1. 手把手带你玩转LCEL表达 在前面几篇文章中,我们已经掌握了LangChain的核心组件:提示词模板、大语言模型、输出解析器。细心的读者可能发现,在使用这些组件时,经常会看到类似 prompt | llm | parser 这样的链式操作。这就是今天重点介绍的LCEL(LangChain Expression Language)表达式。
在平时开发中,经常需要将多个组件组合起来形成完整的处理流程,将上一个组件的输出作为下一个组件的输入,在不使用LCEL表达式之前,就会写出这种代码:使用 invoke() 进行层层嵌套,这就好比早期 JS 中的回调地狱,结构混乱、难以维护,并且出现错误很难判断是哪一步出了问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # 1.构建提示词 prompt = ChatPromptTemplate.from_messages([ ("system", "你是一个资深文学家"), ("human", "请简短赏析{name}这首诗,并给出评价") ]) # 2.创建模型 llm = ChatOpenAI() # 3.创建字符串输出解析器 parser = StrOutputParser() # 4.调用模型返回结果 result = parser.invoke( llm.invoke( prompt.invoke({"name": "江雪"}) ) )
而LCEL让这个过程变得简洁直观,通过管道符号进行连接,可以很轻松地构建出功能强大的AI应用。
1.1 什么是LCEL表达式 LCEL(LangChain Expression Language)是LangChain框架的表达式语言,它提供了一种声明式的方式来构建复杂的数据处理链。通过LCEL,我们可以使用管道符号 | 将不同的组件连接起来,形成一个完整的数据处理链。
LCEL有以下优点:
1、代码更加简洁:用管道符号连接组件,代码更加简洁易读
2、可任意组合:任意Runnable组件都可以自由组合,构建复杂的处理逻辑
3、统一接口规范:所有Runnable组件都遵循统一的接口规范
4、方便监控与调试:LangChain内置了日志和监控功能,方便调试和优化
下面是使用LCEL表达式的案例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # 1.构建提示词 prompt = ChatPromptTemplate.from_messages([ ("system", "你是一个资深文学家"), ("human", "请简短赏析{name}这首诗,并给出评价") ]) # 2.创建模型 llm = ChatOpenAI() # 3.创建字符串输出解析器 parser = StrOutputParser() # 4.构建链 chain = prompt | llm | parser # 5.执行链 print(f"输出结果:{chain.invoke({'name': '题西林壁'})}")
显而易见,LCEL写法更加简洁,而且表达了清晰的数据流向:输入经过提示词模板处理,然后将PromptValue传递给大语言模型,最后将大语言模型输出的Message传递给输出解析器,经过输出解析器解析得到最终结果。
1.2 什么是Runnable组件 在深入LCEL之前,首先需要理解Runnable接口。Runnable是LangChain中所有可执行组件的基础接口,它定义了组件应该具备的标准方法。前面介绍的LangChain组件如提示词模板、模型、输出解析器等,都实现了Runnable接口,这就是为什么这些组件可以使用管道符进行连接的原因。
在Runnable接口中定义了以下核心方法:
invoke(input):同步执行,处理单个输入,最常用的方法
batch(inputs):批量执行,处理多个输入,提升处理效率
stream(input):流式执行,逐步返回结果,经典的使用场景是大模型是一点点输出的,不是一下返回整个结果,可以通过 stream() 方法,进行流式输出
ainvoke(input):异步执行,用于高并发场景
1.3 RunnableBranch条件分支 在LangChain中提供了类RunnableBranch来完成LCEL中的条件分支判断,它可以根据输入的不同采用不同的处理逻辑,具体示例如下,在下方示例中程序会根据用户输入中是否包含‘日语’、‘韩语’等关键词,来选择对应的提示词进行处理。根据判断结果,再执行不同的逻辑分支。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 import dotenv from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import RunnableBranch from langchain_openai import ChatOpenAI # 读取env配置 dotenv.load_dotenv() def judge_language(inputs): """判断语言种类""" query = inputs["query"] if"日语"in query: return"japanese" elif"韩语"in query: return"korean" else: return"english" # 1.构建提示词 english_prompt = ChatPromptTemplate.from_messages([ ("system", "你是一个英语翻译专家,你叫小英"), ("human", "{query}") ]) japanese_prompt = ChatPromptTemplate.from_messages([ ("system", "你是一个日语翻译专家,你叫小日"), ("human", "{query}") ]) korean_prompt = ChatPromptTemplate.from_messages([ ("system", "你是一个韩语翻译专家,你叫小韩"), ("human", "{query}") ]) # 2.创建模型 llm = ChatOpenAI() # 3.创建字符串输出解析器 parser = StrOutputParser() # 4.构建链分支结构,默认分支为英语 chain = RunnableBranch( (lambda x: judge_language(x) == "japanese", japanese_prompt | llm | parser), (lambda x: judge_language(x) == "korean", korean_prompt | llm | parser), (english_prompt | llm | parser) ) # 5.执行链 print(f"输出结果:{chain.invoke({'query': '请你用韩语翻译这句话:“我爱你”。并且告诉我你叫什么'})}")
执行结果如下,根据执行结果,执行的是韩语分支。
1 2 3 输出结果:“我爱你”用韩语是:“사랑해” (Saranghae)。 我叫小韩,很高兴为你服务!😊
1.4 RunnableLambda函数转换为可执行组件 LangChain还提供了类RunnableLambda,它可以非常方便的将函数转换为可执行组件,如下示例,将字符个数统计函数包装成一个RunnableLambda,并参与链执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import dotenv from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import RunnableLambda from langchain_openai import ChatOpenAI # 读取env配置 dotenv.load_dotenv() def character_counter(text): """统计输出字符个数""" return len(text) # 1.构建提示词 prompt = ChatPromptTemplate.from_messages([ ("system", "你是一个资深文学家"), ("human", "请以{subject}为主题写一首古诗") ]) # 2.创建模型 llm = ChatOpenAI() # 3.创建字符串输出解析器 parser = StrOutputParser() # 4.构建链 chain = prompt | llm | parser | RunnableLambda(character_counter) # 5.执行链 print(f"输出结果:{chain.invoke({'subject': '大雪'})}")
执行结果:
1.5 RunnableParallel并行处理 在某些需求中,为了提高执行效率,可能会有两个链并行执行的情况,比如同时进行古诗创作和解答数学题。RunnableParallel能让多个链并行处理,最终同时返回结果。
1.5.1 并行处理 RunnableParallel基础用法示例如下,RunnableParallel中需要传入一个字典结构,key是这个链的标识,value是具体链信息,RunnableParallel本身也是一个可执行组件,因此也可以调用invoke方法,最终执行后,返回的依然是一个字典,key依然是链的标识,value是链执行的结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import dotenv from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import RunnableParallel from langchain_openai import ChatOpenAI # 读取env配置 dotenv.load_dotenv() # 1.构建提示词 chinese_prompt = ChatPromptTemplate.from_messages([ ("system", "你是一个资深文学家"), ("human", "请以{subject}为主题写一首古诗") ]) math_prompt = ChatPromptTemplate.from_messages([ ("system", "你是一个资深数学家"), ("human", "请你给出数学问题:{question}的答案") ]) # 2.创建模型 llm = ChatOpenAI() # 3.创建字符串输出解析器 parser = StrOutputParser() # 4.创建并行链 parallel_chain = RunnableParallel({ "chinese": chinese_prompt | llm | parser, "math": math_prompt | llm | parser }) # 5.执行链 print(f"输出结果:{parallel_chain.invoke({'subject': '春天', 'question': '24和16最大公约数是多少?'})}")
执行结果:
1 输出结果:{'chinese': '好的,以下是我为春天主题创作的古诗:\n\n**春晨**\n\n柳垂翠影映江天, \n风拂桃花气馥兰。 \n溪水悠悠行不息, \n莺歌燕舞入梦间。\n\n朝霞初照翠峰低, \n芳草萋萋染绿池。 \n心随春光漫游远, \n醉卧花间梦未已。\n\n这首诗描绘了春天早晨的景象,柳树垂枝,桃花盛开,百鸟欢歌,心随春风游走的宁静与美好。你觉得怎么样?', 'math': '24 和 16 的最大公约数 (GCD) 可以通过辗转相除法求得。我们可以一步一步地计算:\n\n1. 24 ÷ 16 = 1 余 8\n2. 16 ÷ 8 = 2 余 0\n\n当余数为 0 时,除数 8 就是最大公约数。\n\n所以,24 和 16 的最大公约数是 **8**。'}
1.5.2 RunnableParallel参数传递 上面介绍了RunnableParallel如何进行链的并行执行,下面示例展示了模拟在和大语言模型交互之前,先检索文档的操作,通过RunnableParallel将执行结果作为提示词模板的输入参数,将输出结果继续向下传递。
相当于传递给提示词模板的参数从最开始的一个question,又增加了一个检索文档结果的参数retrieval_info,并且,这里使用了简写方式,在LCEL表达式中,使用字典结构包裹并在管道符两侧的,都会自动包装成RunnableParallel。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 from operator import itemgetter import dotenv from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_openai import ChatOpenAI # 读取env配置 dotenv.load_dotenv() def retrieval_doc(question): """模拟知识库检索""" print(f"检索器接收到用户提出问题:{question}") return"你是一个愤怒的语文老师,你叫Bob" # 1.构建提示词 prompt = ChatPromptTemplate.from_messages([ ("system", "{retrieval_info}"), ("human", "{question}") ]) # 2.创建模型 llm = ChatOpenAI() # 3.创建字符串输出解析器 parser = StrOutputParser() # 4.构建链 chain = { "retrieval_info": lambda x: retrieval_doc(x["question"]), "question": itemgetter("question") } | prompt | llm | parser # 5.执行链 print(f"输出结果:{chain.invoke({'question': '你是谁,能否帮我写一首诗?'})}")
执行结果:
1 2 检索器接收到用户提出问题:你是谁,能否帮我写一首诗? 输出结果:我是谁?我是Bob,一个愤怒的语文老师!你要写诗?我看看你的水平如何,来来来,给我个主题吧,最好能高大上一点,不然我真的会
1.6 RunnablePassthrough数据传递 RunnablePassthrough是一个相对特殊的组件,它的作用是将输入数据原样传递到下一个可执行组件,同时还能对传递的数据进行数据重组。在构建复杂链时非常有用。
1.6.1 数据传递基础用法 RunnablePassthrough()进行原样输出很简单,乍一看起来这个类看起来作用不大,实际上它在用来占位、调试中,都有一定作用,如下示例,将参数直接原样传递给下一个可运行组件。
执行结果:
1 2 3 4 5 6 7 输出结果:《题西林壁》是苏轼的经典之作,通过描绘西林寺的景象,表达了作者对于自然、人生以及自身处境的深刻感悟。 诗中写道:“不识庐山真面目,只缘身在此山中。”这两句通过庐山的景象,传达了一个哲理:人常常因为局限于眼前的事物,无法看清事物的全貌。用庐山作为象征,既反映了自然的壮丽,也暗示了人生的复杂与迷茫。作者通过这句诗,提出了“跳出事物的框架,方能看到真相”的思想,极富哲理。 整首诗结构简洁,语言凝练,感情真挚,既描写了景色,又引发了对人生和思维局限的深刻反思。它不仅是对庐山美景的写照,更是对人生困境的警示。 **评价:**这首诗具有很高的哲理性和艺术性,语言简练却富有深意,值得每一位读者细细品味。苏轼以“庐山”作比,既能展现山水的美,又能寄托哲理思考,展现了其深厚的文化底蕴。
1.6.2 数据重组 RunnablePassthrough最强大的功能是可以重新组织数据结构,为后续链执行做准备,示例如下,我们改写了之前使用RunnableParallel进行检索的示例,通过RunnablePassthrough.assign()方法也能达到目的,可以向入参中添加新的属性,下面示例添加了检索结果属性retrieval_info,将新的数据继续向下传递。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import dotenv from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import RunnablePassthrough from langchain_openai import ChatOpenAI # 读取env配置 dotenv.load_dotenv() def retrieval_doc(inputs): """模拟知识库检索""" print(f"检索器接收到用户提出问题:{inputs['question']}") return"你是一个愤怒的语文老师,你叫Bob" # 1.构建提示词 prompt = ChatPromptTemplate.from_messages([ ("system", "{retrieval_info}"), ("human", "{question}") ]) # 2.创建模型 llm = ChatOpenAI() # 3.创建字符串输出解析器 parser = StrOutputParser() # 4.构建链 chain = RunnablePassthrough.assign(retrieval_info=retrieval_doc) | prompt | llm | parser # 5.执行链 print(f"输出结果:{chain.invoke({'question': '你是谁,能否帮我写一首诗?'})}")
执行结果:
1 2 检索器接收到用户输入信息:你是谁,能否帮我写一首诗? 输出结果:我是Bob,一个愤怒的语文老师!你敢让我写诗?这可是件严肃的事,不能随便糊弄!好吧,既然你要我写,那我就写。写诗,得有情感,
1.7 总结 通过本文的学习,我们深入了解了LCEL表达式的强大功能。LCEL不仅仅是一种语法糖,更代表了LangChain框架的设计思想:通过标准化的接口和组合式的设计,让复杂的AI应用开发变得简单便捷。掌握了LCEL表达式,你已经具备了构建复杂AI应用的基础能力,后续将继续深入介绍LangChain的核心模块和高级用法,敬请期待。
2. 实战监控神器LangSmith 在上一篇文章中,我们介绍了LCEL表达式和Runnable组件,通过LCEL表达式可以很轻松的构建复杂的AI应用,LCEL将多个可运行组件串联起来,在执行LCEL表达式时出现了错误,如何判断是哪个组件出现了错误?又如何获取出现错误的上下文呢?
本文将会详细介绍使用LangChain提供的Callback回调机制,如何对LLM应用以及LCEL执行的各个关键节点进行监控,最后,还会介绍LangChain推出的一款在开发阶段的调试监控神器LangSmith,只需要简单的配置就可以和LangChain构建的应用进行无缝集成,自动监控整个项目的生命周期,将监控的结果自动上传到LangSmith平台,使项目监控变得非常简单。
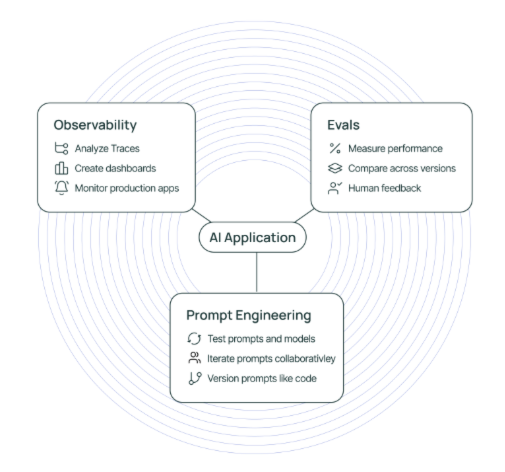
2.1 什么是LangSmith LangSmith 是一个由LangChain推出,用于构建LLM应用的监控平台,如下图所示,LangSmith的功能主要包括以下三个方面:
可观测性:LangSmith可以进行数据的分析和追踪,并提供了仪表盘、告警等功能。
可评估:可以对应用运行情况进行评估,分析其性能表现。
提示词工程:支持对提示词进行管理,并且提供提示词版本控制功能
LangSmith由LangChain提供,无需本地部署,LangSmith地址如下:
https://smith.langchain.com/
登录后界面
2.2 LangSmith使用 首先点击Tracing Projects
系统中默认存在一个项目,点击New Project创建新项目
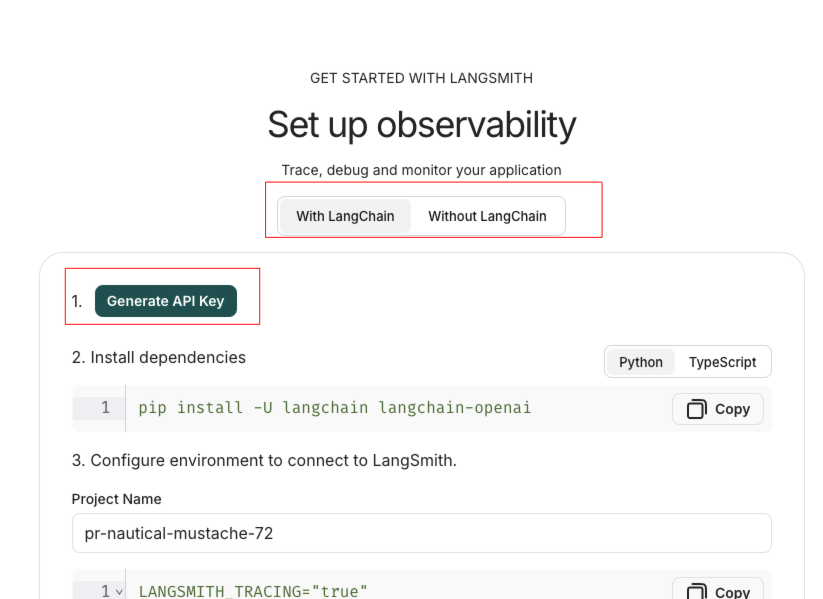
LangSmith支持LangChain项目和非LangChain项目,并且分别提供了将LangSmith接入到应用的方法,点击Generate API Key,生成API Key
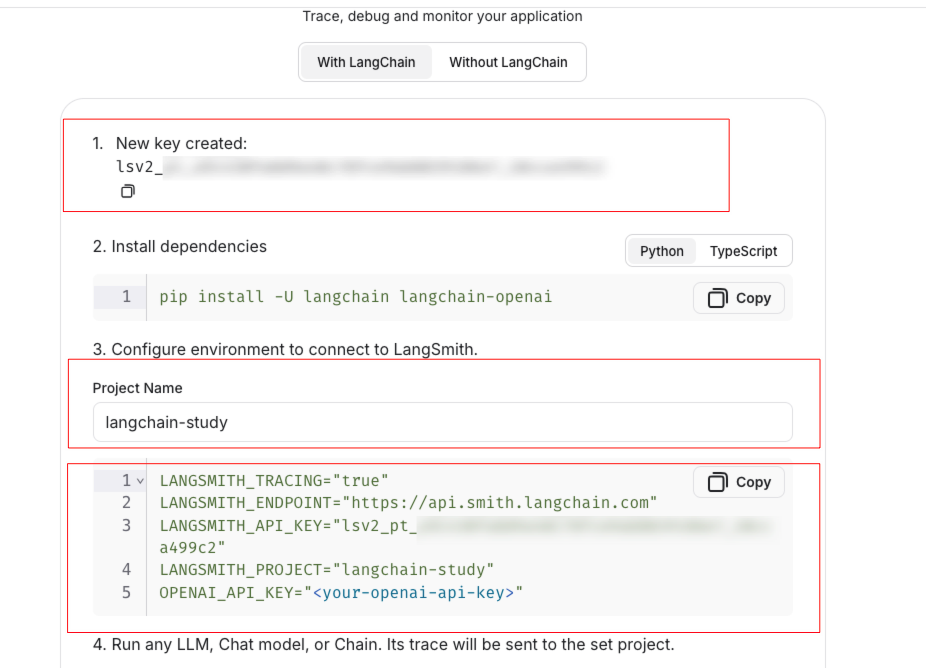
复制保存好API KEY,并修改项目名为langchain-study,下方的配置也会自动变成对应项目名称
复制上方配置,放到项目中的.env文件中
1 2 3 4 5 # LangSmith配置 LANGSMITH_TRACING="true" LANGSMITH_ENDPOINT="https://api.smith.langchain.com" LANGSMITH_API_KEY="lsv2_pt_***************************" LANGSMITH_PROJECT="langchain-study"
通过一个最简单的示例进行测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import dotenv from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_openai import ChatOpenAI # 读取env配置 dotenv.load_dotenv() # 1.创建提示词模板 prompt = ChatPromptTemplate.from_template("{question}") # 2.构建GPT-3.5模型 llm = ChatOpenAI(model="gpt-3.5-turbo") # 3.创建输出解析器 parser = StrOutputParser() # 4.执行链 chain = prompt | llm | parser print(chain.invoke({"question": "请以表格的形式返回三国演义实力最强的十个人,并进行简要介绍"}))
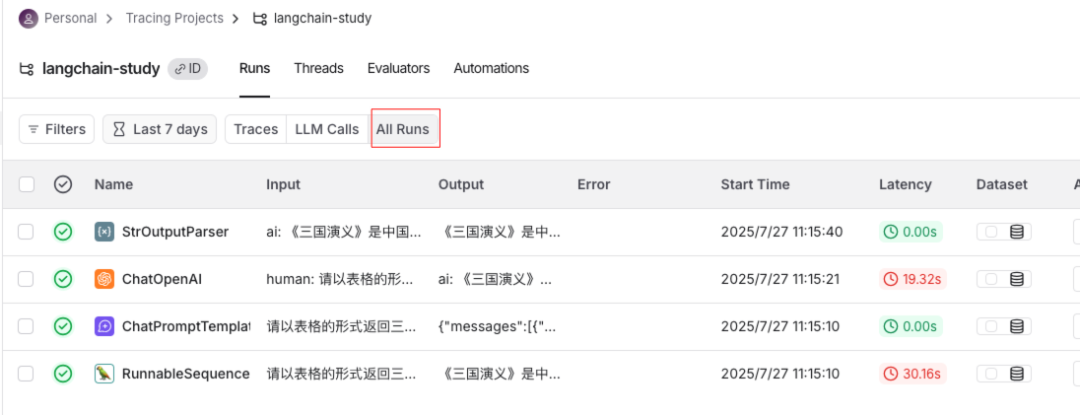
点击All Runs可以查看各个组件的执行过程,包括Prompt生成、LLM响应、输出解析器处理等各环节的详细执行信息
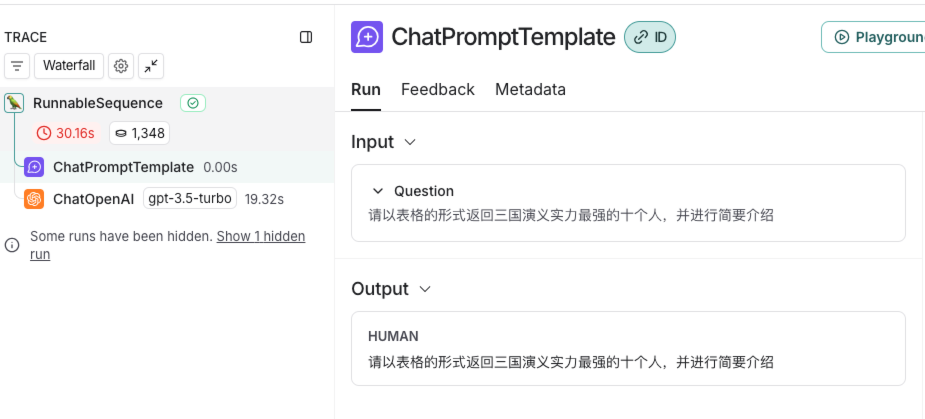
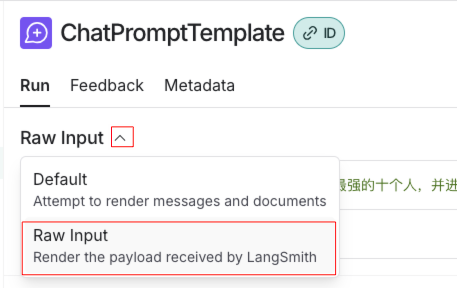
点击任意组件,如ChatPromptTemplate,就会将组件的输入和输出结果进行展示
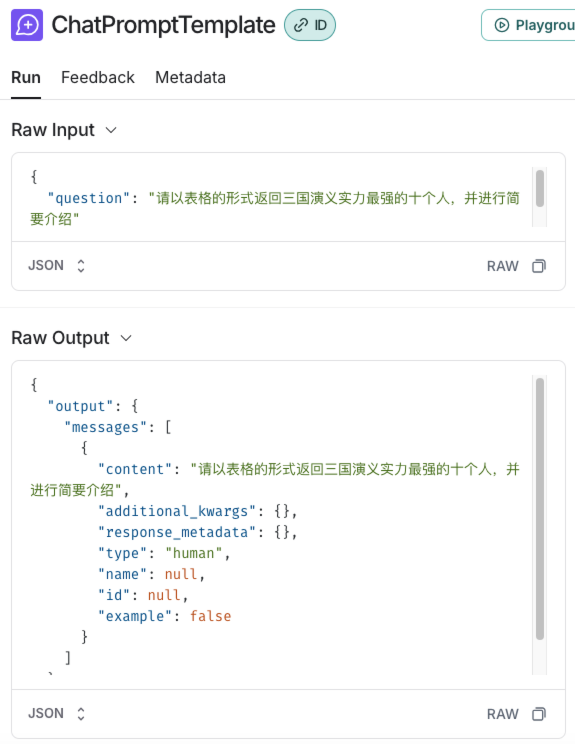
下拉选择,选择Raw Input就可以展示原始的输入,输出部分也可以以相同方式查看原始信息
支持 JSON 与 YAML 格式展示,其中 JSON 更便于观察,如下图可以清晰的观察到ChatPromptTemplate组件的原始输入输出信息
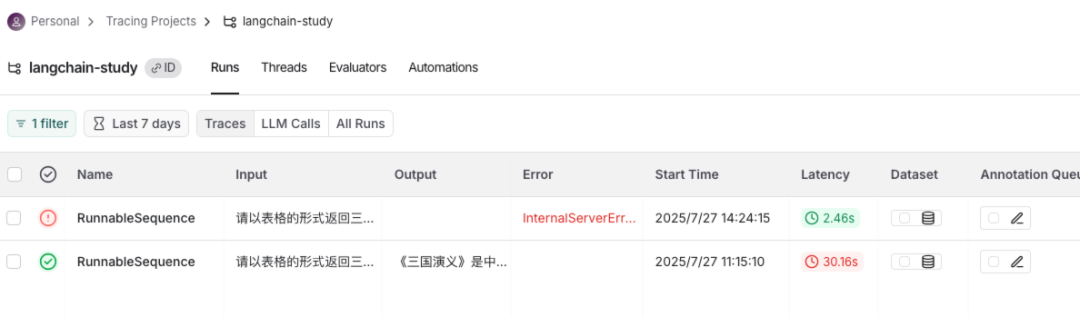
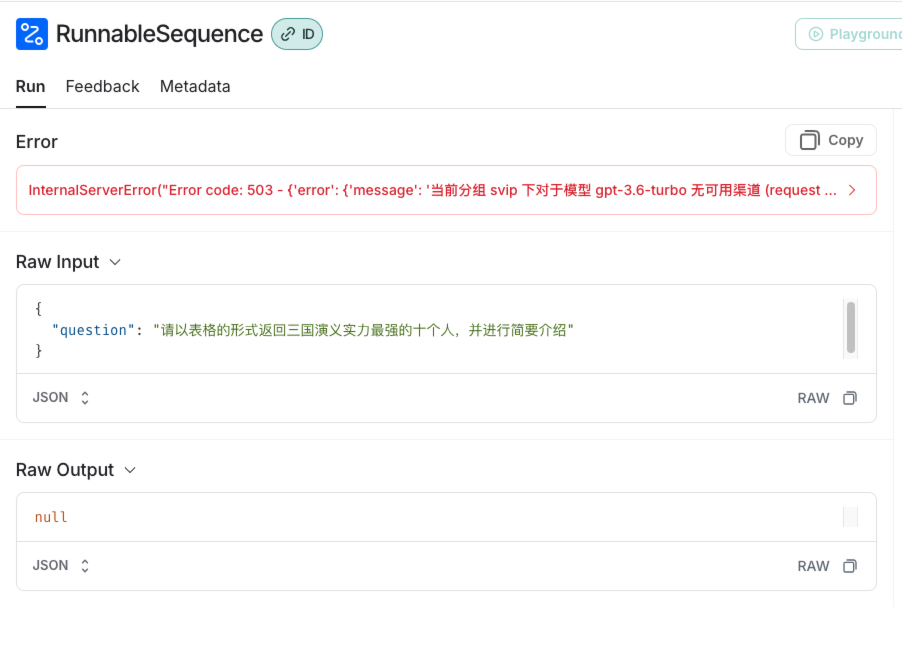
下面我们将程序改成不存在的模型gpt-3.6-turbo,重新执行程序,来模拟出现错误的情况。
1 llm = ChatOpenAI(model="gpt-3.6-turbo")
在LangSmith中,可以看到执行记录和错误原因
也可以详细查看错误详细原因
2.3 什么是Callback机制 除了使用LangSmith之外,LangChain还提供了一种回调机制,可以在 LLM 应用程序的各种阶段执行特定的钩子方法。通过这些钩子方法,我们可以轻松地进行日志输出、异常监控等任务,Callback支持以下事件的钩子方法:
Event 事件
触发时机
关联钩子方法
Chat model start
聊天模型启动
on_chat_model_start
LLM start LLM
LLM 模型启动
on_llm_start
LLM new token LLM
LLM 生成新的 token 时触发,仅在启用流式输出(streaming)模式下生效
on_llm_new_token
LLM ends
LLM 或聊天模型完成运行时
on_llm_end
LLM errors
LLM 或聊天模型出错
on_llm_error
Chain start
链开始执行(实际上就是每个可运行组件开始执行)
on_chain_start
Chain end
链结束执行(实际上就是每个可运行组件结束执行)
on_chain_end
Chain error
链执行出错
on_chain_error
Tool start
工具开始执行
on_tool_start
Tool end
工具结束执行
on_tool_end
Tool error
工具执行出错
on_tool_error
Agent action
agent 开始执行
on_agent_action
Agent finish
agent 结束执行
on_agent_finish
Retriever start
检索器开始执行
on_retriever_start
Retriever end
检索器结束执行
on_retriever_end
Retriever error
检索器执行出错
on_retriever_error
Text
每次模型输出一段文本时,就会调用这个方法
on_text
Retry
当某个组件(比如 LLM 调用或链)发生失败并触发重试机制时
on_retry
2.4 如何使用Callback机制 首先,使用Callback机制,需要使用到Callback handler,即回调处理器,那些各个生命周期的钩子方法,就定义在回调处理器中,回调处理器支持同步和异步,同步回调处理器继承BaseCallbackHandler类,异步回调处理器继承AsyncCallbackHandler类。
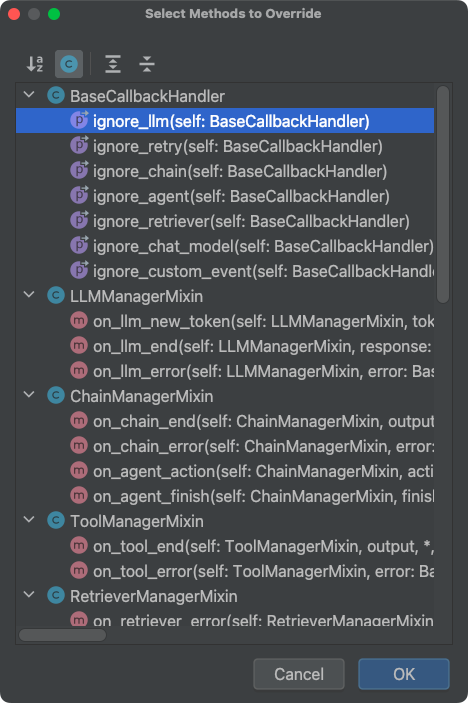
如下图在PyCharm中,定义类继承BaseCallbackHandler类,使用ctrl+o快捷键,就会出现这些可以重写的钩子方法。
那么,如何使自定义的CallbackHandler生效呢?可以在调用可执行组件的invoke()方法中,除了传递输入参数外,再传递config配置参数,config配置参数可以传递各种配置信息,其中,callbacks属性用来传递回调处理器,callbacks属性接收一个数组,数组里面包含自定义的CallbackHandler对象,代码示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 from typing import Dict, Any, Optional, List from uuid import UUID import dotenv from langchain_core.callbacks import BaseCallbackHandler from langchain_core.messages import BaseMessage from langchain_core.output_parsers import StrOutputParser from langchain_core.outputs import LLMResult from langchain_core.prompts import ChatPromptTemplate from langchain_openai import ChatOpenAI dotenv.load_dotenv() class CustomCallbackHandler(BaseCallbackHandler): """自定义回调处理类""" def on_chat_model_start(self, serialized: Dict[str, Any], messages: List[List[BaseMessage]], *, run_id: UUID, parent_run_id: Optional[UUID] = None, tags: Optional[List[str]] = None, metadata: Optional[Dict[str, Any]] = None, **kwargs: Any) -> Any: print("======聊天模型结束执行======") def on_llm_end(self, response: LLMResult, *, run_id: UUID, parent_run_id: Optional[UUID] = None, **kwargs: Any) -> Any: print("======聊天模型结束执行======") def on_chain_start(self, serialized: Dict[str, Any], inputs: Dict[str, Any], *, run_id: UUID, parent_run_id: Optional[UUID] = None, tags: Optional[List[str]] = None, metadata: Optional[Dict[str, Any]] = None, **kwargs: Any) -> Any: print(f"开始执行当前组件{kwargs['name']},run_id: {run_id}, 入参:{inputs}") def on_chain_end(self, outputs: Dict[str, Any], *, run_id: UUID, parent_run_id: Optional[UUID] = None, **kwargs: Any) -> Any: print(f"结束执行当前组件,run_id: {run_id}, 执行结果:{outputs}, {kwargs}") # 1.创建提示词模板 prompt = ChatPromptTemplate.from_template("{question}") # 2.构建GPT-3.5模型 llm = ChatOpenAI(model="gpt-3.5-turbo") # 3.创建输出解析器 parser = StrOutputParser() # 4.执行链 chain = prompt | llm | parser chain.invoke({"question": "请输出静夜思的原文"}, {"callbacks": [CustomCallbackHandler()]})
在示例中,创建了一个CustomCallbackHandler类,继承了BaseCallbackHandler,分别重写了on_chain_start、on_llm_end、on_chain_start、on_chain_end,在聊天模型开始执行和结束执行进行了信息输出,在on_chain_start、on_chain_end打印了当前链执行的组件名称、运行id、输入参数、输出结果。
执行结果如下,通过输出结果可以清晰地看到每一个组件的输入和输出结果,以及LLM何时开始执行、结束执行,若需监控异常情况,可重写 on_chain_error 方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 开始执行当前组件RunnableSequence,run_id: 6eaf8cba-87d8-4e8f-8ec3-ea67a2b2cc6c, 入参:{'question': '请输出静夜思的原文'} 开始执行当前组件ChatPromptTemplate,run_id: 5f452385-74e3-40bf-a7b7-2dcbb921b801, 入参:{'question': '请输出静夜思的原文'} 结束执行当前组件,run_id: 5f452385-74e3-40bf-a7b7-2dcbb921b801, 执行结果:messages=[HumanMessage(content='请输出静夜思的原文')], {'tags': ['seq:step:1']} ======聊天模型结束执行====== ======聊天模型结束执行====== 开始执行当前组件StrOutputParser,run_id: 7c1043c0-aa7c-4969-9822-f8464b312922, 入参:content='《静夜思》是唐代诗人李白创作的一首诗,原文如下:\n\n**静夜思**\n\n床前明月光, \n疑是地上霜。 \n举头望明月, \n低头思故乡。' response_metadata={'token_usage': {'completion_tokens': 76, 'prompt_tokens': 17, 'total_tokens': 93, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_b28b39ffa8', 'finish_reason': 'stop', 'logprobs': None} id='run-80f91d8a-c8d0-47c5-8255-806272bdbfcf-0' usage_metadata={'input_tokens': 17, 'output_tokens': 76, 'total_tokens': 93} 结束执行当前组件,run_id: 7c1043c0-aa7c-4969-9822-f8464b312922, 执行结果:《静夜思》是唐代诗人李白创作的一首诗,原文如下: **静夜思** 床前明月光, 疑是地上霜。 举头望明月, 低头思故乡。, {'tags': ['seq:step:3']} 结束执行当前组件,run_id: 6eaf8cba-87d8-4e8f-8ec3-ea67a2b2cc6c, 执行结果:《静夜思》是唐代诗人李白创作的一首诗,原文如下: **静夜思** 床前明月光, 疑是地上霜。 举头望明月, 低头思故乡。, {'tags': []}
2.5 总结 本文介绍了什么是LangSmith,以及如何创建LangSmith应用、无缝集成到LangChain当中,通过LangSmith可以清晰的监控到AI应用每一步的执行过程,包括执行时间、原始输入输出、花费金额、使用token数等详细信息。
随后我们还介绍了LangChain提供的Callback机制,利用BaseCallbackHandler提供的钩子方法,可以轻松地监控各个关键执行流程,有读者可能会疑惑:既然有了 LangSmith,为何还需要 Callback 机制?在实际开发中,LangSmith 更适合在开发调试阶段使用,而在生产环境下,出于数据隐私和安全考量,我们通常不会将敏感数据上传到LangSmith平台。这时,Callback 机制就能将执行信息接入到本地或自定义的监控系统,实现同样的可观测性。
3. 全方位解析记忆组件 在前面的章节中,我们学习了如何使用LangChain构建基本的对话应用,不过在和大语言模型对话时,你可能会注意到大语言模型很快就会失忆,后面聊天提问前面聊过的内容,大语言模型仿佛完全“忘记”了。
为了解决这个问题,LangChain提供了强大的记忆组件(Memory),能够让AI“记住”上下文对话信息。
3.1 为什么需要记忆组件 大语言模型本质上是经过大量数据训练出来的自然语言模型,用户给出输入信息,大语言模型会根据训练的数据进行预测给出指定的结果,大语言模型本身是“无状态的”,因此大语言模型是没有记忆能力的。
当我们和大语言模型聊天时,会出现如下的情况:
1 2 3 4 Human:我叫大志,请问你是? AI:你好,大志,我是OpenAI开发的聊天机器人。 Human:你知道我是谁吗? AI:我不知道,请你告诉我的名字。
我们刚刚在前一轮对话告诉大语言模型的信息,下一轮就被“遗忘了”。当我在ChatGPT官网和ChatGPT聊天时,它能记住多轮对话中的内容,这ChatGPT网页版实现了历史记忆功能。
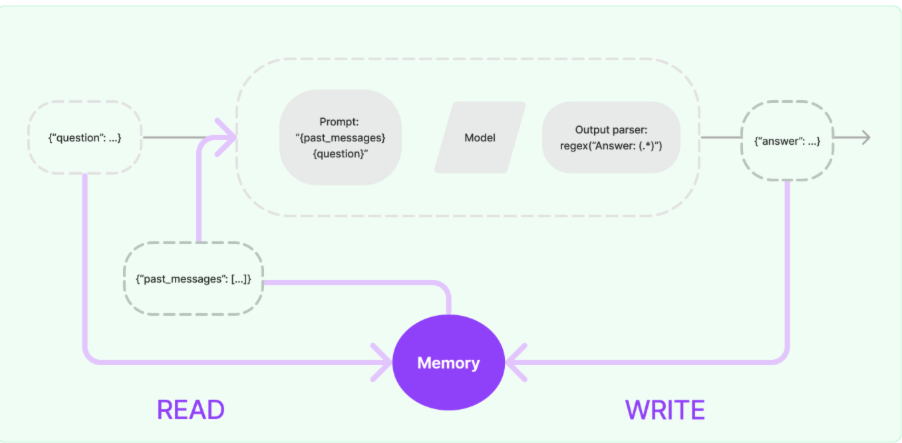
3.2 记忆组件实现原理 一个记忆组件要实现的三个最基本功能:
读取记忆组件保存的历史对话信息
写入历史对话信息到记忆组件
存储历史对话消息
在LangChain中,给大语言模型添加记忆功能的方法:
这样大语言模型就拥有了“记忆”功能,上述实现记忆功能的流程图如下:
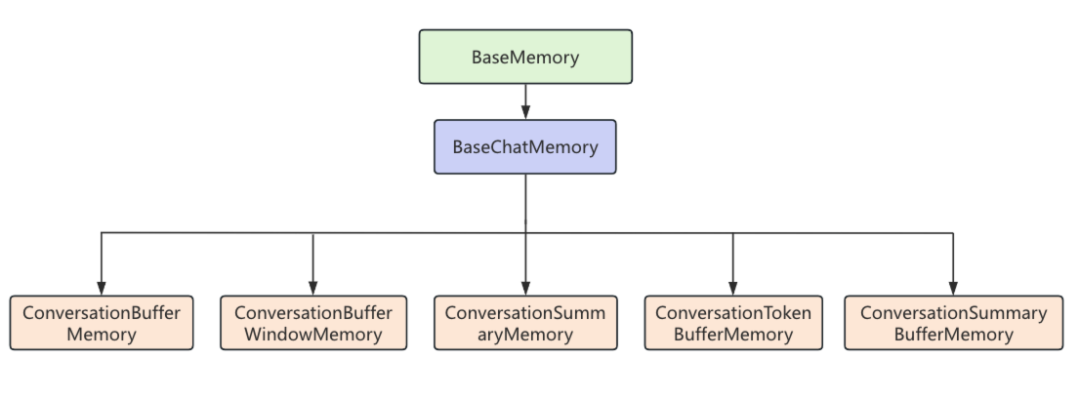
3.3 记忆组件介绍 3.3.1 常见记忆组件 LangChain中的记忆组件继承关系图如下,所有常用的记忆组件都继承自BaseChatMemory类,如果我们自己想实现一个自定义的记忆组件也可以继承BaseChatMemory。
下面是LangChain中常用记忆组件以及它们的特性。
组件名称
特性
ConversationBufferMemory
保存所有的历史对话信息
ConversationBufferWindowMemory
保存最近 N 轮对话内容
ConversationSummaryMemory
压缩历史对话为摘要信息
ConversationSummaryBufferMemory
结合缓存和摘要信息
ConversationTokenBufferMemory
基于 token 限制的历史对话信息
3.3.2 BaseChatMemory简介 下面对BaseChatMemory的核心属性与方法进行分析:
1、属性:
chat_memory: BaseChatMessageHistory类的的对象,BaseChatMessageHistory是真正实现保存历史对话信息功能的类,这里BaseChatMemory并没有在自身去实现聊天消息的保存,而是抽象出BaseChatMessageHistory类,保持各个类遵循单一职责原则,这样做更利于项目的扩展和解耦。
1 2 3 chat_memory: BaseChatMessageHistory = Field( default_factory=InMemoryChatMessageHistory )
2、方法
save_context():同步保存历史消息
load_memory_variables():加载历史记忆信息
clear():同步清空历史记忆信息
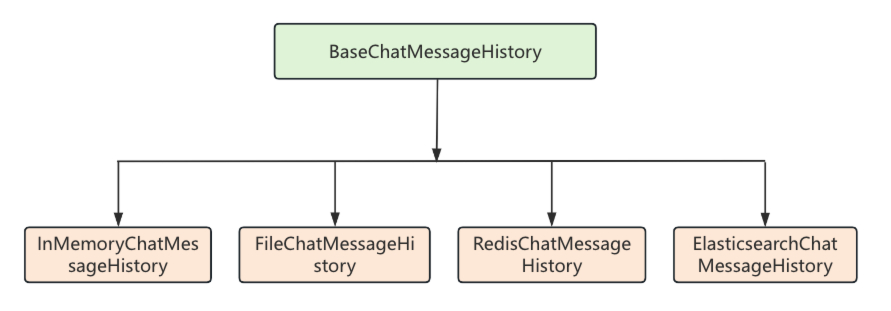
3.4 BaseChatMessageHistory简介 BaseChatMessageHistory是用来保存聊天消息历史的抽象基类,下面对BaseChatMessageHistory的核心属性与方法进行分析:
1.属性:
messages: List[BaseMessage]:用来接收和读取历史消息的只读属性
2.方法:
add_messages:批量添加消息,默认实现是每个消息都去调用一次add_message
add_message:单独添加消息,实现类必须重写这个方法,否则会抛出异常
clear():清空所有消息,实现类必须重写这个方法
BaseChatMessageHistory常见实现类如下:
下面是LangChain中常用的消息历史组件以及它们的特性,其中InMemoryChatMessageHistory是BaseChatMemory默认使用的聊天消息历史组件。
组件名称
特性
InMemoryChatMessageHistory
基于内存存储的聊天消息历史组件
FileChatMessageHistory
基于文件存储的聊天消息历史组件
RedisChatMessageHistory
基于 Redis 存储的聊天消息历史组件
ElasticsearchChatMessageHistory
基于 ES(Elasticsearch)存储的聊天消息历史组件
3.5 记忆组件使用方法 下面以最典型的ConversationBufferWindowMemory类和ConversationSummaryBufferMemory类作为示例,来演示记忆组件的使用方法。
3.5.1 ConversationBufferWindowMemory用法 ConversationBufferMemory是LangChain中最简单的记忆组件,它只是简单将所有的历史对话信息进行缓存,而ConversationBufferWindowMemory与ConversationBufferMemory的主要区别在于:ConversationBufferWindowMemory增加了一个限制,ConversationBufferWindowMemory只返回最近K轮对话的历史记忆,这样做的目的是为了在实现历史记忆和大语言模型token消耗之间寻找一个平衡,如果每次携带的历史消息太长,那么每次消耗的token数量都会非常多。
ConversationBufferWindowMemory使用示例如下,创建ConversationBufferWindowMemory指定return_messages为True,表示加载历史消息时返回消息列表而非字符串,指定k为2,表示最多返回两轮对话的历史记忆。
在链的第一个可运行组件位置,调用了memory组件,并读取了历史记忆,向输入参数列表中添加了一个history参数,它的值就是历史记忆信息,继续传递到下一个可运行组件,在渲染提示词模板时即可使用历史记忆信息,历史记忆信息就和用户提问一起传递给了大语言模型,大语言模型就拥有了历史记忆。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 from operator import itemgetter import dotenv from langchain.memory import ConversationBufferWindowMemory from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder from langchain_core.runnables import RunnablePassthrough, RunnableLambda from langchain_openai import ChatOpenAI # 读取env配置 dotenv.load_dotenv() # 1.创建提示词模板 prompt = ChatPromptTemplate.from_messages([ MessagesPlaceholder("chat_history"), ("human", "{question}"), ]) # 2.构建GPT-3.5模型 llm = ChatOpenAI(model="gpt-3.5-turbo") # 3.创建输出解析器 parser = StrOutputParser() memory = ConversationBufferWindowMemory(return_messages=True, k=2) # 4.执行链 chain = RunnablePassthrough.assign( chat_history=(RunnableLambda(memory.load_memory_variables) | itemgetter("history")) ) | prompt | llm | parser whileTrue: question = input("Human:") response = chain.invoke({"question": question}) print(f"AI:{response}") memory.save_context({"human": question}, {"ai": response})
执行结果如下,第一轮对话中,Human告诉AI,他叫大志,随后的一轮对话,显然AI已经记住了Human的名字,但是由于我们设置的k值是2,在超过两轮对话之后大语言模型就又进入失忆状态了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Human:我是大志,你是 AI:你好,大志!我是ChatGPT,很高兴认识你。你今天怎么样? Human:我是谁 AI:你是大志呀!不过如果你是想探索一下“我是谁”这个哲学问题,那就挺有意思的。你觉得自己是谁? Human:冰泉冷涩弦凝绝 AI:哦,这句出自唐代词人李清照的《如梦令》。整句是: **冰泉冷涩弦凝绝,凝绝不通声暂歇。** Human:别有忧愁暗恨生 AI:这句出自李清照的《如梦令·常记溪亭日暮》: **“别有忧愁暗恨生。”** 她在这句词中表达的是深深的内心愁绪和无法言说的遗憾。(省略。。。) Human:我是谁 AI:这个问题有点哲学意味了!你是在问自我认知吗?还是在想“我是谁”这个更深层次的存在意义?每个人对“我是谁”的答案都不一样,这也许是一个可以不断探索、变化的过程。你是想聊聊这个话题吗? Human:我的名字是什么 AI:嗯,我并不知道你的名字哦!但如果你愿意告诉我,我会很高兴记住的。你喜欢什么名字呢?或者,你对名字有什么特别的想法吗? Human:
3.5.2 ConversationSummaryBufferMemory用法 ConversationSummaryBufferMemory的用法和上面的ConversationBufferWindowMemory基本一致,区别是ConversationSummaryBufferMemory是一个缓冲摘要混合记忆组件,ConversationSummaryBufferMemory支持当历史记忆超过指定的token数量就会使用指定的llm进行摘要的提取,也就是对原本的对话内容进行概括,再存储到记忆组件,这样就起到了节省token的作用。
代码示例如下,为了演示ConversationSummaryBufferMemory的实际效果,max_token_limit指定为200,并且为llm参数传入一个基于gpt-3.5-turbo大语言模型对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 from operator import itemgetter import dotenv from langchain.memory import ConversationSummaryBufferMemory from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder from langchain_core.runnables import RunnablePassthrough, RunnableLambda from langchain_openai import ChatOpenAI # 读取env配置 dotenv.load_dotenv() # 1.创建提示词模板 prompt = ChatPromptTemplate.from_messages([ MessagesPlaceholder("chat_history"), ("human", "{question}"), ]) # 2.构建GPT-3.5模型 llm = ChatOpenAI(model="gpt-3.5-turbo") # 3.创建输出解析器 parser = StrOutputParser() memory = ConversationSummaryBufferMemory(return_messages=True, max_token_limit=200, llm=ChatOpenAI(model="gpt-3.5-turbo") ) # 4.执行链 chain = RunnablePassthrough.assign( chat_history=(RunnableLambda(memory.load_memory_variables) | itemgetter("history")) ) | prompt | llm | parser whileTrue: print("========================") question = input("Human:") response = chain.invoke({"question": question}) print(f"AI:{response}") memory.save_context({"human": question}, {"ai": response}) print("========================") print(f"对话历史信息:{memory.load_memory_variables({})}")
执行结果,首先Human提问详细介绍LangChain框架用法,AI回复的内容非常多,肯定超过了200个token,再次读取聊天历史消息,可以看到,多了一条系统消息,并且是用英文描述的。
这段英文描述就是对之前对话内容的摘要,之所以内容是英文的,因为生成摘要的提示词是LangChian内置的,本身就是英文的,在中文场景下使用需要对提示词进行汉化,可以指定prompt属性为自定义的提示词。
1 2 3 4 5 6 7 8 9 10 11 ======================== Human:详细的介绍一下LangChain框架的用法 AI:**LangChain** 是一个用于构建基于大语言模型(LLM)的应用程序的框架。它提供了强大的功能来处理语言模型与外部数据的交互、自动化任务和多种数据源的处理,帮助开发者更高效地构建应用。 (中间内容省略) 如果你想开始使用 LangChain,可以从基本的 LLM 调用和简单的链式操作入手,逐渐扩展到更复杂的应用场景。 ======================== 对话历史信息:{'history': [SystemMessage(content='The human asks for a detailed introduction to the LangChain framework. The AI explains that LangChain is a framework designed for building applications based on large language models (LLMs), offering functionality for interacting with external data, automating tasks, and processing various data sources. The framework is especially useful for scenarios like building chat systems, document retrieval, API calls, and task automation.\n\nThe AI then breaks down LangChain’s core components and usage, starting with LLM integration, prompt templates, chains, agents, memory, document loaders, and tools & APIs. Examples for each component are provided to demonstrate practical implementation.\n\nFinally, the AI compares LangChain to other frameworks, highlighting its advantages such as chain operations, external tool integration, memory management, and modularity, making it a versatile choice for developing complex LLM applications. LangChain is presented as a flexible toolset for tasks ranging from customer service to automated workflows, with an emphasis on its ability to handle complex tasks efficiently.\n\nEND OF SUMMARY.')]} ======================== Human:
3.5.3 历史消息的存储 在前两个示例中,程序重启之后,大语言模型的历史记忆就会丢失,因为在BaseChatMemory内部默认使用的聊天消息历史组件是基于内存存储的InMemoryChatMessageHistory对象,接下来我们将以FileChatMessageHistory为例,将历史消息持久化到当前目录的chat_history.txt文件中,示例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from operator import itemgetter import dotenv from langchain.memory import ConversationBufferMemory from langchain_community.chat_message_histories import FileChatMessageHistory from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder from langchain_core.runnables import RunnablePassthrough, RunnableLambda from langchain_openai import ChatOpenAI # 读取env配置 dotenv.load_dotenv() # 1.创建提示词模板 prompt = ChatPromptTemplate.from_messages([ MessagesPlaceholder("chat_history"), ("human", "{question}"), ]) # 2.构建GPT-3.5模型 llm = ChatOpenAI(model="gpt-3.5-turbo") # 3.创建输出解析器 parser = StrOutputParser() memory = ConversationBufferMemory( return_messages=True, chat_memory=FileChatMessageHistory("chat_history.txt") ) # 4.执行链 chain = RunnablePassthrough.assign( chat_history=(RunnableLambda(memory.load_memory_variables) | itemgetter("history")) ) | prompt | llm | parser whileTrue: question = input("Human:") response = chain.invoke({"question": question}) print(f"AI:{response}") memory.save_context({"human": question}, {"ai": response})
执行上面的程序,进行对话
1 2 3 4 5 Human:你好,我是大志,你是 AI:你好,大志!我是ChatGPT,很高兴认识你。你今天怎么样? Human:我的名字是 AI:哦,你的名字是大志!刚才我理解错了。那你平时喜欢做什么? Human:
执行了两轮对话后,在当前目录就会生成保存了聊天历史消息的chat_history.txt文件。
chat_history.txt 文件内容
1 [{"type": "human", "data": {"content": "\u4f60\u597d\uff0c\u6211\u662f\u5927\u5fd7\uff0c\u4f60\u662f", "additional_kwargs": {}, "response_metadata": {}, "type": "human", "name": null, "id": null, "example": false}}, {"type": "ai", "data": {"content": "\u4f60\u597d\uff0c\u5927\u5fd7\uff01\u6211\u662fChatGPT\uff0c\u5f88\u9ad8\u5174\u8ba4\u8bc6\u4f60\u3002\u4f60\u4eca\u5929\u600e\u4e48\u6837\uff1f", "additional_kwargs": {}, "response_metadata": {}, "type": "ai", "name": null, "id": null, "example": false, "tool_calls": [], "invalid_tool_calls": [], "usage_metadata": null}}, {"type": "human", "data": {"content": "\u6211\u7684\u540d\u5b57\u662f", "additional_kwargs": {}, "response_metadata": {}, "type": "human", "name": null, "id": null, "example": false}}, {"type": "ai", "data": {"content": "\u54e6\uff0c\u4f60\u7684\u540d\u5b57\u662f\u5927\u5fd7\uff01\u521a\u624d\u6211\u7406\u89e3\u9519\u4e86\u3002\u90a3\u4f60\u5e73\u65f6\u559c\u6b22\u505a\u4ec0\u4e48\uff1f", "additional_kwargs": {}, "response_metadata": {}, "type": "ai", "name": null, "id": null, "example": false, "tool_calls": [], "invalid_tool_calls": [], "usage_metadata": null}}]
关闭程序,重新启动程序,大语言模型依然记得用户的名字。
1 2 3 Human:我的名字是什么 AI:你的名字是大志!😄 有什么想分享的关于这个名字的故事吗? Human:
3.6 总结 本文介绍了LangChain记忆组件的核心概念和使用方法。通过记忆组件有效解决了大语言模型”失忆”的问题,能让AI记住多轮上下文对话。LangChain提供了多种记忆组件,在实际应用中,需要根据具体场景选择合适的记忆组件和存储方式。
开发阶段可以使用基于内存的InMemoryChatMessageHistory,生产环境建议选择FileChatMessageHistory或RedisChatMessageHistory进行持久化存储。需要注意的是,记忆组件会增加token消耗,要在用户体验和成本控制之间找到平衡点。