1. LangChain是什么?
1.1 为什么要了解LangChain?
近两年来,大语言模型(如ChatGPT、DeepSeek、Claude)持续火爆,从写文案、AI绘图,到写代码、AI智能客服,几乎“无所不能”。并且大语言模型的调用成本越来越低,作为程序员的你可能已经开始尝试用OpenAI、DeepSeek的API做些小应用,但是很快可能就会遇到一些问题:
- 提示词(Prompt)无法复用,而且内容过长不易管理。
- 每个大模型都有自己的API,想用多个模型切换很困难,代码耦合很严重。
- 想自己实现复杂功能,比如多轮对话、工具调用、知识库等功能,导致逻辑混乱。
- 不同的Prompt、大模型、工具的使用没有统一规范。
因此,LangChain 就出现了,它可以帮助开发者把模型调用、提示词管理、记忆模块、外部工具调用等等模块标准化,不同的模块可自由组合。
1.2 LangChain是什么?
LangChain 是一个基于Python语言的大语言模型应用开源框架,LangChain可以帮你快速搭好项目架构,下图为LangChain技术体系的示意图。
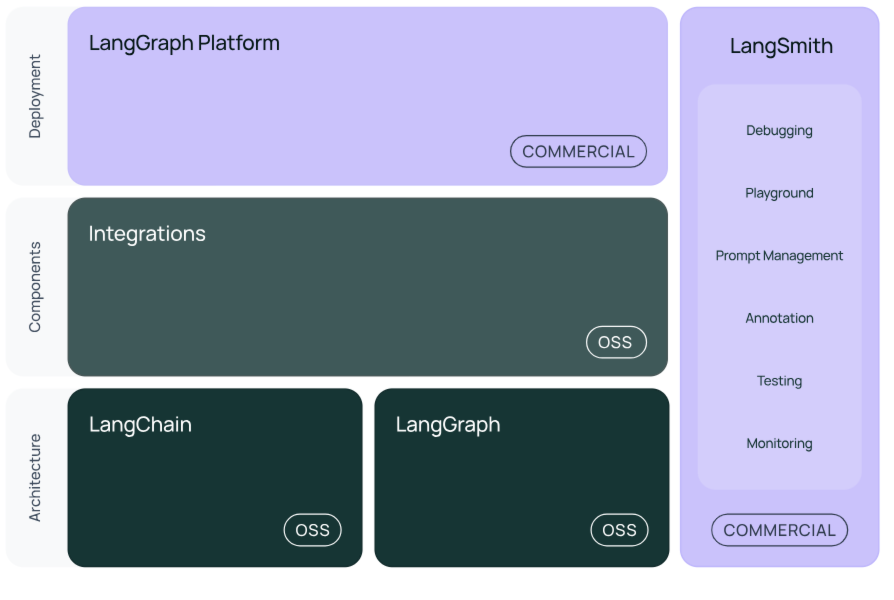
- LangChain技术体系主要包括以下模块:
- langchain-core : 封装好的基础聊天模型和其他组件。
- integrations:LangChain集成包,目前LangChain会将一些重要的集成包单独拆分出来(例如 langchain-openai , langchain-anthropic 等),让集成包更轻量级,这些包将会由LangChain团队和集成包的开发者共同维护。
- langchain : 构成AI应用的链、AI agent和检索器。
- langchain-community : 社区维护的第三方集成包。
- langgraph : LangGraph 专门用于构建能处理 复杂任务流程的 AI 应用。它的核心思想是用 “图”(Graph) 来管理任务流程,就像画一张路线图,让 AI 知道何时该执行什么操作、何时需要循环或分支判断,还能自动记住执行到哪一步了。
- langsmith:LangSmith 是 LLM 应用的全生命周期管理平台,覆盖开发→测试→部署→监控全流程,可以观察到AI应用运行的每一个步骤,它与 LangChain深度集成,但它不仅适用于 LangChain,也可以用于监控任何使用 LLM 的应用。
LangChain 目前支持两个主要版本:
- Python 版(最成熟,社区最大)
- JavaScript/TypeScript 版(适合前端和Node.js应用)
1.3 LangChain核心模块简介
在学习LangChain前,先了解一些在LangChain框架中,甚至AI应用开发中一些核心的概念和模块,一定要首先清楚地知道是什么,之后再研究怎么做,下图展示了一个LangChain框架开发的应用的核心运行流程。
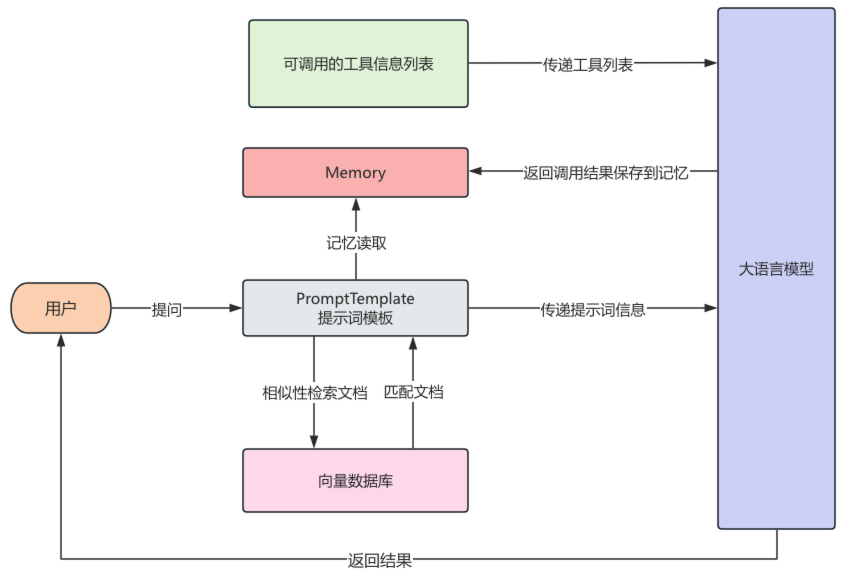
1.3.1 LLM接口
LangChain 封装了不同模型的调用方式,它统一了各种模型的接口,切换不同模型变得轻松。如下示例,创建了一个gpt-3.5-turbo的LLM模型。
1 | from langchain_community.chat_models import ChatOpenAI |
1.3.2 PromptTemplate提示词模板
大模型的输出质量在很大程度上取决于提示词(Prompt)的设计,在LangChain 把提示词封装成模板,支持变量动态替换,管理起来更清晰,能灵活控制 Prompt 内容,避免硬编码。
如下示例,一个模板中包含了两条消息,分别是人类消息和系统消息,并且设置了name和question两个动态变量,使用invoke方法进行动态替换,这里invoke之后返回的是渲染后Prompt的内容。
1.3.3 Chain链
Chain链是 LangChain 的核心思想之一,一个 Chain 就是将多个模块串起来完成一系列操作,Chain链可以将上一步操作的结果交给下一步进行执行,比如用提示词模板生成 Prompt,将渲染后的提示词交给大模型生成回答,再将大模型的回答将结果输出到控制台,Chain和Linux中的管道符十分类似,每一步的输出自动作为下一步输入,实现模块串联。
如下是Chain链的基本实例,它将提示词模板、LLM、输出解析器连接在一起。
1 | prompt = ChatPromptTemplate.from_template("{question}") |
1.3.4 RAG检索
在一些LLM的使用场景,需要使用一些特定的文档让LLM根据这些文档的内容进行回复,而这些特定的文档通常不在LLM的训练数据中,此时RAG检索就有用武之地。
在LangChain中,可以读取文档作为大模型的知识库,来进行增强搜索,LangChain封装各种类型的文档读取器,可以将读取文档得到的数据,通过LangChain文档分割器对文档进行分割,通过文本嵌入模型对文本进行向量化,将文本的向量信息保存到向量数据库。
当用户向AI发起提问时,在向量数据库中检索出与提问相关的文档,然后与用户问题一起发送给大模型,这个过程就叫做RAG(检索增强生成,Retrieval-Augmented Generation),RAG 能让大模型回答特定领域的问答变得更加精准、实时,避免出现幻觉。
下面代码示例,展示了LangChain中提供了文档读取相关加载类,对项目API文档进行读取。
1 | from langchain_community.document_loaders import TextLoader |
1.3.5 Memory记忆
在和大模型对话时,大模型本身并不具备有记忆历史对话的功能,但是在使用ChatGPT、DeepSeek等大模型时,发现它们在同一个会话内有“上下文记忆”的能力,这样能使对话更加连贯。
LangChain 也提供了类似的记忆功能。通过 memory,可以把用户的历史对话保存下来,使大模型拥有历史记忆的能力,如下示例,每一轮对话会从ConversationSummaryBufferMemory中读取历史对话,渲染到Prompt供大模型使用。
对话结束之后,会将对话内容保存到ConversationSummaryBufferMemory,如果历史记忆超过一定大小,为了节省和大模型之间调用的token消耗,会对历史记忆进行摘要提取、压缩之后再保存,这样大模型拥有了记忆功能。
1 | prompt = ChatPromptTemplate.from_messages([ |
1.3.6 Tool工具调用
大语言模型本身是一种基于大量数据训练而成的人工智能,它本身是基于大量的数据为基础对结果进行预测,因此,大模型可能会出现给出1+1=3这种情况,大模型本身是不会“上网”, 也不会算数的,因此,可以给大模型接入各种各样的工具如Google搜索、高德地图定位信息查询、图像生成等等。
那么大模型是怎么使用工具的呢?在现如今,很多的大模型都支持了工具调用,也就是将可用的工具信息列表在调用大模型时传递过去,这些信息包括工具的用途、参数说明等等,大模型会根据这些工具的作用确定调用哪些工具,并且根据参数的描述,来返回调用工具的参数。
最终将工具调用结果返回给大模型,完成用户交给的任务,整个过程中,大模型会根据任务判断是否调用工具,并组织执行,这个自动决策执行的过程,就是由 agent 完成的。
agent 会自己思考、分步骤执行,非常适合复杂任务处理,后续我们也会深入介绍如何通过 LangChain 创建一个完整的 agent,自动协调多个工具完成复杂任务。
对于那些不支持工具调用的大模型,也可以根据提示词将可选的工具和调用方法传递给大模型,但是大模型的预测有很强的不确定性,返回结果的准确率会显著下降。
1.4 总结
LangChain 是一个强大又灵活的大模型开发框架,它将 LLM 的调用和创建、提示词管理、记忆、知识库、RAG检索、工具调用等模块化,通过LangChain可以快速构建 AI 应用。
如果你在使用不同厂商的 LLM API 时,写出了难以维护的代码,那么LangChain就是你最好的选择,本文主要介绍了LangChain框架是什么以及它的核心模块,接下来我们将深入介绍 LangChain 中的每个模块。
2. 开发环境配置
2.1 LangChain中的包
1 | pip install langchain |
下图表示了LangChain包之间的依赖关系:
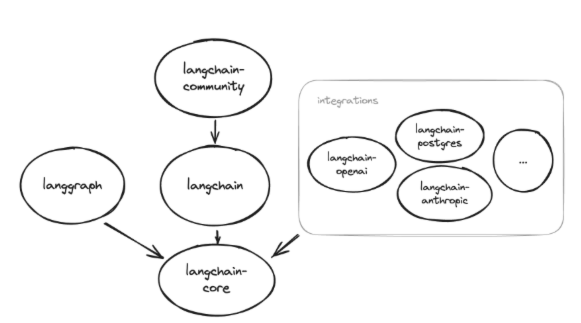
- langchain-core:除 langsmith 外,LangChain 中的其他所有包都依赖于该核心包,它提供了所有模块共享的基础类。
- langchain:包含了langchain-core。
- langchain-openai:OpenAI 相关工具的集成包
- langchain-community:尚未独立拆分的第三方集成包。
- langgraph:基于图的任务流程管理工具包,可以和LangChain无缝集成,也可以不使用LangChain单独安装
- langsmith:LLM 应用的全生命周期管理平台,既可以与 LangChain 配合使用,也可以独立用于非 LangChain 的大模型应用场景。
2.2 项目创建
2.2.1 使用conda创建虚拟环境
1 | conda create -n langchain-study310 python=3.10 |
2.2.2 Pycharm配置虚拟环境
2.2.3 依赖管理
首先,创建依赖管理文件 requirements.txt
1 | touch requirements.txt |
在 requirements.txt 中添加 LangChain 所需依赖,其中 python-dotenv 用于加载 .env 环境变量配置。
1 | langchain==0.2.17 |
导入依赖
1 | pip install -r requirements.txt |
2.2.4 创建配置文件
在项目根目录下创建 .env 文件,添加 OpenAI 的 API 地址和密钥
1 | # OpenAI大模型 |
2.3 第一个聊天机器人
新建一个 Python 文件,就可以开始编写第一个聊天机器人程序了。
代码如下:
1 | import dotenv |
输出:
1 | 以下是《三国演义》中综合实力(结合武艺、智谋、统帅、影响力等因素)最强的十位人物,按历史贡献和文学描写进行简要评述: |
2.4 总结
本文介绍了LangChain框架的包依赖结构及其模块划分,明确了主包 langchain 与核心包 langchain-core、第三方集成包如 langchain-openai 和 langchain-community 之间的关系,并简要介绍了 langgraph 和 langsmith 这两个生态工具的功能与使用场景。
在项目实操部分,我们从零开始搭建了一个LangChain开发环境,涵盖了虚拟环境的创建、依赖版本管理、PyCharm解释器配置及.env配置文件的设置,并通过一个简单的聊天机器人示例,展示了 LangChain 与 OpenAI 模型的基础集成流程。
通过本文,相信你应该已经掌握了如何快速构建一个基于LangChain的Python开发环境,构建自己的第一个AI应用。
3. PromptTemplate提示词模板
3.1 提示词模板分类
- LangChain 提供了多种不同的提示词模板,下面介绍几种常用的提示词模板:
- PromptTemplate:文本生成模型提示词模板,用字符串拼接变量生成提示词
- ChatPromptTemplate:聊天模型提示词模板,适用于如 gpt-3.5-turbo、gpt-4 等聊天模型
- HumanMessagePromptTemplate:人类消息提示词模板
- SystemMessagePromptTemplate:系统消息提示词模板
- FewShotPromptTemplate:少量示例提示词模板,自动拼接多个示例到提示词中,例:1+1=2,2+2=4,让大模型去计算5+5等于多少。
3.2 提示词模板用法
3.2.1 PromptTemplate文本提示词模板
PromptTemplate 针对文本生成模型的提示词模板,也是LangChain提供的最基础的模板,通过格式化字符串生成提示词,在执行invoke时将变量格式化到提示词模板中,示例如下:
1 | from langchain_core.prompts import PromptTemplate |
执行结果:
1 | text='你是一个专业的律师,请你回答我提出的法律问题,并给出法律条文依据,我的问题是:婚姻法是在哪一年颁布的?' |
3.2.2 ChatPromptTemplate聊天消息提示词模板
ChatPromptTemplate 是专为聊天模型(如 gpt-3.5-turbo、gpt-4 等)设计的提示词模板,它支持构造多轮对话的消息结构,每条消息可指定角色(如系统、用户、AI)。
代码示例如下,提示词模板中包含两条消息,第一条是系统消息,无需做提示词渲染,第二条是人类消息,在执行invoke时,需要把变量question渲染进去。
1 | from langchain_core.prompts import ChatPromptTemplate |
执行结果:
1 | messages=[SystemMessage(content='你是一个资深的Python应用开发工程师,请认真回答我提出的Python相关的问题'), HumanMessage(content='请写一个Python程序,关于冒泡排序')] |
3.2.3 Prompt三个常用方法区别
上述的代码示例中,我们使用了invoke方法,除了invoke方法能够格式化提示词模板,format()和partial()方法也可以做到,以下是它们的作用:
- format:格式化提示词模板为字符串
- partial:格式化提示词模板为一个新的提示词模板,可以继续进行格式化
- invoke:格式化提示词模板为PromptValue
- format() 方法用法如下,将 question 参数格式化到提示词模板中,返回一个字符串:
1 | from langchain_core.prompts import ChatPromptTemplate |
执行结果:
1 | System: 你是一个资深的Python应用开发工程师,请认真回答我提出的Python相关的问题,并确保没有错误 |
partial()方法用法如下,可以格式化部分变量,并且继续返回一个模板
1 | from datetime import datetime |
执行结果:
1 | System: 你是一个资深的Python应用开发工程师,请认真回答我提出的Python相关的问题,并确保没有错误 |
3.2.4 MessagesPlaceholder消息占位符
如果我们不确定消息何时生成,也不确定要插入几条消息,比如在提示词中添加聊天历史记忆这种场景,可以在ChatPromptTemplate添加MessagesPlaceholder占位符,在调用invoke时,在占位符处插入消息。
1 | prompt = ChatPromptTemplate.from_messages([ |
执行结果:
1 | Human: 我的名字叫大志,是一名程序员 |
隐式使用MessagesPlaceholder方法
1 | prompt = ChatPromptTemplate.from_messages([ |
执行结果:
1 | Human: 我的名字叫大志,是一名程序员 |
3.2.5 PromptValue提示值
PromptValue 是提示词模板 .invoke() 执行后返回的中间对象,支持将提示词转换为字符串或消息列表传递给 LLM。主要包含两个方法:
to_string:将提示词转换为字符串
to_messages:将提示词转换为消息列表。普通 PromptValue 调用该方法会将整个字符串包装成一条人类消息;ChatPromptValue是PromptValue的子类,ChatPromptValue 会返回完整的消息列表(系统、人类、AI消息 等)
PromptValue这个中间类的存在的作用在于:适配不同LLM的输入要求,因为聊天模型需要输入消息,文本生成模型则需要输入字符串,PromptValue能够自由转换为字符串或消息,以适配不同 LLM 的输入要求,并且保持接口一致、逻辑清晰、易于维护。
3.2.6 加号连接提示词模板
PromptTemplate重载了+号运算符,因此可以使用+将两个提示词模板进行连接,连接成一个提示词模板,通过 + 操作符将多个提示词模板组合,可以实现提示词的模块化、动态拼接,提升代码复用率和维护性。
1 | from langchain_core.prompts import ChatPromptTemplate |
执行结果:
1 | System: 你是OpenAI开发的大语言模型,下面所有提问你扮演小米雷军的角色,对我的提问进行回答 |
或者直接使用模板和字符串进行连接
1 | chat_prompt = ChatPromptTemplate.from_messages([ |
执行结果:
1 | System: 你是OpenAI开发的大语言模型,下面所有提问你扮演小米雷军的角色,对我的提问进行回答 |
3.3 完整示例
下面是一个完整的案例,使用了ChatPromptTemplate的用法,目前只需要关注Prompt相关的代码即可,其他相关代码后续文章会展开讲解。
1 | from datetime import datetime |
执行结果:
1 | (微笑)我是雷军,小米公司的创始人。现在是2025年,说到最好的手机品牌,我当然是推荐小米啦!我们一直在追求极致的技术创新,比如最新的小米15系列就搭载了突破性的影像技术和更智能的AI系统。不过说实话,现在各大品牌都在进步,关键还是要看哪款手机更适合你的需求。 |
3.4 总结
本文介绍了用来构建文本生成模型的提示词模板 PromptTemplate 、 构建对话模型的提示词模板 ChatPromptTemplate,在ChatPromptTemplate中还可以使用MessagesPlaceholder 占位符灵活的插入动态信息。
还介绍了PromptTemplate类中三种方法的作用 invoke、format、partial ,最后介绍了用+号连接多个PromptTemplate。
提示词模板是LangChain 中非常核心的模块,它可以让AI能够更加清晰理解我们的意图,通过提示词模板的复用、拼接,能大大简化使用LLM的工作量,通过本文,相信你应该已经掌握了如何使用提示词模板。
4. 10分钟优雅接入主流大模型
4.1 Model的分类
LangChain中将大语言模型分为:文本生成模型(LLMs)和支持多轮对话的聊天模型(Chat models)。
聊天模型:接受消息输入,并且输出消息,返回的消息封装为不同类型的 BaseMessage 实例, LangChain 也允许聊天模型以字符串作为输入。这样做可以轻松地用聊天模型代替 LLMs,当以字符串作为输入时,该字符串会被转换为 HumanMessage ,然后传递给底层聊天模型。
文本生成模型:接受字符串输入,并且输出字符串,LangChain 也允许文本模型也以“消息”作为输入,从而与聊天模型的接口保持一致。当以消息作为输入时,这些消息会在传递给LLM之前被转换为字符串。
在 LangChain 的类结构中,顶层基类是 BaseLanguageModel,用于定义模型的通用接口。它分为两支:BaseChatModel 和 BaseLLM。接入聊天模型时需继承 BaseChatModel,如常用的 ChatOpenAI;而文本生成模型则继承 BaseLLM,如 OpenAI。
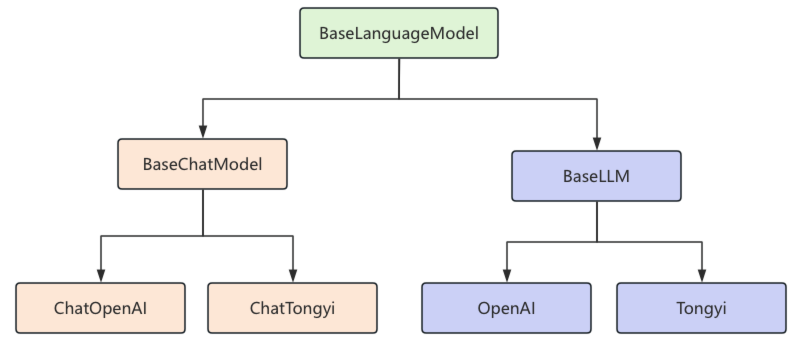
4.2 Chat Model聊天模型
在构建聊天模型时,有一些标准化参数:
| 参数名 (Parameter Name) | 参数含义 (Description) |
|---|---|
model |
指定使用的大语言模型名称(如 “gpt-4”、”gpt-3.5-turbo” 等)。 |
temperature |
温度,温度越高,输出内容越随机;温度越低,输出内容越确定。 |
timeout |
请求超时时间。 |
max_tokens |
生成内容的最大 token 数。 |
stop |
模型在生成时遇到这些 “停止词” 将立刻停止生成,常用于控制输出的边界。 |
max_retries |
最大重试请求次数。 |
api_key |
大模型供应商提供的 API 秘钥。 |
base_url |
大模型供应商 API 请求地址。 |
以上的标准参数,也只是适用于部分的大语言模型,有些参数在特定模型中可能是无效的,这些标准化参数仅对 LangChain 官方提供集成包的模型(如 langchain-openai、langchain-anthropic)生效,在langchain-community包中的第三方模型,则不需要遵守这些标准化参数的规则。
ChatOpenAI完整示例:
1 | import dotenv |
执行结果如下:
1 | 好的!求最大公约数(GCD)可以用欧几里得算法,这是一种高效的算法。下面是用 Python 实现的代码: |
解释:
- 这个方法使用了 欧几里得算法,通过反复取模来缩小问题的规模,直到
b为 0。 - 当
b为 0 时,a就是两个数的最大公约数。
你可以用这个函数来求两个数的最大公约数。例如:
1 | print(gcd(56, 98)) # 输出:14 |
这种方法的时间复杂度是 (O(\log(\min(a, b)))),非常高效。
4.3 LLM文本生成模型
LLM文本生成模型使用方式如下:
1 | import dotenv |
执行结果:
1 | 《悯农》是唐代诗人李绅创作的一首诗,原文如下: |
4.4 Message组件
在之前介绍聊天模型ChatOpenAI的案例中,调用模型后返回了一条AI消息,在LangChain中,消息有几种不同的类型。所有消息都有 type 、 content 、 response_metadata 等属性。
下面是这几个属性的作用:
| 属性名 (Attribute Name) | 属性作用 (Function) |
|---|---|
type |
描述消息的类型,包含 “user”(用户消息)、”ai”(AI 回复消息)、”system”(系统提示消息)和 “tool”(工具调用 / 返回消息)四种类型。 |
content |
消息的核心内容,通常为字符串;部分场景下可为字典列表,用于支持大模型的多模态输出(如文本 + 图片信息)。 |
name |
用于区分相同类型的不同消息(如多个工具调用消息),但并非所有模型都支持该属性。 |
response_metadata |
仅 AI 消息(AIMessage)包含的附加元数据,内容因模型而异,可能包含本次请求的 token 使用量、响应时间等信息。 |
tool_calls |
仅 AI 消息(AIMessage)包含的属性,当大模型决定调用工具时会生成该字段;返回一个 ToolCall 列表,每个 ToolCall 为字典,包含 name(工具名称)、args(工具调用参数)、id(工具调用唯一标识)三个字段。 |
根据消息类型的不同, Message组件被分为:
HumanMessage:人类消息,type为”user”
AIMessage: AI 消息,type为”ai”
SystemMessage:系统消息,type为”system”,告诉大模型当前的背景是什么,应该如何做,并不是所有模型提供商都支持这个消息类型
ToolMessage:工具消息,type为”tool”
FunctionMessage:旧的函数调用消息类型,现已被 ToolMessage 取代。
4.5 使用其他大语言模型
除了使用OpenAI的大语言模型之外,LangChain还可以使用很多的大语言模型,下面我们以接入阿里巴巴的通义千问聊天模型为例。
首先,申请阿里云百炼平台API KEY:

在.env文件中,加入阿里云百炼平台的API Key
1 | # 阿里云百炼平台API KEY |
安装依赖包
1 | pip install dashscope |
调用通义千问模型示例如下:
1 | import dotenv |
执行结果:
1 | 《短歌行》是东汉末年曹操所作的一首乐府诗,全诗如下: |
这首诗表达了诗人对人生短暂的感慨、对贤才的渴求以及统一天下的雄心壮志。
接入更多模型的文档在LangChain官网的Integrations中
4.6 总结
本文详细介绍了 LangChain 中模型组件(Model)的使用方法与设计思路,首先从模型的分类开始,分析了文本生成模型和聊天模型的区别,接下来通过具体的代码示例,来演示聊天模型ChatOpenAI和文本生成模型OpenAI的基本用法。
我们还学习了聊天模型输入输出都要用到的Message组件,了解了 Message 组件的几种类型(如 HumanMessage、AIMessage、SystemMessage、ToolMessage),最后,我们以接入阿里巴巴的通义千问的聊天模型为例,展示如何在LangChain中接入其他第三方模型。
总的来说,LangChain 在模型接入方面做了大量抽象,可以灵活支持 OpenAI、Anthropic、阿里通义千问、百度文心一言等主流模型。通过本文,相信你已经理解Model组件的设计思想和使用方法。
5. 输出解析器使用技巧
在实际的AI应用开发中,可能经常遇到这样的问题:很多时候大语言模型输出格式不够标准化,有时候返回的是纯文本,有时候是JSON格式,甚至还可能包含一些不需要的冗余信息,如:
1 | Human:帮我生成一个商品信息的json字符串,格式是:{"name": "苹果", "price": "1000"} |
但实际上,我们期望的是只返回一个JSON字符串,AI却返回了一些多余的文字,为了解决这个问题,LangChain提供了输出解析器(Output Parsers)组件,可以帮助我们将模型的原始输出转换为结构化的、易于处理的数据格式,这一步不仅仅涉及数据类型的转换,也包括对返回数据的处理。
学习完输出解析器,LangChain框架中最核心的组件就已经讲解完毕,整个与大语言模型交互的流程非常的清晰完整,流程图如下:
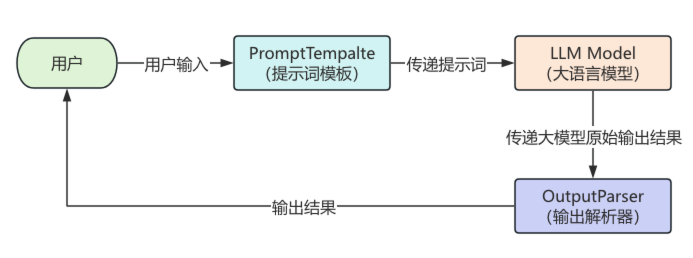
5.1 什么是输出解析器
输出解析器是LangChain框架中的重要组件,它的作用是将大语言模型的原始输出内容解析为如JSON、XML、YAML等结构化数据。在LangChain中,输出解析器位于模型和最终数据输出之间,作为数据处理的中间层。通过输出解析器,可以实现如下目的:
- 指定格式输出:将模型的文本输出转换指定格式
- 数据校验:确保输出内容符合预期的格式和类型
- 错误处理:当解析失败时,进行错误修复和重试
- 输出格式提示词:生成对应格式要求的提示词,如要生成JSON的具体描述,可以通过提示词传递给大模型,达到返回特定格式数据的目的
5.2 输出解析器类型
LangChain提供了多种输出解析器,以下是常见的输出解析器及使用场景:
| 解析器类型 (Parser Type) | 适用场景 (Use Case) | 输出格式 (Output Format) |
|---|---|---|
StrOutputParser |
简单文本输出 | Python 字符串 (String) |
JsonOutputParser |
JSON 格式数据 | Python 字典或列表 (Dictionary / List) |
PydanticOutputParser |
复杂结构化数据 | Pydantic 模型对象 (Pydantic Model Object) |
ListOutputParser |
列表数据 | Python 列表 (List) |
DatetimeOutputParser |
时间日期数据 | Python datetime 对象 |
BooleanOutputParser |
布尔值输出 | Python 布尔值 (True / False) |
输出解析器核心方法:
- parse:将大模型输出的内容,格式化成指定的格式返回。
- format_instructions:它会返回一段清晰的格式说明字符串,告诉 LLM 希望输出成什么格式(比如 JSON,或者特定格式)。
5.3 常用输出解析器用法
5.3.1 StrOutputParser用法
StrOutputParser 是LangChain中最简单的输出解析器,它直接从AIMessage的content中提取纯文本内容。在前面的章节中,其实已经使用过它,代码示例如下,在示例中使用了链式调用,在后续的文章中会详细讲解。
1 | import dotenv |
执行结果:
1 | 输出类型: <class 'str'> |
5.3.2 JsonOutputParser用法
当我们需要模型输出JSON格式数据时,可以使用 JsonOutputParser。这个解析器不仅能解析JSON格式,还能为模型提供输出指定格式的提示词,使用示例如下,这里要注意的是案例中使用的模型是gpt-4o,因为经过多次测试,使用gpt-3.5-turbo输出结果会产生幻觉,幻觉可能表现为格式错误或字段遗漏。
1 | import dotenv |
执行结果:
1 | 输出类型: <class 'dict'> |
5.3.3 PydanticOutputParser用法
对于结构更复杂、具有强类型约束的需求,PydanticOutputParser 则是最佳选择。它结合了Pydantic模型的强大功能,提供了类型验证、数据转换等高级功能,使用示例如下:
1 | import dotenv |
执行结果:
1 | 输出类型: <class '__main__.Poet'> |
5.4 自定义输出解析器
在某些情况下,LangChain提供的内置的解析器无法满足业务的要求,这时我们可以创建自定义的输出解析器,如下示例,在代码中创建了一个书名号自定义输出解析器,在 get_format_instructions 方法中,提供输出格式的提示词,并在parse方法中通过正则提取书名号包裹的内容,最终返回一个列表。
1 | import dotenv |
执行结果:
1 | 输出类型: <class 'list'> |
5.5 错误修复与重试机制
LangChain 提供两种常见的错误处理机制:
OutputFixingParser:用于修复格式不规范的输出(再次调用大模型)
RetryOutputParser:在初次解析失败时自动附带提示词重试生成过程
首先是错误修复机制,使用示例如下,将大模型输出的结果传递给fixing_parser,调用parse()方法时,在方法内,首先尝试调用 PydanticOutputParser 的 parse() 方法;若抛出异常,才会触发 OutputFixingParser 的修复逻辑,需要注意的是这里多了一次大模型调用的成本。
1 | import dotenv |
执行结果:
1 | 修复前的内容:{'content': '白日依山尽,黄河入海流。欲穷千里目,更上一层楼。', 'author': '王之涣'} |
除了错误修复机制,LangChain还提供了重试机制,使用示例如下,将大模型输出结果传递给retry_parser,内部会调用PydanticOutputParser的parse()方法,与 OutputFixingParser 不同,RetryOutputParser 会在解析失败时,将原始提示词与输出一并传回模型,尝试重新生成符合格式的内容,如果parse_with_prompt没有报错,不会去触发重试的,同样重试也会多调用一次大模型。
1 | import dotenv |
执行结果:
1 | 重试前的内容:{'content': '白日依山尽,黄河入海流。欲穷千里目,更上一层楼。', 'author': '王之涣'} |
5.6 总结
输出解析器是LangChain框架中不可或缺的组件,它解决了大语言模型输出格式不规范的问题。通过本文的介绍,我们学习了基础解析器的使用从简单的StrOutputParser到复杂的PydanticOutputParser。
我们还了解了结构化数据处理,通过JsonOutputParser和PydanticOutputParser,可以将模型输出转换为结构化的Python对象、JSON对象,便于后续处理。当LangChain提供的内置解析器无法满足需求时,可以创建自定义解析器来处理特殊格式的数据。
在实际项目中,选择合适的输出解析器能够大大提升开发效率和数据处理的准确性。建议根据具体的业务需求,选择最适合的解析器类型,并结合错误处理机制确保系统的稳定性。