1. 魔搭社区
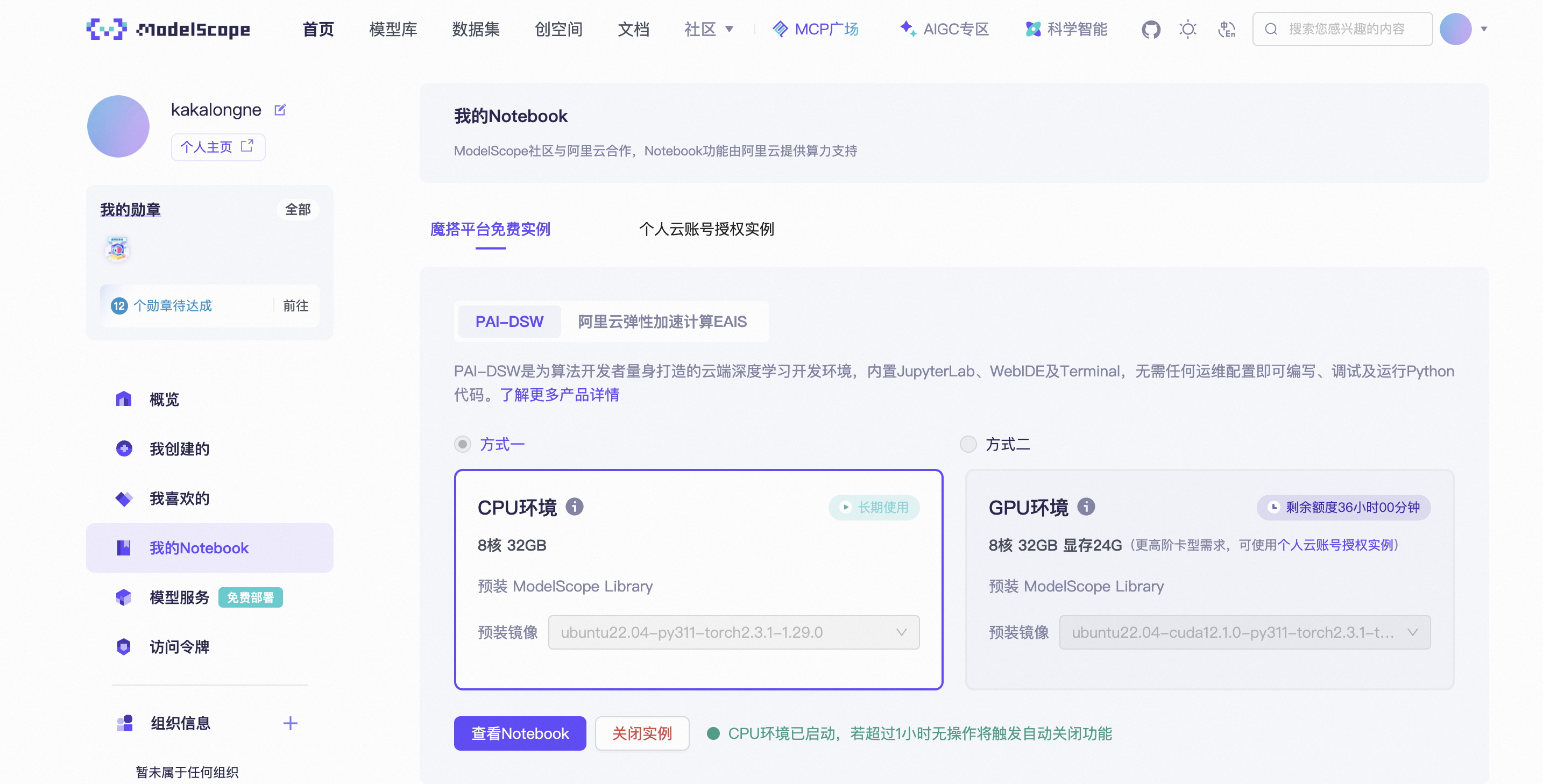
可以看到可以长期使用一个8c 32g的py环境,就想着把本地调试的工作放到社区提供的环境上。

2. 使用
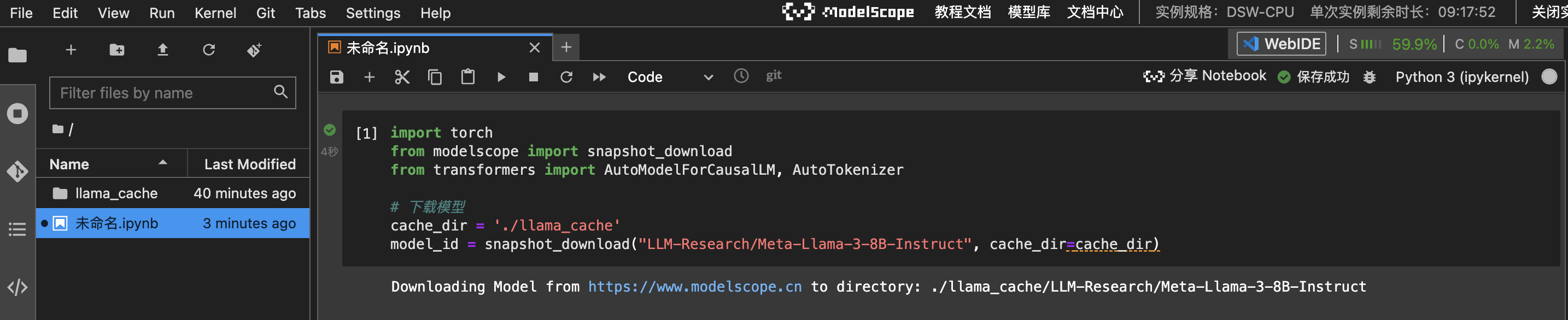
2.1 下载模型
1
2
3
4
5
6
7
| import torch
from modelscope import snapshot_download
from transformers import AutoModelForCausalLM, AutoTokenizer
cache_dir = './llama_cache'
model_id = snapshot_download("LLM-Research/Meta-Llama-3-8B", cache_dir=cache_dir)
|
2.2 运行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
cache_dir = './llama_cache'
model_path = cache_dir + '/LLM-Research/Meta-Llama-3-8B'
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16 if torch.cuda.is_available() else torch.float32,
device_map="auto" if torch.cuda.is_available() else None
)
input_text = "在一个阳光明媚的早晨,Alice决定去森林里探险。她走着走着,突然发现了一条小路。"
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=100)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)
|
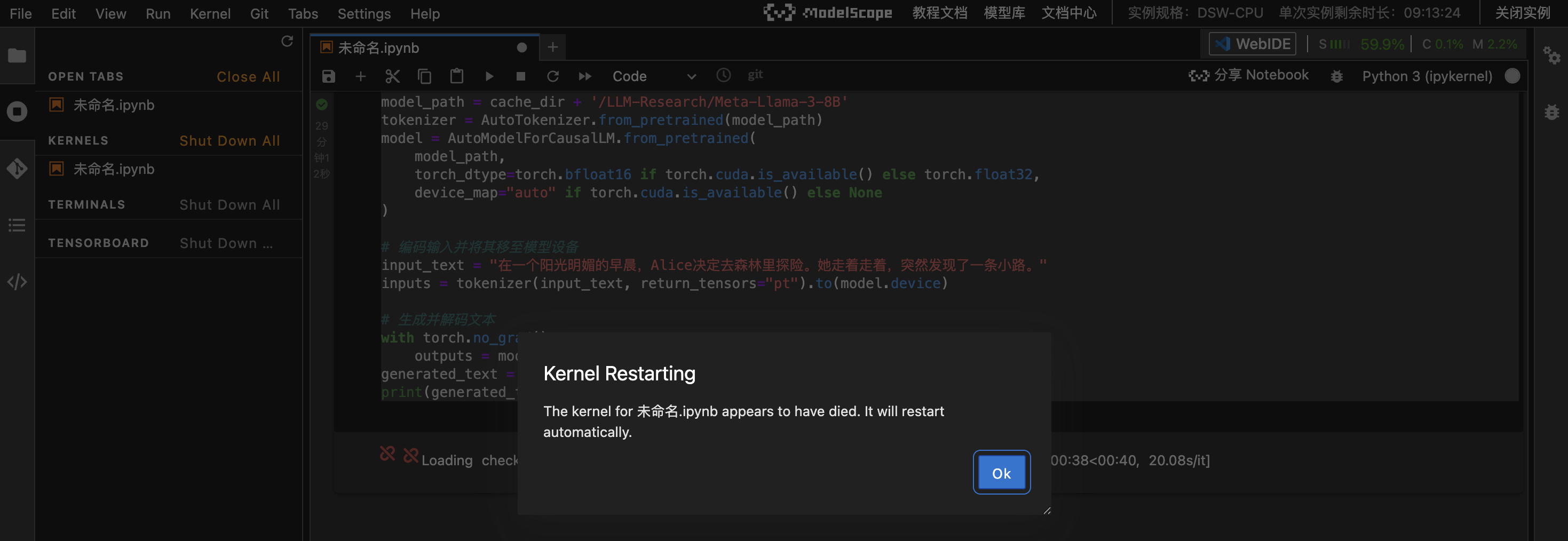
这个配置运行不起来;查询豆包运行这个模型的运行配置:
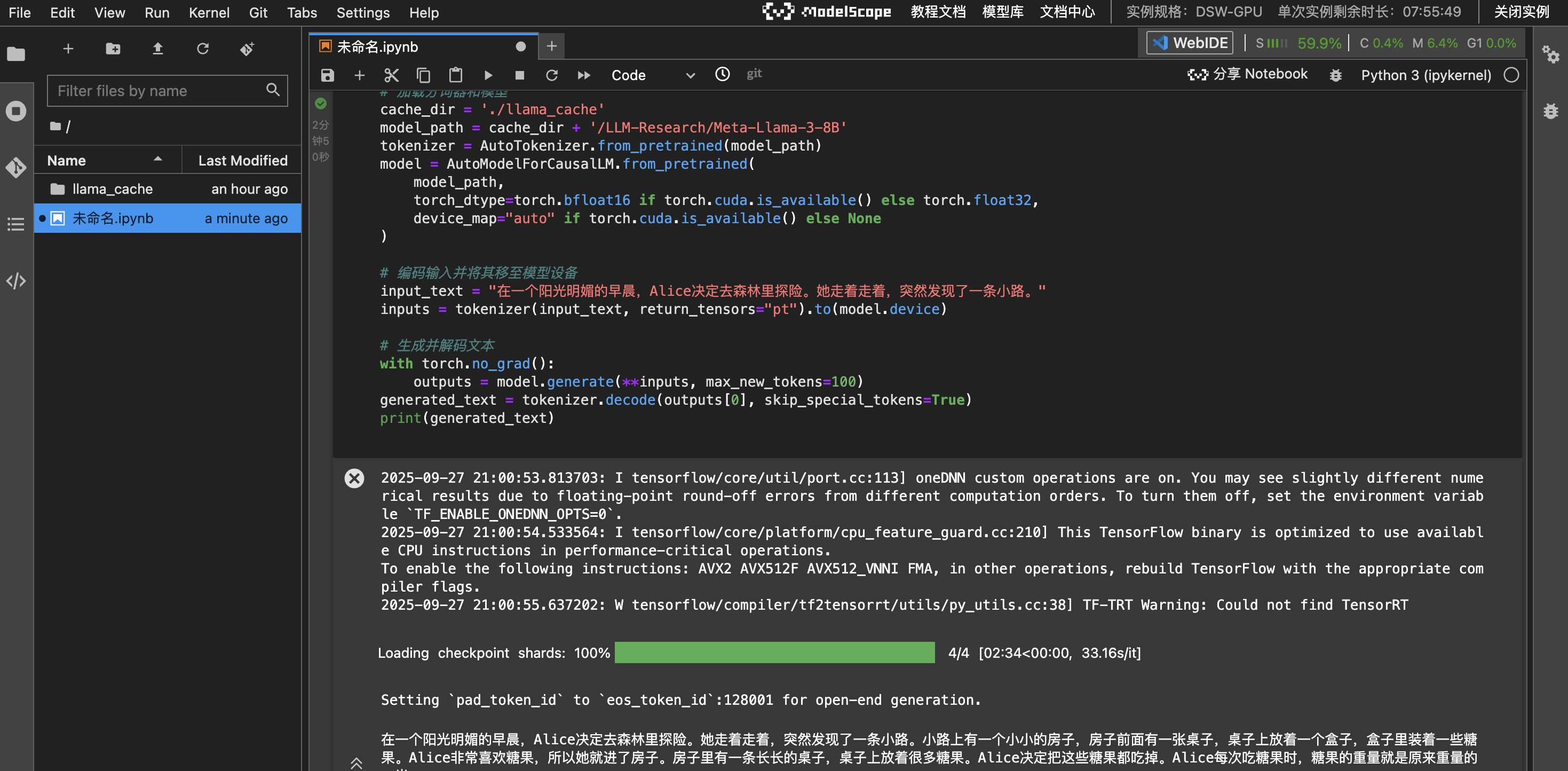
2.3 换GPU环境
很轻松运行出了结果
3. 最佳实践
- 将需要测试的项目都放入git仓库
- 本地修改后提交
- 在魔搭社区提供的cpu环境中拉取代码,下载模型
- 在GPU环境中,运行,实验