1. 认知提升
1.1 AI大模型是什么?
基础模型(Foundation Models)
一种大型机器学习模型,通常在大量数据上进行大规模训练(通过自监督学习或半监督学习),以使它可以适应各类下游任务。
兼顾参数量大(大型模型),训练数据量大(大量数据大规模训练)和迁移学习能力强(适应多种下游任务)
AIGC(Artificial Intelligence Generated Content)
通过“大模型”的上下文学习、涌现和思维链等能力支撑实现
1.2 AI大模型能做什么?
很好地应对如语言翻译、创意策划、文章创作和代码编写这类任务。
利用大模型平台先天具备的优异语言能力、意图识别能力和指令翻译能力,将互联网领域的各个能力接入其中,由AI大模型作为大脑,帮助各个应用互相对话。
1.3 具身智能要做什么?
具身智能
像人一样能与环境交互感知,自主规划、决策、行动的机器人
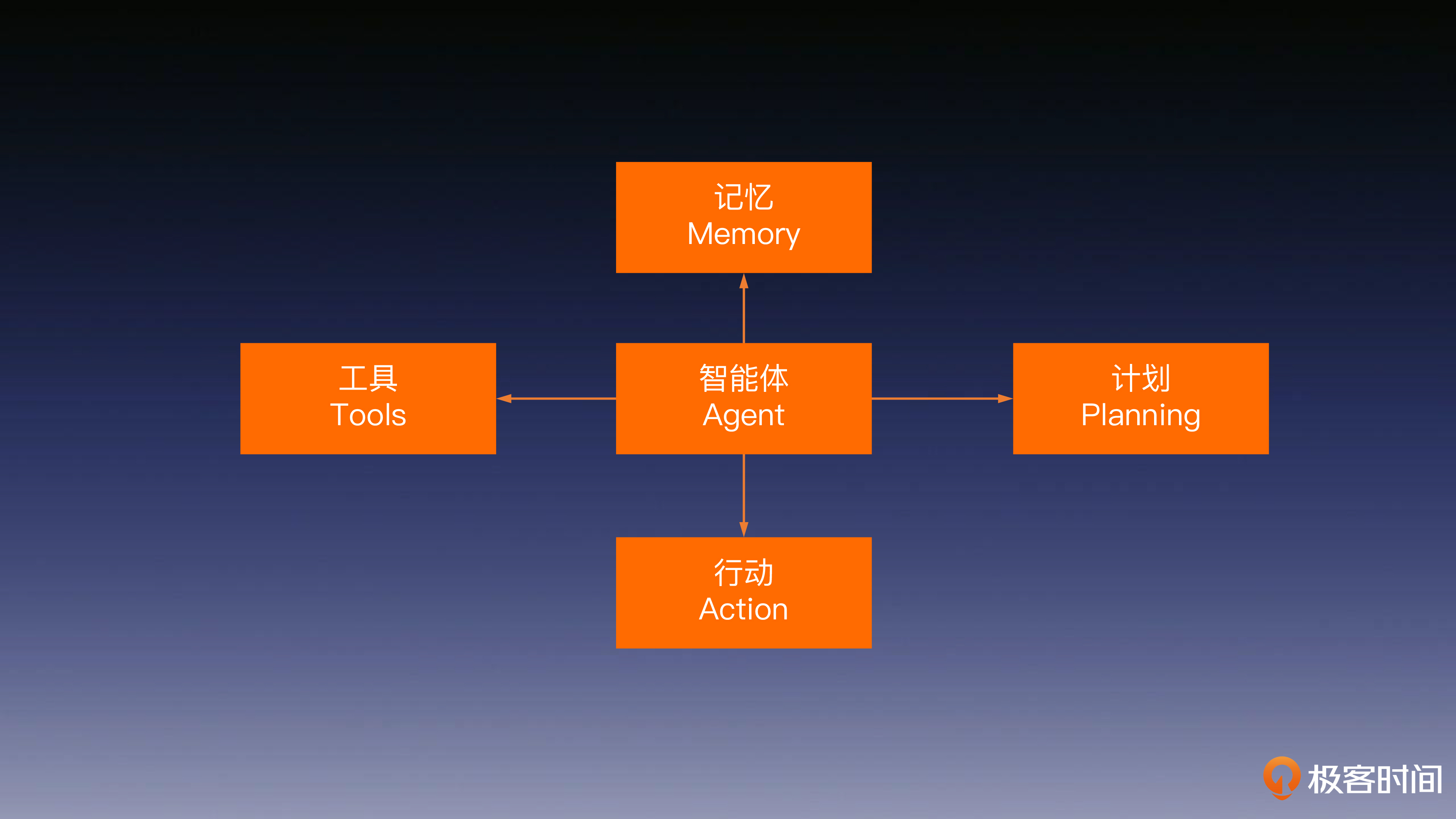
1.4 发展前景
智能体结构图:
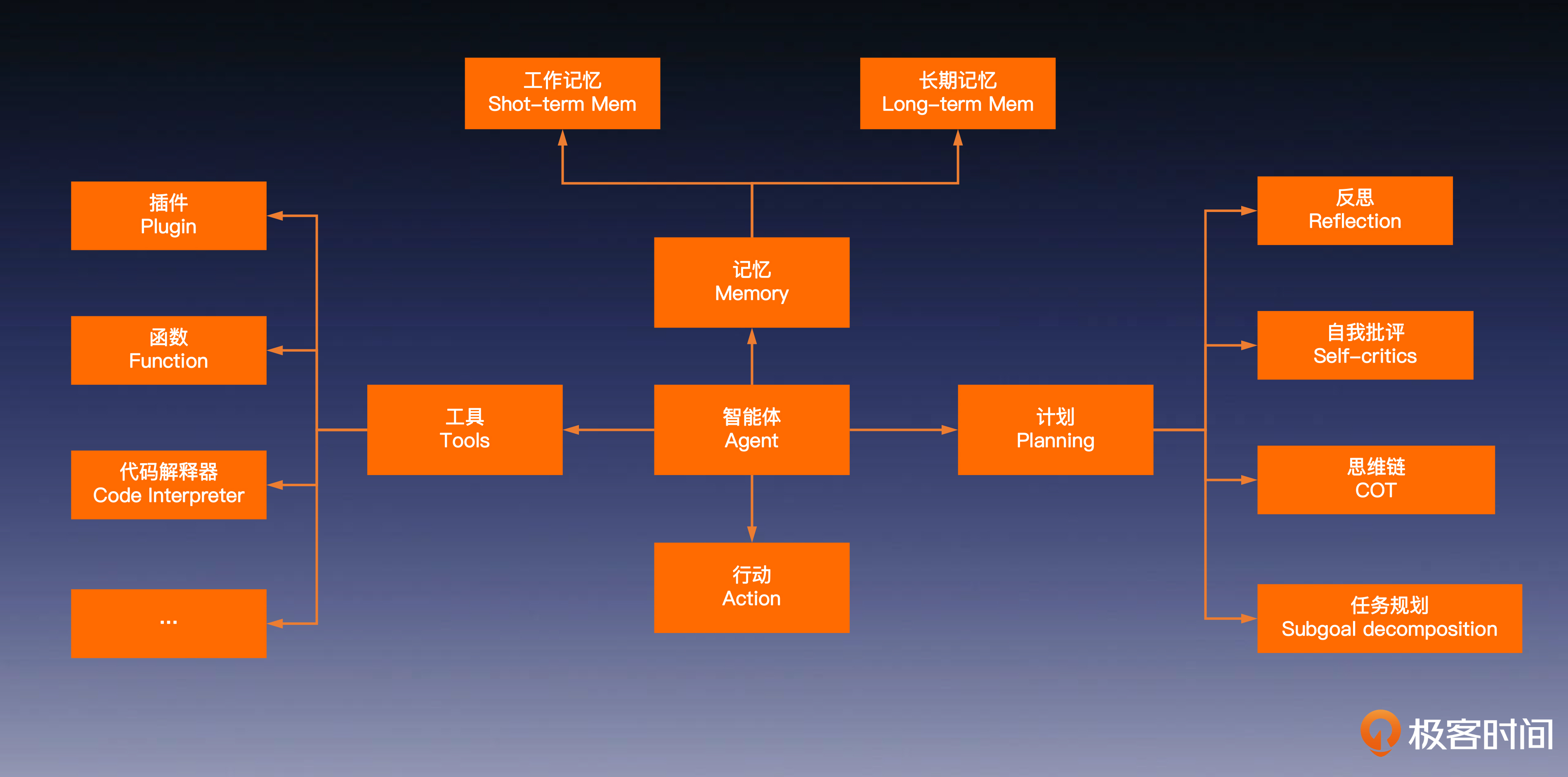
- 任务唤醒plan
- 记忆规划memory
- 驾驭工具tool
具身智能结构图:
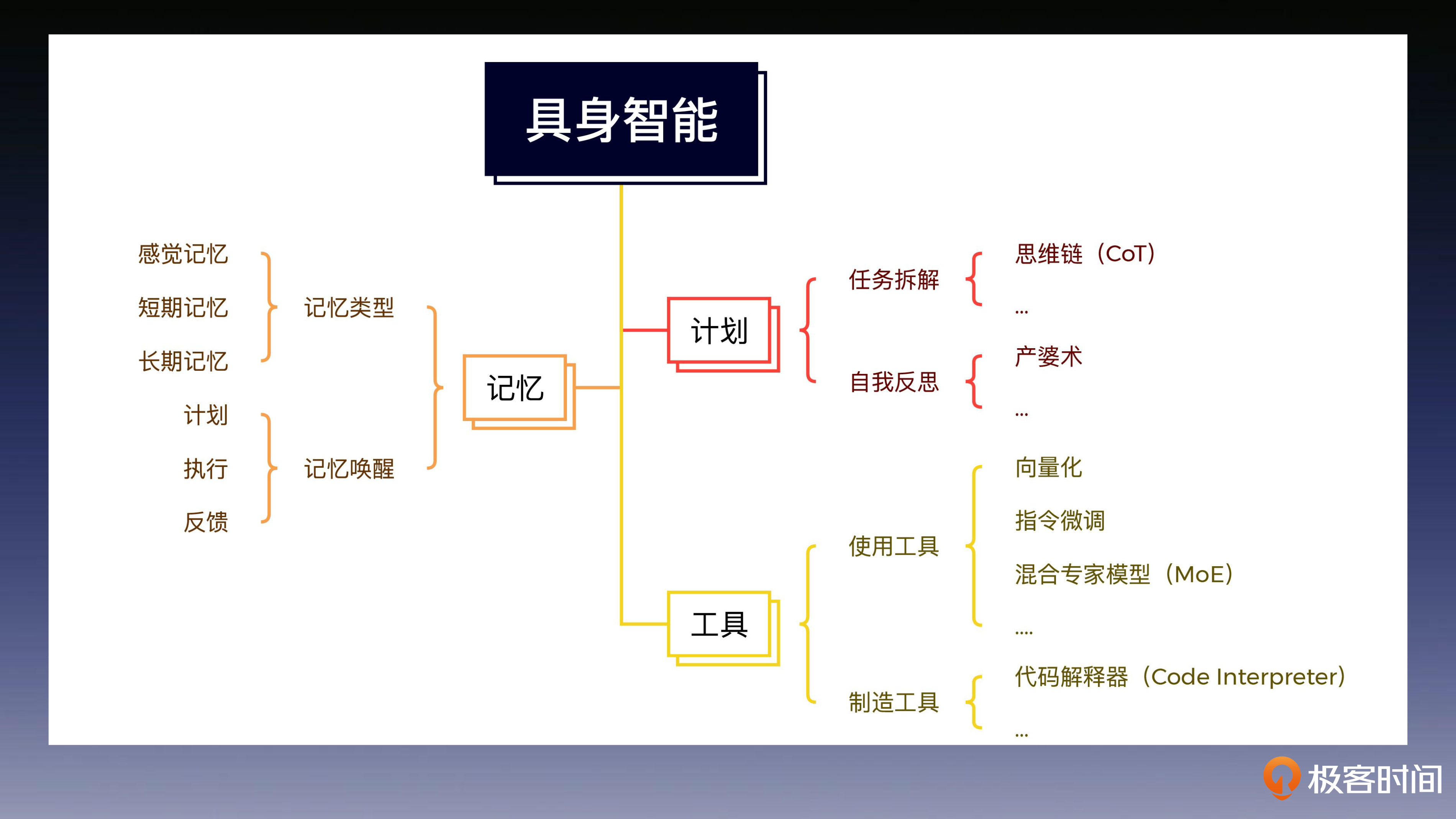
2. 原型搭建
2.1 开源工具
链式调用黏合剂(Langchain)
领域知识库(Embedding & 向量检索引擎)
Llama
AutoGPT
2.2 工业级大模型系统
三大误区
误区一:将LangChain和AutoGPT认作真正的LLM系统
误区二:将Embedding检索奉为记忆增强的“圭臬”
误区三:无视开源大模型的内容生成质量问题
如何构建工业级系统?
工业级 AI 大模型系统最鲜明的一个特征,就是针对自己的业务场景,基于数据驱动的业务系统框架去定制大模型,而不是使用别人“施舍”的通用大模型。
首先,我们需要学习AI系统的策略建模方法。思路是把业务问题转化为数学问题,然后对这些数学问题进行建模,最终将它们转化为工程问题。在这个过程中,你将学会如何根据不同的场景选择合适的模型算法。
在学习AI内容推荐服务时,你将掌握如何让你的系统轻松地应对在线真实场景,如何通过调整算法来灵活地控制在线指标。这些问题也是在线内容生成(AIGC)系统需要解决的。
如果想让你的系统在商业竞争中处于优势地位,就需要有针对性地设计系统模块,结合在线服务的特性来实现算法。这样,你的系统才可能成为商业竞争中有竞争力的智能体。这不仅关系到在线AI系统的盈利能力,也是让你的LLM应用走向具身智能的重要技能。
对于AIGC系统而言,为了避免过高的推理开销增加商业成本,模型小型化的方法也必不可少,这能大大降低在线推理的开销。
至于前面说的外部记忆问题,我们需要去学习如何构建一个工业级的检索增强系统。这个系统将成为提示引擎的主要外部记忆,也会成为可信AI的重要依据。该系统的数据来源正是AIRC系统中积累的强大知识表示和检索能力。
另外,安全可靠的风控模块也必不可少,这样AI系统才能拥有工业级的鲁棒性,确保你的商业系统能够在各种真实风险中稳定运行。
3. 内容推荐系统(AIRC)
指标建模-业务追求的终极目标
一、如何得到排序的概率值
二、如何对海量商品进行在线“实时”的排序,多路召回(关键词召回、用户画像召回、向量召回)、排序(粗排、精排、重排)
3.1 特征工程
特征工程的核心工作:特征处理的过程是对数据进行微观和宏观投影的过程
首先,怎样对特征进行微观投影,得到特征的特征。我们用非线性处理、特征组合处理和归一化处理等特征处理方法,让你的特征更好地服务于模型。
接下来,怎样把低维特征投射到高维空间。我们使用独热编码,将特征投射到高维空间,并保证它们在高维空间的独立性,避免对模型造成干扰。
最后,怎样在高维空间,刻画特征之间的语义关系,我们用对比学习的方法,刻画了高维空间中的特征距离,也就是单词之间的语义关系,进而让模型“抄近道”理解特征在现实世界中的关系。
3.2 模型工程
人工智能在学术上的三大学派,它们分别是符号主义学派、连接主义学派和行为主义学派,其中的代表分别是知识图谱、深度学习和强化学习。
监督学习(Supervised Learning)
在正确答案的指导下进行学习
对比学习(Contrastive Learning)
通过样本之间的相似度,来学习它们之间的距离,进而表示它们的关系
强化学习(Reinforcement learning)
利用感知和行动的闭环进行学习
3.3 数据算法
利用人类的经验把数据分成了主体数据、客体数据和环境数据这三类数据。比如在无人驾驶和车联网系统中,这三类数据对应的是车辆数据、交通流数据和环境数据。再比如AIRC系统,它利用数据包括用户特征、物品特征和场景特征。这些数据都遵循了主体、客体和环境这种划分方式。
用户
投其所好。构建用户画像
数据管理平台(Data Management Platform,DMP)对用户特征进行管理。
- 用户使用产品时产生的信息,其中包括用户个人注册信息,人群特征数据等等。
- 团队内部产品或者业务伙伴提供的数据。
- 数据供应商提供的数据,例如从BlueKai、秒针这类地方购买的数据。
DMP中会将用户基本信息(例如性别、年龄、职业),使用习惯和行为记录(例如点击、购买、收藏)等信息综合起来,生成用户画像。
对数据做“身份对齐”的能力,比如对同一人在多设备、多账号产生的数据做身份识别。
挖掘某个人群的“潜在用户”的能力,比如识别符合某个品牌产品调性的用户。
人群扩展算法(Look-alike)的三大作用:
- 挖掘潜在高净值用户。比如识别出与“保时捷”车主相似的用户,扩大推广活动的覆盖范围。
- 提高风控能力。比如通过用户相似行为和特征,发现黑灰产作案团伙,识别出潜在欺诈活动。
- 提高冷启动推荐效果。比如利用相似人的特征代表未知新用户,做出更准确的推荐决策。
GraphSAGE 是一个端到端的方案,能更好地保留图结构中的信息
将高维空间中与高净值用户距离最接近的那群人作为潜在用户
们只要找到足够相近的两个人,将他们近似识别成同一人
物品特征
知识图谱(KG):知识抽取、知识融合和知识加工

场景特征
来自于每一次流量请求中客户端提供的信息,被用于刻画用户触达应用时的全景信息,包括后面这些信息。
- 应用程序所处的界面(应用、页面、媒体位等)
- 用户的设备信息(信号强度、手机型号、电池电量等)
- 所在地点信息(城市、气温、邮编等)
- …
在处理场景特征时,我们需要将与用户长期习惯相关的数据放在用户画像中。那些随着场景变化频率较高的数据应该放在场景特征中。
实时特征:场景特征的最大价值,在于它在时间维度上的区分性和敏感性。例如“用户最近30分钟的商品点击数量”或“用户最近1小时浏览商品数量”这些实时特征都是非常重要的,它们会对推荐结果产生很大影响。为什么这么说呢?
这是因为用户画像和物料特征数据相对稳定,更新频率不高,如果不增加场景特征,模型的输入值很可能在一段时间内没有任何变化。因此,场景特征的输入可以让模型变得更加敏感。

3.4 系统构建
全量+增量系统架构:

存储索引系统:

实时特征存储:
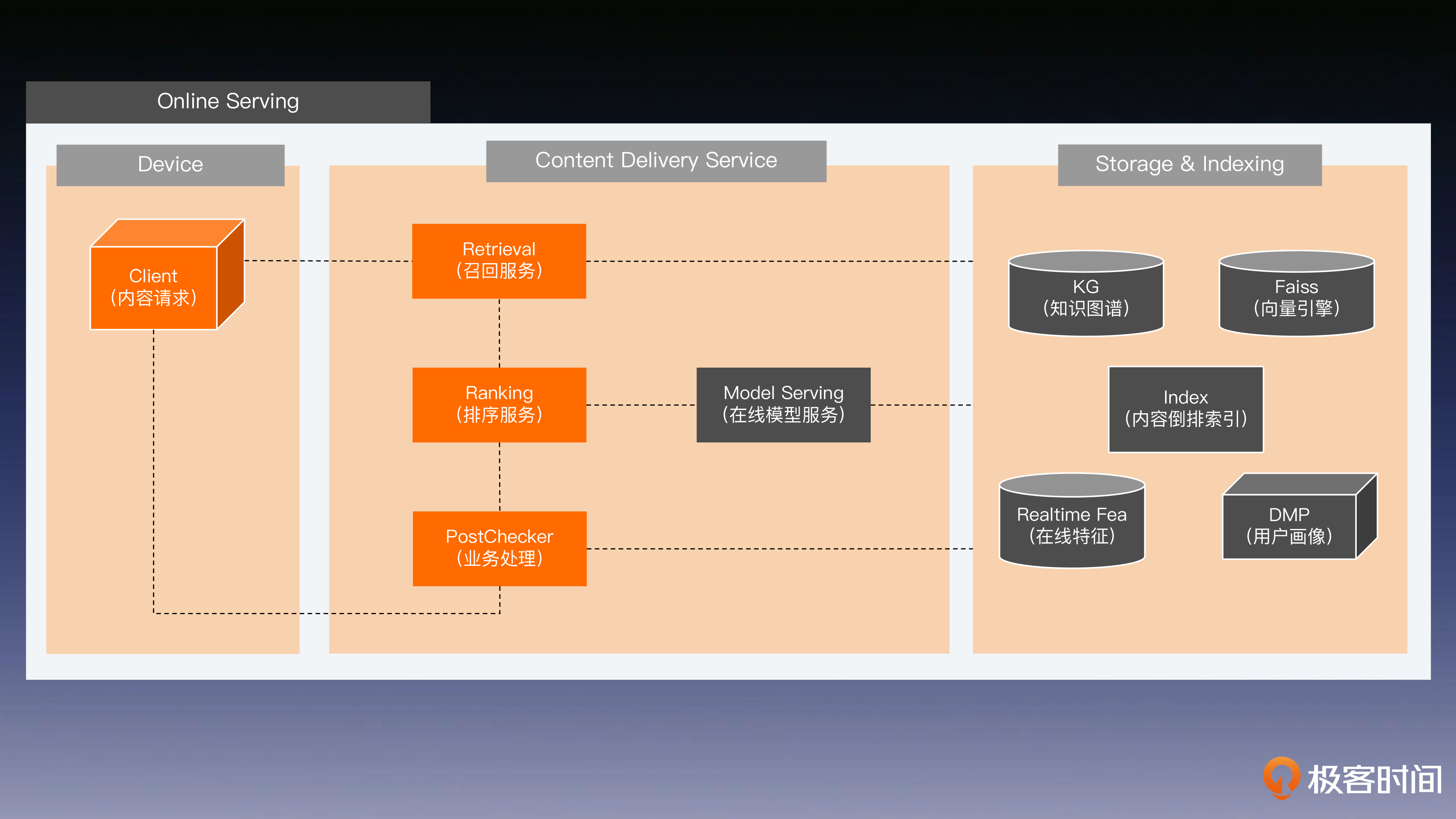
再总体理解下推荐系统:

4. 技术原理
4.1 视觉模型
CNN
平移不变形、边缘提取能力
AlexNet
ResNet
4.2 语言模型
循环神经网络(Recurrent Neural Network,RNN)
一种用于处理“序列数据”的神经网络模型
LSTM(Long short-term memory)模型
Seq2Seq
Word2Vec
ElMo(Embeddings from Language Models)
GPT
BERT
Transformer
5. 人工智能生成内容(AIGC)
人工智能生成内容