之前我们已经介绍了spring中默认标签的解析,解析来我们将分析自定义标签的解析,我们先回顾下自定义标签解析所使用的方法,如下图所示:
1. 自定义标签的使用 扩展 Spring 自定义标签配置一般需要以下几个步骤:
创建一个需要扩展的组件
定义一个 XSD 文件,用于描述组件内容
创建一个实现 AbstractSingleBeanDefinitionParser 接口的类,用来解析 XSD 文件中的定义和组件定义
创建一个 Handler,继承 NamespaceHandlerSupport ,用于将组件注册到 Spring 容器
编写 Spring.handlers 和 Spring.schemas 文件
下面就按照上面的步骤来实现一个自定义标签组件。
1.1 创建组件 该组件就是一个普通的 JavaBean,没有任何特别之处。这里我创建了两个组件,为什么是两个,后面有用到
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package chenhao.spring01; /** * @author: ChenHao * @Description: * @Date: Created in 16:26 2019/7/2 * @Modified by: */ public class User { private String id; private String userName; private String email;public void setId(String id) { this.id = id; }public void setUserName(String userName) { this.userName = userName; }public void setEmail(String email) { this.email = email; } @Override public String toString() { final StringBuilder sb = new StringBuilder("{"); sb.append("\"id\":\"") .append(id).append('\"'); sb.append(",\"userName\":\"") .append(userName).append('\"'); sb.append(",\"email\":\"") .append(email).append('\"'); sb.append('}'); return sb.toString(); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package chenhao.spring01; /** * @author: ChenHao * @Description: * @Date: Created in 16:26 2019/7/2 * @Modified by: */ public class Phone { private String color; private int size; private String remark; public void setColor(String color) { this.color = color; } public void setSize(int size) { this.size = size; } public void setRemark(String remark) { this.remark = remark; } @Override public String toString() { final StringBuilder sb = new StringBuilder("{"); sb.append("\"color\":\"") .append(color).append('\"'); sb.append(",\"size\":") .append(size); sb.append(",\"remark\":\"") .append(remark).append('\"'); sb.append('}'); return sb.toString(); } }
1.2 定义XSD文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 <?xml version="1.0" encoding="UTF-8" standalone="no"?> <xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns="http://www.chenhao.com/schema/user" targetNamespace="http://www.chenhao.com/schema/user" elementFormDefault="qualified"> <xsd:element name="user"> <xsd:complexType> <xsd:attribute name="id" type="xsd:string" /> <xsd:attribute name="userName" type="xsd:string" /> <xsd:attribute name="email" type="xsd:string" /> </xsd:complexType> </xsd:element> <xsd:element name="phone"> <xsd:complexType> <xsd:attribute name="id" type="xsd:string" /> <xsd:attribute name="color" type="xsd:string" /> <xsd:attribute name="size" type="xsd:int" /> <xsd:attribute name="remark" type="xsd:string" /> </xsd:complexType> </xsd:element> </xsd:schema>
在上述XSD文件中描述了一个新的targetNamespace,并在这个空间里定义了一个name为user 和phone 的element 。user里面有三个attribute。主要是为了验证Spring配置文件中的自定义格式。再进一步解释,就是,Spring位置文件中使用的user自定义标签中,属性只能是上面的三种,有其他的属性的话,就会报错。
1.3 Parser类 定义一个 Parser 类,该类继承 AbstractSingleBeanDefinitionParser ,并实现 getBeanClass()doParse()
UserBeanDefinitionParser.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 package chenhao.spring01; import org.springframework.beans.factory.support.BeanDefinitionBuilder; import org.springframework.beans.factory.xml.AbstractSingleBeanDefinitionParser; import org.springframework.util.StringUtils; import org.w3c.dom.Element; /** * @author: ChenHao * @Description: * @Date: Created in 16:29 2019/7/2 * @Modified by: */ public class UserBeanDefinitionParser extends AbstractSingleBeanDefinitionParser { @Override protected Class getBeanClass(Element ele){ return User.class; } @Override protected void doParse(Element element, BeanDefinitionBuilder builder) { String id = element.getAttribute("id"); String userName=element.getAttribute("userName"); String email=element.getAttribute("email"); if(StringUtils.hasText(id)){ builder.addPropertyValue("id",id); } if(StringUtils.hasText(userName)){ builder.addPropertyValue("userName", userName); } if(StringUtils.hasText(email)){ builder.addPropertyValue("email", email); } } }
PhoneBeanDefinitionParser.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 package chenhao.spring01; import org.springframework.beans.factory.support.BeanDefinitionBuilder; import org.springframework.beans.factory.xml.AbstractSingleBeanDefinitionParser; import org.springframework.util.StringUtils; import org.w3c.dom.Element; /** * @author: ChenHao * @Description: * @Date: Created in 16:29 2019/7/2 * @Modified by: */ public class PhoneBeanDefinitionParser extends AbstractSingleBeanDefinitionParser { @Override protected Class getBeanClass(Element ele){ return Phone.class; } @Override protected void doParse(Element element, BeanDefinitionBuilder builder) { String color = element.getAttribute("color"); int size=Integer.parseInt(element.getAttribute("size")); String remark=element.getAttribute("remark"); if(StringUtils.hasText(color)){ builder.addPropertyValue("color",color); } if(StringUtils.hasText(String.valueOf(size))){ builder.addPropertyValue("size", size); } if(StringUtils.hasText(remark)){ builder.addPropertyValue("remark", remark); } } }
1.4 Handler类 定义 Handler 类,继承 NamespaceHandlerSupport ,主要目的是将上面定义的解析器Parser类 注册到 Spring 容器中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package chenhao.spring01; import org.springframework.beans.factory.xml.NamespaceHandlerSupport; /** * @author: ChenHao * @Description: * @Date: Created in 16:38 2019/7/2 * @Modified by: */ public class MyNamespaceHandler extends NamespaceHandlerSupport { @Override public void init() { registerBeanDefinitionParser("user",new UserBeanDefinitionParser()); registerBeanDefinitionParser("phone",new PhoneBeanDefinitionParser()); } }
我们看看 registerBeanDefinitionParser 方法做了什么
1 2 3 4 5 private final Map<String, BeanDefinitionParser> parsers = new HashMap<>(); protected final void registerBeanDefinitionParser(String elementName, BeanDefinitionParser parser) { this.parsers.put(elementName, parser); }
就是将解析器 UserBeanDefinitionParser和 PhoneBeanDefinitionParser 的实例放到全局的Map中,key为user和phone。
1.5 Spring.handlers和Spring.schemas 编写Spring.handlers和Spring.schemas文件,默认位置放在工程的META-INF文件夹下
Spring.handlers
1 http\://www.chenhao.com/schema/user=chenhao.spring01.MyNamespaceHandler
Spring.schemas
1 http\://www.chenhao.com/schema/user.xsd=org/user.xsd
而 Spring 加载自定义的大致流程是遇到自定义标签然后 就去 Spring.handlers 和 Spring.schemas 中去找对应的 handler 和 XSD ,默认位置是 META-INF 下,进而有找到对应的handler以及解析元素的 Parser ,从而完成了整个自定义元素的解析,也就是说 Spring 将向定义标签解析的工作委托给了 用户去实现。
1.6 创建测试配置文件 经过上面几个步骤,就可以使用自定义的标签了。在 xml 配置文件中使用如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 <?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:myTag="http://www.chenhao.com/schema/user" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.chenhao.com/schema/user http://www.chenhao.com/schema/user.xsd"> <bean id="myTestBean" class="chenhao.spring01.MyTestBean"/> <myTag:user id="user" email="chenhao@163.com" userName="chenhao" /> <myTag:phone id="iphone" color="black" size="128" remark="iphone XR"/> </beans>
xmlns:myTag 表示myTag的命名空间是 http://www.chenhao.com/schema/user ,
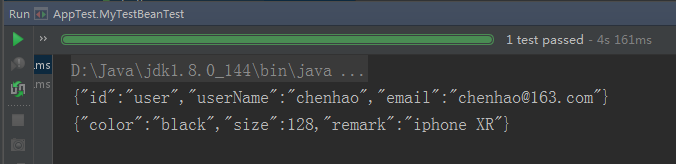
1.7 测试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import chenhao.spring01.MyTestBean; import chenhao.spring01.Phone; import chenhao.spring01.User; import org.junit.Test; import org.springframework.beans.factory.BeanFactory; import org.springframework.beans.factory.xml.XmlBeanFactory; import org.springframework.core.io.ClassPathResource; /** * @author: ChenHao * @Description: * @Date: Created in 10:36 2019/6/19 * @Modified by: */ public class AppTest { @Test public void MyTestBeanTest() { BeanFactory bf = new XmlBeanFactory( new ClassPathResource("spring-config.xml")); //MyTestBean myTestBean01 = (MyTestBean) bf.getBean("myTestBean"); User user = (User) bf.getBean("user"); Phone iphone = (Phone) bf.getBean("iphone"); System.out.println(user); System.out.println(iphone); } }
输出结果:
项目整体文件目录如下
2. 自定义标签的解析 了解了自定义标签的使用后,接下来我们分析下自定义标签的解析,自定义标签解析用的是方法:parseCustomElement(Element ele, @Nullable BeanDefinition containingBd),进入方法体:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public BeanDefinition parseCustomElement(Element ele, @Nullable BeanDefinition containingBd) { // 获取 标签对应的命名空间 String namespaceUri = getNamespaceURI(ele); if (namespaceUri == null) { return null; } // 根据 命名空间找到相应的 NamespaceHandler NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri); if (handler == null) { error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", ele); return null; } // 调用自定义的 Handler 处理 return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd)); }
相信了解了自定义标签的使用方法后,或多或少会对向定义标签的实现过程有一个自己的 想法 其实思路非常的简单,无非是根据对应的bean 获取对应的命名空间 ,根据命名空间解析对应的处理器,然后根据用户自定义的处理器进行解析。
2.1 获取标签的命名空间 标签的解析是从命名空间的提起开始的,元论是区分 Spring中默认标签和自定义标 还是 区分自定义标签中不同标签的处理器 都是以标签所提供的命名空间为基础的,而至于如何提取对应元素的命名空间其实并不需要我们亲内去实现,在 org.w3c.dom.Node 中已经提供了方法供我们直接调用:
1 2 3 4 5 String namespaceUri = getNamespaceURI(ele); @Nullable public String getNamespaceURI(Node node) { return node.getNamespaceURI(); }
这里我们通过DEBUG看出myTag:user自定义标签对应的 namespaceUri 是 http://www.chenhao.com/schema/user
2.2 读取自定义标签处理器 根据 namespaceUri 获取 Handler,这个映射关系我们在 Spring.handlers 中已经定义了,所以只需要找到该类,然后初始化返回,最后调用该 Handler 对象的 parse() 方法处理,该方法我们也提供了实现。所以上面的核心就在于怎么找到该 Handler 类。调用方法为:this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 public NamespaceHandler resolve(String namespaceUri) { // 获取所有已经配置的 Handler 映射 Map<String, Object> handlerMappings = getHandlerMappings(); // 根据 namespaceUri 获取 handler的信息:这里一般都是类路径 Object handlerOrClassName = handlerMappings.get(namespaceUri); if (handlerOrClassName == null) { return null; } else if (handlerOrClassName instanceof NamespaceHandler) { // 如果已经做过解析,直接返回 return (NamespaceHandler) handlerOrClassName; } else { String className = (String) handlerOrClassName; try { Class<?> handlerClass = ClassUtils.forName(className, this.classLoader); if (!NamespaceHandler.class.isAssignableFrom(handlerClass)) { throw new FatalBeanException("Class [" + className + "] for namespace [" + namespaceUri + "] does not implement the [" + NamespaceHandler.class.getName() + "] interface"); } // 初始化类 NamespaceHandler namespaceHandler = (NamespaceHandler) BeanUtils.instantiateClass(handlerClass); // 调用 自定义NamespaceHandler 的init() 方法 namespaceHandler.init(); // 记录在缓存 handlerMappings.put(namespaceUri, namespaceHandler); return namespaceHandler; } catch (ClassNotFoundException ex) { throw new FatalBeanException("Could not find NamespaceHandler class [" + className + "] for namespace [" + namespaceUri + "]", ex); } catch (LinkageError err) { throw new FatalBeanException("Unresolvable class definition for NamespaceHandler class [" + className + "] for namespace [" + namespaceUri + "]", err); } } }
首先调用 getHandlerMappings() 获取所有配置文件中的映射关系 handlerMappings ,就是我们在 Spring.handlers 文件中配置 命名空间与命名空间处理器的映射关系,该关系为 <命名空间,类路径>,然后根据命名空间 namespaceUri 从映射关系中获取相应的信息,如果为空或者已经初始化了就直接返回,否则根据反射对其进行初始化,同时调用其 init()方法,最后将该 Handler 对象缓存。我们再次回忆下示例中对于命名空间处理器的内容:
1 2 3 4 5 6 7 8 9 10 public class MyNamespaceHandler extends NamespaceHandlerSupport { @Override public void init() { registerBeanDefinitionParser("user",new UserBeanDefinitionParser()); registerBeanDefinitionParser("phone",new PhoneBeanDefinitionParser()); } }
当得到自定义命名空间处理后会马上执行 namespaceHandler.init() 来进行自定义 BeanDefinitionParser的注册,在这里,你可以注册多个标签解析器,如当前示例中 <myTag:user 标签就使用 new UserBeanDefinitionParser()解析器; <myTag:phone就使用new PhoneBeanDefinitionParser()解析器。
上面我们已经说过, init()中的registerBeanDefinitionParser 方法 其实就是将映射关系放在一个 Map 结构的 parsers 对象中:private final Map<String, BeanDefinitionParser> parsers 。
2.3 解析标签 得到了解析器和分析的元素后,Spring就可以将解析工作委托给自定义解析器去解析了,对于标签的解析使用的是:NamespaceHandler.parse(ele, new ParserContext(this.readerContext, this, containingBd))方法,进入到方法体内:
1 2 3 4 public BeanDefinition parse(Element element, ParserContext parserContext) { BeanDefinitionParser parser = findParserForElement(element, parserContext); return (parser != null ? parser.parse(element, parserContext) : null); }
调用 findParserForElement() 方法获取 BeanDefinitionParser 实例,其实就是获取在 init() 方法里面注册的实例对象。如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 private BeanDefinitionParser findParserForElement(Element element, ParserContext parserContext) { //获取元素名称,也就是<myTag:user中的 user String localName = parserContext.getDelegate().getLocalName(element); //根据 user 找到对应的解析器,也就是在 //registerBeanDefinitionParser("user",new UserBeanDefinitionParser()); //中注册的解析器 BeanDefinitionParser parser = this.parsers.get(localName); if (parser == null) { parserContext.getReaderContext().fatal( "Cannot locate BeanDefinitionParser for element [" + localName + "]", element); } return parser; }
获取 localName,在上面的例子中就是 : user,然后从 Map 实例 parsers 中获取 UserBeanDefinitionParser实例对象。返回 BeanDefinitionParser 对象后,调用其 parse(),该方法在 AbstractBeanDefinitionParser 中实现:
获取 localName,在上面的例子中就是 : user,然后从 Map 实例 parsers 中获取 UserBeanDefinitionParser实例对象。返回 BeanDefinitionParser 对象后,调用其 parse(),该方法在 AbstractBeanDefinitionParser 中实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public final BeanDefinition parse(Element element, ParserContext parserContext) { AbstractBeanDefinition definition = parseInternal(element, parserContext); if (definition != null && !parserContext.isNested()) { try { String id = resolveId(element, definition, parserContext); if (!StringUtils.hasText(id)) { parserContext.getReaderContext().error( "Id is required for element '" + parserContext.getDelegate().getLocalName(element) + "' when used as a top-level tag", element); } String[] aliases = null; if (shouldParseNameAsAliases()) { String name = element.getAttribute(NAME_ATTRIBUTE); if (StringUtils.hasLength(name)) { aliases = StringUtils.trimArrayElements(StringUtils.commaDelimitedListToStringArray(name)); } } BeanDefinitionHolder holder = new BeanDefinitionHolder(definition, id, aliases); //将 AbstractBeanDefinition 转换为 BeanDefinitionHolder 并注册 registerBeanDefinition(holder, parserContext.getRegistry()); if (shouldFireEvents()) { BeanComponentDefinition componentDefinition = new BeanComponentDefinition(holder); postProcessComponentDefinition(componentDefinition); parserContext.registerComponent(componentDefinition); } } catch (BeanDefinitionStoreException ex) { String msg = ex.getMessage(); parserContext.getReaderContext().error((msg != null ? msg : ex.toString()), element); return null; } } return definition; }
虽然说是对自定义配置文件的解析,但是我们可以看到在这个函数中大部分的代码用来处理将解析后的AbstractBeanDefinition转换为BeanDefinitionHolder并注册的功能,而真正去做解析的事情委托了给parseInternal,真是这句代码调用了我们的自定义解析函数。在parseInternal中,并不是直接调用自定义的doParse函数,而是进行了一些列的数据准备,包括对beanClass,scope,lazyInit等属性的准备。 我们进入到AbstractSingleBeanDefinitionParser.parseInternal方法中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 protected final AbstractBeanDefinition parseInternal(Element element, ParserContext parserContext) { // 创建一个BeanDefinitionBuilder,内部实际上是创建一个GenericBeanDefinition的实例,用于存储自定义标签的元素 BeanDefinitionBuilder builder = BeanDefinitionBuilder.genericBeanDefinition(); // 获取父类元素 String parentName = getParentName(element); if (parentName != null) { builder.getRawBeanDefinition().setParentName(parentName); } // 获取自定义标签中的 class,这个时候会去调用自定义解析中的 getBeanClass() Class<?> beanClass = getBeanClass(element); if (beanClass != null) { builder.getRawBeanDefinition().setBeanClass(beanClass); } else { // beanClass 为 null,意味着子类并没有重写 getBeanClass() 方法,则尝试去判断是否重写了 getBeanClassName() String beanClassName = getBeanClassName(element); if (beanClassName != null) { builder.getRawBeanDefinition().setBeanClassName(beanClassName); } } builder.getRawBeanDefinition().setSource(parserContext.extractSource(element)); BeanDefinition containingBd = parserContext.getContainingBeanDefinition(); if (containingBd != null) { // Inner bean definition must receive same scope as containing bean. builder.setScope(containingBd.getScope()); } if (parserContext.isDefaultLazyInit()) { // Default-lazy-init applies to custom bean definitions as well. builder.setLazyInit(true); } // 调用子类的 doParse() 进行解析 doParse(element, parserContext, builder); return builder.getBeanDefinition(); } public static BeanDefinitionBuilder genericBeanDefinition() { return new BeanDefinitionBuilder(new GenericBeanDefinition()); } protected Class<?> getBeanClass(Element element) { return null; } protected void doParse(Element element, BeanDefinitionBuilder builder) { }
在该方法中我们主要关注两个方法:**getBeanClass() 、doParse()**。对于 getBeanClass() 方法,AbstractSingleBeanDefinitionParser 类并没有提供具体实现,而是直接返回 null,意味着它希望子类能够重写该方法,当然如果没有重写该方法,这会去调用 getBeanClassName() ,判断子类是否已经重写了该方法。对于 doParse() 则是直接空实现。所以对于 parseInternal() 而言它总是期待它的子类能够实现 getBeanClass()、doParse(),其中 doParse() 尤为重要,如果你不提供实现,怎么来解析自定义标签呢?最后将自定义的解析器:UserDefinitionParser 再次回观。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class UserBeanDefinitionParser extends AbstractSingleBeanDefinitionParser { @Override protected Class getBeanClass(Element ele){ return User.class; } @Override protected void doParse(Element element, BeanDefinitionBuilder builder) { String id = element.getAttribute("id"); String userName=element.getAttribute("userName"); String email=element.getAttribute("email"); if(StringUtils.hasText(id)){ builder.addPropertyValue("id",id); } if(StringUtils.hasText(userName)){ builder.addPropertyValue("userName", userName); } if(StringUtils.hasText(email)){ builder.addPropertyValue("email", email); } } }
我们看看 builder.addPropertyValue (“id”,id) ,实际上是将自定义标签中的属性解析,存入 BeanDefinitionBuilder 中的 beanDefinition实例中
1 2 3 4 5 6 private final AbstractBeanDefinition beanDefinition; public BeanDefinitionBuilder addPropertyValue(String name, @Nullable Object value) { this.beanDefinition.getPropertyValues().add(name, value); return this; }
最后 将 AbstractBeanDefinition 转换为 BeanDefinitionHolder 并注册 registerBeanDefinition(holder, parserContext.getRegistry());这就和默认标签的注册是一样了。
至此,自定义标签的解析过程已经分析完成了。其实整个过程还是较为简单:首先会加载 handlers 文件,将其中内容进行一个解析,形成 <namespaceUri,类路径> 这样的一个映射,然后根据获取的 namespaceUri 就可以得到相应的类路径,对其进行初始化等到相应的 Handler 对象,调用 parse() 方法,在该方法中根据标签的 localName 得到相应的 BeanDefinitionParser 实例对象,调用 parse() ,该方法定义在 AbstractBeanDefinitionParser 抽象类中,核心逻辑封装在其 parseInternal() 中,该方法返回一个 AbstractBeanDefinition 实例对象,其主要是在 AbstractSingleBeanDefinitionParser 中实现,对于自定义的 Parser 类,其需要实现 getBeanClass() 或者 getBeanClassName() 和 doParse()。最后将 AbstractBeanDefinition 转换为 BeanDefinitionHolder 并注册 。
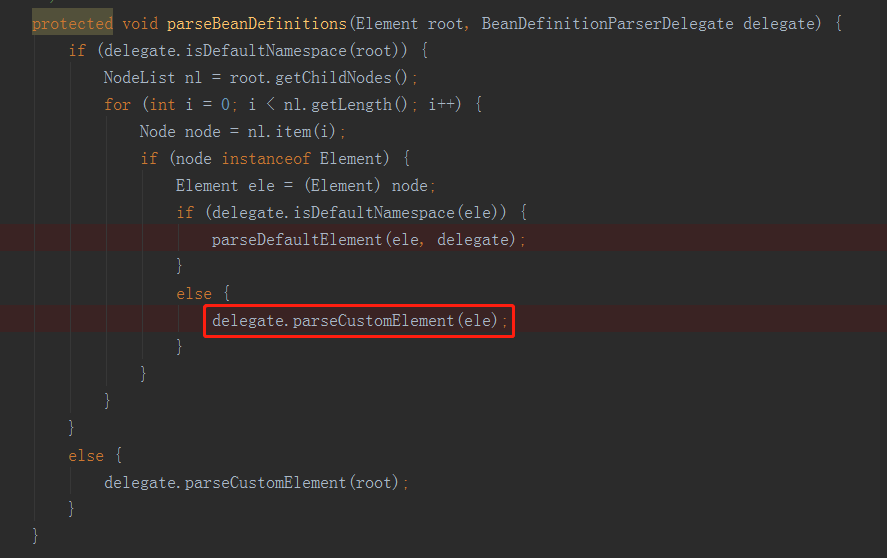 我们看到自定义标签的解析是通过BeanDefinitionParserDelegate.parseCustomElement(ele)进行的,解析来我们进行详细分析。
我们看到自定义标签的解析是通过BeanDefinitionParserDelegate.parseCustomElement(ele)进行的,解析来我们进行详细分析。