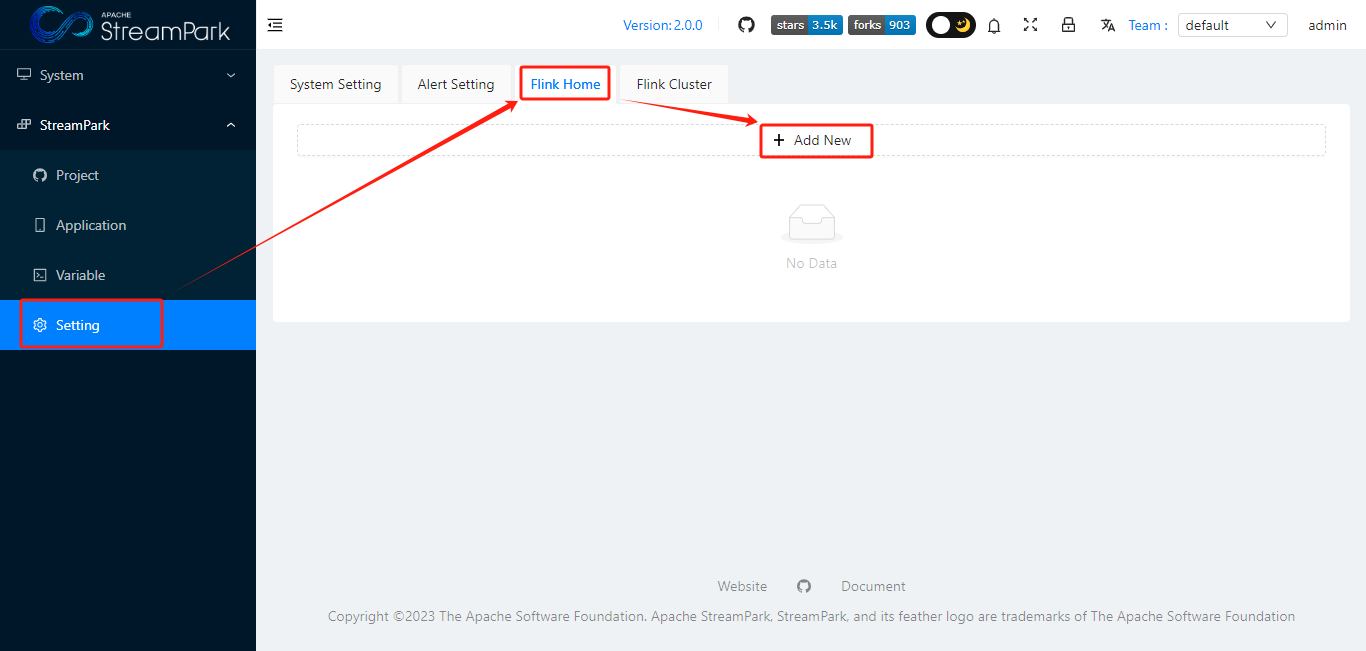
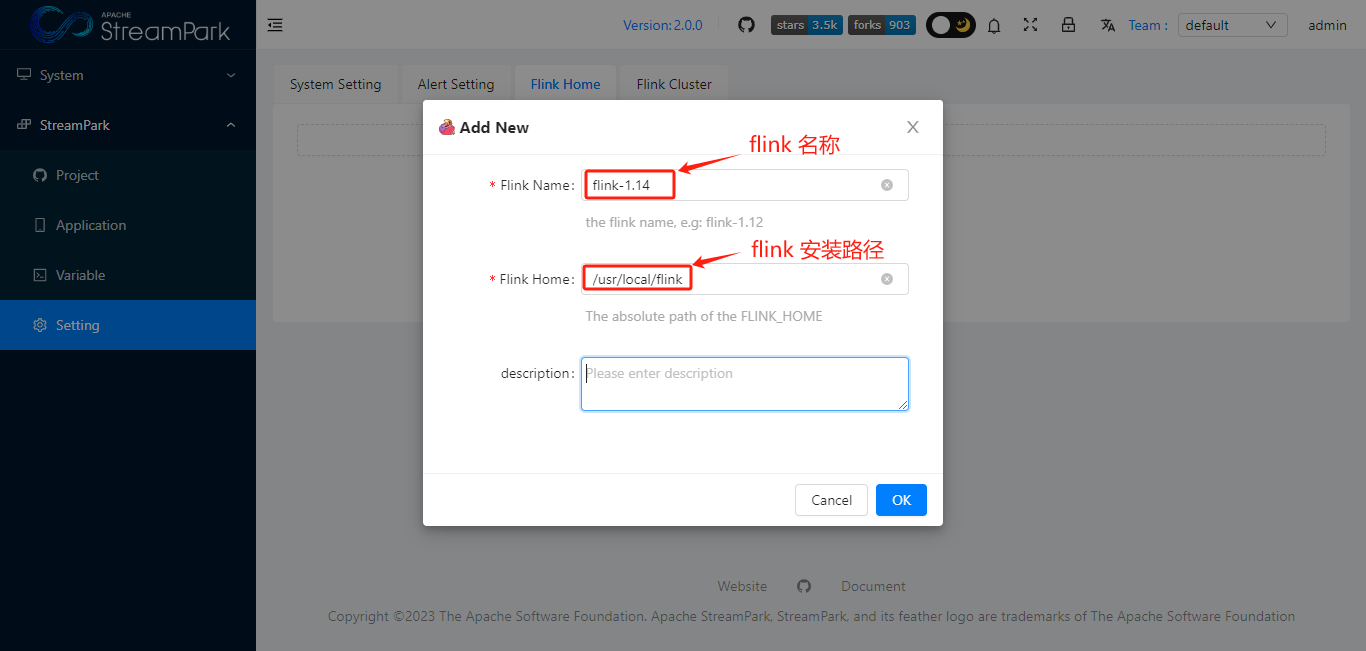
点击”OK”,保存
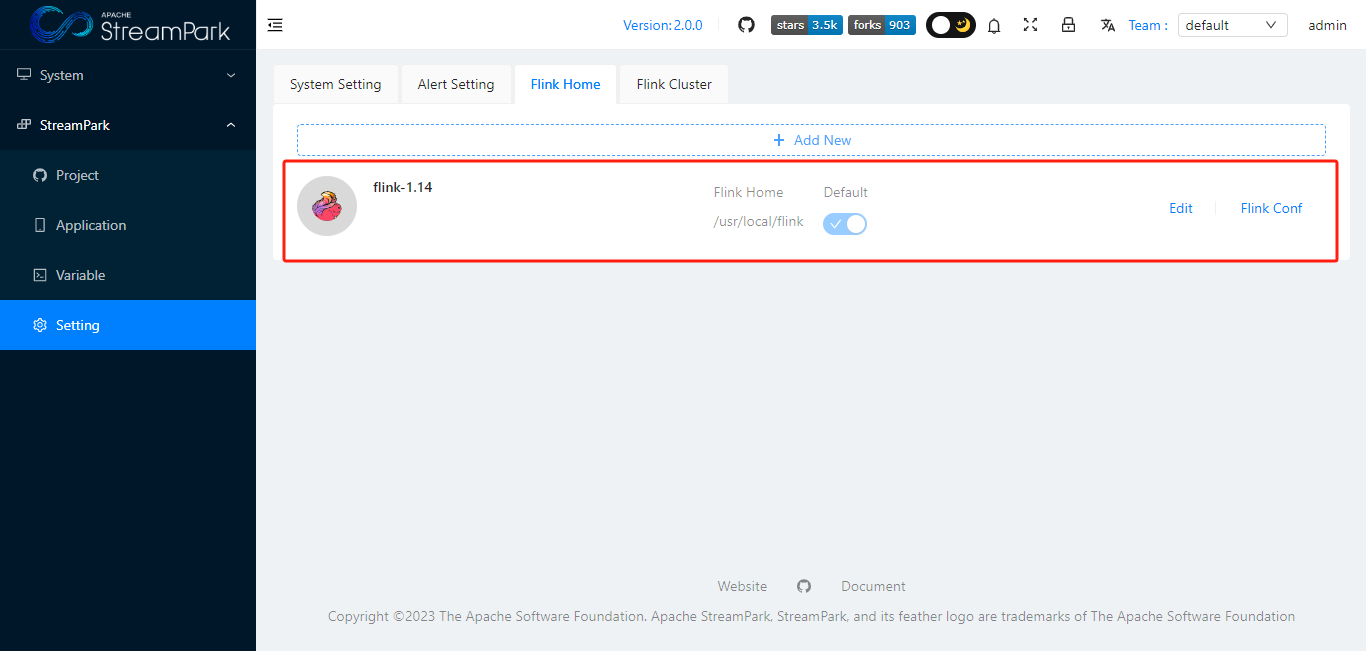
3.2 配置Flink Cluster
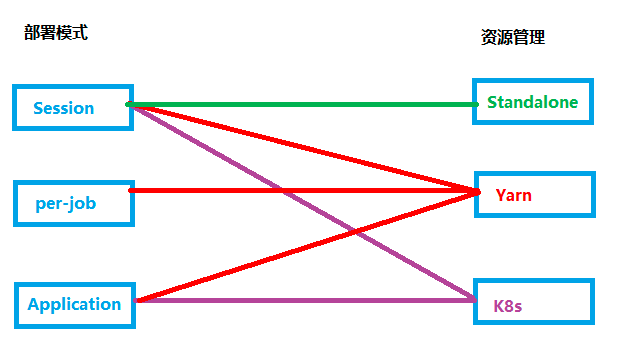
根据flink 部署模式 以及 资源管理方式,StreamPark 支持以下6种作业模式
- Standalone Session
- Yarn Session
- Yarn Per-job
- Yarn Application
- K8s Session
- K8s Application
本次选取较为简单的 Standalone Session 模式(下图绿色连线),快速上手。
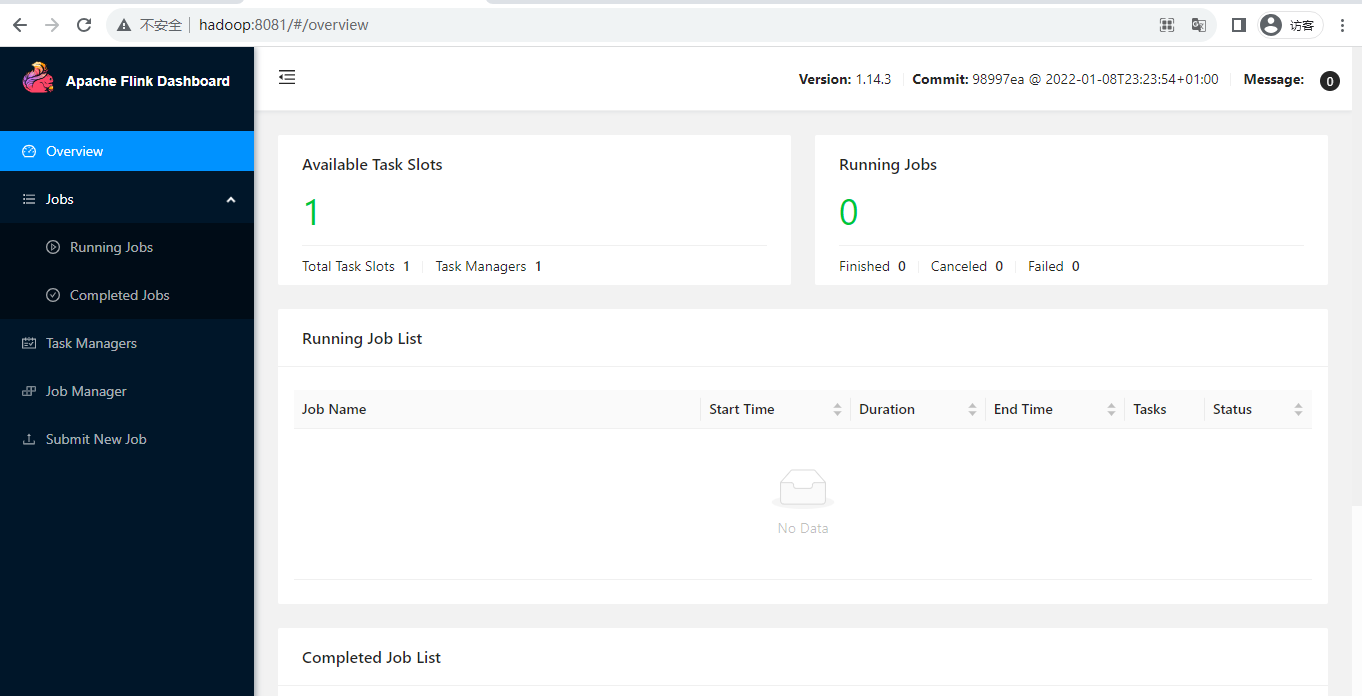
- 服务器启动 flink Standalone Session
1 | start-cluster.sh |

- 配置Flink Cluster
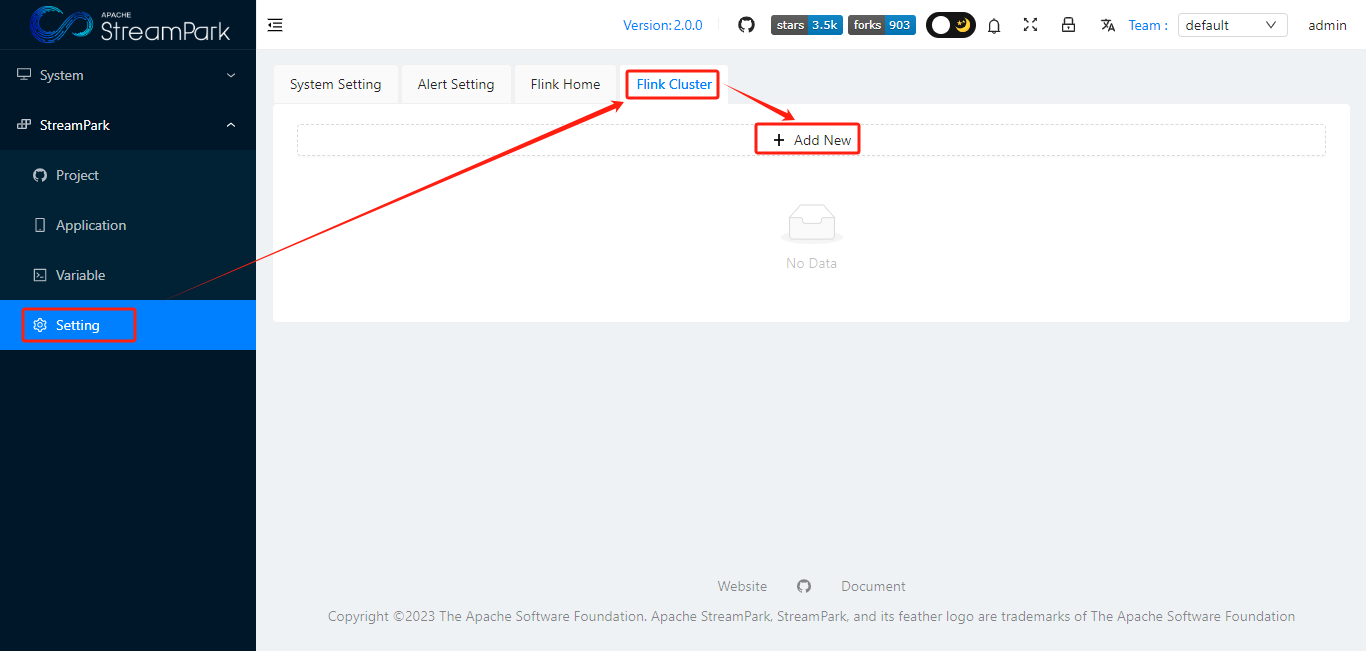
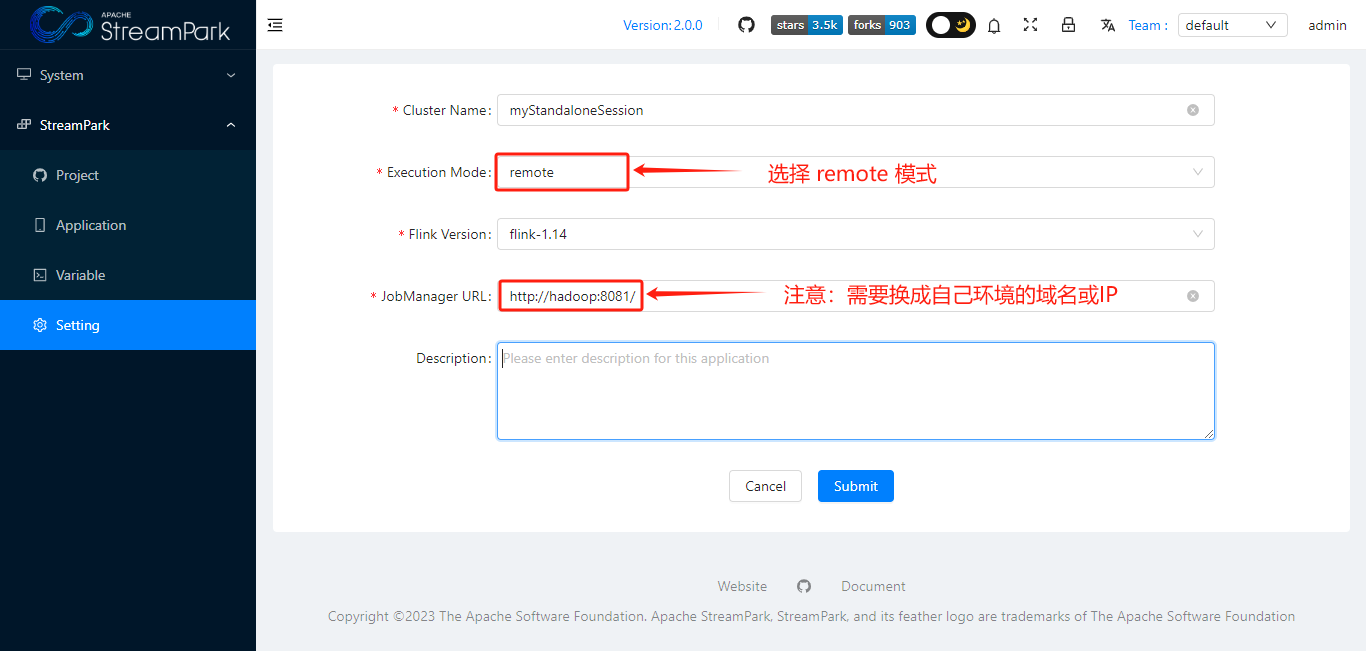

3.3 创建作业
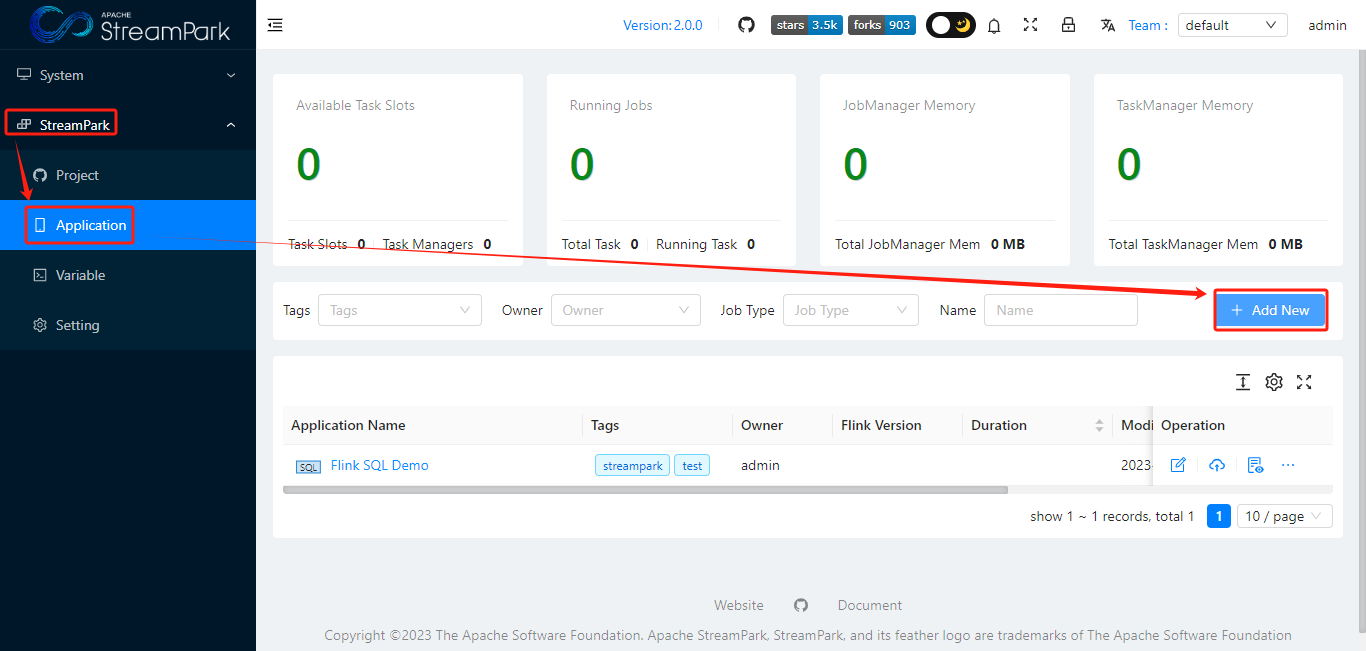
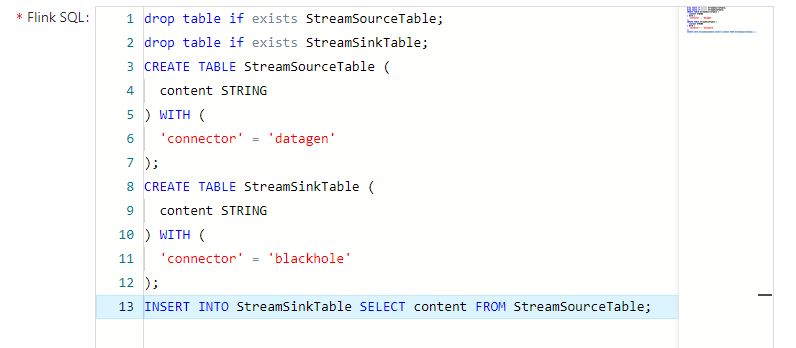
1 | drop table if exists StreamSourceTable; |
3.4 构建作业
点击 蓝色“Submit”按钮,提交作业
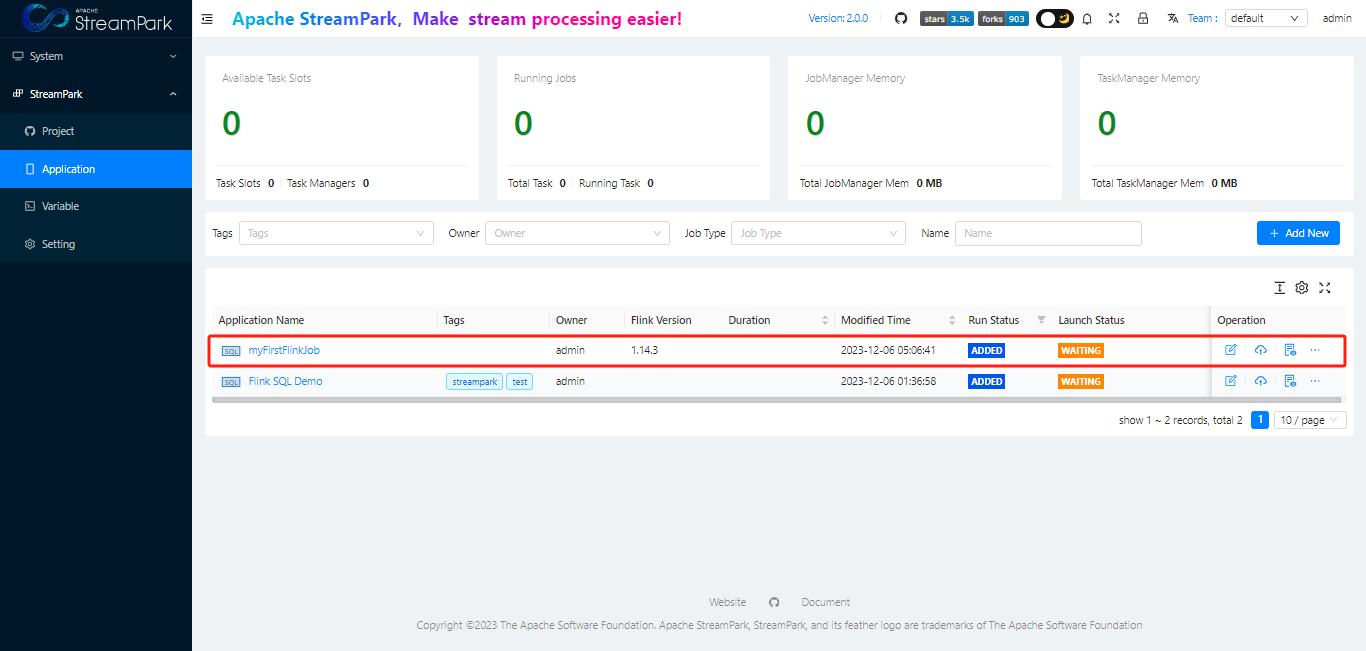
3.5 启动作业
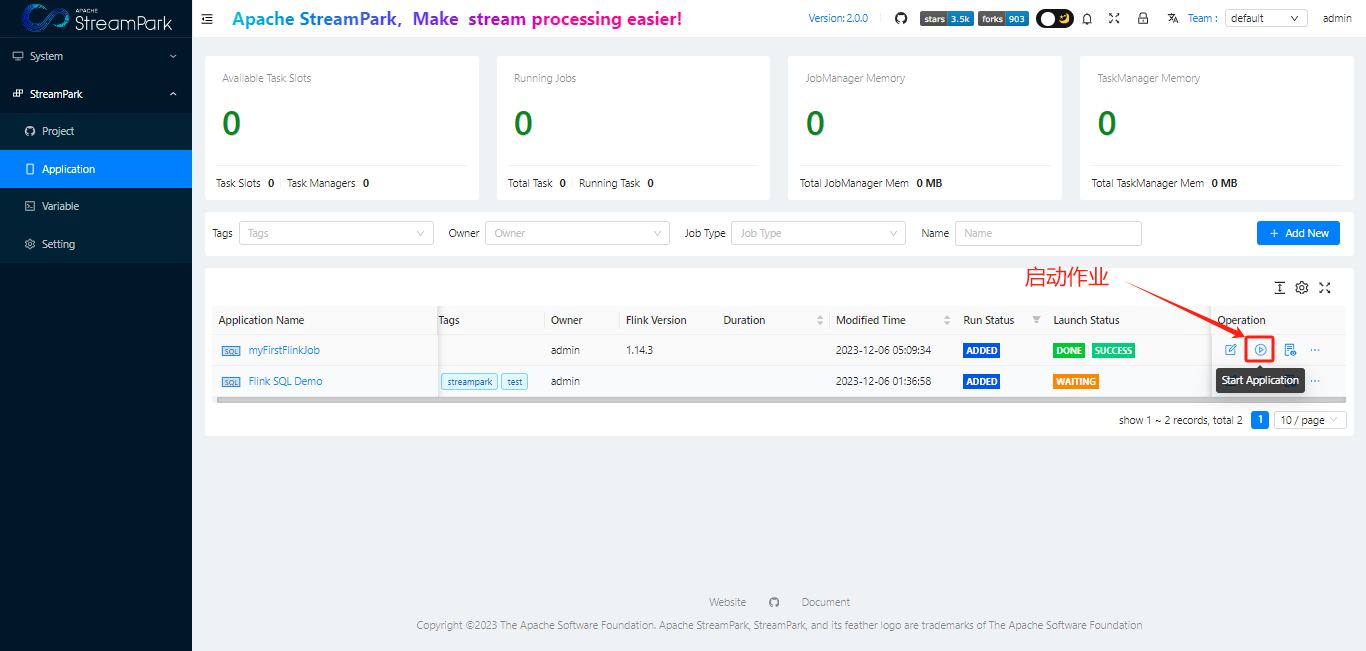
3.6 查询作业状态
- 查看StreamPark dashboard
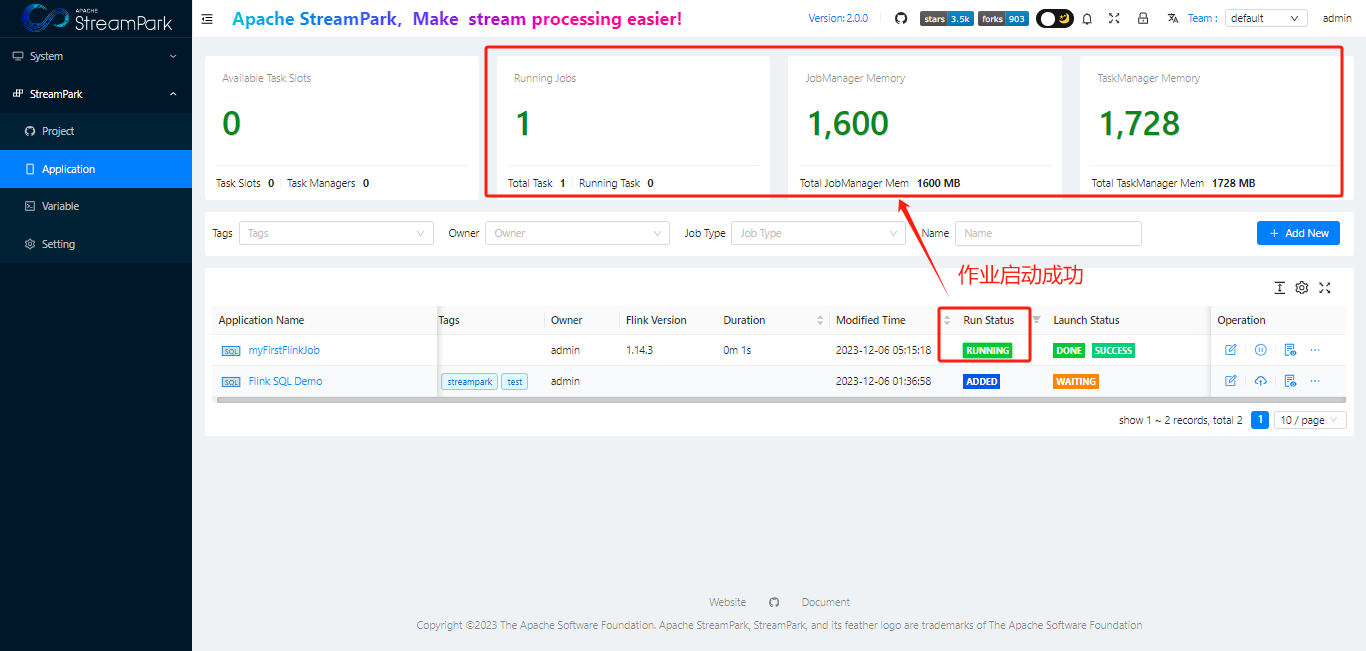
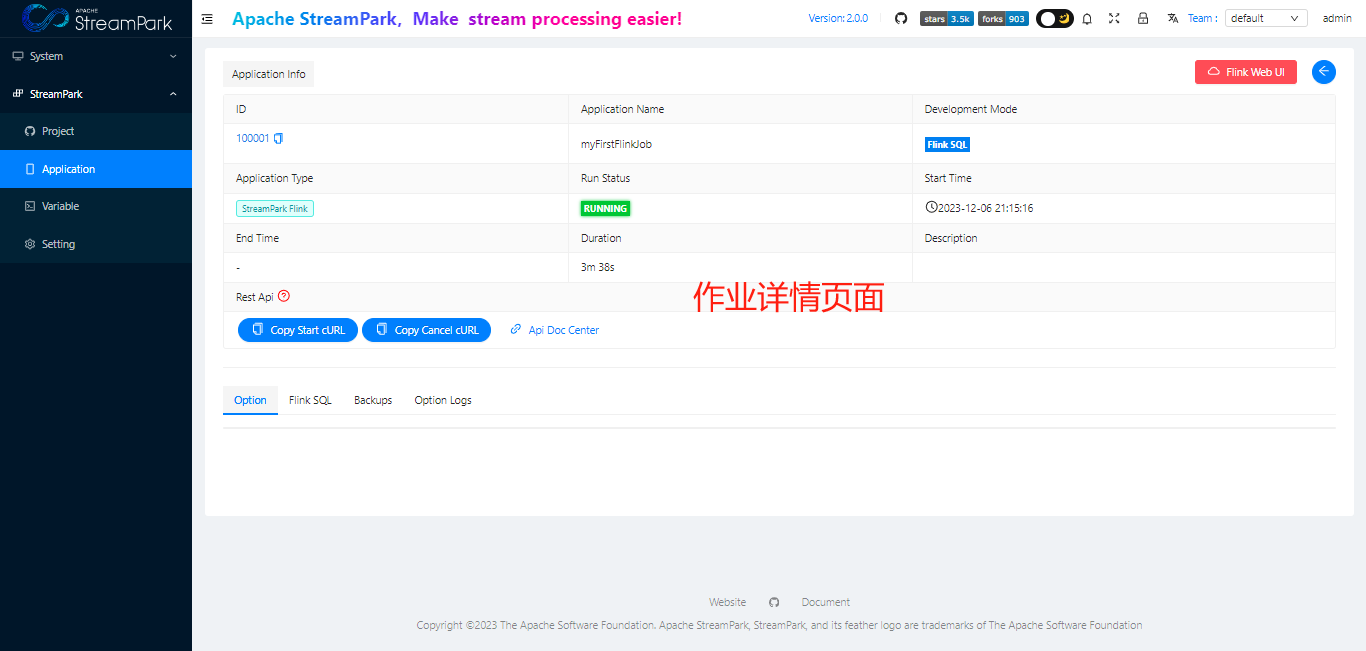
查看作业详情

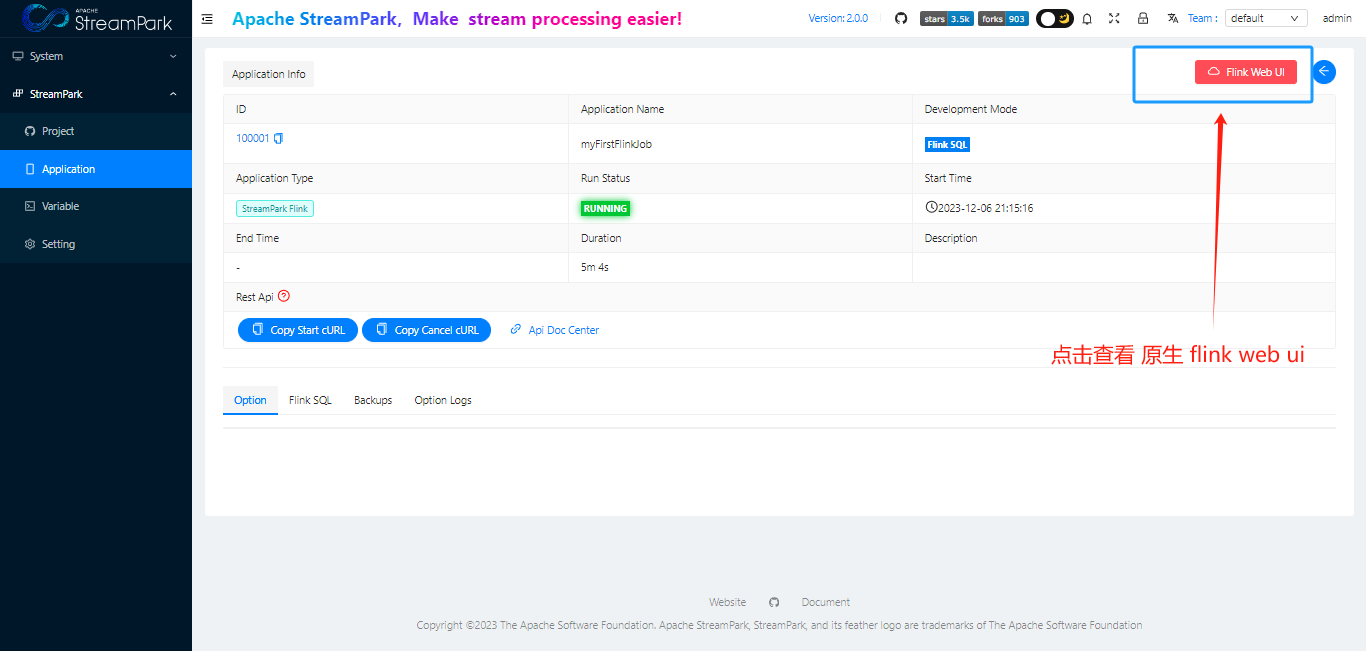
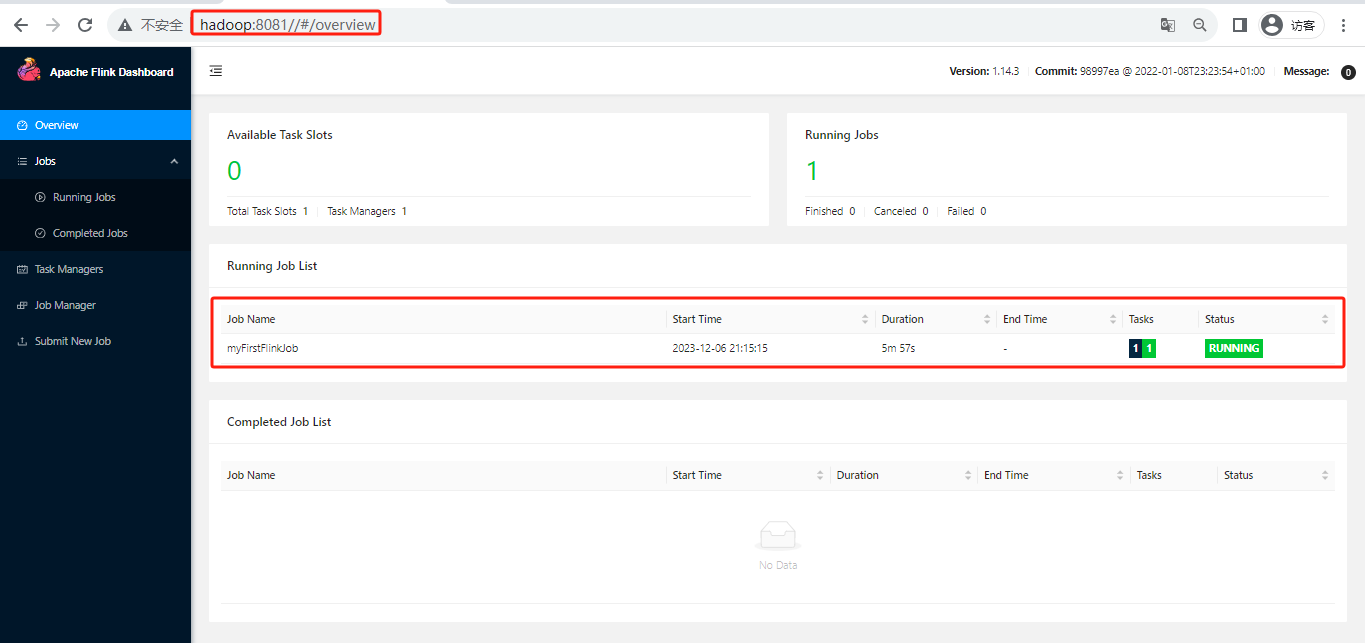
- 查看flink web ui
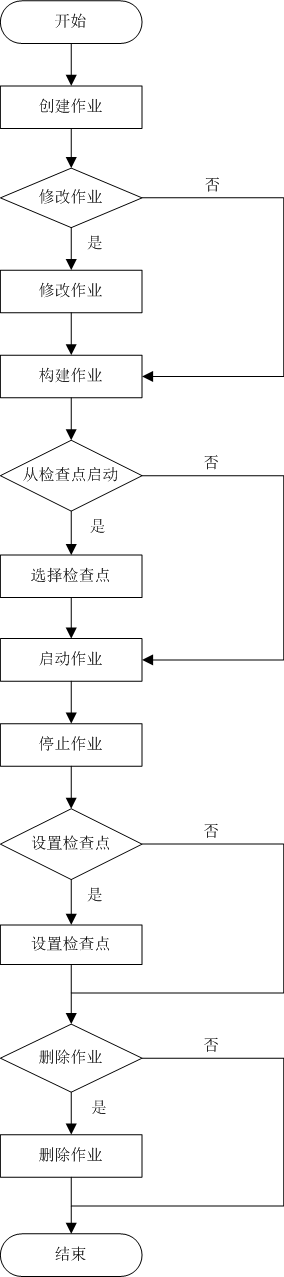
3.7 apache streampark平台管理flink job的流程
3.8 系统设置
菜单模块
flink部署模式
设置作业参数
告警策略
cp/sp
作业状态
作业详情
如何与第三方系统集成