本门课程为精品小课,不标配音频
你好,我是常扬。
上节课我们详细探讨了RAG(Retrieval-Augmented Generation, 检索增强生成)的技术背景、应用场景以及技术流程。这节课我们将进入代码实战,从0到1快速搭建RAG应用。我们会使用广泛流行的开源库搭建核心框架,完成RAG流程的代码构建。后续课程将基于这节课的实战项目,进一步深入分析各流程的核心技术细节及应用优化,提供更多技术选型的建议和实战代码。
这节课代码实战内容包括技术框架的介绍与选型、开发环境搭建与技术库安装、RAG流程的代码实现。所有相关代码我都会公开在Gitee平台上,供你参考和使用。
技术框架与选型
我们先来探讨RAG技术的框架与选型问题。我们课程中的选型并非适用于所有场景的最佳方案,而是基于当前广泛应用和流行的技术模块。关于这些模块的具体特点以及可能的替代选型,我们会在后续课程中进行详细分析与解读。
RAG技术框架:LangChain
LangChain是专为开发基于大型语言模型(LLM)应用而设计的全面框架,其核心目标是简化开发者的构建流程,使其能够高效创建LLM驱动的应用。
索引流程 - 文档解析模块:pypdf
pypdf是一个开源的Python库,专门用于处理PDF文档。pypdf支持PDF文档的创建、读取、编辑和转换操作,能够有效提取和处理文本、图像及页面内容。
索引流程 - 文档分块模块:RecursiveCharacterTextSplitter
采用LangChain默认的文本分割器-RecursiveCharacterTextSplitter。该分割器通过层次化的分隔符(从双换行符到单字符)拆分文本,旨在保持文本的结构和连贯性,优先考虑自然边界如段落和句子。
索引/检索流程 - 向量化模型:bge-small-zh-v1.5
bge-small-zh-v1.5是由北京人工智能研究院(BAAI,智源)开发的开源向量模型。虽然模型体积较小,但仍然能够提供高精度和高效的中文向量检索。该模型的向量维度为512,最大输入长度同样为512。
索引/检索流程 - 向量库:Faiss
Faiss全称Facebook AI Similarity Search,由Facebook AI Research团队开源的向量库,因其稳定性和高效性在向量检索领域广受欢迎。
生成流程 - 大语言模型:通义千问 Qwen
通义千问Qwen是阿里云推出的一款超大规模语言模型,支持多轮对话、文案创作、逻辑推理、多模态理解以及多语言处理,在模型性能和工程应用中表现出色。采用云端API服务,注册有1,000,000 token的免费额度。
上述选型在RAG流程图中的应用如下所示:
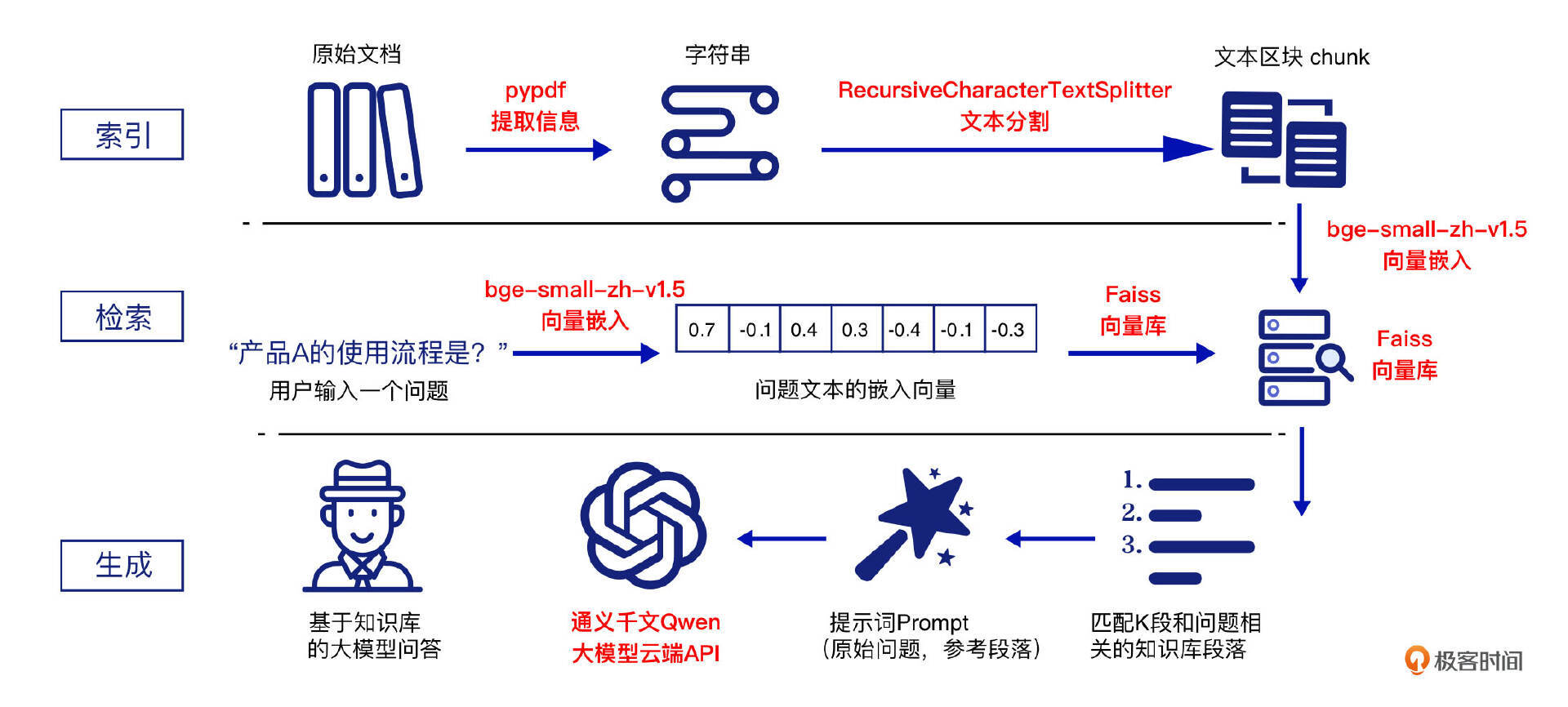
- LangChain:提供用于构建LLM RAG的应用程序框架。
- 索引流程:使用 pypdf 对文档进行解析并提取信息;随后,采用 RecursiveCharacterTextSplitter 对文档内容进行分块(chunks);最后,利用 bge-small-zh-v1.5 将分块内容进行向量化处理,并将生成的向量存储在 Faiss 向量库中。
- 检索流程:使用 bge-small-zh-v1.5 对用户的查询(Query)进行向量化处理;然后,通过 Faiss 向量库对查询向量和文本块向量进行相似度匹配,从而检索出与用户查询最相似的前 top-k 个文本块(chunk)。
- 生成流程:通过设定提示模板(Prompt),将用户的查询与检索到的参考文本块组合输入到 Qwen 大模型中,生成最终的 RAG 回答。
开发环境与技术库
我们采用Python编程语言,Python版本3.8及以上,运行于Linux操作系统下。结合上述的技术框架与选型,我们的开发环境需要按照以下步骤进行准备:
- 创建并激活虚拟环境:目的是隔离项目依赖,避免项目之间冲突。先在命令行窗口中执行指令定位到具体的RAG项目文件夹,然后在命令行中执行以下指令:
1 | python3 -m venv rag_env # 创建名为rag_env的虚拟环境 |
- 安装技术依赖库:包括langchain、langchain_community LLM RAG的技术框架及其扩展,pypdf 处理PDF文档的解析库,sentence-transformers 运行指定文本嵌入模型 bge-small-zh-v1.5 的模型库,faiss-cpu 高效相似度搜索的 Faiss 向量库,dashscope 与阿里云Qwen大模型API的集成库。
首先,升级pip版本,以确保兼容性,在命令行中执行以下指令:
1 | pip install --upgrade pip # 升级pip版本以确保兼容性 |
然后,安装上述技术依赖库,在命令行中执行以下指令:
1 | pip install langchain langchain_community pypdf sentence-transformers faiss-cpu dashscope |
如果无法连接,可以使用国内镜像站点,在命令行中执行以下指令:
1 | pip install langchain langchain_community pypdf sentence-transformers faiss-cpu dashscope -i https://pypi.tuna.tsinghua.edu.cn/simple |
- 下载bge-small-zh-v1.5模型:该模型的文件已包含在 Gitee 上托管的项目中的 bge-small-zh-v1.5 文件夹内,你可以直接下载到RAG项目的根目录中,模型大小95.8M,在命令行中执行以下指令:
1 | git clone https://gitee.com/techleadcy/rag_app.git |
下载过程需要一些时间,不要关闭命令行窗口。下载完成后,检查 rag_app 项目中 bge-small-zh-v1.5 文件夹中是否包含pytorch_model.bin文件。该库中同时包含了本讲的RAG核心流程代码rag_app_lesson2.py及测试PDF文档test_lesson2.pdf。
- 准备测试 PDF 文档:Gitee 上托管的项目中包含一份名为 test_lesson2.pdf 的数字化转型报告。这个报告涵盖了数字化转型的背景和意义、案例分析,以及制造业、零售业、金融业的数字化转型等章节。你也可以替换成自己的 PDF 文件,并更改查询问题,体验 RAG 应用的效果。
完成以上步骤后,RAG应用开发所需的环境及技术依赖库就已准备就绪。
RAG核心流程代码
在实战过程中,你不仅可以快速构建RAG应用,还能够在研发过程中深入理解其背后的技术逻辑与核心原理。为此,我在代码的每一行添加了必要的注释,并对每段流程代码进行了归纳和解释,旨在通过实战代码增强你对RAG技术的理解。
整个流程代码分为模块库的引入、索引流程、检索流程、生成流程以及测试代码几部分进行精细讲解,具体的代码位于Gitee项目库中的rag_app_lesson2.py文件中。
模块库的引入
1 | from langchain_community.document_loaders import PyPDFLoader # PDF文档提取 |
阿里云百炼大模型服务平台获取的Qwen大模型的API密钥流程如下:
- 打开阿里云百炼大模型服务平台 ,点击立即开通,登陆阿里云/支付宝/钉钉账号;
- 点击模型广场,搜索 通义千问-Turbo,点击API 调用示例;
- 点击查看我的API-KEY,继续点击弹出框中的查看,复制API-KEY,将API-KEY替换代码中qwen_api_key = “your_api_key”;
- 点击模型详情,可以看到模型Model英文名称,赋值qwen_model参数。可以看到剩余额度,当前阿里云提供1,000,000次的免费模型额度;
- 如果需要尝试其他模型,可以对应赋值上述代码中qwen_model参数及qwen_api_key参数。
以上代码导入了我们在RAG流程中需要使用的核心模块及大模型参数等配置,这些模块和配置将在后续的索引、检索和生成流程中调用使用。
索引流程
1 | def load_embedding_model(): |
上述代码实现了RAG技术中的索引流程,首先使用 PyPDFLoader 加载并预处理PDF文档,将其内容提取并合并为完整文本。接着,利用 RecursiveCharacterTextSplitter 将文本分割为每块512字符(非token)、重叠128字符(非token)的文本块,并通过预加载的 bge-small-zh-v1.5 嵌入模型将这些文本块转化为归一化的嵌入向量。最终,这些嵌入向量被存储在基于余弦相似度的 Faiss 向量库中,以支持后续的相似性检索和生成任务。
为更清晰地展示RAG流程的各个细节,当前代码未涉及多文档处理、嵌入模型的效率优化与并行处理。此外,Faiss 向量目前仅在内存中存储,未考虑持久化存储问题。以及文档解析、文本分块、嵌入模型与向量库的技术选型,后续课程将逐步深入探讨,并以上述代码作为基础,持续优化。
检索流程
1 | def retrieval_process(query, index, chunks, embedding_model, top_k=3): |
上述代码实现了RAG技术中的检索流程。首先,用户的查询(Query)被预加载的 bge-small-zh-v1.5 嵌入模型转化为归一化的嵌入向量,进一步转换为 numpy 数组以适配 Faiss 向量库的输入格式。然后,利用 Faiss 向量库中的向量检索功能,计算查询向量与存储向量之间的余弦相似度,从而筛选出与查询最相似的前 top_k 个文本块。这些文本块及其相应的相似度得分被逐一输出,相似文本块存储在结果列表中,最终返回供后续生成过程使用。
生成流程
1 | def generate_process(query, chunks): |
上述代码实现了RAG流程中的生成过程。首先,结合用户查询与检索到的文本块内容组织成大模型提示词(Prompt)。随后,代码通过调用 Qwen 大模型云端 API,将构建好的Prompt发送给大模型,并利用流式输出的方式逐步获取模型生成的响应内容,实时输出并汇总为最终的生成结果。
测试脚本
1 | def main(): |
在命令行窗口中执行指令定位到具体的RAG项目文件夹,在命令行中执行以下指令即可开始RAG应用测试:
1 | source rag_env/bin/activate # 激活虚拟环境 |
测试代码通过 main() 函数串联各个步骤,从索引到生成,确保RAG的各个环节顺畅执行,准确完成“下面报告中涉及了哪几个行业的案例以及总结各自面临的挑战?”的RAG问答任务。
正确运行结果如下所示:
1 | RAG过程开始. |
总结
这节课我通过代码实战向你展示了RAG技术的完整实现过程,涵盖了索引、检索、生成三个核心流程。上述代码已公开在Gitee代码仓库中,链接地址为:https://gitee.com/techleadcy/rag_app。
技术选型方面,我们选择了 LangChain 作为核心框架,结合 pypdf 用于PDF文档解析,RecursiveCharacterTextSplitter 用于文本分块,bge-small-zh-v1.5 作为嵌入模型,Faiss 作为向量检索库,以及阿里云的Qwen大模型用于生成任务。
代码实战中,我们依次完成了嵌入模型的加载、PDF文档的解析与文本分块、向量化嵌入与Faiss向量库的构建、用户查询的检索匹配,以及最终的生成模型调用。
这节课的实战内容为后续课程奠定了基础,后续课程将深入讲解每个技术流程的细节,并在此实战项目基础上对代码进行持续优化和迭代。
思考题
我们基于上述技术组件快速搭建了RAG应用,实现了其核心流程。然而,在真实的应用场景中,可能还需要补充一些关键组件才能更好、更优地满足用户需求,需要补充哪些关键组件呢?欢迎你在留言区补充,描述它们的作用,我们共同完善RAG应用效果,如果你觉得这节课的内容对你有帮助的话,也欢迎你分享给其他朋友,我们下节课再见!