1. RAG
当我们在跟大语言模型交流时,会发现大语言模型只能回答训练数据范围内的事情,如果你问它一些超出训练数据之外的事情,AI的回答往往就是胡言乱语,或者给出错误的答案。
那么我们不禁会想到:大模型拥有如此强大的能力,是否能让大模型掌握一些特定领域的知识,甚至接入企业内部的知识库数据?来帮助我们实现业务需求。
这就是本文要介绍的技术——RAG(Retrieval Augmented Generation)即检索增强生成,本文将重点介绍RAG是什么以及使用LangChain实现RAG所需的关键组件,并分析它们之间的协作机制。具体实现细节将在后续文章中展开。
1.1 什么是RAG
RAG(Retrieval Augmented Generation)检索增强生成,RAG是一种将信息检索和大语言模型文本生成相结合的技术。简单来说,RAG就是在大语言模型生成答案之前,AI应用先从外部知识库中检索与用户提问相关的信息,然后将检索到的信息作为上下文通过提示词一起传递给大语言模型,从而让大语言模型根据检索出来的内容进行回答。
RAG解决了如下几个问题:
(1)知识边界问题:大语言模型所掌握的知识来源于训练数据,对超过自身训练数据以外的问题无法回答。
(2)知识更新问题:大语言模型训练完成后,除了重新训练之外无法继续获取最新的信息。
(3)幻觉问题:当大语言模型不确定答案时,编造一些错误信息,这种现象被称为幻觉。
(4)回答特定领域专业问题:目前参数比较大的大语言模型多数都是通用的模型,这些通用模型的知识面非常广,但是对特定领域知识了解的深度更低。
通过RAG技术就能在一定程度上解决上述的问题,让大语言模型拥有了获取特定领域知识的能力,并且给出准确、专业的回答。
1.2 如何实现RAG技术
RAG技术的落地主要由以下几个步骤组成:
(1)文档的收集
(2)文档处理
(3)文档数据向量化
(4)文档数据相似性检索
(5)构建提示词
(6)大语言模型生成结果
其中前三个步骤属于RAG的准备阶段,后三个步骤是RAG的使用阶段,下面分别介绍RAG每个步骤都需要完成哪些工作。
1.2.1 RAG准备阶段
主要负责知识库的构建,包括文档的收集、处理和向量化;
(1)文档的加载:对你需要让大模型了解的相关领域的文档材料进行整理,可以是word文档、PDF、PPT、TXT、CSV、HTML等等种类的文档,通过这些文档来构建一个知识库,作为大语言模型知识的来源。
(2)文档的处理:收集到的文档往往是很长很长并且存在一些换行和空白,不利于对文档进行检索,同时,还可能涉及隐私的数据,因此需要将收集到的文档进行加载、处理和分割,将一个大的文档分割成小块的文档片段。
(3)文档片段数据的向量化:如果仅将文档片段保存至传统关系型数据库中,再根据关键词进行模糊查询,往往效果较差。例如用户查询“如何种植马铃薯?”,数据库中的“土豆”内容很可能无法匹配,尽管两者语义相同。
1 | 种植土豆需要选择合适的土壤、进行催芽、适时播种、田间管理和收获。 |
因此,在文档检索的过程中需要使用向量数据库(如Pinecone、Weaviate等),什么是向量数据库呢?向量数据库(Vector Database)是一种专门用于存储高维向量的数据库,主要用于基于向量相似度的快速检索,例如人脸识别、图像检索、推荐系统、RAG 等场景。
将一个文档片段向量化需要使用文本嵌入模型,文本嵌入模型会根据文档片段的文本信息以不同的维度构建出一个高维向量,这个高维向量和文本片段的元数据信息将会一起保存到向量数据库,这就是文档文本片段向量化的过程。
1.2.2 RAG的使用阶段
用户提出问题后,系统从知识库中检索相关信息,并调用大语言模型生成回答。
(4)文档相似性检索:前面三个步骤属于RAG的准备阶段,下面将会进入使用阶段,当用户提出问题后,同样的会使用相同的文本嵌入模型对提问文本进行向量化,根据向量在向量数据库中进行相似性检索,并且可以传递一些过滤条件,最终将检索的文本片段的元数据信息返回,如文档片段ID,可通过返回的文档片段ID,在关系型数据库中定位到对应的原始文档内容。
(5)构建提示词:将使用相似性检索得到的文档片段信息,拼接到提示词中,作为供大语言模型参考的上下文信息。
(6)大语言模型生成结果:将渲染后的提示词传递给大语言模型,大语言模型输出相应结果。
1.3 LangChain中实现RAG功能组件
那么,如何将上述每个步骤落地实现?LangChain 框架提供了丰富的组件帮助我们搭建 RAG 应用,下面是关于这些核心组件的介绍:
| LangChain 组件 | 作用 | 常用组件类 |
|---|---|---|
| 文档加载器 | 对各种格式的文档信息进行加载 | Document(文档组件)、UnstructuredPDFLoader(PDF 文档加载器)、UnstructuredFileLoader(文件文档加载器)、UnstructuredMarkdownLoader(markdown 文档文本加载器) |
| 文档分割器 | 将加载的文档分割成文档片段 | RecursiveCharacterTextSplitter(递归字符文本分割器) |
| 文本嵌入模型组件 | 将文本信息向量化 | OpenAIEmbeddings(OpenAI 文本嵌入模型)、HuggingFaceEmbeddings(HuggingFace 文本嵌入模型) |
| 向量数据库组件 | 将向量和元数据信息保存到向量数据库 | VectorStore(向量数据库,不同向量数据库有不同的实现类) |
| 文本检索器 | 根据用户提问在向量数据库中进行检索 | VectorStoreRetriever(向量数据库检索器) |
1.4 LangChain中如何实现RAG功能
在RAG准备阶段,LangChain通过文档加载器对各种格式的文档进行加载,转换为LangChain中的文档对象,之后对文档对象进行分割,根据分割规则,分割成文档片段。
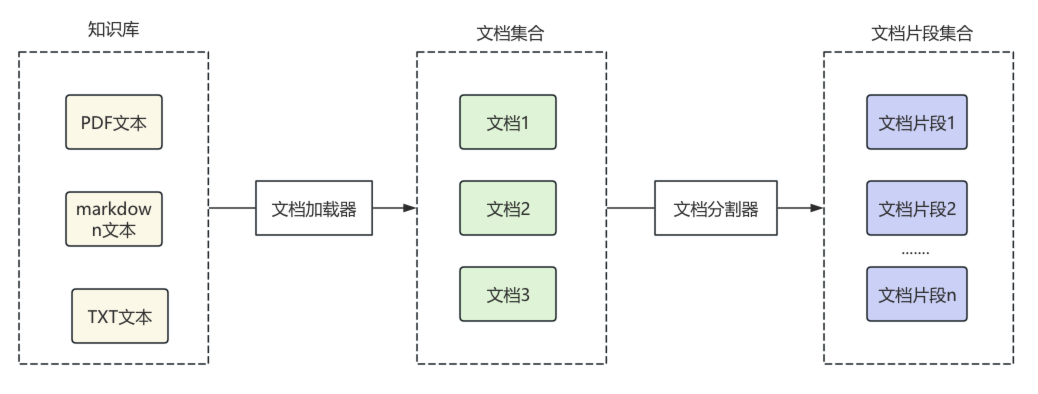
之后,将文档片段通过文本嵌入模型组件,转换为向量,通过向量数据库组件,保存到向量数据库,每个向量通常还会绑定原文内容、文档ID、来源等元数据信息,便于后面数据检索。
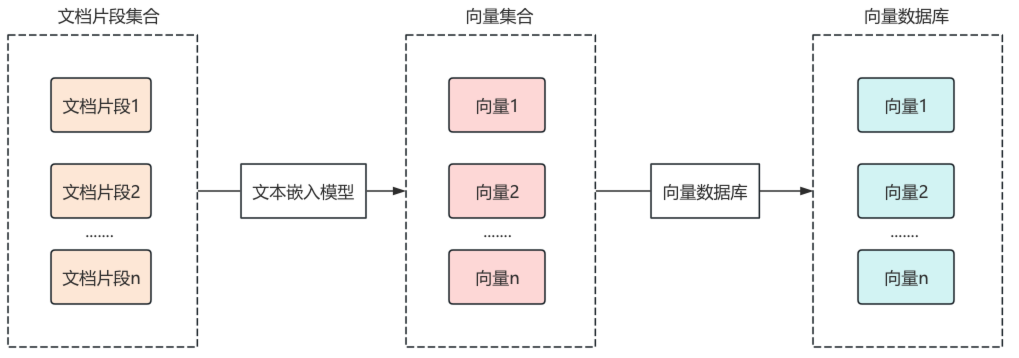
在RAG的使用阶段,用户首先提出问题,使用文本嵌入模型组件,将提问文本转换为向量数据,通过向量数据库检索器组件,进行相似性检索,返回关联的文本片段。
将相关的文档片段内容渲染到提示词模板中,作为提问问题的上下文传递给大语言模型,大语言模型输出结果,再传递给输出解析器,最终结果通过输出解析器处理后返回给用户,这样就完成了一次RAG检索。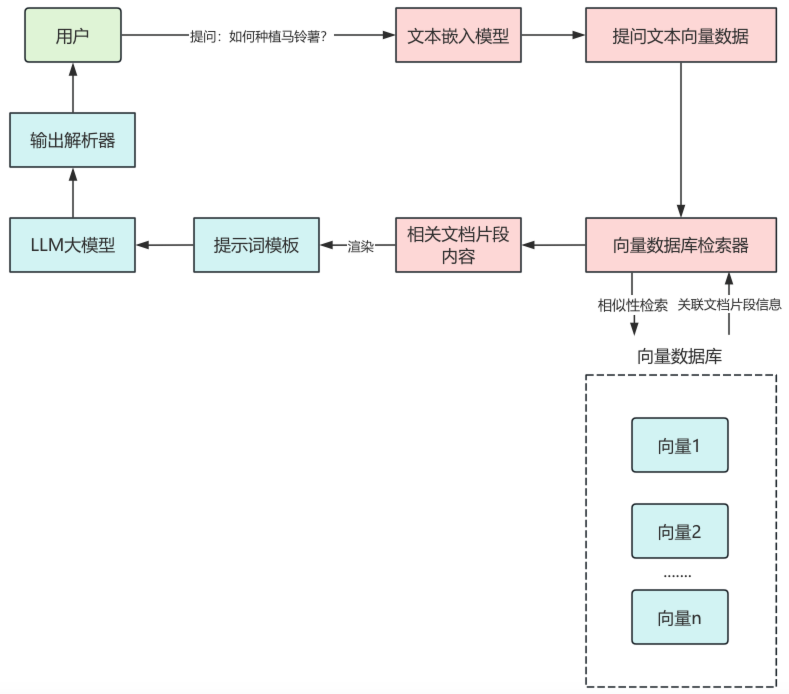
1.5 总结
本文详细介绍了 RAG(检索增强生成) 技术的概念、作用以及完整的实现流程。RAG的本质是在大语言模型生成答案之前,通过检索外部知识库的相关信息,来解决大语言模型知识边界的局限性问题,让大语言模型具备实时获取、理解和回答特定领域问题的能力。
LangChain作为一个大语言模型应用开发框架,为RAG的实现提供了完整的组件体系,覆盖了从文档加载、内容分割、文本嵌入、向量存储、相似性检索到提示词构建的全流程。开发者可通过LangChain框架,只需完成少量工作即可实现RAG功能。
2. 一文带你吃透文档加载器
在上一篇文章中,介绍了实现RAG功能的整个流程,以及LangChain提供了哪些组件来实现RAG功能,想了解RAG实现过程可以参考:LangChain框架入门09:什么是RAG?
本文将从RAG准备阶段第一个步骤:文档加载,详细介绍LangChain中的文档加载器组件,LangChain内置的文档加载器可以加载各种格式的知识库文档,而无需开发者自己编写,可以非常便捷地实现文档加载功能。
2.1 什么是文档加载器
在LangChain中,文档加载器用于将各种格式的文档转换为Document对象,LangChain提供了大量的文档加载器,支持从各种来源加载文档,如文件、数据源、URL等。
常用的LangChain文档加载器如下:
| 文档加载器 | 作用 |
|---|---|
| CSVLoader | 从 CSV 加载文档 |
| JSONLoader | 从 JSON 数据加载文档 |
| PyPDFLoader | 从 PDF 数据加载文档 |
| UnstructuredHTMLLoader | 从 HTML 数据加载文档 |
| UnstructuredMarkdownLoader | 从 Markdown 加载文档 |
| UnstructuredExcelLoader | 从 Excel 文件加载数据 |
每一个文档加载器都有自己特定的参数和方法,但它们有一个统一的load()方法来完成文档的加载,load()方法会返回一个Document类的对象列表,因为这些文档加载器都继承自BaseLoader基类,它们的继承关系如下:
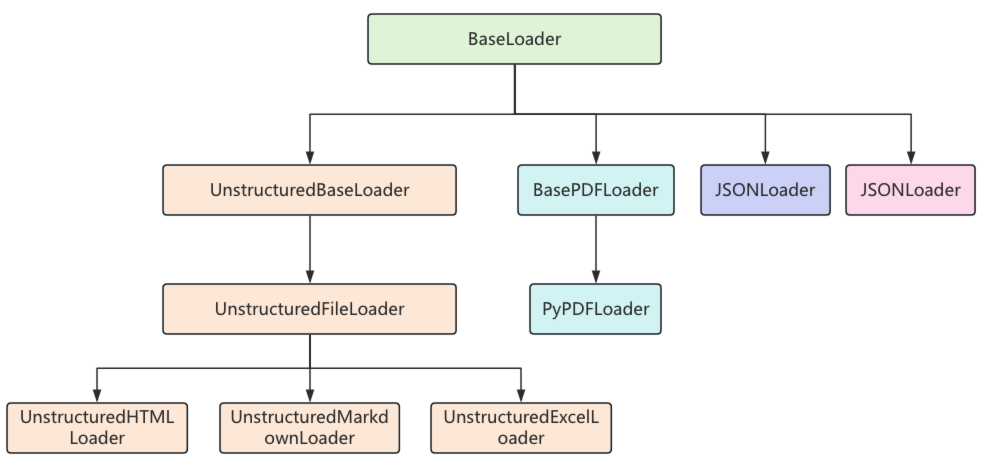
在BaseLoader类中,定义了load()方法,用来加载文档对象,在方法内部又调用了lazy_load()懒加载方法
1 | def load(self) -> List[Document]: |
在lazy_load()方法中,判断了子类是否重写了load()方法,如果重写了,则调用当前类的load()方法,如果没有重写则抛出异常,因此在子类中,要重写load()方法或lazy_load()方法。
1 | def lazy_load(self) -> Iterator[Document]: |
如果LangChain提供的文档加载器无法满足业务需求,我们也可以自己实现自定义加载器,通过继承BaseLoader,并实现其中的load()方法,来编写自定义文档加载器的加载逻辑。
2.2 Document文档类
文档加载器无论从什么来源进行文档加载,最终都是为了将文档信息解析为Document对象,下面一起来看看Document类中重要属性:
page_content:表示文档的内容,类型是字符串
metadata :与文档本身无关的元数据信息。可以保存文档 ID、文件名等任意信息,类型是字典
2.3 UnstructuredMarkdownLoader文档加载器使用
下面以UnstructuredMarkdownLoader为例来介绍文档加载器的用法:
首先需要安装unstructured相关依赖
1 | pip install "unstructured[md]" nltk |
执行命令,生成依赖版本快照
1 | pip freeze > requirements.txt |
使用UnstructuredMarkdownLoader读取md文件示例如下:
1 | from langchain_community.document_loaders import UnstructuredMarkdownLoader |
执行结果如下,默认情况下UnstructuredMarkdownLoader把md文档内容加载成了一个Document对象,并且自动将文件名添加到了Document对象的元数据中。
1 | 文档数量:1 |
在底层Unstructured包会为不同的文本片段创建不同的“元素”。默认情况下会将这些元素合并在一起,可以通过指定 mode="elements" 来将不同元素进行分离,解析成多个文档。
1 | document_load = UnstructuredMarkdownLoader(file_path="LangChain框架入门09:什么是RAG?.md", |
重新执行代码,可以看到加载的文档数为12,文档的内容也按照不同元素进行了拆分。
1 | 文档数量:12 |
2.4 实现自定义文档加载器
在实际开发中,基于文件的不同类型和不同格式,有时通过这些LangChain提供的文档加载器很难满足业务需求,例如需要根据特定规则提取文本片段,这时就需要开发自定义加载器,只需要定义一个自定义文档加载器类,并继承前面提到的BaseLoader类。
假设有如下需求,对chat_record.txt文件进行文档加载,内容如下,要求将不同人物的每一句对话加载成一个文档,并且在文档的元数据中添加人物的名字。
1 | 小明:你是哪个学校的? |
自定义文档加载器代码如下:
1 | from typing import List |
执行结果如下,chat_record.txt文件被解析成6个文档,并且每个文档的元数据都保存了user_name。
1 | 文档数量:6 |
2.5 总结
本文首先介绍了什么是文档加载器,以及常见文档加载器和它们的类继承关系。随后,以 UnstructuredMarkdownLoader 为例,演示了如何加载 Markdown 文件,并对比了默认模式与 mode=”elements” 模式下的不同拆分效果。
最后,通过一个聊天记录文件加载的案例,展示了如何根据业务需求定制自定义文档加载器,实现将聊天记录逐句加载为 Document 对象,并在 metadata 中附加额外信息。
通过本文相信大家已经掌握了文档加载器的用法,LangChain 提供了丰富的内置加载器来快速适配常见文档格式,同时也为开发者预留出了灵活的扩展空间,使得无论是处理结构化数据还是非结构化文本,都能很好的处理文档的加载,在后续的文章中,将会介绍LangChain的文档分割器的用法,敬请期待。
3. 文本分割器实战指南
在上一篇文章《LangChain框架入门10:一文带你吃透文档加载器》中详细介绍了文档加载器的用法,在实现RAG功能准备阶段,首先将知识库文档信息加载成Document对象之后,一般就会对文档进行分割处理。
在LangChain中提供了许多开箱即用的、能分割多种格式的文本分割器,本文将会对这些文本分割器进行详细介绍。
3.1 什么是文本分割器
在RAG应用中,文档加载器将原始文档转换为Document对象后,通常需要对长文档进行分割处理,这是因为大语言模型的上下文窗口是有限的,如果在RAG检索完成之后,直接将检索到的长文档作为上下文传递给模型,可能会超出模型处理的上下文长度,导致信息丢失或回答质量下降,其中,进行文档分割的组件就是文本分割器。
文本分割器的主要作用有:
控制上下文长度:把长文档分割成更小,缩小上下文长度
提高检索准确性:小的文本片段能提升文档检索的精确度
保持语义完整性:在分割过程中,能尽量保持文本的语义连贯性
LangChain提供了多种文本分割器,常用的有:
| 分割器 | 核心作用 | 适用场景 |
|---|---|---|
| RecursiveCharacterTextSplitter | 递归按字符分割文本 | 通用场景,如普通文档、小说、新闻等无特定格式的长文本 |
| CharacterTextSplitter | 按指定字符分割文本 | 需自定义分割规则的场景,如按 “。”“;” 等符号分割中文文本 |
| MarkdownHeaderTextSplitter | 按 Markdown 标题分割 | Markdown 格式文档,如技术文档、博客,需保留标题层级关系 |
| PythonCodeTextSplitter | 专门分割 Python 代码 | Python 代码文件,可按函数、类、代码块逻辑分割 |
| TokenTextSplitter | 按 Token 数量分割 | 需严格匹配大语言模型 Token 限制的场景,如精准控制输入长度 |
| HTMLHeaderTextSplitter | 按 HTML 标题分割 | HTML 格式文档,如网页源码,需按<h1>``<h2>等标签分割 |
大部分文本分割器都继承自TextSplitter基类,该基类定义了分割文本的核心方法:
- split_text():将文本字符串分割成字符串列表
- split_documents():将Document对象列表分割成更小文本片段的Document对象列表
- create_documents():通过字符串列表创建Document对象
3.2 递归文本分割器用法
RecursiveCharacterTextSplitter是LangChain中最常用的通用文本分割器,它会根据指定的字符优先级递归分割文本,直到所有片段长度不超过指定上限。
在使用前首先安装依赖:
1 | pip install -qU langchain-text-splitters |
执行命令,生成依赖版本快照
1 | pip freeze > requirements.txt |
首先介绍一下RecursiveCharacterTextSplitter构造函数几个核心参数:
- chunk_size: 每个片段的最大字符数
- chunk_overlap:片段之间的重叠字符数
- length_function:计算长度函数
- is_separator_regex: 分隔符是否为正则表达式
- separators:自定义分隔符
3.2.1 分割文本
首先介绍使用split_text()方法进行文本分割,使用示例如下,其中RecursiveCharacterTextSplitter中指定的块大小为100,片段重叠字符数为30,计算长度的函数使用len。
1 | from langchain_text_splitters import RecursiveCharacterTextSplitter |
执行结果如下,文本分割器将文本内容分割成了四个文本片段,且内容长度最大为100个字符。
1 | 分割文档数量:4 |
3.2.2 分割文档对象
RecursiveCharacterTextSplitter不仅可以分割纯文本,还可以直接分割Document对象,使用示例如下:
1 | from langchain_community.document_loaders import UnstructuredFileLoader |
执行结果如下:
1 | 分割文档数量:4 |
3.2.3 自定义分隔符
RecursiveCharacterTextSplitter默认按照["\n\n", "\n", " ", ""]的优先级进行分割,可以通过separators指定自定义分隔符。
1 | # 2.定义递归文本分割器 |
3.3 按标题分割Markdown文件
在对Markdown格式的文档进行分割时,一般不能像RecursiveCharacterTextSplitter默认分割规则方式进行分割,通常需要按照标题层次进行分割,LangChain提供了MarkdownHeaderTextSplitter类来实现这个功能。
在对Markdown文件进行分割时,对于那些很长的文档,可以先利用MarkdownHeaderTextSplitter按标题分割,将分割后的文档再使用RecursiveCharacterTextSplitter进行分割,使用示例如下:
1 | from langchain_community.document_loaders import TextLoader |
执行结果如下,先用MarkdownHeaderTextSplitter将markdown文本内容分割成4个文档,之后在对每一个文档使用RecursiveCharacterTextSplitter进行分割,分割成了11个文档,并且在文档元数据中,还添加了文本片段所属的标题信息。
1 | 按标题分割文档数量:4 |
3.4 自定义文本分割器
当内置的的文本分割器无法满足业务需求时,可以继承TextSplitter类来实现自定义分割器,不过一般需要自定义文本分割器的情况非常少,
假设我们有如下需求,在对文本分割时,按段落进行分割,并且每个段落只提取第一句话,下面通过实现自定义文本分割器,来实现这个功能,示例如下:
1 | from typing import List |
执行结果:
1 | 文本分割片段大小:8, 文本内容:# 一、李白简介 |
3.5 总结
本文详细介绍了LangChain中文本分割器的概念和用法。文本分割器是实现RAG的重要组件,它可以将长文本分割成适合模型处理的小片段,同时保持文本的语义完整性。
在本文中,重点介绍了RecursiveCharacterTextSplitter递归文本分割器,它是最常用的通用分割器,能够按照字符优先级进行递归文本分割。对于Markdown格式的文档,MarkdownHeaderTextSplitter能够按照标题层次进行结构化分割,保证文本分割的层次性。
当内置的分割器无法满足特定需求时,我们可以通过继承TextSplitter类来实现自定义分割器,灵活的处理各种文本分割需求。
选择合适的文本分割策略对RAG应用的效果至关重要。在实际项目中,建议根据文档的特点和业务需求来选择或组合使用不同的分割器,来到最佳的文本处理效果。
在下一篇文章中,我们将介绍LangChain中的文本嵌入模型embeddings组件敬请期待。
4. 深入解析文本嵌入组件
在前面两篇文章中,我们分别介绍了“文档加载”和“文本分割”。此时,知识库中的长文档已被拆分为一个个固定长度的文本片段。完成这两步后,实现 RAG 功能的下一步就是对这些文本片段进行向量化。
在文本向量化时,可以使用LangChain提供的文本嵌入组件:Embeddings,这也是本文的主角,本文将会详细介绍Embeddings组件的用法。
4.1 什么是文本嵌入模型
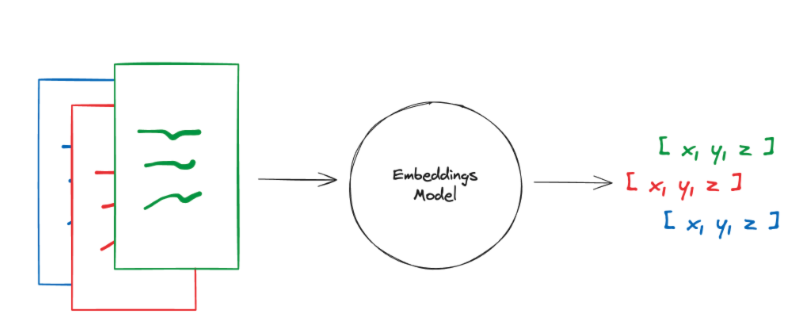
文本嵌入模型可以将一段文本转换为高维向量表示,向量可以理解为是一组数字,文本嵌入模型根据多个不同维度将文本转换为具有语义含义的向量数据,这个转换过程叫做文本嵌入。
之后,将这些向量存储到向量数据库中。当用户向LLM提出问题,先将问题文本进行向量化,得到问题文本的向量,使用这个向量在向量数据库中进行相似性搜索,就可以找到与提问文本语义最相近向量,进而找到文本片段信息。
文本嵌入流程如下图所示:
4.2 Embeddings类用法
4.2.1 Embeddings类介绍
在LangChain中,Embeddings类是为文本嵌入模型设计的标准接口,针对不同的文本嵌入模型供应商(如OpenAI、Hugging Face、通义千问等)提供不同的实现类。
Embeddings类提供了两个方法:
- embed_documents:传入多个文本片段,将文本片段转换为多个向量返回
- embed_query:传入查询文本,将查询文本转换为向量返回
将文本转换为向量被拆分为两个方法,是因为某些模型提供商对“文档嵌入”和“查询文本嵌入”提供了不同的方法。
4.2.2 OpenAIEmbeddings用法
下面以OpenAI提供的OpenAIEmbeddings类为例,介绍Embeddings类用法。
首先安装langchain-openai相关依赖
1 | pip install langchain-openai==0.1.8 |
执行命令,生成依赖版本快照
1 | pip freeze > requirements.txt |
在.env文件中,添加OpenAI秘钥配置
1 | # OpenAI大模型 |
OpenAIEmbeddings使用示例如下,使用embed_documents和embed_query分别对文档和查询文本进行嵌入,其中使用的模型是text-embedding-3-small,该模型生成的向量维度是1536,能接收最大的token数是8192。
1 | import dotenv |
执行结果如下,可以看到三个文档分别生成了三个高维向量,查询文本也生成了一个对应的向量。由于向量维度较高,输出进行了部分省略。
1 | 文档向量: |
4.3 CacheBackedEmbeddings结果缓存
当使用Embeddings类对一段文本进行嵌入后,再有同样的文本进行嵌入,如果每次都重新调用嵌入模型,不仅会显著增加处理时间,也会带来额外的调用成本。
因此,LangChain提供了CacheBackedEmbeddings可以对嵌入结果进行缓存,下次同样的文本进行嵌入,直接从缓存中读取,无需重复调用嵌入模型。
创建CacheBackedEmbeddings对象,需要通过from_bytes_store方法,该方法需要指定如下参数:
- underlying_embedder: 真正用于文本嵌入Embeddings类。
- document_embedding_cache: 用于缓存文档嵌入向量数据的 ByteStore(字节存储接口) ,ByteStore 是 LangChain 提供的通用“字节存储接口”,用于以二进制形式读写向量数据。常见实现包括本地文件系统(如 LocalFileStore)、Redis(RedisStore) 等。
- batch_size: 可选参数,默认为 None,在嵌入缓存未命中时,多少个文档为一批,去调用底层文本嵌入组件去文本嵌入并写入缓存。
- namespace: 可选参数,默认为 “” ,文档缓存的命名空间。使用命名空间来避免和其他嵌入模型的缓存数据发生冲突。因此,可以将命名空间设置为所使用的嵌入模型的名称。
- query_embedding_cache: 可选参数,默认为 None,传入False则不进行缓存,传入True使用与 文档缓存相同的ByteStore,也可以传入单独的 ByteStore用于查询文本的缓存。
from_bytes_store方法定义如下:
1 | @classmethod |
CacheBackedEmbeddings使用示例如下,在示例中,使用了OpenAIEmbeddings来作为真正进行文本嵌入的组件,并且,为文档向量缓存和查询文档向量缓存指定了两个不同的本地文件存储容器,还指定了命名空间为嵌入模型的名称。
1 | import time |
第一次执行结果,整个文本嵌入执行时间比较长
1 | 文档嵌入执行时间:52.9221 秒 |
在当前文件目录就会生成两个缓存文件夹,分别用来缓存文档和查询文本向量信息,并且命名空间使用的是模型名称
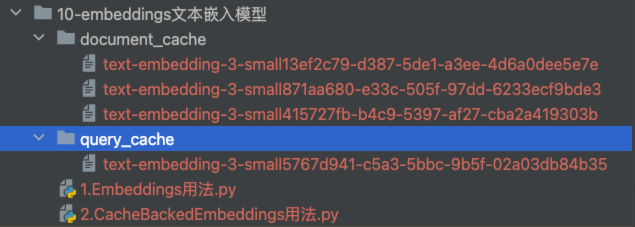
第二次执行程序,程序很快的返回结果,并且计算的执行时间也是非常的快,因为整个嵌入过程没有调用嵌入模型,而是读取了缓存中的数据。
1 | 文档嵌入执行时间:0.0036 秒 |
4.4 总结
本文详细介绍了实现RAG功能的重要组件:文本嵌入组件,讲解了LangChain中的Embeddings类的使用方法,以及Embeddings类的核心方法,以OpenAI提供的 OpenAIEmbeddings 类为例,演示如何进行文本嵌入。
为了能提升文本嵌入执行效率、节省成本,LangChain还提供了CacheBackedEmbeddings类,通过在本地对文本嵌入信息缓存,当同样的文本再进行文本嵌入时,就可以从本地缓存中进行读取,有效提升了文本嵌入的整体性能。
相信通过本文,你已经掌握了如何使用Embeddings类进行文本嵌入,在下一篇文章中,我们将介绍向量数据库相关用法,敬请期待。