1. 从0到1学习Weaviate向量数据库 在之前的文章中,相信你已经学会了如何将加载好的文档按照一定规则分割成文档片段,以及对文档片段进行了文本嵌入生成对应的向量数据。
下一步就是要将这些向量数据存储到向量数据库,本文将会详细的讲解什么是向量数据库(Vector database),以及常用向量数据库Weaviate的安装及使用方法。
1.1 什么是向量数据库 向量数据库(Vector database)是一种能够存储多维向量数据的新型数据库,向量数据库实现了一种或者多种近似相邻算法,来支持用户使用查询文本或图像进行相似性检索,来检索到最匹配的向量数据。
这些存储的向量都是高维的,比如我们在上一篇文章中使用的text-embedding-3-small模型,生成的向量的维度是1536,向量的维度一般可以从几百到几万不等,这些向量的维度表示了原始的数据在不同方面的特征,向量的维度取决于它要表示的数据复杂程度,除了文本片段,图像、音频等都可以被向量化存储到向量数据库。
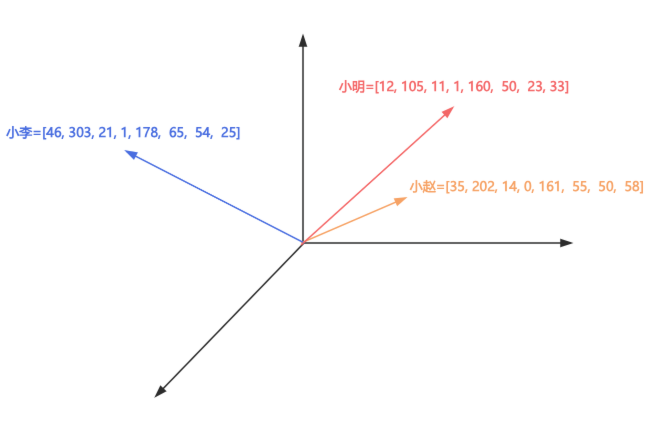
下面通过一个例子进行分析:
文本1:小明是一个光明小学五年级学生,年龄11岁,性别男,身高160cm,体重50kg,他喜欢唱歌和写作。
文本2:小赵是一个第二初级中学初二学生,年龄14岁,性别女,身高161cm,体重55kg,她喜欢游泳和羽毛球。
文本3:小李是一个光明大学大三学生,年龄21岁,性别男,身高178cm,体重65kg,他喜欢跑步和弹吉他。
假设要将上面的三个文本片段转换为向量,文本嵌入模型就会对原始文本的多方面的特征进行提取,比如以姓名、学校、年龄、性别、身高、体重、爱好维度进行向量转换。
通过一定规则根据这几个维度映射模拟的向量值如下,并将这些向量数据和元数据一起存储到向量数据库中。
第一个文本转换为向量:[12, 105, 11, 1, 160, 50, 23, 33],元数据segment_id=1
第二个文本转换为向量:[35, 202, 14, 0, 161, 55, 50, 58],元数据segment_id=2
第三个文本转换为向量:[46, 303, 21, 1, 178, 65, 54, 25],元数据segment_id=3
以下是模拟三个向量映射到向量空间:
当进行数据检索时,假设提供的查询的文本是:
我需要一个身高在180cm左右,喜欢弹吉他的大学生的学生信息
通过文本嵌入模型将查询文本也转换向量:[80, 300, 99, 10, 180, 60, 24, 25],通过这一组向量到数据中进行相似性检索,向量数据库会计算向量之间的距离,找到和查询文本向量距离最近的一个或者几个向量值,返回检索到的向量数据,通过向量的元数据中的segment_id,就可以找到原始的文本片段信息。
以上就是向量数据库的一次基础检索流程,向量数据库和传统的关系型数据库相比,可以进行语义上的相似性匹配,而不像关系型数据库只能根据关键词进行模糊搜索。
1.2 Weaviate向量数据库安装 本文要介绍的数据是当前非常流行的Weaviate数据库,Weaviate数据库是一个基于GO语言开发的开源的向量数据库。
Weaviate官方文档:https://docs.weaviate.io/weaviate
Weaviate支持以下四种部署方式:
Docker部署:Docker部署适用于开发和测试环境
Weaviate Cloud:Weaviate官方提供的Serverless方案,支持高可用、零停机时间,适用于生产环境
K8S部署:使用K8S部署Weaviate,可以用于开发或者生产环境。
嵌入式部署:嵌入式 Weaviate可以从应用程序中运行 Weaviate 实例,不需要从独立的服务器安装,嵌入式Weaviate目前仍处于实验阶段,并且不支持Windows系统。
下面对如何在Docker中安装Weaviate进行介绍:
运行 Weaviate命令如下
1 docker run -d --name weaviate -p 8080:8080 -p 50051:50051 cr.weaviate.io/semitechnologies/weaviate:1.32.2
这样Weaviate实例就创建成功了
1 2 3 $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 66cec8f2cc75 cr.weaviate.io/semitechnologies/weaviate:1.32.2 "/bin/weaviate --hos…" 13 seconds ago Up 12 seconds 0.0.0.0:8080->8080/tcp, 0.0.0.0:50051->50051/tcp weaviate
Docker其他常用命令:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # 查看所有docker镜像 docker images # 查看所有docker实例 docker ps -a # 查看所有运行中的Docker实例 docker ps # 删除docker实例 docker rm weaviate # 启动weaviate实例 docker start weaviate # 停止weaviate实例 docker stop weaviate
1.3 Weaviate向量数据库使用方法 Weaviate官方并没有提供可视化界面来查看和操作Weaviate数据库,下面我们通过Weaviate提供的Python 客户端来操作Weaviate数据库。
首先,在项目中安装Weaviate客户端依赖
1 pip install -U weaviate-client
执行命令,生成依赖版本快照
1 pip freeze > requirements.txt
在介绍Weaviate客户端使用之前,首先需要了解Weaviate的几个基础知识。
在Weaviate中,可以创建多个集合,用来保存数据
在Weaviate中,保存数据的载体是对象,在对象中可以包含向量信息(Vector)和属性信息(properties),这里的属性信息就是我们之前所说的元数据信息。
所有的对象都属于一个集合且仅属于一个集合
1.3.1 连接Weaviate 连接本地Weaviate数据库代码示例如下,指定host地址、端口号和grpc端口号。
1 2 3 4 5 6 7 8 9 import weaviate client = weaviate.connect_to_local( host="localhost", port=8080, grpc_port=50051, ) print(client.is_ready())
1.3.2 创建集合 在Weaviate中,可以通过create方法创建集合:
1 client.collections.create("Database")
1.3.3 创建对象 在集合Database中创建一个带向量和属性的对象,并且insert方法会返回一个uuid,这个uuid就是这个对象的唯一标识。
1 2 3 4 5 6 7 8 9 10 11 database = client.collections.get("Database") uuid = database.data.insert( properties={ "segment_id": "1000", "document_id": "1", }, # 复制生成1536维向量 vector=[0.12345] * 1536 ) print(uuid)
执行结果:
1 a60f4b19-9c97-4eb0-ba02-8c7b0a6cfcb1
也可以单独指定uuid,不让Weaviate自动生成,通过指定uuid属性,设置uuid
1 2 3 4 5 6 7 8 9 uuid = database.data.insert( properties={ "segment_id": "1000", "document_id": "1", }, # 复制生成1536维向量 vector=[0.12345] * 1536, uuid=uuid.uuid4() )
1.3.4 批量导入对象 除了单个创建对象,还可以批量导入对象,预先生成5条数据和5个向量,使用批量导入将对象导入到集合中,并自己指定uuid,当出现失败数量超过10个时,则终止对象导入。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 # 生成5条数据 data_rows = [{"title": f"标题{i + 1}"} for i in range(5)] # 生成5个对应的向量数据 vectors = [[0.1] * 1536for i in range(5)] # 集合对象 collection = client.collections.get("Database") # 批处理大小为200 with collection.batch.fixed_size(batch_size=200) as batch: for i, data_row in enumerate(data_rows): # 批量导入对象 batch.add_object( properties=data_row, vector=vectors[i], # 指定uuid uuid=uuid.uuid4() ) # 超过10个则终止导入 if batch.number_errors > 10: print("批量导入对象出现错误次数过多,终止执行") break # 打印处理失败对象 failed_objects = collection.batch.failed_objects if failed_objects: print(f"导入失败数量: {len(failed_objects)}") print(f"第一个导入失败对象: {failed_objects[0]}")
1.3.5 根据uuid查询对象 Weaviate支持通过uuid 检索对象。如果uuid不存在,将会返回 404 错误,这里还指定了include_vector属性为True表示除了返回对象元数据信息之外,同时返回向量信息,在打印向量时,读取vector的default属性是因为,在Weaviate对象可以保存多个向量信息,默认的向量名就是default。
1 2 3 4 5 6 7 8 9 10 11 12 database = client.collections.get("Database") # 通过uuid获取对象信息,并且返回向量信息 data_object = database.query.fetch_object_by_id( "a60f4b19-9c97-4eb0-ba02-8c7b0a6cfcb1", include_vector=True ) # 打印向量信息 print(data_object.properties) print(data_object.vector["default"])
执行结果如下:
1 2 {'document_id': '1', 'segment_id': '1000', 'title': None} [0.12345000356435776, 0.12345000356435776, 0.12345000356435776, 省略部分数据...]
1.3.6 查询所有对象 Weaviate 提供了相关API来遍历集合所有的数据,这个方法在迁移数据时非常有用,通过如下方式可以遍历集合内的全部对象信息。
1 2 3 4 5 6 7 collection = client.collections.get("Database") for item in collection.iterator( include_vector=True ): print(item.properties) print(item.vector)
执行结果如下,返回了元数据信息和向量信息。
1 2 3 4 5 6 {'title': '标题1', 'segment_id': None, 'document_id': None} {'default': [0.10000000149011612, 0.10000000149011612, 省略部分数据...]} {'document_id': None, 'segment_id': None, 'title': '标题2'} {'default': [0.10000000149011612, 0.10000000149011612, 省略部分数据...]} 省略部分数据...
1.3.7 更新对象信息 Weaviate支持对对象部分更新,也支持对对象进行整体替换。
首先来介绍对象的部分更新,使用示例如下,根据uuid去更新对象属性信息、向量信息,没有指定更新的属性不会发生变化。
1 2 3 4 5 6 7 8 9 10 database = client.collections.get("Database") database.data.update( uuid="a60f4b19-9c97-4eb0-ba02-8c7b0a6cfcb1", # 更新属性 properties={ "segment_id": "2000", }, # 更新向量信息 vector=[1.0] * 1536 )
在执行上面的程序之前,uuid为a60f4b19-9c97-4eb0-ba02-8c7b0a6cfcb1的向量信息如下。
1 2 {'document_id': '1', 'segment_id': '1000', 'title': None} [0.12345000356435776, 0.12345000356435776, 0.12345000356435776, 省略部分数据...]
执行上述程序,重新查询该对象信息如下,数据已经修改成功,由于没有指定document_id因此该属性没有变化。
1 2 {'title': None, 'document_id': '1', 'segment_id': '2000'} [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 省略部分数据...]
除了使用update方法进行属性更新,也可以使用replace方法对整个对象数据进行替换,代码示例如下:
1 2 3 4 5 6 7 8 database = client.collections.get("Database") database.data.replace( uuid="a60f4b19-9c97-4eb0-ba02-8c7b0a6cfcb1", properties={ "segment_id": "3000", }, vector=[1.0] * 1536 )
执行成功之后,重新查询对象信息,可以看到除了segment_id属性和向量信息都进行更新之外,document_id也被设置为None,因此可以判断整个对象进行了替换。
1 2 {'document_id': None, 'segment_id': '3000', 'title': None} [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 省略部分数据...]
1.3.8 删除对象 Weaviate支持按uuid删除、批量删除、删除全部三种删除方式。
按照uuid删除方法
1 2 3 4 database = client.collections.get("Database") database.data.delete_by_id( "a60f4b19-9c97-4eb0-ba02-8c7b0a6cfcb1" )
按条件批量删除方法,使用示例如下,对属性title进行模糊匹配,匹配成功的对象将会被删除。
1 2 3 4 database = client.collections.get("Database") database.data.delete_many( where=Filter.by_property("title").like("标题*") )
所有对象都属于一个集合,因此删除集合就相当于删除全部对象,删除集合方法如下:
1 2 3 client.collections.delete( "Database" )
1.4 总结 本文首先介绍了向量数据库的基本概念,分析了它与传统关系型数据库的区别与优势:关系型数据库主要用于精确匹配或模糊搜索,而向量数据库能够基于语义进行相似性检索,更适用于文本、图像、音频等非结构化数据的搜索场景。
接着,我们了解了当前在 AI 应用中非常流行的开源向量数据库 Weaviate,介绍了Weaviate的主要特性和四种部署方式,详细讲解了使用 Docker 部署 Weaviate 的方法。
在Weaviate向量数据库使用方法部分,主要介绍了数据库连接、创建集合、对象的增删改查等操作。
2. 深入解析向量存储组件VectorStore 在上一篇文章中,我们了解了什么是向量数据库,并以开源向量数据库Weaviate为例,介绍了它的使用安装和基本使用方法。
本文将继续回到LangChain框架的用法上,详细分析在LangChain中,如何使用VectorStore组件将向量数据存储到向量数据库中。
2.1 VectorStore组件介绍 对非结构化数据的存储与检索,最常用的方法是先将文本进行嵌入,转换为向量后存储到向量数据库中;在查询时,同样将查询文本嵌入生成向量,再将该向量传递给向量数据库,由数据库完成后续的相似度计算与检索过程。
在 LangChain 中,这一过程由顶层接口 VectorStore 统一管理,不同类型的向量数据库只需实现该接口中的抽象方法即可完成集成。VectorStore 接口提供了多个常用方法,例如:
add_texts:将文本列表转换为向量,并存储到向量数据库。
add_documents:将文档列表转换为向量,并存储到向量数据库。
as_retriever:返回向量数据库初始化的检索器。
similarity_search_with_relevance_scores:进行相似性检索,返回文档及其相关性得分(范围在[0, 1]之间)。
delete:根据向量id删除向量数据
from_texts:传入文本列表、元数据信息、文本嵌入模型,返回创建好的VectorStore。
VectorStore接口,常用的实现类如下:
类名(Class Name)
核心描述
关键特性
InMemoryVectorStore 基于内存实现的向量数据库
1. 无需部署独立服务,启动速度快;2. 数据仅存于内存,服务重启后数据丢失;3. 适合开发测试、小规模临时数据场景。
ElasticsearchStore 以 Elasticsearch 搜索引擎为基础实现的向量数据库
1. 支持向量检索与全文检索结合;2. 具备成熟的分布式部署、高可用能力;3. 适合需要复杂检索逻辑的生产环境。
TencentVectorDB 腾讯官方向量数据库的 LangChain 适配类
1. 当前位于 community(社区)包,未归入核心模块;2. 依托腾讯云服务,适合已使用腾讯云生态的项目;3. 需额外安装社区依赖才能使用。
PineconeVectorDB 云原生向量数据库 Pinecone 的 LangChain 适配类
1. 完全托管的云服务,无需关注底层运维;2. 支持大规模向量数据存储与低延迟检索;3. 适合对稳定性和检索性能要求高的生产场景。
WeaviateVectorStore 开源向量数据库 Weaviate 的 LangChain 适配类
1. 支持本地部署或云服务(Weaviate Cloud);2. 内置多种向量索引算法,可灵活配置;3. 适合需要自定义部署或开源技术栈的项目
2.2 WeaviateVectorStore数据存储 WeaviateVectorStore 是 VectorStore 接口的一个实现类,下面将以它为例介绍 VectorStore 的用法。在使用 WeaviateVectorStore 之前,需要先安装 langchain-weaviate 依赖:
1 pip install langchain-weaviate==0.0.2
执行命令,生成依赖版本快照
1 pip freeze > requirements.txt
接下来,先展示如何使用 WeaviateVectorStore 进行数据存储。示例程序如下:在构造 WeaviateVectorStore 对象时,需要传入 Weaviate Client 对象、text_key、文本嵌入对象以及 Weaviate 集合名称。其中,text_key 表示存储原文的 key 名,这里命名为 text_key。
Weaviate 数据库支持将文本片段的原文直接保存到 Weaviate 中,这样在检索时就可以直接获取原文,避免了通过元数据中的 segment_id 再去关系型数据库查询的额外操作。这种方式适用于文本数量较少的情况;当文本数量较大时,建议将原文保存到关系型数据库中,更便于管理和维护。
构建好 WeaviateVectorStore 后,将准备好的文本信息和元数据信息通过 add_texts() 方法添加到向量数据库中。WeaviateVectorStore 会使用传入的文本嵌入模型自动对文本进行嵌入,并在对象创建成功后返回对应的 UUID 列表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 import dotenv import weaviate from langchain_openai import OpenAIEmbeddings from langchain_weaviate import WeaviateVectorStore # 读取env配置 dotenv.load_dotenv() # 1.创建Weaviate客户端 client = weaviate.connect_to_local( host="localhost", port=8080, grpc_port=50051, ) # 2.创建文本嵌入模型 embeddings = OpenAIEmbeddings(model="text-embedding-3-small") # 3.创建Weaviate向量数据库 vector_store = WeaviateVectorStore( client=client, text_key="text_key", embedding=embeddings, index_name="Database" ) # 4.准备好要保存的文本数据、元数据 texts = [ "光明科技公司总部位于北京市朝阳区,是一家专注于人工智能与大数据分析的高新技术企业,现有员工500人。", "公司董事长张三,男,40岁,籍贯黑龙江漠河市,毕业于清北大学,曾在硅谷工作十年,现负责公司战略规划与重大项目决策。", "总经理李四,男,38岁,江苏南京人,拥有十五年软件工程经验,主导过多个国家重点科技项目。", "副总经理王五,男,35岁,四川成都人,负责公司运营管理与市场拓展。", "技术部拥有120名开发人员,主要从事机器学习模型训练、数据挖掘、云计算平台研发等工作。", "光明科技公司在2024年获得国家科技进步二等奖,并与多所高校建立产学研合作关系。", "公司设有技术部、市场部、运营部和人力资源部,其中技术部是公司的核心部门。", "张三不仅担任董事长,还热衷公益事业,曾多次捐助贫困地区教育项目。", "李四毕业于上海交通大学计算机系,擅长分布式系统与云架构设计。", "王五在加入光明科技公司前,曾任某知名互联网企业运营总监,具有丰富的企业管理经验。" ] metadatas = [ {"segment_id": "1"}, {"segment_id": "2"}, {"segment_id": "3"}, {"segment_id": "4"}, {"segment_id": "5"}, {"segment_id": "6"}, {"segment_id": "7"}, {"segment_id": "8"}, {"segment_id": "9"}, {"segment_id": "10"}, ] # 5.存储数据到向量数据库 uuids = vector_store.add_texts(texts, metadatas) # 6.打印返回的uuid列表 print(f"存储到Weaviate向量数据库的对象的uuid列表:{uuids}")
执行结果如下,返回了创建对象的uuid列表。
1 存储到Weaviate向量数据库的对象的uuid列表:['61adde43-8fac-4ed9-82ae-79b73b7eaf94', 'a9864354-80b5-4426-98c4-30e0da4e5cd7', 'f8b3f2e5-dda8-493d-9e73-00763dd5e274', '5dbf58ab-5db8-4e7a-94aa-d1d2dba0d9af', '9d12f56c-96f4-4867-8ee9-a5f05757dfc8', '63f94a88-160e-4b1e-b049-245af8f20962', 'df850306-45ae-4d70-ab48-01e00a652a7a', '61634caf-e65c-4b4c-a1b5-4d44d855d70a', '8b0e22f1-652f-4ef5-b5a1-3be03673d833', '0529d236-9253-4a22-a413-72798c5f4f27']
2.3 WeaviateVectorStore数据检索 在上面的示例程序中,我们将文本信息和元数据信息都保存到了数据库中。接下来,使用 VectorStore的similarity_search_with_relevance_scores() 方法进行相似性检索。在调用该方法时,传入查询文本 query,并指定 k=3,即返回匹配分数最高的三条数据(k 的默认值为 4)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import dotenv import weaviate from langchain_openai import OpenAIEmbeddings from langchain_weaviate import WeaviateVectorStore # 读取env配置 dotenv.load_dotenv() # 1.创建Weaviate客户端 client = weaviate.connect_to_local( host="localhost", port=8080, grpc_port=50051, ) # 2.创建文本嵌入模型 embeddings = OpenAIEmbeddings(model="text-embedding-3-small") # 3.创建Weaviate向量数据库 vector_store = WeaviateVectorStore( client=client, text_key="text_key", embedding=embeddings, index_name="Database" ) # 4、进行数据检索 search_result = vector_store.similarity_search_with_relevance_scores(query="光明公司的董事长是谁?", k=3) # 5、打印检索结果 for document, score in search_result: print(f"文档内容:{document.page_content}") print(f"文档元数据信息:{document.metadata}") print(f"相关度得分:{score}") print("=================================")
执行结果如下,返回了3个与查询文本最相关的文本信息。
1 2 3 4 5 6 7 8 9 10 11 12 文档内容:王五在加入光明科技公司前,曾任某知名互联网企业运营总监,具有丰富的企业管理经验。 文档元数据信息:{'segment_id': '10', 'text': None} 相关度得分:0.6681877695251427 ================================= 文档内容:公司董事长张三,男,40岁,籍贯黑龙江漠河市,毕业于清北大学,曾在硅谷工作十年,现负责公司战略规划与重大项目决策。 文档元数据信息:{'segment_id': '2', 'text': None} 相关度得分:0.6405468061607247 ================================= 文档内容:光明科技公司总部位于北京市朝阳区,是一家专注于人工智能与大数据分析的高新技术企业,现有员工500人。 文档元数据信息:{'segment_id': '1', 'text': None} 相关度得分:0.6342571121423872 =================================
2.4 总结 本文详细介绍了 LangChain 的 VectorStore 接口,VectorStore提供了add_texts、similarity_search_with_relevance_scores、delete 等常用方法,该接口有多种数据库(Weaviate、Pinecone、Elasticsearch 等)的实现类。
接下来,以WeaviateVectorStore介绍了如何进行向量数据的存储,在存储完成后,使用similarity_search_with_relevance_scores 进行带得分的相似性检索,分数越高表示越相关,检索结果同时返回文档内容与元数据,方便后续处理。
通过本文可以快速掌握 LangChain的VectorStore组件,以及LangChain如何集成 Weaviate 的基本流程,从数据存储、向量化,到检索查询,掌握完整的数据存储检索流程,在下一篇文章中,将会继续介绍LangChain中Retrievers检索器组件的用法,欢迎持续关注。
3. 深度解析Retrievers检索器组件 在上一篇文章中,介绍了 VectorStore 接口的常用方法,以及 VectorStore 接口的常见实现类,并以 WeaviateVectorStore 为例,演示了如何使用 WeaviateVectorStore 进行向量数据库的存储和检索。本文将继续介绍如何使用检索器组件 Retrievers 进行高效的数据检索。
3.1 BaseRetriever接口 BaseRetriever 是检索器相关类的顶层接口。当给定一个查询文本需要进行非结构化查询时,它比 VectorStore 更为通用。检索器本身不需要存储文档,只要能够对文档进行检索并返回检索到的文档即可。检索器可以通过 VectorStore 创建,也可以对诸如维基百科等数据源进行检索。
最重要的是,BaseRetriever 是一个可运行组件,它可以方便地使用 LECL 表达式对检索器组件进行集成。检索器接受一个查询文本作为输入,返回一个 Document 对象列表作为输出。BaseRetriever 的 invoke 方法定义如下:
1 2 3 def invoke( self, input: str, config: Optional[RunnableConfig] = None, **kwargs: Any ) -> List[Document]:
3.2 VectorStoreRetriever使用 在 RAG 应用中,当需要基于向量数据库进行文档检索时,就可以使用VectorStoreRetriever。它封装了向量数据库检索的底层逻辑,能够直接调用 VectorStore 的方法,从向量数据库中检索最相关的文档。
在前面介绍 VectorStore 常用方法时,包括了 as_retriever() 方法,该方法可以构建一个检索器对象,这个检索器就是 VectorStoreRetriever。
在介绍VectorStoreRetriever用法之前,首先将如下测试数据插入到向量数据库中,为避免过多重复代码,具体的插入实现已省略,大家可以到 GitHub 中自行查看。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 # 准备好要保存的文本数据、元数据 texts = [ "光明科技公司总部位于北京市朝阳区,是一家专注于人工智能与大数据分析的高新技术企业,现有员工500人。", "董事长张三,男,40岁,籍贯黑龙江漠河市,毕业于清北大学,曾在硅谷工作十年,现负责公司战略规划与重大项目决策。", "总经理李四,男,38岁,江苏南京人,拥有十五年软件工程经验,主导过多个国家重点科技项目。", "副总经理王五,男,35岁,四川成都人,负责公司运营管理与市场拓展。", "技术部拥有120名开发人员,主要从事机器学习模型训练、数据挖掘、云计算平台研发等工作。", "光明科技公司在2024年获得国家科技进步二等奖,并与多所高校建立产学研合作关系。", "公司设有技术部、市场部、运营部和人力资源部,其中技术部是公司的核心部门。", "张三不仅担任董事长,还热衷公益事业,曾多次捐助贫困地区教育项目。", "总经理李四毕业于上海交通大学计算机系,擅长分布式系统与云架构设计。", "副总经理王五在加入光明科技公司前,曾任某知名互联网企业运营总监,具有丰富的企业管理经验。" ] metadatas = [ {"segment_id": "1"}, {"segment_id": "2"}, {"segment_id": "3"}, {"segment_id": "4"}, {"segment_id": "5"}, {"segment_id": "6"}, {"segment_id": "7"}, {"segment_id": "8"}, {"segment_id": "9"}, {"segment_id": "10"}, ]
使用示例如下,使用as_retriever()方法创建了一个VectorStoreRetriever 对象,之后调用invoke()方法传入query进行文档检索。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import dotenv import weaviate from langchain_openai import OpenAIEmbeddings from langchain_weaviate import WeaviateVectorStore # 读取env配置 dotenv.load_dotenv() # 1.创建Weaviate客户端 client = weaviate.connect_to_local( host="localhost", port=8080, grpc_port=50051, ) # 2.创建文本嵌入模型 embeddings = OpenAIEmbeddings(model="text-embedding-3-small") # 3.创建Weaviate向量数据库 vector_store = WeaviateVectorStore( client=client, text_key="text_key", embedding=embeddings, index_name="Database" ) # 4.创建检索器,进行数据检索 retriever = vector_store.as_retriever() documents = retriever.invoke("介绍一下光明科技公司副总经理的情况。") for document in documents: print(document.page_content) print(document.metadata) print("=================================")
执行结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 副总经理王五在加入光明科技公司前,曾任某知名互联网企业运营总监,具有丰富的企业管理经验。 {'text': None, 'segment_id': '10'} ================================= 光明科技公司总部位于北京市朝阳区,是一家专注于人工智能与大数据分析的高新技术企业,现有员工500人。 {'text': None, 'segment_id': '1'} ================================= 董事长张三,男,40岁,籍贯黑龙江漠河市,毕业于清北大学,曾在硅谷工作十年,现负责公司战略规划与重大项目决策。 {'text': None, 'segment_id': '2'} ================================= 总经理李四,男,38岁,江苏南京人,拥有十五年软件工程经验,主导过多个国家重点科技项目。 {'text': None, 'segment_id': '3'} =================================
在默认情况下,检索器使用相似性检索方式进行检索。另一种检索方式是最大边际相关性检索(简称 MMR),可以在调用 as_retriever() 方法时通过 search_type="mmr" 指定,但前提是检索器所使用的底层数据库必须支持该检索方式。
1 retriever = vector_store.as_retriever(search_type="mmr")
除了 search_type 之外,还可以使用 search_kwargs 将参数传递给 VectorStore 的底层搜索方法,例如传递 k 值,将默认匹配度最高的前三个文档返回(默认 k=4)。
1 retriever = vector_store.as_retriever(search_type="mmr", search_kwargs={"k": 3})
3.3 MultiQueryRetriever使用 在向量检索过程中,查询文本会被转换为向量,并通过计算向量间距离来检索相似文档。然而,检索结果的准确性可能会受到查询文本表达方式的影响。
因此,为了提升查询结果的准确性,可以将查询文本传递给大语言模型,由其生成多个不同表达方式的查询文本变体。随后,使用这些不同的查询文本分别进行文档检索,并将所有检索结果汇总、排序,返回最相关的文档。
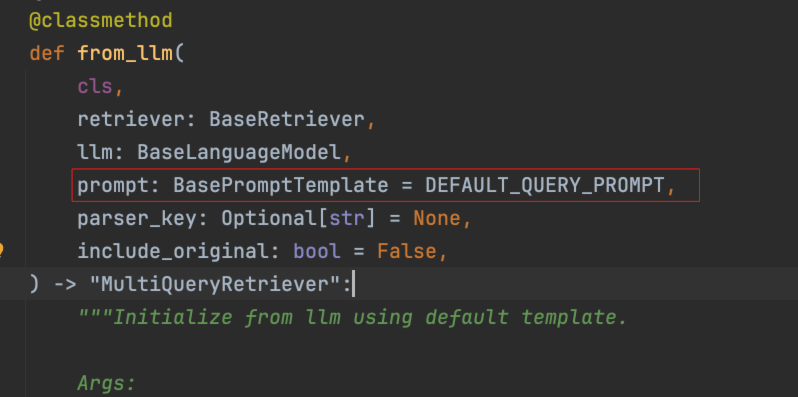
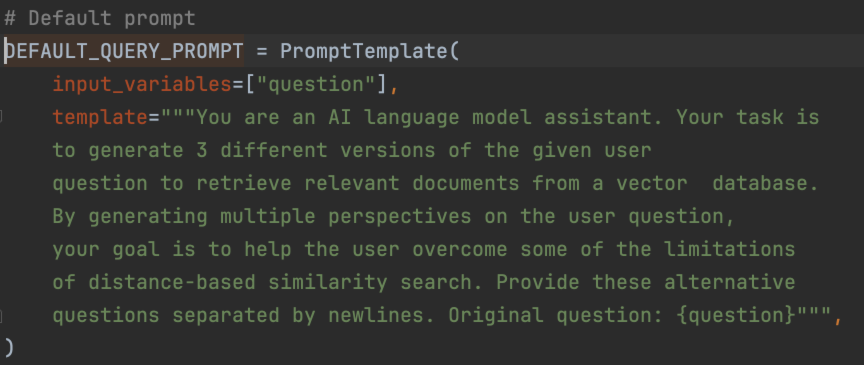
MultiQueryRetriever(多查询检索器)正是实现上述 RAG 检索优化逻辑的工具。可以使用 MultiQueryRetriever.from_llm() 方法创建一个多查询检索器。进入 from_llm() 源码可以看到,除了需要传递检索器对象和模型对象之外,还可以传入 prompt 参数,该参数用于调用大模型生成多个查询文本的提示词,并提供了默认值。
该默认提示词为英文版,在使用时需要进行汉化,否则返回的查询文本将全部为英文,导致检索效果下降。
MultiQueryRetriever 使用示例如下,首先进行了日志设置,在调用大语言模型生成多个查询文本时,MultiQueryRetriever 会进行 INFO 级别的日志打印,将生成的文本输出,
在创建 MultiQueryRetriever 时,需要传入 BaseRetriever 对象、模型对象以及汉化后的 prompt,之后同样通过调用invoke()方法传入查询文本进行检索。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 import logging import dotenv import weaviate from langchain.retrievers import MultiQueryRetriever from langchain_core.prompts import PromptTemplate from langchain_openai import OpenAIEmbeddings, ChatOpenAI from langchain_weaviate import WeaviateVectorStore # 日志设置 logging.basicConfig() logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO) # 读取env配置 dotenv.load_dotenv() # 1.创建Weaviate客户端 client = weaviate.connect_to_local( host="localhost", port=8080, grpc_port=50051, ) # 2.创建文本嵌入模型 embeddings = OpenAIEmbeddings(model="text-embedding-3-small") # 3.创建Weaviate向量数据库 vector_store = WeaviateVectorStore( client=client, text_key="text_key", embedding=embeddings, index_name="Database" ) # 4.创建多查询检索器 retriever = vector_store.as_retriever() retriever_from_llm = MultiQueryRetriever.from_llm( retriever=retriever, llm=ChatOpenAI(model="gpt-3.5-turbo"), prompt=PromptTemplate( input_variables=["question"], template="""你是一个 AI 语言模型助手。你的任务是: 为给定的用户问题生成 3 个不同的版本,以便从向量数据库中检索相关文档。 通过生成用户问题的多种视角(改写版本), 你的目标是帮助用户克服基于距离的相似性搜索的某些局限性。 请将这些改写后的问题用换行符分隔开。原始问题:{question}""") ) # 5.进行数据检索 documents = retriever_from_llm.invoke("介绍一下董事长信息") for document in documents: print(document.page_content) print(document.metadata) print("=================================")
执行结果如下。通过日志可以观察到,LLM 生成了三个查询文本,并且最终检索结果中排在前面的前两条文档与查询文本的信息最为相关。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 INFO:langchain.retrievers.multi_query:Generated queries: ['1. 请简要介绍一下董事长的背景和信息。', '2. 能否提供有关董事长的相关资料和详细介绍?', '3. 董事长的基本情况是什么?能给我更多的说明吗?'] 董事长张三,男,40岁,籍贯黑龙江漠河市,毕业于清北大学,曾在硅谷工作十年,现负责公司战略规划与重大项目决策。 {'segment_id': '2', 'text': None} ================================= 张三不仅担任董事长,还热衷公益事业,曾多次捐助贫困地区教育项目。 {'segment_id': '8', 'text': None} ================================= 总经理李四,男,38岁,江苏南京人,拥有十五年软件工程经验,主导过多个国家重点科技项目。 {'segment_id': '3', 'text': None} ================================= 光明科技公司总部位于北京市朝阳区,是一家专注于人工智能与大数据分析的高新技术企业,现有员工500人。 {'segment_id': '1', 'text': None} ================================= 副总经理王五,男,35岁,四川成都人,负责公司运营管理与市场拓展。 {'segment_id': '4', 'text': None} =================================
3.4 自定义检索器实现 在前面已经介绍过 BaseRetriever 接口,我们可以通过继承 BaseRetriever 来实现自定义检索器。查看 BaseRetriever 的 invoke 方法(省略部分代码)可以发现,最终真正执行检索的核心方法是 _get_relevant_documents。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def invoke( self, input: str, config: Optional[RunnableConfig] = None, **kwargs: Any ) -> List[Document]: ...... try: _kwargs = kwargs if self._expects_other_args else {} if self._new_arg_supported: result = self._get_relevant_documents( input, run_manager=run_manager, **_kwargs ) else: result = self._get_relevant_documents(input, **_kwargs) except Exception as e: run_manager.on_retriever_error(e) raise e else: run_manager.on_retriever_end( result, ) return result
并且 _get_relevant_documents 是一个抽象方法,需要由子类去实现。
1 2 3 4 @abstractmethod def _get_relevant_documents( self, query: str, *, run_manager: CallbackManagerForRetrieverRun ) -> List[Document]:
因此,实现一个自定义检索器需要继承 BaseRetriever 并实现 _get_relevant_documents 方法。
假设有如下需求:需要一个自定义检索器,将传入的查询文本按空格拆分成关键词数组,并在文档中进行匹配。只要有任意一个关键词匹配成功,即返回该文档信息,同时支持通过传递参数控制检索器返回的文档数量。
具体实现该需求的代码示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 from typing import List from langchain_core.callbacks import CallbackManagerForRetrieverRun from langchain_core.documents import Document from langchain_core.retrievers import BaseRetriever class KeywordsRetriever(BaseRetriever): """自定义检索器""" documents: List[Document] k: int def _get_relevant_documents(self, query: str, *, run_manager: CallbackManagerForRetrieverRun) -> List[Document]: # 1.去除kwargs中的k参数 k = self.k if self.k isnotNoneelse3 documents_result = [] # 2.按照空格拆分query,为多个关键词 query_keywords = query.split(" ") # 3.遍历文档,只要文档中包含其中一个关键词,添加到结果中 for document in self.documents: if any(query_keyword in document.page_content for query_keyword in query_keywords): documents_result.append(document) # 4.返回前k条文档数据 return documents_result[:k] # 1.定义文档列表 documents = [ Document("光明科技公司总部位于北京市朝阳区,是一家专注于人工智能与大数据分析的高新技术企业,现有员工500人。"), Document("董事长张三,男,40岁,籍贯黑龙江漠河市,毕业于清北大学,曾在硅谷工作十年,现负责公司战略规划与重大项目决策。"), Document("总经理李四,男,38岁,江苏南京人,拥有十五年软件工程经验,主导过多个国家重点科技项目。"), Document("副总经理王五,男,35岁,四川成都人,负责公司运营管理与市场拓展。"), Document("技术部拥有120名开发人员,主要从事机器学习模型训练、数据挖掘、云计算平台研发等工作。"), Document("光明科技公司在2024年获得国家科技进步二等奖,并与多所高校建立产学研合作关系。"), Document("公司设有技术部、市场部、运营部和人力资源部,其中技术部是公司的核心部门。"), Document("张三不仅担任董事长,还热衷公益事业,曾多次捐助贫困地区教育项目。"), Document("总经理李四毕业于上海交通大学计算机系,擅长分布式系统与云架构设计。"), Document("副总经理王五在加入光明科技公司前,曾任某知名互联网企业运营总监,具有丰富的企业管理经验。"), ] # 2.创建检索器 retriever = KeywordsRetriever(documents=documents, k=1) # 3.检索得到结果 result = retriever.invoke("张三") # 4.打印检索结果 for document in result: print(document.page_content) print("===========================")
执行结果:
1 2 董事长张三,男,40岁,籍贯黑龙江漠河市,毕业于清北大学,曾在硅谷工作十年,现负责公司战略规划与重大项目决策。 ===========================
3.5 总结 本文介绍了 LangChain 的检索器组件 Retrievers 的使用方法,以及检索器组件的顶层接口 BaseRetriever。还介绍了多种不同类型的检索器,例如通过 VectorStoreRetriever 可以快速基于向量数据库进行文档检索,MultiQueryRetriever 则通过生成多个查询变体提升检索准确性。
除此之外,实现自定义检索器需要继承 BaseRetriever,并实现抽象方法,在抽象方法内实现特定的检索逻辑,例如按关键词匹配文档并控制返回数量。
相信通过本文的学习,你已经掌握了 LangChain 检索器的用法,在下一篇文章中,将对 RAG 整个流程进行总结,并编写一个基础的 RAG 应用,敬请期待。
4. 智能客服系统RAG应用实战 在前面几篇文章中,介绍了什么是 RAG 以及其工作流程。在 RAG 的准备阶段,学习了如何使用文档加载器 对文档进行加载;文档加载完成后,需要通过文本分割器 将长文档分割成适合大小的文档片段。
之后,这些文档片段会通过文本嵌入模型 转换为向量数据,并借助 VectorStore 组件存储到向量数据库 中。至此,RAG 的检索准备阶段就完成了。
接下来,通过检索器 Retrievers 进行检索:在向量数据库检索器内部,查询文本会先通过文本嵌入模型转换为向量数据,再调用 VectorStore 进行向量检索,最终返回最相关的文档列表。
以上就是此前介绍过的 RAG 基本流程。本文将会把上述各个组件结合起来,实现一个完整的 RAG 应用。
4.1 需求分析 在前面的文章中也曾经提到过,大语言模型(LLM)所掌握的知识都来源于训练数据。但在许多业务场景下,我们需要让大模型掌握特定的知识库,这也正是RAG的作用。
假设现在有这样一个需求:某在线电商系统售卖各类商品,系统中存在大量的 商品信息。每天都会有大量用户来咨询,如果全部由人工客服处理,客服的压力会非常大。此时,就需要开发一个 智能客服系统,帮助人工客服处理一些关于商品信息的基础问题,并能够对系统内的商品信息进行快速、准确的介绍和回复。
要实现这样的智能客服系统,大体可以分为两步:
完成 RAG 数据的准备和处理;
开发 智能客服系统本身。
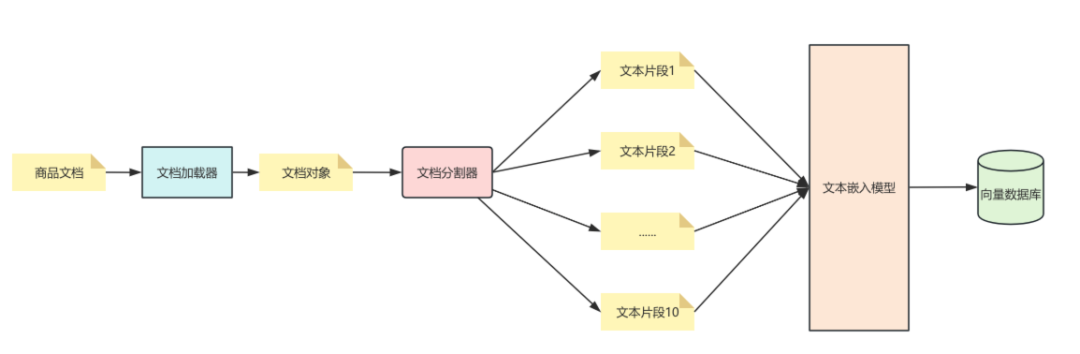
RAG 准备和处理阶段架构图如下:
针对智能客服系统本身,我们将采用RAG + LLM来完成这一需求。结合前面所学的知识,这个智能客服系统应该具备以下功能:
支持历史记忆功能,并且能够实现历史记忆持久化。
使用LCEL 表达式来构建链。
支持RAG 检索功能,使大语言模型能够根据知识库文档内容进行作答。
编写完善的提示词模板,内容包括历史对话信息、RAG 检索的上下文信息、用户提问,以及AI 作为客服的系统提示词。
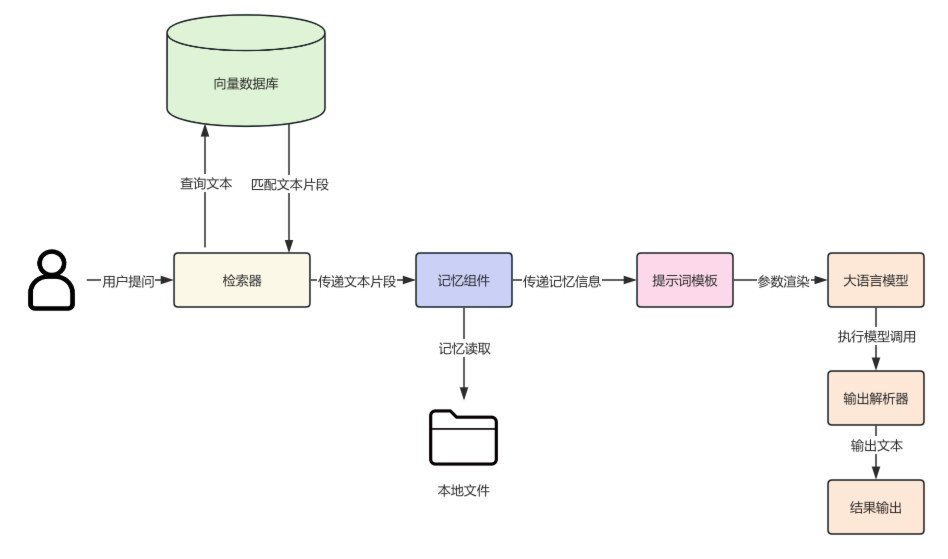
整个智能客服系统的架构图如下:
4.2 RAG准备阶段 首先,需要将电商系统中所有售卖商品的数据整理成一份或多份文档,作为商品知识库的源文档。商品信息包括商品名称、价格、生产日期、享受服务、商品详情等内容。具体商品信息如下(部分数据已省略)。 最终,我们将这些商品信息存放到商品信息.md文件中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 1.商品名称:小米 REDMI Note14 5G 国家补贴 金刚品质 5110mAh大电量 大光圈超感相机 8GB+128GB 子夜黑 红米手机 价格:764.15元 生产日期:2024-05-17 享有服务:59元免基础运费 · 可配送全球 · PLUS 180天只换不修 · 7天价保 · 免费上门退换 365天原厂维修 · 供应商售后 · 一年质保 商品详情:小米 Redmi Note 14(入网型号 24094RAD4C,国补备案型号 Redmi Note 14 5G)于 2024 年 9 月 26 日上市,机身颜色为子夜黑,尺寸为 162.4mm×75.7mm×7.99mm,重量 190g,采用轻薄设计并具备 IP64 防护及金刚架构。该机搭载天玑 7025-Ultra 处理器,运行小米澎湃 OS 系统,配备 6.67 英寸 OLED 直屏,分辨率 FHD+,刷新率 120Hz,并通过德国莱茵护眼及 SGS 认证。内存配置为 8GB 运行内存和 128GB 机身存储,电池容量为 5110mAh(typ),支持 45W 有线快充,无线充电不支持。影像系统方面,后置三摄包括 5000 万像素主摄及普通超广角镜头,长焦镜头未配备,支持光学防抖,前置摄像头为 1600 万像素。手机支持双卡 5G 网络,生物识别功能包括人脸识别和屏幕指纹,充电接口为 Type-C。包装清单包含手机主机、电源适配器、USB Type-C 数据线、插针、手机保护壳、说明书(含三包凭证)及出厂贴好的屏幕保护膜(以官网为准)。 2、 商品名称:OPPO K12 Plus 12GB+256GB 雪峰白 政府国家补贴 6400mAh大电池 第三代骁龙7 120Hz护眼直屏5G AI手机 价格:1189.15元 生产日期:2024-11-22 享有服务:59元免基础运费 · 可配送全球 · PLUS 180天只换不修 · 7天价保 · 发货延时补贴 免费上门退换 · 365天原厂维修 · 免举证退换货 · 一年质保 商品详情:省略..... 3、商品名称:Apple/苹果 iPhone 14 (A2884) 128GB 星光色 支持移动联通电信5G 双卡双待手机 价格:2981.51元 生产日期:2021-08-01 享有服务:59元免基础运费 · 可配送全球 · PLUS 180天只换不修 · 7天价保 · 免费上门退换 免举证退换货 · 一年质保 商品详情:省略..... 4、商品名称:Apple/苹果 iPhone 16 Pro Max(A3297)256GB 原色钛金属 支持移动联通电信5G 双卡双待手机 价格:8599.00元 生产日期:2024-02-02 享有服务:59元免基础运费 · 可配送全球 · PLUS 180天只换不修 · 7天价保 · 免费上门退换 免举证退换货 · 一年质保 商品详情:省略..... 5、商品名称:HUAWEI Mate 70 Pro 12GB+512GB曜石黑鸿蒙AI 红枫原色影像 超可靠玄武架构华为鸿蒙智能手机 价格:5589.4元 生产日期:2024-04-28 享有服务:包邮 · 可配送全球 · PLUS 180天只换不修 · 7天价保 · 免费上门退换 365天原厂维修 · 一年质保 商品详情:省略..... 6、商品名称:OPPO Find X8 Ultra 卫星通信版 16GB+1TB 晨曦微光 夜景人像专业镜头 丹霞原彩镜头 AI 5G旗舰手机 价格:7999.00元 生产日期:2025-06-30 享有服务:省略..... 7、商品名称:vivoX200 Ultra 16G+1T 红圈V单相机 蔡司三大定焦大师镜头 骁龙8至尊版 手机 价格:7959.01元 生产日期:2024-12-01 享有服务:59元免基础运费 · 可配送全球 · PLUS 180天只换不修 · 7天价保 · 免费上门退换 365天原厂维修 · 一年质保 商品详情:省略..... 8、商品名称:三星Samsung Galaxy Z Flip7 折叠屏手机 4.1英寸超大智能外屏 AI手机 徐明浩同款12GB+256GB 珊瑚红 价格:7999.00元 生产日期:2024-01-11 享有服务:59元免基础运费 · 可配送全球 · PLUS 180天只换不修 · 7天价保 · 免费上门退换 365天原厂维修 · 免举证退换货 · 一年质保 商品详情:省略..... 9、商品名称:华为(HUAWEI) Pura X 12GB+512GB 全网通手机 幻夜黑 *【赠云盘】 价格:7660.51元 生产日期:2024-03-12 享有服务:59元免基础运费 · 可配送全球 · PLUS 180天只换不修 · 7天价保 · 免费上门退换 365天原厂维修 · 一年质保 商品详情:省略..... 10、商品名称:纽曼(Newman)L8 星空黑 4G全网通移动联通电信老年人手机超长待机大字体大声音大按键老年机学生儿童备用功能机 价格:94.00元 生产日期:2022-08-17 享有服务:包邮 · 可配送全球 · PLUS 180天只换不修 · 7天价保 · 上门换新 · 免费上门退换 365天原厂维修 · 免举证退换货 · 一年质保 商品详情:省略.....
接下来进入RAG 的准备阶段,主要包含以下 4 个步骤:
(1)文档加载:使用TextLoader对非结构化的商品信息.md文件进行加载。
(2)文档分割:创建递归文本分割器,并指定块大小为 800,重叠部分为 100,对文本进行分割。
(3)文本嵌入:创建文本嵌入组件,指定模型名称为text-embedding-3-small。
(4)向量存储:创建WeaviateVectorStore,配置 Weaviate 连接,并传入文本嵌入模型,用于将文本片段进行嵌入。最后调用add_documents()方法,将文本片段存储到向量数据库中。
具体实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import dotenvimport weaviatefrom langchain_community.document_loaders import TextLoaderfrom langchain_openai import OpenAIEmbeddingsfrom langchain_text_splitters import RecursiveCharacterTextSplitterfrom langchain_weaviate import WeaviateVectorStoredotenv.load_dotenv() document_load = TextLoader(file_path="商品信息.md" ) documents = document_load.load() text_splitter = RecursiveCharacterTextSplitter(chunk_size=800 , chunk_overlap=100 , length_function=len , ) documents = text_splitter.split_documents(documents) print (f"文档数量:{len (documents)} " )for document in documents: print (f"文档片段大小:{len (document.page_content)} " ) print ("=====================================" ) client = weaviate.connect_to_local( host="localhost" , port=8080 , grpc_port=50051 , ) embeddings = OpenAIEmbeddings(model="text-embedding-3-small" ) vector_store = WeaviateVectorStore( client=client, text_key="text_key" , embedding=embeddings, index_name="Product" ) vector_store.add_documents(documents)
执行结果如下:文档被分割成了10 个文本片段,每个片段的长度大约在500左右。至此,RAG 准备阶段的工作就完成了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 文档数量:10 文档片段大小:662 ===================================== 文档片段大小:671 ===================================== 文档片段大小:514 ===================================== 文档片段大小:573 ===================================== 文档片段大小:762 ===================================== 文档片段大小:577 ===================================== 文档片段大小:574 ===================================== 文档片段大小:555 ===================================== 文档片段大小:456 ===================================== 文档片段大小:538 =====================================
4.3 实现智能客服系统 接下来,开始实现智能客服系统,主要包含以下8 个步骤:
(1)创建提示词模板:模板包括 系统消息、消息占位符、人类消息。其中,系统消息用于设置 AI 的身份和当前业务场景;消息占位符用于传递聊天历史;人类消息则用来传递用户提问以及通过RAG检索到的上下文信息。
(2)构建模型:使用 gpt-3.5-turbo 模型。
(3)创建输出解析器:创建一个 字符串输出解析器,用于结果输出。
(4)构建检索器:连接 Weaviate 数据库,创建 WeaviateVectorStore 对象,并传入 文本嵌入对象、Weaviate 客户端对象、存储文本信息 key、集合名称。然后调用 WeaviateVectorStore.as_retriever() 方法生成检索器,并指定只返回一条最相关的文档数据。
(5)创建记忆组件:构建记忆组件,并将历史对话信息保存在 customer_service_history.txt 中。
(6)构建链:构建LCEL 链。链的后半部分较为直观,这里重点介绍前半部分。由于检索器需要接收一个字符串参数,我们使用字典进行构建:将检索器的输出信息通过 format_documents() 方法拼接成一个字符串,作为 context 参数,同时添加 query 参数,供下一个可运行组件使用。 这里利用了 RunnableParallel 的参数传递功能。之前介绍过,在LCEL 表达式中,使用字典结构包裹并通过管道符连接时,会自动被包装成 RunnableParallel。
(7)调用链:使用 stream() 方法调用链,传入用户提问。stream() 可以实现流式输出,相比一次性返回结果,用户体验更好。
(8)记忆保存:调用 save_context(),将对话记忆进行持久化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 from operator import itemgetterimport dotenvimport weaviatefrom langchain.memory import ConversationBufferMemoryfrom langchain_community.chat_message_histories import FileChatMessageHistoryfrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderfrom langchain_core.runnables import RunnablePassthrough, RunnableLambdafrom langchain_openai import ChatOpenAI, OpenAIEmbeddingsfrom langchain_weaviate import WeaviateVectorStoredotenv.load_dotenv() prompt = ChatPromptTemplate.from_messages( [ ("system" , "你是大米公司的智能客服,你的名字叫大米,接下来你将扮演一个专业客服的角色,对用户提出来的商品问题进行回答,一定要礼貌热情," "如果用户提问与客服和商品无关的问题,礼貌委婉的表示拒绝或无法回答,只回答商品售卖相关的问题" ), MessagesPlaceholder("chat_history" ), ("human" , """ 用户提问上下文信息: <context>{context}</context> 请根据用户提出的问题进行回答:{query} """ ) ] ) llm = ChatOpenAI(model="gpt-3.5-turbo" ) parser = StrOutputParser() client = weaviate.connect_to_local( host="localhost" , port=8080 , grpc_port=50051 , ) embeddings = OpenAIEmbeddings(model="text-embedding-3-small" ) vector_store = WeaviateVectorStore( client=client, text_key="text_key" , embedding=embeddings, index_name="Product" ) retriever = vector_store.as_retriever(search_kwargs={"k" : 1 }) memory = ConversationBufferMemory( return_messages=True , chat_memory=FileChatMessageHistory("customer_service_history.txt" ) ) def format_documents (documents ) -> str : return "\n" .join([document.page_content for document in documents]) chain = ({"context" : retriever | format_documents, "query" : RunnablePassthrough()} | RunnablePassthrough.assign( chat_history=(RunnableLambda(memory.load_memory_variables) | itemgetter("history" ))) | prompt | llm | parser) whileTrue: query = input ("用户:" ) if query == '退出' : exit(0 ) response = chain.stream(query) print ("智能客服: " , flush=True , end="" ) answer = "" for chunk in response: answer += chunk print (chunk, flush=True , end="" ) print () memory.save_context({"用户" : query}, {"智能客服" : answer})
首先,测试历史记忆功能,验证 AI 能记住用户的名字,从而证明 AI 应用具有历史记忆能力。
1 2 3 4 智能客服: 你好,大志!我是大米,负责解答关于商品的问题。请问有什么我可以帮忙的吗? 用户:你是知道我是谁吗 智能客服: 您好!我知道您是大志,如果您有关于商品的问题,随时可以告诉我哦! 用户:
接下来,测试RAG 功能:首先提问“小米手机有哪些型号”,智能客服通过RAG 检索得到的数据,准确回答了文档中的小米手机信息;第二个问题,“iPhone14 有哪些配件”,智能客服同样能够准确无误地给出答案。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 用户:我想买一款小米手机,请问有哪些型号 智能客服: 您好!我们这里有很多小米手机可供选择,包括不同型号和配置。您提到想要购买一款小米手机,具体想要什么样的手机呢?比如说,您有喜欢的价格范围、配置需求或者是其他特别的功能吗?这样我可以为您推荐适合的型号。 如果您感兴趣的话,我可以先给您介绍一款比较受欢迎的小米手机——**小米 Redmi Note 14 5G**,这款手机的主要特点包括: - **大电池**:5110mAh电池,支持45W快充。 - **超感相机**:5000万像素主摄,支持光学防抖。 - **高刷新率屏幕**:6.67英寸OLED直屏,120Hz刷新率,视觉体验非常流畅。 - **性价比高**:8GB+128GB配置,适合日常使用和轻度游戏。 如果您对这款有兴趣或者想了解更多型号,随时告诉我哦! 用户:我想知道iPhone14有哪些配件 智能客服: 您好!根据您提供的商品信息,iPhone 14的包装清单中包含以下配件: - iPhone 主机 ×1 - USB-C 转闪电连接线 ×1 以上是iPhone 14手机的标配配件。如果您对其他配件或相关信息有任何疑问,欢迎随时向我咨询!
4.4 总结 本文完整实现了一个基于 RAG+LLM 的智能客服系统,使用了前面几篇文章中介绍的核心组件:文档加载、文本分割、嵌入模型、向量数据库、检索器、提示词模板、记忆组件等,并将它们组合在一起,构建出一个完整的 RAG 应用。
当前智能客服系统仍有很多可优化和扩展的空间,大家可以自行改进,目的是让大家通过该系统,将 RAG 相关知识串联起来,更好地理解如何构建 RAG 应用。
相信通过本文的学习,你已经对如何将 RAG 流程应用到真实业务场景有了较为完整的了解。在下一篇文章中,将对 LangChain 中的工具调用进行详细介绍,欢迎持续关注。
5. 手把手教你创建LLM工具 大语言模型(LLM)是基于训练数据进行预测并生成结果的,它无法掌握训练数据之外的知识。这一点在前面的文章中已经多次提到,通过 RAG 检索的方式,可以在一定程度上缓解这一问题。
但如果我们希望大模型获取最新的时事信息呢?或者让它查找“北京最好吃的五家餐馆”的地理位置信息?又或者要求它完成一套复杂的数学计算?这些需求仅依靠大语言模型本身的能力显然无法解决。
为此,LangChain 提供了 Tools 组件,可以通过创建自定义工具的方式,让 LLM 调用外部能力:例如,获取时事信息时调用搜索工具,查询地理位置时对接高德地图等 API,执行复杂计算时也能编写专门的工具。有了工具调用,AI 应用在解决实际问题上的能力就能得到进一步提升。
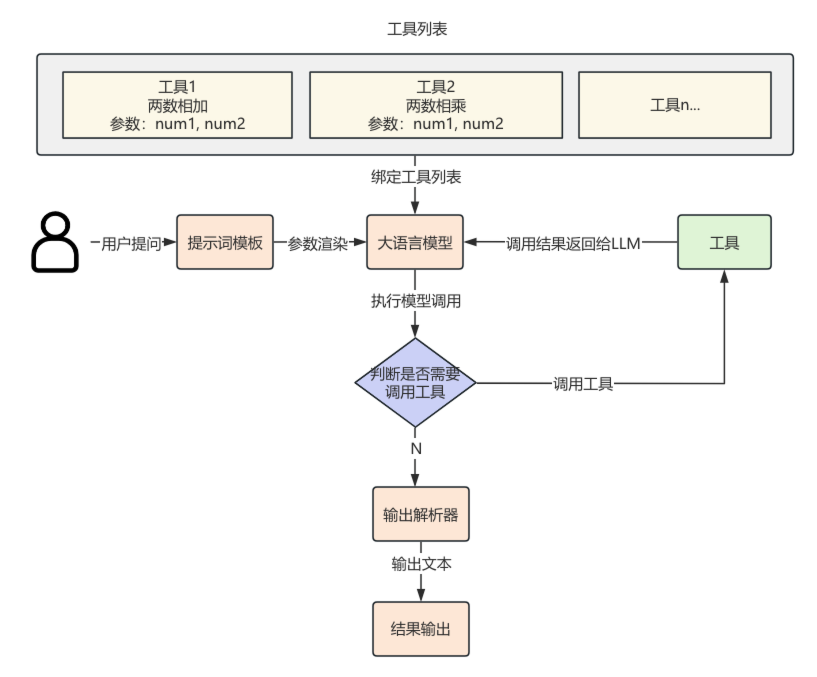
在构建 LLM 对象时,可以将工具列表绑定到模型上。这样,LLM 就能够获取到这些工具的名称、描述和参数定义,并以此作为上下文信息来判断是否需要调用工具。如果需要,它会请求调用一个或多个工具,并传入相应的参数,工具调用流程图如下:
当接收到调用指令和参数后,工具会执行相应逻辑并返回结果。随后,大语言模型会结合工具的输出,对用户的提问生成最终回答。这就是LLM工具调用的基本流程。
要实现LLM工具调用,第一步就是工具的创建。本文将会详细介绍在 LangChain 中如何创建工具,在后续文章中,我们会进一步展开,讲解工具调用的完整流程。
5.1 工具是什么 LLM 和工具之间的关系好比:大语言模型像是“大脑”,工具就像人的“四肢”。大脑可以对四肢发出指令,而 LLM 则会根据用户的提问来决定调用哪些工具。
所谓工具,其实就是供 LLM 调用的程序,可以是实现特定功能的类或函数,也可以是对外部 API 的封装。
一个工具通常需要包含以下几个部分:
工具的名称
工具的功能描述
工具入参的 JSON Schema
执行工具逻辑的函数
在 LangChain 中,支持三种方式来创建工具:
函数方式
通过 Runnables 创建
继承 BaseTool 类
下面将分别介绍这三种工具创建方式。
5.2 通过函数创建工具 通过函数方式创建工具时,需要配合 @tool 注解,将函数转换为工具。其中,第一个参数默认为工具名称,args_schema 用于指定入参结构,return_direct 表示工具调用完成后是否直接将结果传递给大模型:当值为 True 时,结果会直接返回;当值为 False 时,结果会先经过大模型加工后再返回。示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from langchain_core.tools import toolfrom pydantic.v1 import Field, BaseModelclass AddNumberInput (BaseModel ): num1: int = Field(description="第一个数" ) num2: int = Field(description="第二个数" ) @tool("add-tool" , args_schema=AddNumberInput, return_direct=True def add (num1: int , num2: int ): """两数相加""" return num1 + num2 print (f"工具名称:{add.name} " )print (f"工具描述:{add.description} " )print (f"工具参数:{add.args} " )print (f"是否直接返回:{add.return_direct} " )print ("1+1=" + str (add.invoke({"num1" : 1 , "num2" : 1 })))
执行结果如下:
1 2 3 4 5 工具名称:add-tool 工具描述:两数相加 工具参数:{'num1': {'title': 'Num1', 'description': '第一个数', 'type': 'integer'}, 'num2': {'title': 'Num2', 'description': '第二个数', 'type': 'integer'}} 是否直接返回:True 1+1=2
除了使用注解的方式,还可以通过 StructuredTool 来创建工具。StructuredTool.from_function 类方法相比 @tool 注解提供了更多配置项,并且不需要额外编写代码。其中,func 参数用于传入同步执行的函数,coroutine 参数则用于传入异步执行的函数,其余参数的作用与前面介绍的相同。示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 import asynciofrom langchain_core.tools import StructuredToolfrom pydantic.v1 import BaseModel, Fieldclass AddNumberInput (BaseModel ): """加法工具入参""" num1: int = Field(description="第一个数" ) num2: int = Field(description="第二个数" ) def add (num1: int , num2: int ): """两数相加""" return num1 + num2 asyncdef async_add(num1: int , num2: int ): """两数相加""" return num1 + num2 add_tool = StructuredTool.from_function( func=add, coroutine=async_add, name="add_tool" , description="两数相加" , args_schema=AddNumberInput, return_direct=True , ) print (f"工具名称:{add_tool.name} " )print (f"工具描述:{add_tool.description} " )print (f"工具参数:{add_tool.args} " )print (f"是否直接返回:{add_tool.return_direct} " )print ("1+1=" + str (add_tool.invoke({"num1" : 1 , "num2" : 1 })))asyncdef async_main(): result = await add_tool.ainvoke({"num1" : 2 , "num2" : 5 }) print ("2+5=" + str (result)) asyncio.run(async_main())
执行结果如下:
1 2 3 4 5 6 工具名称:add_tool 工具描述:两数相加 工具参数:{'num1': {'title': 'Num1', 'description': '第一个数', 'type': 'integer'}, 'num2': {'title': 'Num2', 'description': '第二个数', 'type': 'integer'}} 是否直接返回:True 1+1=2 2+5=7
5.3 通过Runnables创建工具 通过可运行组件(Runnable)的 as_tool() 方法也可以创建工具。由于由多个可运行组件组成的链(Chain)本身也是一个 Runnable,因此可以直接调用 chain.as_tool() 方法,将整个链包装成一个工具。示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import dotenv from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_openai import ChatOpenAI from pydantic.v1 import BaseModel, Field # 读取env配置 dotenv.load_dotenv() class RandomInput(BaseModel): """生成随机数入参""" count: int = Field(description="生成随机数个数") # 1.创建提示词模板 prompt = ChatPromptTemplate.from_template("请帮我生成{count}个100以内随机数,只返回随机数本身就好") # 2.构建GPT-3.5模型 llm = ChatOpenAI(model="gpt-3.5-turbo") # 3.创建输出解析器 parser = StrOutputParser() # 4.执行链 chain = prompt | llm | parser random_tool = chain.as_tool(name="random_tool", description="生成100以内随机数", args_schema=RandomInput) print("生成随机数:" + str(random_tool.invoke({"count": 10})))
执行结果:
1 生成随机数:27, 63, 84, 12, 95, 41, 55, 73, 38, 9
还可以通过继承 BaseTool 来创建自定义工具。这种方式的自由度最高,也更加灵活。示例如下:创建 AddNumberTool 类继承 BaseTool,并指定工具相关参数,同时重写 _run() 方法,在方法中实现具体的工具逻辑。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from langchain_core.tools import BaseToolfrom pydantic.v1 import BaseModel, Fieldclass AddNumberInput (BaseModel ): """加法工具入参""" num1: int = Field(description="第一个数" ) num2: int = Field(description="第二个数" ) class AddNumberTool (BaseTool ): """加法工具""" name = "add_number_tool" description = "两数相加工具" args_schema = AddNumberInput def _run (self, num1: int , num2: int ) -> int : return num1 + num2 add_number_tool = AddNumberTool() print (f"工具名称:{add_number_tool.name} " )print (f"工具描述:{add_number_tool.description} " )print (f"工具参数:{add_number_tool.args} " )print (f"是否直接返回:{add_number_tool.return_direct} " )print ("1+1=" + str (add_number_tool.invoke({"num1" : 1 , "num2" : 1 })))
执行结果:
1 2 3 4 5 工具名称:add_number_tool 工具描述:两数相加工具 工具参数:{'num1': {'title': 'Num1', 'type': 'integer'}, 'num2': {'title': 'Num2', 'type': 'integer'}} 是否直接返回:False 1+1=2
5.5 总结 通过工具,LLM 这个“超级大脑”有了四肢,甚至可以配备各种各样的“武器”。这些“武器”就是提供给 LLM 的工具。有了工具,LLM 不再只是一个聊天助手,而是能够真正解决问题的助手。它可以根据用户的提问内容做出判断,决定需要调用哪些工具,并传递相应的参数。
在 LangChain 中,创建工具的方式有多种,不同方式适用于不同场景:通过函数创建工具,适合实现简单功能;将 Chain 包装成工具,方便已有逻辑的复用;如果需求比较复杂,则可以通过继承 BaseTool 类的方式,实现更灵活的工具。
通过本文的介绍,相信你已经理解了为什么需要工具,以及 LLM 如何进行工具调用。除此之外,我们还重点介绍了多种工具创建方式。在下一篇文章中,将会详细讲解如何让 LLM 实际完成工具调用,欢迎持续关注。