1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
| import os
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.document_loaders import Docx2txtLoader
from langchain_community.document_loaders import TextLoader
base_dir = '.\OneFlower'
documents = []
for file in os.listdir(base_dir):
file_path = os.path.join(base_dir, file)
if file.endswith('.pdf'):
loader = PyPDFLoader(file_path)
documents.extend(loader.load())
elif file.endswith('.docx'):
loader = Docx2txtLoader(file_path)
documents.extend(loader.load())
elif file.endswith('.txt'):
loader = TextLoader(file_path)
documents.extend(loader.load())
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
chunked_documents = text_splitter.split_documents(documents)
print(f"优化后文档分块数量:{len(chunked_documents)}")
import os
import requests
from typing import List
from langchain.embeddings.base import Embeddings
from langchain_community.vectorstores import Qdrant
class QwenEmbeddings(Embeddings):
def __init__(self, api_key: str, base_url: str):
self.api_key = api_key
self.base_url = base_url
self.model = "text-embedding-v1"
self.max_batch_size = 25
def embed_documents(self, texts: List[str]) -> List[List[float]]:
"""嵌入文档:过滤空文本 + 批量拆分(每批≤25条)"""
valid_texts = [text.strip() for text in texts if text.strip()]
if not valid_texts:
return []
all_embeddings = []
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
for i in range(0, len(valid_texts), self.max_batch_size):
batch_texts = valid_texts[i:i + self.max_batch_size]
payload = {
"model": self.model,
"input": batch_texts
}
try:
response = requests.post(
f"{self.base_url}/embeddings",
headers=headers,
json=payload,
timeout=30
)
response.raise_for_status()
batch_embeddings = [item["embedding"] for item in response.json()["data"]]
all_embeddings.extend(batch_embeddings)
print(f"成功处理第 {i // self.max_batch_size + 1} 批嵌入(共 {len(batch_texts)} 条)")
except Exception as e:
print(f"处理第 {i // self.max_batch_size + 1} 批嵌入失败:{str(e)}")
print(f"当前批次文本(前300字符):{str(batch_texts[:2])[:300]}...")
raise
assert len(all_embeddings) == len(valid_texts), "嵌入结果数量与文本数量不匹配!"
return all_embeddings
def embed_query(self, text: str) -> List[List[float]]:
"""嵌入查询:单条文本,无需拆分"""
return self.embed_documents([text])[0] if text.strip() else []
embedding = QwenEmbeddings(
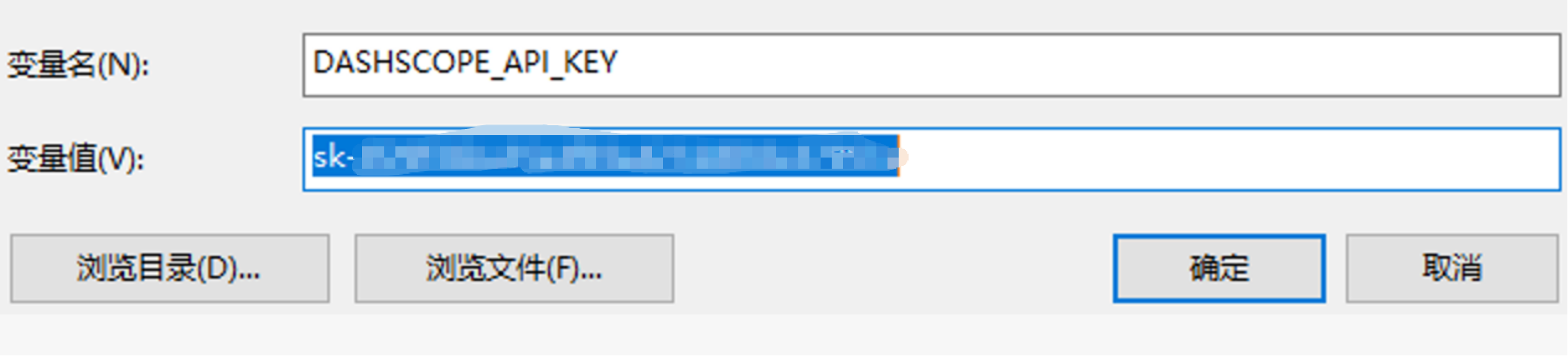
api_key=os.environ.get("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
vectorstore = Qdrant.from_documents(
documents=chunked_documents,
embedding=embedding,
location=":memory:",
collection_name="my_documents",
)
import logging
from langchain_community.chat_models import ChatOpenAI
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain.chains import RetrievalQA
logging.basicConfig()
logging.getLogger('langchain.retrievers.multi_query').setLevel(logging.INFO)
llm = ChatOpenAI(
api_key=os.environ.get("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model_name="qwen-flash",
)
retriever_from_llm = MultiQueryRetriever.from_llm(retriever=vectorstore.as_retriever(), llm=llm)
qa_chain = RetrievalQA.from_chain_type(llm,retriever=retriever_from_llm)
from flask import Flask, request, render_template
app = Flask(__name__)
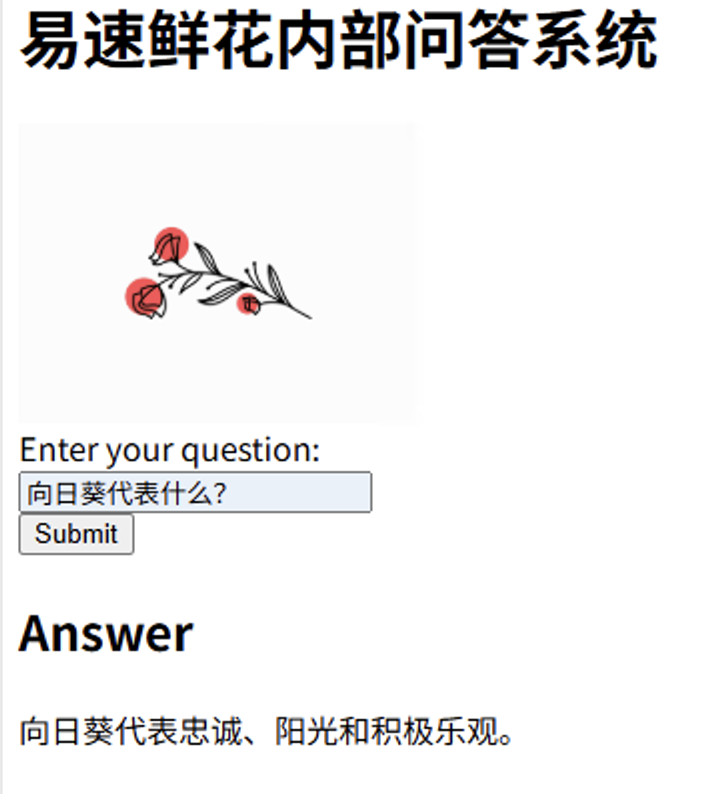
@app.route('/', methods=['GET', 'POST'])
def home():
if request.method == 'POST':
question = request.form.get('question')
result = qa_chain({"query": question})
return render_template('index.html', result=result)
return render_template('index.html')
if __name__ == "__main__":
app.run(host='0.0.0.0',debug=True,port=5000)
|