1. RAG
当我们在跟大语言模型交流时,会发现大语言模型只能回答训练数据范围内的事情,如果你问它一些超出训练数据之外的事情,AI的回答往往就是胡言乱语,或者给出错误的答案。
那么我们不禁会想到:大模型拥有如此强大的能力,是否能让大模型掌握一些特定领域的知识,甚至接入企业内部的知识库数据?来帮助我们实现业务需求。
这就是本文要介绍的技术——RAG(Retrieval Augmented Generation)即检索增强生成,本文将重点介绍RAG是什么以及使用LangChain实现RAG所需的关键组件,并分析它们之间的协作机制。具体实现细节将在后续文章中展开。
1.1 什么是RAG
RAG(Retrieval Augmented Generation)检索增强生成,RAG是一种将信息检索和大语言模型文本生成相结合的技术。简单来说,RAG就是在大语言模型生成答案之前,AI应用先从外部知识库中检索与用户提问相关的信息,然后将检索到的信息作为上下文通过提示词一起传递给大语言模型,从而让大语言模型根据检索出来的内容进行回答。
RAG解决了如下几个问题:
(1)知识边界问题:大语言模型所掌握的知识来源于训练数据,对超过自身训练数据以外的问题无法回答。
(2)知识更新问题:大语言模型训练完成后,除了重新训练之外无法继续获取最新的信息。
(3)幻觉问题:当大语言模型不确定答案时,编造一些错误信息,这种现象被称为幻觉。
(4)回答特定领域专业问题:目前参数比较大的大语言模型多数都是通用的模型,这些通用模型的知识面非常广,但是对特定领域知识了解的深度更低。
通过RAG技术就能在一定程度上解决上述的问题,让大语言模型拥有了获取特定领域知识的能力,并且给出准确、专业的回答。
1.2 如何实现RAG技术
RAG技术的落地主要由以下几个步骤组成:
(1)文档的收集
(2)文档处理
(3)文档数据向量化
(4)文档数据相似性检索
(5)构建提示词
(6)大语言模型生成结果
其中前三个步骤属于RAG的准备阶段,后三个步骤是RAG的使用阶段,下面分别介绍RAG每个步骤都需要完成哪些工作。
1.2.1 RAG准备阶段
主要负责知识库的构建,包括文档的收集、处理和向量化;
(1)文档的加载:对你需要让大模型了解的相关领域的文档材料进行整理,可以是word文档、PDF、PPT、TXT、CSV、HTML等等种类的文档,通过这些文档来构建一个知识库,作为大语言模型知识的来源。
(2)文档的处理:收集到的文档往往是很长很长并且存在一些换行和空白,不利于对文档进行检索,同时,还可能涉及隐私的数据,因此需要将收集到的文档进行加载、处理和分割,将一个大的文档分割成小块的文档片段。
(3)文档片段数据的向量化:如果仅将文档片段保存至传统关系型数据库中,再根据关键词进行模糊查询,往往效果较差。例如用户查询“如何种植马铃薯?”,数据库中的“土豆”内容很可能无法匹配,尽管两者语义相同。
1 | 种植土豆需要选择合适的土壤、进行催芽、适时播种、田间管理和收获。 |
因此,在文档检索的过程中需要使用向量数据库(如Pinecone、Weaviate等),什么是向量数据库呢?向量数据库(Vector Database)是一种专门用于存储高维向量的数据库,主要用于基于向量相似度的快速检索,例如人脸识别、图像检索、推荐系统、RAG 等场景。
将一个文档片段向量化需要使用文本嵌入模型,文本嵌入模型会根据文档片段的文本信息以不同的维度构建出一个高维向量,这个高维向量和文本片段的元数据信息将会一起保存到向量数据库,这就是文档文本片段向量化的过程。
1.2.2 RAG的使用阶段
用户提出问题后,系统从知识库中检索相关信息,并调用大语言模型生成回答。
(4)文档相似性检索:前面三个步骤属于RAG的准备阶段,下面将会进入使用阶段,当用户提出问题后,同样的会使用相同的文本嵌入模型对提问文本进行向量化,根据向量在向量数据库中进行相似性检索,并且可以传递一些过滤条件,最终将检索的文本片段的元数据信息返回,如文档片段ID,可通过返回的文档片段ID,在关系型数据库中定位到对应的原始文档内容。
(5)构建提示词:将使用相似性检索得到的文档片段信息,拼接到提示词中,作为供大语言模型参考的上下文信息。
(6)大语言模型生成结果:将渲染后的提示词传递给大语言模型,大语言模型输出相应结果。
1.3 LangChain中实现RAG功能组件
那么,如何将上述每个步骤落地实现?LangChain 框架提供了丰富的组件帮助我们搭建 RAG 应用,下面是关于这些核心组件的介绍:
| LangChain 组件 | 作用 | 常用组件类 |
|---|---|---|
| 文档加载器 | 对各种格式的文档信息进行加载 | Document(文档组件)、UnstructuredPDFLoader(PDF 文档加载器)、UnstructuredFileLoader(文件文档加载器)、UnstructuredMarkdownLoader(markdown 文档文本加载器) |
| 文档分割器 | 将加载的文档分割成文档片段 | RecursiveCharacterTextSplitter(递归字符文本分割器) |
| 文本嵌入模型组件 | 将文本信息向量化 | OpenAIEmbeddings(OpenAI 文本嵌入模型)、HuggingFaceEmbeddings(HuggingFace 文本嵌入模型) |
| 向量数据库组件 | 将向量和元数据信息保存到向量数据库 | VectorStore(向量数据库,不同向量数据库有不同的实现类) |
| 文本检索器 | 根据用户提问在向量数据库中进行检索 | VectorStoreRetriever(向量数据库检索器) |
1.4 LangChain中如何实现RAG功能
在RAG准备阶段,LangChain通过文档加载器对各种格式的文档进行加载,转换为LangChain中的文档对象,之后对文档对象进行分割,根据分割规则,分割成文档片段。
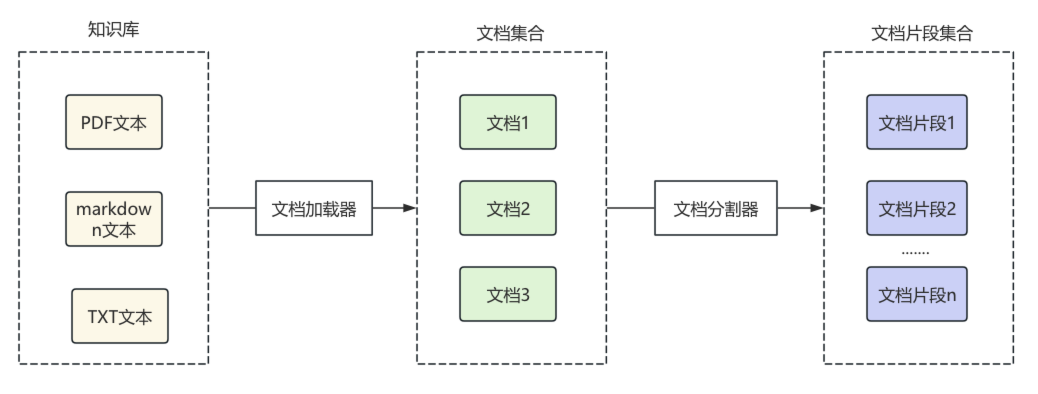
之后,将文档片段通过文本嵌入模型组件,转换为向量,通过向量数据库组件,保存到向量数据库,每个向量通常还会绑定原文内容、文档ID、来源等元数据信息,便于后面数据检索。
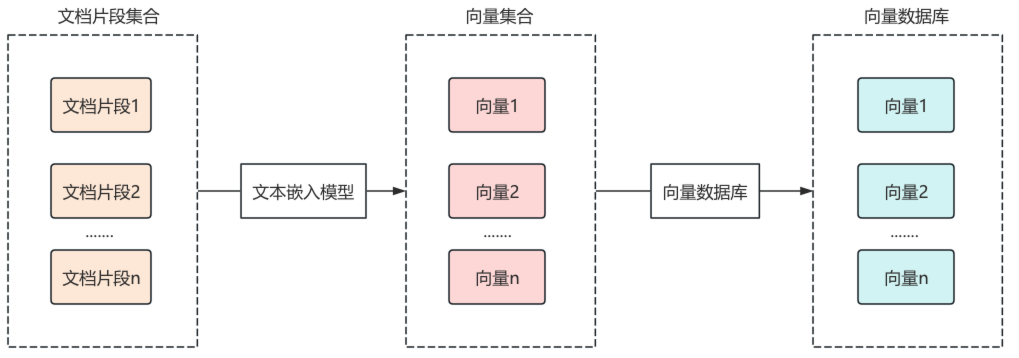
在RAG的使用阶段,用户首先提出问题,使用文本嵌入模型组件,将提问文本转换为向量数据,通过向量数据库检索器组件,进行相似性检索,返回关联的文本片段。
将相关的文档片段内容渲染到提示词模板中,作为提问问题的上下文传递给大语言模型,大语言模型输出结果,再传递给输出解析器,最终结果通过输出解析器处理后返回给用户,这样就完成了一次RAG检索。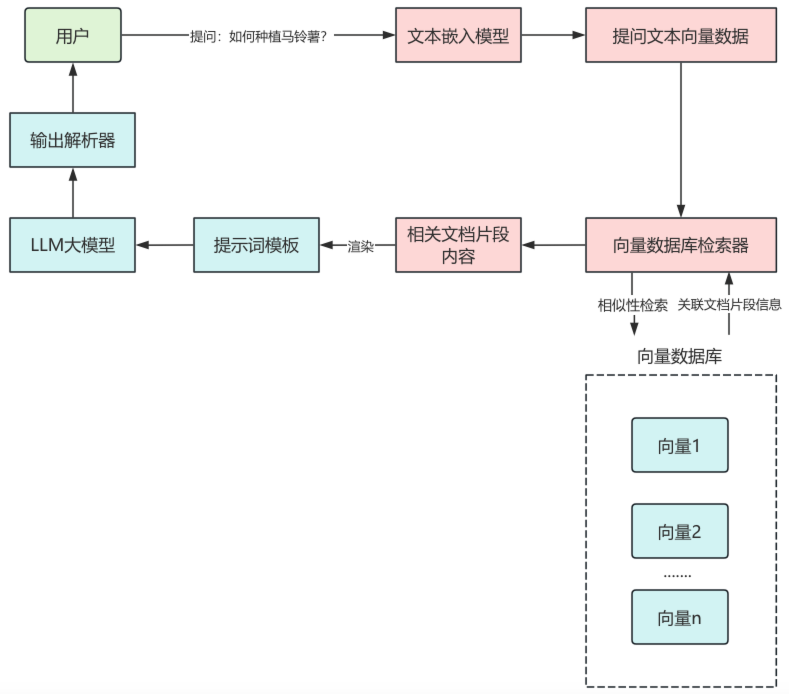
1.5 总结
本文详细介绍了 RAG(检索增强生成) 技术的概念、作用以及完整的实现流程。RAG的本质是在大语言模型生成答案之前,通过检索外部知识库的相关信息,来解决大语言模型知识边界的局限性问题,让大语言模型具备实时获取、理解和回答特定领域问题的能力。
LangChain作为一个大语言模型应用开发框架,为RAG的实现提供了完整的组件体系,覆盖了从文档加载、内容分割、文本嵌入、向量存储、相似性检索到提示词构建的全流程。开发者可通过LangChain框架,只需完成少量工作即可实现RAG功能。
2. 一文带你吃透文档加载器
在上一篇文章中,介绍了实现RAG功能的整个流程,以及LangChain提供了哪些组件来实现RAG功能,想了解RAG实现过程可以参考:LangChain框架入门09:什么是RAG?
本文将从RAG准备阶段第一个步骤:文档加载,详细介绍LangChain中的文档加载器组件,LangChain内置的文档加载器可以加载各种格式的知识库文档,而无需开发者自己编写,可以非常便捷地实现文档加载功能。
2.1 什么是文档加载器
在LangChain中,文档加载器用于将各种格式的文档转换为Document对象,LangChain提供了大量的文档加载器,支持从各种来源加载文档,如文件、数据源、URL等。
常用的LangChain文档加载器如下:
| 文档加载器 | 作用 |
|---|---|
| CSVLoader | 从 CSV 加载文档 |
| JSONLoader | 从 JSON 数据加载文档 |
| PyPDFLoader | 从 PDF 数据加载文档 |
| UnstructuredHTMLLoader | 从 HTML 数据加载文档 |
| UnstructuredMarkdownLoader | 从 Markdown 加载文档 |
| UnstructuredExcelLoader | 从 Excel 文件加载数据 |
每一个文档加载器都有自己特定的参数和方法,但它们有一个统一的load()方法来完成文档的加载,load()方法会返回一个Document类的对象列表,因为这些文档加载器都继承自BaseLoader基类,它们的继承关系如下:
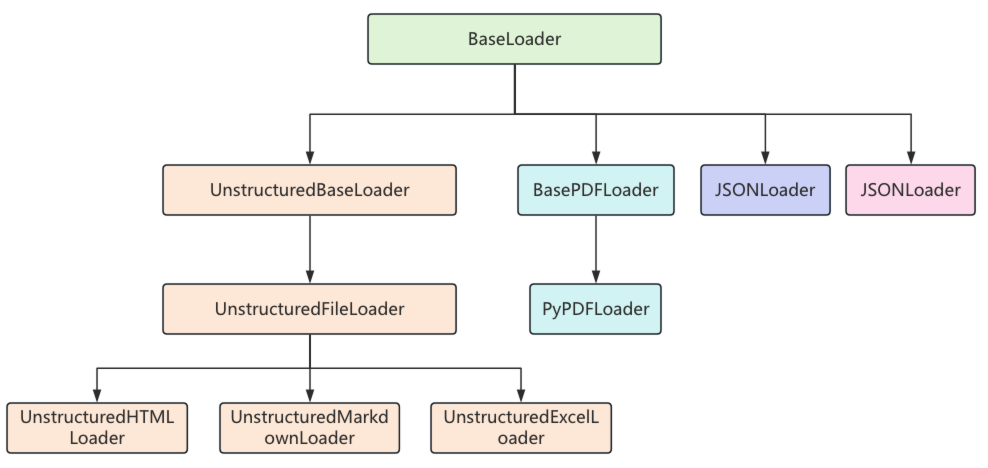
在BaseLoader类中,定义了load()方法,用来加载文档对象,在方法内部又调用了lazy_load()懒加载方法
1 | def load(self) -> List[Document]: |
在lazy_load()方法中,判断了子类是否重写了load()方法,如果重写了,则调用当前类的load()方法,如果没有重写则抛出异常,因此在子类中,要重写load()方法或lazy_load()方法。
1 | def lazy_load(self) -> Iterator[Document]: |
如果LangChain提供的文档加载器无法满足业务需求,我们也可以自己实现自定义加载器,通过继承BaseLoader,并实现其中的load()方法,来编写自定义文档加载器的加载逻辑。