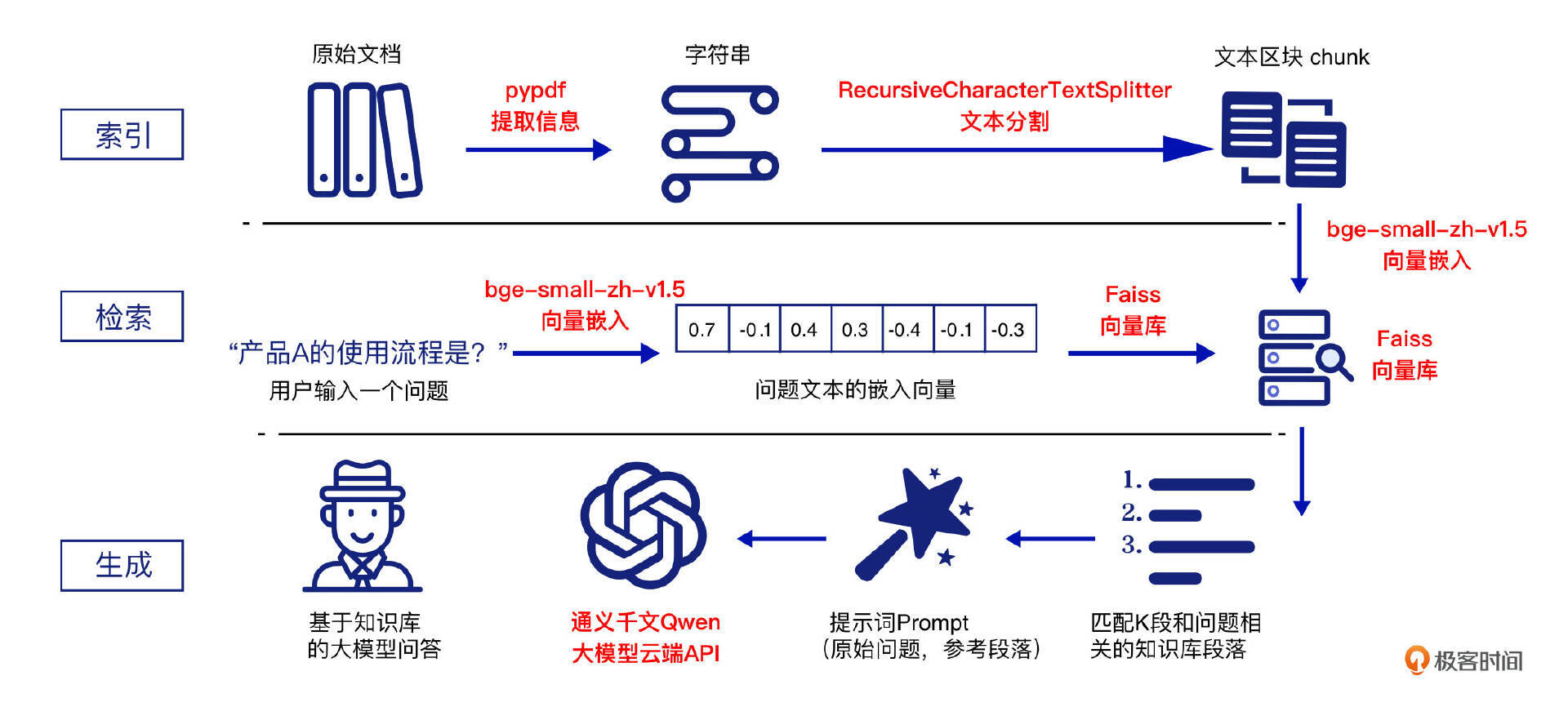
1. 技术框架与选型

1.1 RAG技术框架:LangChain
LangChain是专为开发基于大型语言模型(LLM)应用而设计的全面框架,其核心目标是简化开发者的构建流程,使其能够高效创建LLM驱动的应用。
1.2 索引流程 - 文档解析模块:pypdf
pypdf是一个开源的Python库,专门用于处理PDF文档。pypdf支持PDF文档的创建、读取、编辑和转换操作,能够有效提取和处理文本、图像及页面内容。
1.3 索引流程 - 文档分块模块:RecursiveCharacterTextSplitter
采用LangChain默认的文本分割器-RecursiveCharacterTextSplitter。该分割器通过层次化的分隔符(从双换行符到单字符)拆分文本,旨在保持文本的结构和连贯性,优先考虑自然边界如段落和句子。
1.3 索引/检索流程 - 向量化模型:bge-small-zh-v1.5
bge-small-zh-v1.5是由北京人工智能研究院(BAAI,智源)开发的开源向量模型。虽然模型体积较小,但仍然能够提供高精度和高效的中文向量检索。该模型的向量维度为512,最大输入长度同样为512。
此处改为请求text-embedding-v3
1
2
3
4
5
6
7
8
9
10
11
| import dashscope
input_texts = "衣服的质量杠杠的,很漂亮,不枉我等了这么久啊,喜欢,以后还来这里买"
embedding_model = "text-embedding-v3"
resp = dashscope.TextEmbedding.call(
model=embedding_model,
input=input_texts
)
if resp.status_code == 200:
embedding = resp.output['embeddings'][0]['embedding']
|
1.4 索引/检索流程 - 向量库:Faiss
Faiss全称Facebook AI Similarity Search,由Facebook AI Research团队开源的向量库,因其稳定性和高效性在向量检索领域广受欢迎。
1.5 生成流程 - 大语言模型:通义千问 Qwen
通义千问Qwen是阿里云推出的一款超大规模语言模型,支持多轮对话、文案创作、逻辑推理、多模态理解以及多语言处理,在模型性能和工程应用中表现出色。采用云端API服务,注册有1,000,000 token的免费额度。
2. 第一版代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
| from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
import dashscope
from http import HTTPStatus
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false"
qwen_model = "qwen-turbo"
qwen_api_key = "your_api_key"
def load_embedding_model():
"""
加载bge-small-zh-v1.5模型
:return: 返回加载的bge-small-zh-v1.5模型
"""
print(f"加载Embedding模型中")
embedding_model = SentenceTransformer(os.path.abspath('rag_app/bge-small-zh-v1.5'))
print(f"bge-small-zh-v1.5模型最大输入长度: {embedding_model.max_seq_length}")
return embedding_model
def indexing_process(pdf_file, embedding_model):
"""
索引流程:加载PDF文件,并将其内容分割成小块,计算这些小块的嵌入向量并将其存储在FAISS向量数据库中。
:param pdf_file: PDF文件路径
:param embedding_model: 预加载的嵌入模型
:return: 返回FAISS嵌入向量索引和分割后的文本块原始内容列表
"""
pdf_loader = PyPDFLoader(pdf_file, extract_images=False)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512, chunk_overlap=128
)
pdf_content_list = pdf_loader.load()
pdf_text = "\n".join([page.page_content for page in pdf_content_list])
print(f"PDF文档的总字符数: {len(pdf_text)}")
chunks = text_splitter.split_text(pdf_text)
print(f"分割的文本Chunk数量: {len(chunks)}")
embeddings = []
for chunk in chunks:
embedding = embedding_model.encode(chunk, normalize_embeddings=True)
embeddings.append(embedding)
print("文本块Chunk转化为嵌入向量完成")
embeddings_np = np.array(embeddings)
dimension = embeddings_np.shape[1]
index = faiss.IndexFlatIP(dimension)
index.add(embeddings_np)
print("索引过程完成.")
return index, chunks
def retrieval_process(query, index, chunks, embedding_model, top_k=3):
"""
检索流程:将用户查询Query转化为嵌入向量,并在Faiss索引中检索最相似的前k个文本块。
:param query: 用户查询语句
:param index: 已建立的Faiss向量索引
:param chunks: 原始文本块内容列表
:param embedding_model: 预加载的嵌入模型
:param top_k: 返回最相似的前K个结果
:return: 返回最相似的文本块及其相似度得分
"""
query_embedding = embedding_model.encode(query, normalize_embeddings=True)
query_embedding = np.array([query_embedding])
distances, indices = index.search(query_embedding, top_k)
print(f"查询语句: {query}")
print(f"最相似的前{top_k}个文本块:")
results = []
for i in range(top_k):
result_chunk = chunks[indices[0][i]]
print(f"文本块 {i}:\n{result_chunk}")
result_distance = distances[0][i]
print(f"相似度得分: {result_distance}\n")
results.append(result_chunk)
print("检索过程完成.")
return results
def generate_process(query, chunks):
"""
生成流程:调用Qwen大模型云端API,根据查询和文本块生成最终回复。
:param query: 用户查询语句
:param chunks: 从检索过程中获得的相关文本块上下文chunks
:return: 返回生成的响应内容
"""
llm_model = qwen_model
dashscope.api_key = qwen_api_key
context = ""
for i, chunk in enumerate(chunks):
context += f"参考文档{i+1}: \n{chunk}\n\n"
prompt = f"根据参考文档回答问题:{query}\n\n{context}"
print(f"生成模型的Prompt: {prompt}")
messages = [{'role': 'user', 'content': prompt}]
try:
responses = dashscope.Generation.call(
model = llm_model,
messages=messages,
result_format='message',
stream=True,
incremental_output=True
)
generated_response = ""
print("生成过程开始:")
for response in responses:
if response.status_code == HTTPStatus.OK:
content = response.output.choices[0]['message']['content']
generated_response += content
print(content, end='')
else:
print(f"请求失败: {response.status_code} - {response.message}")
return None
print("\n生成过程完成.")
return generated_response
except Exception as e:
print(f"大模型生成过程中发生错误: {e}")
return None
def main():
print("RAG过程开始.")
query="下面报告中涉及了哪几个行业的案例以及总结各自面临的挑战?"
embedding_model = load_embedding_model()
index, chunks = indexing_process('rag_app/test_lesson2.pdf', embedding_model)
retrieval_chunks = retrieval_process(query, index, chunks, embedding_model)
generate_process(query, retrieval_chunks)
print("RAG过程结束.")
if __name__ == "__main__":
main()
|
输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
| RAG过程开始.
PDF文档的总字符数: 9163
分割的文本Chunk数量: 24
文本块Chunk转化为嵌入向量完成
索引过程完成.
查询语句: 下面报告中涉及了哪几个行业的案例以及总结各自面临的挑战?
最相似的前3个文本块:
文本块 0:
面的数字化转型。
2.3.2 面临的挑战
在数字化转型之前,金融业案例中银行面临以下主要挑战:客户服务模式过时,主要依赖实
体网点,导致服务效率低、客户体验差;金融科技企业带来巨大竞争压力,凭借创新技术和
便捷服务吸引大量客户,尤其是年轻一代;数据孤岛和风险管理滞后,各业务部门缺乏数据
共享机制,导致信息无法整合,风险管理效率低。
2.3.3 数字化转型解决方案
为应对金融业案例挑战,银行实施了多方面的数字化转型措施:首先,构建数字化银行平台,
推出移动银行应用、在线服务、虚拟客服和智能理财顾问,显著提升了服务便捷性和客户满
意度;其次,引入人工智能和大数据分析技术,通过个性化金融产品推荐和实时风险监控,
提升客户服务质量和风险管理能力。
相似度得分: 0.5805433988571167
文本块 1:
发展和应用,企业在环境保护和可持续发展领域的能力将进一步增强,为全球的可持续发展
目标做出更大的贡献。这不仅有助于企业在激烈的市场竞争中保持领先地位,还将推动全社
会向着更加绿色、更加可持续的未来迈进。
1.3 总结
总的来说,数字化转型不仅是企业应对当前市场挑战的一种战略选择,更是通向未来的必由
之路。成功的数字化转型将帮助企业提升核心竞争力,优化客户体验,并在全球经济中获得
长期的可持续发展。
2. 案例分析
2.1 案例一:制造业的数字化转型
2.1.1 公司背景
制造业案例介绍了一家成立于 20 世纪初的德国老牌汽车制造公司,拥有悠久的历史和丰富
的制造经验。面对日益激烈的市场竞争和消费者需求的变化,公司意识到传统制造模式已无
法适应现代市场需求,因而决定实施全面的数字化转型,以保持竞争力。
2.1.2 面临的挑战
在数字化转型之前,制造业案例公司面临多重挑战:生产效率低下,传统制造流程依赖人工,
导致效率低且易出错;供应链复杂,涉及多个国家和地区,信息传递不及时,造成库存管理
困难,甚至存在供应链断裂的风险;客户需求变化快,传统大规模生产方式无法满足市场对
个性化定制产品的需求。
相似度得分: 0.5703892707824707
文本块 2:
统一、客户体验不一致,难以提供无缝购物体验;数据利用率低,尽管拥有大量消费者和销
售数据,但缺乏先进的数据分析工具,未能转化为可操作的商业洞察。
2.2.3 数字化转型解决方案
为了解决零售业案例的线上线下渠道割裂、数据利用率低、供应链效率低下和客户体验滞后
等问题,公司实施了一系列数字化转型措施:首先,构建全渠道零售平台,实现线上与线下
购物渠道的无缝整合,提升顾客的便利性和满意度;其次,引入大数据和人工智能驱动的分
析平台,精准预测需求、优化库存,并提供个性化产品推荐和营销活动。
2.3 案例三:金融业的数字化转型
2.3.1 公司背景
金融业案例中的金融机构是一家全球知名的银行,成立已有百年历史。随着金融科技
(FinTech)的迅速发展以及消费者对在线金融服务需求的增加,传统银行业务模式面临前
所未有的挑战。为了保持市场竞争力并满足客户日益增长的数字化需求,该银行决定开展全
面的数字化转型。
2.3.2 面临的挑战
在数字化转型之前,金融业案例中银行面临以下主要挑战:客户服务模式过时,主要依赖实
体网点,导致服务效率低、客户体验差;金融科技企业带来巨大竞争压力,凭借创新技术和
相似度得分: 0.5682079792022705
检索过程完成.
生成模型的Prompt: 根据参考文档回答问题:下面报告中涉及了哪几个行业的案例以及总结各自面临的挑战?
参考文档1:
面的数字化转型。
2.3.2 面临的挑战
在数字化转型之前,金融业案例中银行面临以下主要挑战:客户服务模式过时,主要依赖实
体网点,导致服务效率低、客户体验差;金融科技企业带来巨大竞争压力,凭借创新技术和
便捷服务吸引大量客户,尤其是年轻一代;数据孤岛和风险管理滞后,各业务部门缺乏数据
共享机制,导致信息无法整合,风险管理效率低。
2.3.3 数字化转型解决方案
为应对金融业案例挑战,银行实施了多方面的数字化转型措施:首先,构建数字化银行平台,
推出移动银行应用、在线服务、虚拟客服和智能理财顾问,显著提升了服务便捷性和客户满
意度;其次,引入人工智能和大数据分析技术,通过个性化金融产品推荐和实时风险监控,
提升客户服务质量和风险管理能力。
参考文档2:
发展和应用,企业在环境保护和可持续发展领域的能力将进一步增强,为全球的可持续发展
目标做出更大的贡献。这不仅有助于企业在激烈的市场竞争中保持领先地位,还将推动全社
会向着更加绿色、更加可持续的未来迈进。
1.3 总结
总的来说,数字化转型不仅是企业应对当前市场挑战的一种战略选择,更是通向未来的必由
之路。成功的数字化转型将帮助企业提升核心竞争力,优化客户体验,并在全球经济中获得
长期的可持续发展。
2. 案例分析
2.1 案例一:制造业的数字化转型
2.1.1 公司背景
制造业案例介绍了一家成立于 20 世纪初的德国老牌汽车制造公司,拥有悠久的历史和丰富
的制造经验。面对日益激烈的市场竞争和消费者需求的变化,公司意识到传统制造模式已无
法适应现代市场需求,因而决定实施全面的数字化转型,以保持竞争力。
2.1.2 面临的挑战
在数字化转型之前,制造业案例公司面临多重挑战:生产效率低下,传统制造流程依赖人工,
导致效率低且易出错;供应链复杂,涉及多个国家和地区,信息传递不及时,造成库存管理
困难,甚至存在供应链断裂的风险;客户需求变化快,传统大规模生产方式无法满足市场对
个性化定制产品的需求。
参考文档3:
统一、客户体验不一致,难以提供无缝购物体验;数据利用率低,尽管拥有大量消费者和销
售数据,但缺乏先进的数据分析工具,未能转化为可操作的商业洞察。
2.2.3 数字化转型解决方案
为了解决零售业案例的线上线下渠道割裂、数据利用率低、供应链效率低下和客户体验滞后
等问题,公司实施了一系列数字化转型措施:首先,构建全渠道零售平台,实现线上与线下
购物渠道的无缝整合,提升顾客的便利性和满意度;其次,引入大数据和人工智能驱动的分
析平台,精准预测需求、优化库存,并提供个性化产品推荐和营销活动。
2.3 案例三:金融业的数字化转型
2.3.1 公司背景
金融业案例中的金融机构是一家全球知名的银行,成立已有百年历史。随着金融科技
(FinTech)的迅速发展以及消费者对在线金融服务需求的增加,传统银行业务模式面临前
所未有的挑战。为了保持市场竞争力并满足客户日益增长的数字化需求,该银行决定开展全
面的数字化转型。
2.3.2 面临的挑战
在数字化转型之前,金融业案例中银行面临以下主要挑战:客户服务模式过时,主要依赖实
体网点,导致服务效率低、客户体验差;金融科技企业带来巨大竞争压力,凭借创新技术和
生成过程开始:
根据提供的参考文档,报告中涉及了以下**三个行业**的案例,并分别总结了各自面临的挑战:
---
### 1. **金融业**
- **面临的主要挑战:**
- 客户服务模式过时,主要依赖实体网点,导致服务效率低、客户体验差;
- 金融科技企业带来巨大竞争压力,凭借创新技术和便捷服务吸引大量客户,尤其是年轻一代;
- 数据孤岛和风险管理滞后,各业务部门缺乏数据共享机制,导致信息无法整合,风险管理效率低。
---
### 2. **制造业**
- **面临的主要挑战:**
- 生产效率低下,传统制造流程依赖人工,导致效率低且易出错;
- 供应链复杂,涉及多个国家和地区,信息传递不及时,造成库存管理困难,甚至存在供应链断裂的风险;
- 客户需求变化快,传统大规模生产方式无法满足市场对个性化定制产品的需求。
---
### 3. **零售业**
- **面临的主要挑战:**
- 线上线下渠道割裂,客户体验不一致,难以提供无缝购物体验;
- 数据利用率低,尽管拥有大量消费者和销售数据,但缺乏先进的数据分析工具,未能转化为可操作的商业洞察。
---
### 总结:
这三个行业(**金融业、制造业、零售业**)在数字化转型前都面临着**效率低下、客户体验不足、数据利用不充分或供应链管理困难**等共性问题,同时也各有其特定的挑战。
生成过程完成.
RAG过程结束.
|