
1. 初探
1.1 MGR 简介
MySQL 5.7 推出了 MGR(MySQL Group Replication),能让我们方便的创建弹性、高可用、容错的复制拓扑。
MGR 单主和多主两个模式。
- 单主模式:自动选主,每次只能接受一个服务器更新。
- 多主模式:所有服务器都可以更新,即使是并发执行的。
MGR 保证了 MySQL 服务的持续可用,但是,完整的高可用方案,还需要用到 InnoDB Cluster。后续内容会仔细讲解。
1.2 MySQL 复制
MySQL 传统的复制中,一般有一个主,一个或者多个从。主库有修改数据的事务,会记录到 Binlog 中,然后传给从库,并在从库回放主库执行的变更语句。大致流程如下:
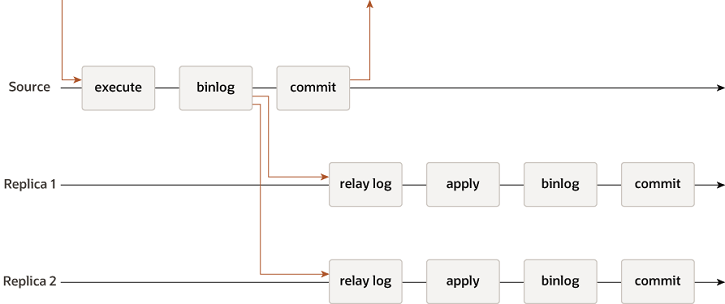
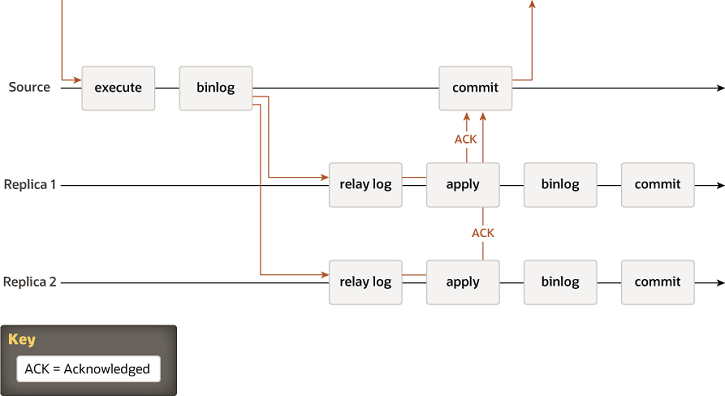
后面又出现了半同步复制,主服务器在处理事务时,需要等待从服务器来确认它已经接受到事务,主服务才会提交。
1.3 组复制
组复制由多个服务器组成,组中每个服务器可以独立执行事务(多主模式)。但是,所有读写事务只有在获得组批准后才会提交(只读事务可以不通过组内协调就能提交)。大致流程如下图:
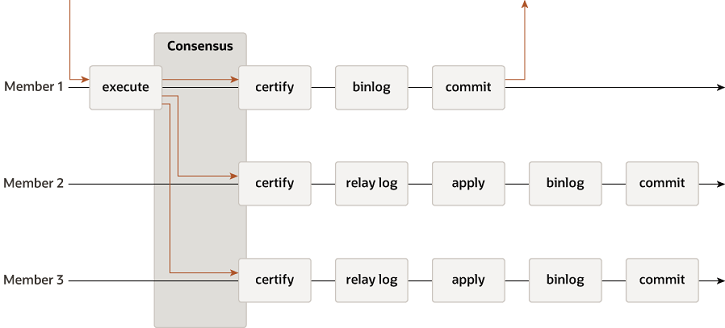
当读写事务准备在原始服务器上提交时,服务器会自动广播已更改的行和已更新行的唯一标识符,因为事务是通过原子广播发送的,组中的所有服务器要么接收事务,要么都不接收。并且都以相同的顺序接收同一组事务,并为事务建立一个全局总顺序。
在不同节点上并发执行的事务会进行冲突检测,如果在不同节点上的两个并发事务更新的是同一行,则与死锁处理类似,排序靠前的提交,排序靠后的回滚。
1.4 MGR 应用场景
下面是 MGR 典型的使用场景:
- 弹性复制:服务器的数量必须动态增长或收缩,并且影响尽可能少,比如:云数据库。
- 多写:在某些情况下,向整个组写入数据可能更具有可伸缩性。
- 自动 Failover:MGR 可自动 Failover。
1.5 MGR 主要的一些限制
在确定要使用 MGR 之前,我们要知道 MGR 的一些限制,其中主要限制有下面这些:
- 只支持 InnoDB 表:如果存在冲突,为了保证组中各个节点的数据一致,需要回滚事务,所以必须是一个支持事务的引擎。
- 每张表都要有主键或非空的唯一字段:可以保证每一行数据都有唯一标识符,这样整个 MGR 系统可以判断每个事务修改了哪些行,从而确定事务是否发生了冲突。
- 必须开启 GTID:MGR 是基于 GTID 的复制,通过 GTID 来跟踪已经提交到组中的每个服务器实例上的事务。
- 多主模式下不支持 SERIALIZABLE 隔离级别:多主模式下,设置 SERIALIZABLE 隔离级别 MGR 将拒绝提交事务,当然,这个隔离级别通常也不太可能使用,除非做实验的时候。
- 最多只支持 9 个节点:这个限制是官方通过测试确定的一个安全边界,在这个安全边界内,组可以在一个稳定的局域网中可靠地执行任务。
- 网络延迟会影响 MGR 的性能:在上面的内容中,也提到了:“所有读写事务只有在获得组批准后才会提交”,所以如果节点之间出现网络延迟,将影响事务提交的速度。
2. 安装
2.1 架构介绍
首先来介绍一下本节内容的大致架构:
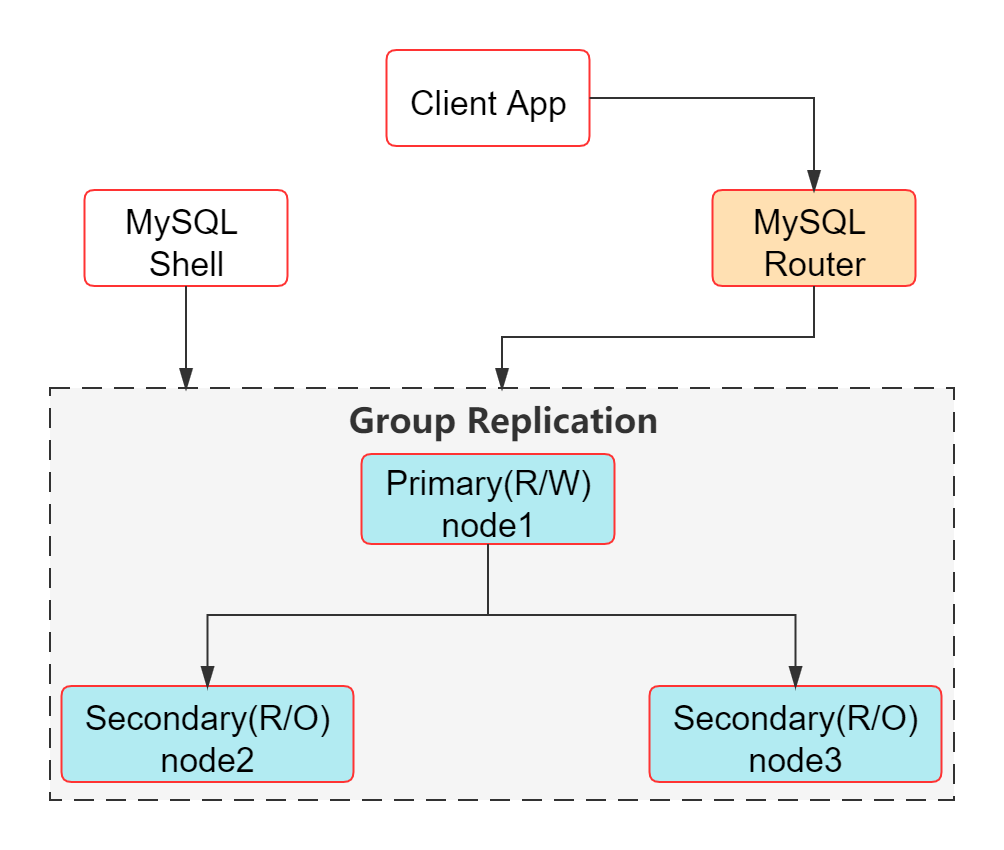
其中 MGR 三个节点分别在下面三台机器上(操作系统均为:CentOS 7.4):
- node1:192.168.150.232。
- node2:192.168.150.253。
- node3:192.168.150.123。
MySQL Shell 和 MySQL Router 都部署在 node1 上。当然,如果是生产环境,官方建议把 MySQL Router 和应用程序部署在相同机器上(详情可参考:https://dev.mysql.com/doc/mysql-shell/8.0/en/admin-api-deploy-router.html)。
MySQL Shell 用于部署和管理 MGR;MySQL Router 进行路由,当 MGR 内部发生切换时,MySQL Router 会自动识别。
2.2 基础环境准备
在 /etc/hosts 文件中加入:
1 | 192.168.150.232 node1 |
三个节点安装 MySQL
需要调整部分参数:
1 | [mysql] |
这里解释一下上面部分参数的含义:
- disabled_storage_engines,MGR 只支持 InnoDB 存储引擎,所以可以通过增加这个参数来禁用其他引擎。
- server_id,三台机器配置不同的 server_id。
- gtid_mode,必须启用 GTID。
- enforce_gtid_consistency,服务器只允许执行安全的 GTID 语句来保证一致性。
- binlog_transaction_dependency_tracking,控制事务依赖模式,MGR 中,需要设置为 WRITESET。
- slave_parallel_type,需要设置为 LOGICAL_CLOCK。
- slave_preserve_commit_order,需要设置为 1,表示并行事务的最终提交顺序与 Primary 提交的顺序保持一致,以保证数据一致性。
- plugin_load_add,启动时加载插件。这里配置的是组复制的插件。
- group_replication_group_name,告诉插件它要加入或创建的组名。group_replication_group_name 必须是合法的 UUID,可以使用 select UUID() 生成一个,这个 UUID 构成了 GTID 的一部分,当组成员从客户端接收事务时,以及组成员内部生成的视图更改事件被写入二进制日志时,使用 GTID。
- group_replication_start_on_boot,设置为 off 会指示插件在服务器启动时不会自动启动操作。这在设置 Group Replication 时非常重要,因为它确保您可以在手动启动插件之前配置服务器。一旦配置了成员,就可以将 group_replication_start_on_boot 设置为 on,以便组复制在服务器启动时自动启动。
- group_replication_local_address,可以设置成员与组内其他成员进行内部通信时使用的网络地址和端口。Group Replication 将此地址用于涉及组通信引擎(XCom, Paxos的一种变体)的远程实例内部成员到成员之间的连接。group_replication_local_address 配置的网络地址必须是所有组成员都可以解析的。
- group_replication_group_seeds,设置组成员的主机名和端口,新成员将使用这些成员建立到组的连接。
- group_replication_bootstrap_group,指示插件是否引导该组,在本例中,即使s1是组的第一个成员,我们也在选项文件中将这个变量设置为 off。相反,我们在实例运行时配置 group_replication_bootstrap_group,以确保实际上只有一个成员引导组。
- plugin-load-add,增加了 Clone Plugin,如果 MySQL 版本是 8.0.17 或更高的版本,则 MGR 在新增节点时,可以使用 Clone Plugin 来传输集群中已有的数据给新增节点。
2.3 MySQL Shell 安装
登录 https://downloads.mysql.com/archives/shell/,选择与 MySQL 对应的版本进行下载:

安装 MySQL Shell:
1 | yum install mysql-shell-8.0.25-1.el7.x86_64.rpm -y |
2.4 创建集群用户
在三个节点创建集群用户,语句如下:
1 | CREATE USER 'mgr_user'@'%' IDENTIFIED BY 'BgIka^123'; |
2.5 用 MySQL Shell 创建 MGR
通过 MySQL Shell 连接 node1 上的 MySQL:
1 | mysqlsh -umgr_user -p'BgIka^123' -h192.168.150.232 |
进入MySQL Shell 之后,执行下面命令创建集群:
1 | var cluster = dba.createCluster('Cluster01') |
如果后续退出了 MySQL Shell,则可以用下面语句重新定义 cluster:
1 | var cluster = dba.getCluster('Cluster01') |
如果显示如下信息,则表示第一个节点配置成功:
1 | A new InnoDB cluster will be created on instance '192.168.150.232:3306'. |
将第二个节点加入集群:
1 | cluster.addInstance('mgr_user@192.168.150.253:3306') |
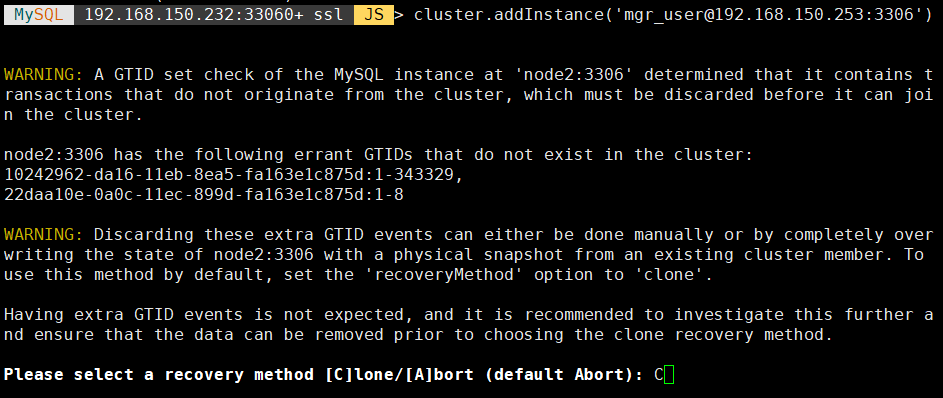
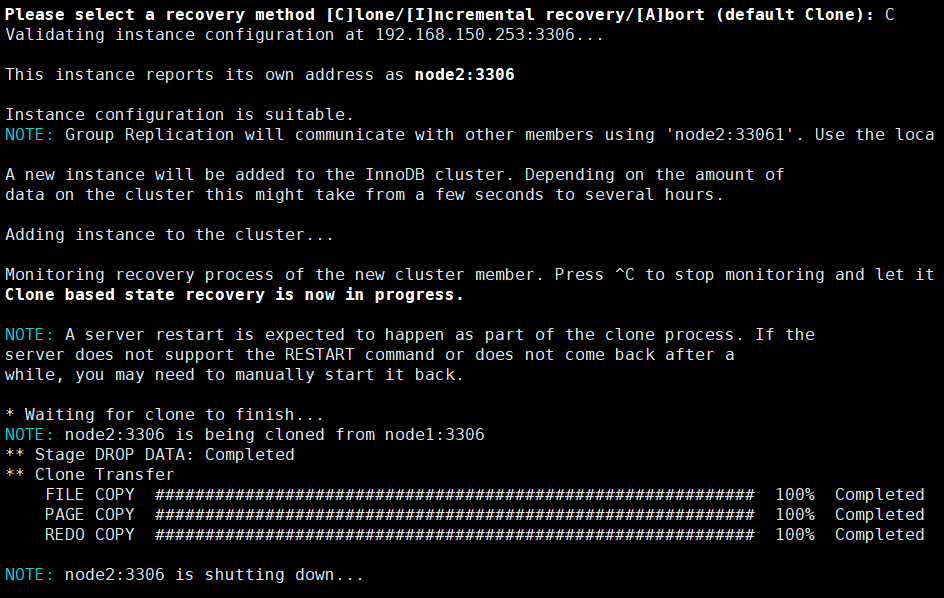
最后一行表示新加入节点的数据同步方法,选择 C,表示使用 MySQL 的 Clone Plugin。可看到如下界面:
查看集群状态,执行:
1 | cluster.status(); |
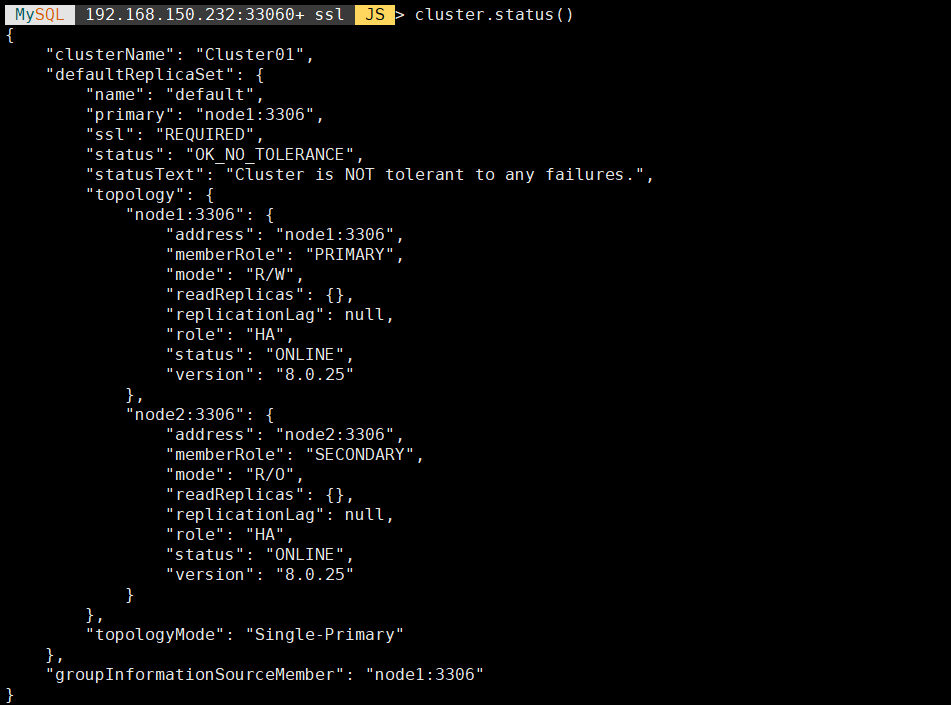
有时会在 instanceErrors 有一些提示,可按提示进行操作,比如:
则直接执行 cluster.rescan() 即可。该命令和更新集群元数据。
将第三个集群加入节点:
1 | cluster.addInstance('mgr_user@192.168.150.123:3306') |
执行 cluster.status() 查看集群状态:
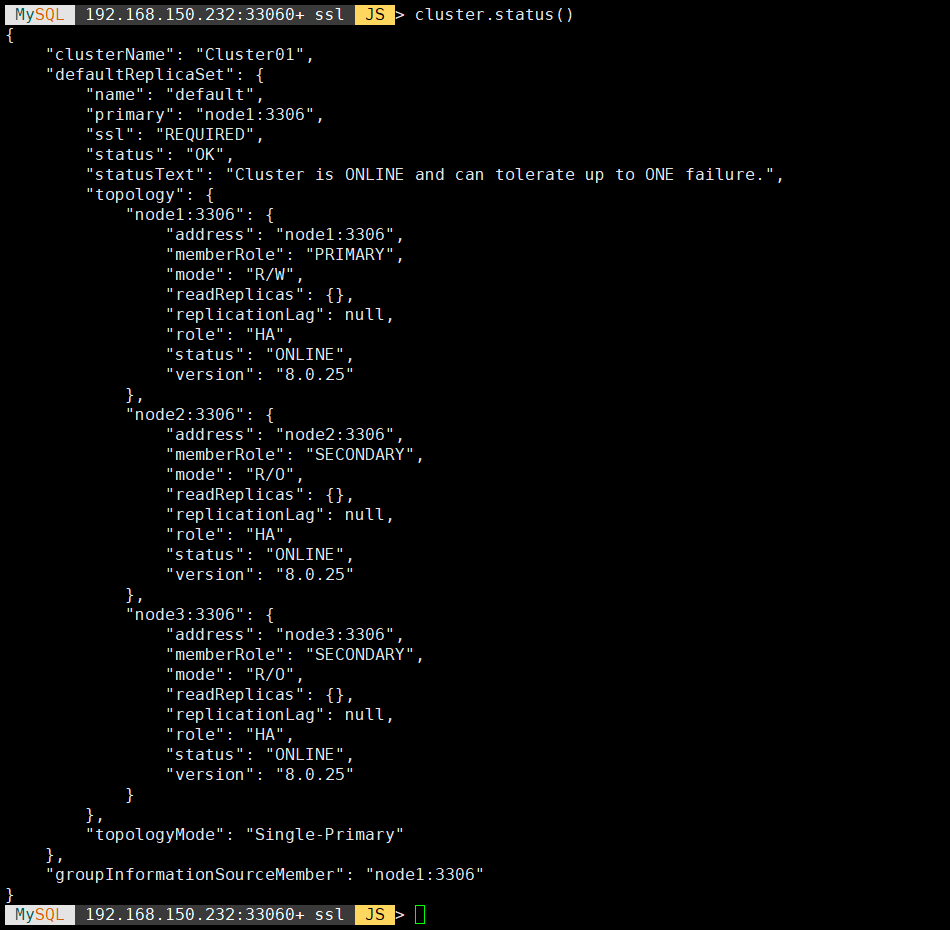
2.6 MySQL Router 安装
在 https://downloads.mysql.com/archives/router/ 中选择与 MySQL 版本相同的 MySQL Router:
如果是用本节中“基础环境准备”的 MySQL 版本和操作系统,则直接执行下面命令下载 MySQL Router:
1 | wget https://downloads.mysql.com/archives/get/p/41/file/mysql-router-community-8.0.25-1.el7.x86_64.rpmyum install mysql-router-community-8.0.25-1.el7.x86_64.rpm -y |
生成配置文件
1 | mkdir /data/mysqlroutemysqlrouter -B mgr_user@192.168.150.232:3306 --directory=/data/mysqlroute -u root --force |
会有如下显示:
1 | Please enter MySQL password for mgr_user: # Bootstrapping MySQL Router instance at '/data/mysqlroute'... |
其中:
- 6446 为读写端口
- 6447 为只读端口
启动 MySQL Router:
1 | /data/mysqlroute/start.sh |
我们再来测试一下。
通过读写端口登录 MySQL Router,执行 select @@hostname:
1 | mysql -umgr_user -p'BgIka^123' -P6446 -h192.168.150.232 -e "select @@hostname" |
结果如下:
1 | mysql> select @@hostname;+------------+| @@hostname |+------------+| node1 |+------------+1 row in set (0.00 sec) |
发现是路由到 node1。
多次通过只读端口登录 MySQL Router:
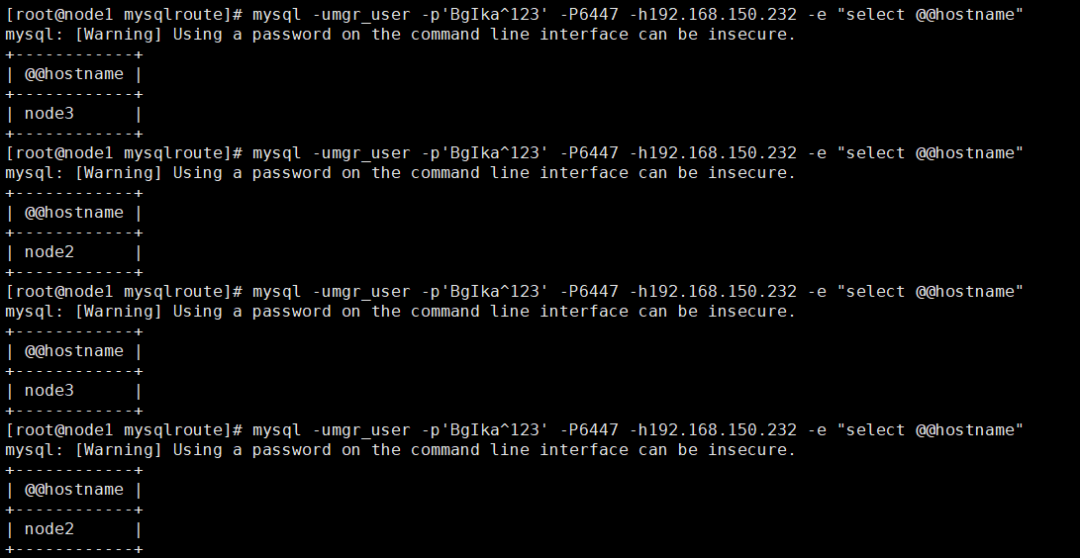
发现新建的连接会在 node2 和 node3 两个 SECONDARY 节点之间轮询。当然,另外还需要测试数据写入和查询是否正常,这个就自行完成拉。
到这里,整个 InnoDB Cluster 部署完成。
2.7 参考文档
Installing MySQL Shell on Linux:https://dev.mysql.com/doc/mysql-shell/8.0/en/mysql-shell-install-linux-quick.html
Deploying a Production InnoDB Cluster:https://dev.mysql.com/doc/mysql-shell/8.0/en/deploying-production-innodb-cluster.html
Group Replication Requirements:https://dev.mysql.com/doc/refman/8.0/en/group-replication-requirements.html
Installing MySQL Router on Linux:https://dev.mysql.com/doc/mysql-router/8.0/en/mysql-router-installation-linux.html
Deploying MySQL Router:https://dev.mysql.com/doc/mysql-shell/8.0/en/admin-api-deploy-router.html
3. 操作
3.1 创建集群
1 | var cluster = dba.createCluster('Cluster01') |
3.2 给集群分配变量
将集群 Cluster01 分配给变量 cluster,如果刚通过 1 中的方式创建了集群,则可以不执行,如果是创建完集群,又退出了 MySQL Shell,则需要执行,方便后面命令执行。
1 | var cluster = dba.getCluster('Cluster01') |
3.3 获取集群结构信息
1 | cluster.describe() |
3.4 查看集群状态
1 | cluster.status() |
比如下面例子(为方便查看,部分内容已经用 …… 替换):
1 |
|
这里重点解释一下 status 列,表示该节点的状态,可能是下面几种值:
- ONLINE:实例在线并加入集群。
- OFFLINE:该实例已失去与其他实例的连接。
- RECOVERING:该实例正在检索它需要的事务来与集群同步 。
- UNREACHABLE:实例已失去与集群的通信。
- ERROR:实例在恢复阶段或应用事务时遇到错误。
3.5 配置检查
新节点加入集群之前,检查配置是否正确:
1 | dba.checkInstanceConfiguration('mgr_user@node4:3306') |
3.6 节点验证
验证新加节点上的数据是否会阻止它加入集群:
1 | cluster.checkInstanceState('mgr_user@node4:3306') |
比如:
1 | MySQL 192.168.150.232:33060+ ssl JS > cluster.checkInstanceState('mgr_user@node4:3306') |
输出可以是下面这些情况:
- OK new:实例没有执行任何 GTID 事务,因此不会与集群执行的 GTID 冲突。
- OK 可恢复:实例执行的 GTID 与集群种子实例执行的 GTID 不冲突。
- ERROR diverged: 实例执行的 GTID 与集群种子实例执行的 GTID 不一致。
- ERROR lost_transactions:实例执行的 GTID 比集群种子实例的执行 GTID 多。
State 为 ok,表示可以加入集群。
3.7 增加实例
1 | cluster.addInstance('mgr_user@192.168.150.123:3306'); |
3.8 删除实例
1 | cluster.removeInstance('mgr_user@192.168.150.123:3306'); |
3.9 列出集群中实例的配置
1 | cluster.options() |
3.10 更改集群全局配置
1 | cluster.setOption(option, value) |
3.11 更改集群单个实例的配置
1 | cluster.setInstanceOption(instance, option, value) |
3.12 将实例重新加入集群
1 | cluster.rejoinInstance(instance) |
3.13 使用仲裁恢复集群
如果部分实例故障,导致集群可能失去法定投票人数,无法进行投票,则可以选择一个包含集群元数据的实例,执行仲裁操作,从而恢复集群。这种方式也是在集群恢复过程中,其他方法都无法恢复集群情况下,最后的操作,通常不建议使用,可能会导致集群脑裂。
命令如下:
1 | cluster.forceQuorumUsingPartitionOf('mgr_user@node1:3306'); |
该命令如果在运行正常的集群执行,则会出现如下报错:
1 | ERROR: Cannot perform operation on an healthy cluster because it can only be used to restore a cluster from quorum loss.Cluster.forceQuorumUsingPartitionOf: The cluster has quorum according to instance 'node1:3306' (RuntimeError) |
3.14 切换到多主模式
1 | cluster.switchToMultiPrimaryMode() |
3.15 切换到单主模式
1 | cluster.switchToSinglePrimaryMode('node3:3306') |
如果指定了节点,则该实例将成为主节点;如果没有指定节点,则新主是权重最高的节点,权重相同时,则新主是 UUID 最低的节点。
3.16 更新集群元数据
1 | cluster.rescan() |
比如我们手动更改了实例的配置,或者实例退出集群之后,需要更新集群的元数据,则可以使用该命令。
rescan() 操作可以检测没有在元数据中注册的新活动实例并添加它们,或者删除在元数据中的过时实例。
4. 原理
4.1 故障检测
MGR 的成员之间会互相发送检测消息,当服务器 A 在给定的时间内没有接收到服务器 B 的消息时,会发生超时并产生怀疑。
之后,如果小组同意怀疑可能是真的,那么小组就会认定某个服务器确实出了故障,这意味着组中其他成员采取协调一致的决定来驱逐给定的成员。
在网络不稳定的情况下,成员之间可能会多次断开和重连,极端情况,一个组最终可能会将所有成员标记为驱逐,之后组不复存在,必须重建。
为了应对这种情况,从 MySQL 8.0.20 开始,组通信系统(GCS)跟踪已经被标记为驱逐的成员,然后决定是否有大多数成员将其标记为怀疑。这样可以确保至少有一个成员留在主中,当被剔除的成员实际上已经从组中删除时,GCS 将删除该成员被剔除的记录,以便该成员可以在恢复之后重新加入组。
4.2 选举算法
单主模式下,主出现故障,会考虑下面的因素选择新的主:
- 考虑的第一个因素是哪个成员运行的是最低的 MySQL 版本。如果所有成员都运行 MySQL 8.0.17 或更高版本,那么组成员将首先按照发布的补丁版本进行排序。如果任何成员运行 MySQL 8.0.16 或更低的版本,成员将首先按其发布的主要版本排序,并忽略补丁版本。低版本优先是考虑到高版本同步到低版本,高版本可能有一些新特性,无法在从库正常回放,导致同步出现问题。
- 如果有多个成员运行最低的 MySQL 版本,则要考虑的第二个因素是每个成员的权重,由参数 group_replication_member_weight 指定。如果 MySQL 的版本为 5.7,则该参数不可用,将不考虑这个因素。系统变量 group_replication_member_weight 指定一个范围为 0-100 的数字。值越大,权重越高。
- 如果前面两个因素都一样,则考虑的是,每个成员生成的服务器 UUID 的词法顺序,如果 server_uuid 系统变量都指定了,则选择 UUID 排序最靠前的成员作为主。
多主模式下,如果一个成员出现故障,连接到它的客户端可以重定向或故障转移到处于读写模式的任何其他成员。Group Replication 本身并不处理客户端故障转移,因此需要使用中间件框架,比如 MySQL Route。
4.3 故障转移
从节点提升为主前,要处理积压的事务,通常有两种选择:
- 可靠性优先:如果有积压的事务,需要等积压的事务全被应用完,才能在新主上进行读写操作。
- 可用性优先:不管是否有积压的事务,直接在新主上进行读写操作。
如果将 group_replication_consistency(该参数会在 MGR 专题后面的文章详细讲解) 设置为 BEFORE_ON_PRIMARY_FAILOVER,则表示设置了可靠性优先。
4.4 视图
Group Replication 每个成员都有一个一致性视图,显示哪些服务器是在工作的。
成员离开或者加入组时,都会触发视图的更新。有时服务器可能会意外离开组,在这种情况下,故障检测机制会检测到这一点,并通知组视图已更改。
4.5 流控
在多主模式中,速度较慢的成员还可能积累过多的事务以进行认证和应用,可能会导致冲突、认证失败或者读到过期数据等风险。为了解决这些问题,可以激活和调优 Group Replication 的流控制机制,以最小化快成员和慢成员之间的差异。
参数 group_replication_flow_control_mode 控制流控是否开启,如果为 QUOTA,表示开启,DISABLED 表示关闭。
两种情况会触发流控:
- 证书队列中等待的事务数超过 group_replication_flow_control_certifier_threshold 配置的值时。
- 应用程序队列中等待的事务数超过 group_replication_flow_control_applier_threshold 配置的值时
4.6 事务执行流程
我们来回顾在第 1 节所提到的组复制过程图:
一个事务在 MGR 中的执行流程大致如下:
- 事务写 Binlog 之前会进入到 MGR 层;
- 事务消息通过 Paxos 广播到各个节点;
- 在各个节点上进行冲突检测(冲突检测详细过程会在稍后介绍);
- 认证通过后本地节点写 Binlog 完成提交;
- 其他节点写 Relay Log 后并完成回放。
4.7 冲突检测
在 MGR 中,为了防止多个节点同时更新了同一条记录,设置了冲突检测机制,具体步骤如下:
- 首先计算出对 write set(write set 的组成是:索引名 + DB 名+ DB 名长度 + 表名 + 表名长度 + 构成索引唯一性的每个列的值 + 值长度) 做 murmur hash 算法的值,判断这个值在 certification_info 是否有相同的记录,有则表示冲突,事务回滚,没有则会把 write set 写入 certification_info ,并进行下一步。
- 然后判断事务执行时执行节点的 gtid_executed 和 certification_info 里面对应的 gtid_set。
- 如果 gtid_executed 是 gtid_set 的子集,说明该节点的事务执行时,其他节点已经对事务操作的数据进行了更改,则不能进行更新,事务回滚。
- 如果 gtid_executed 不是 gtid_set 的子集,表示其他节点没有对事务操作的数据有修改操作,则事务可以正常提交。
write set 的计算方式可参考下面例子(参考 MySQL 8.0.25 源码文件:sql/rpl_write_set_handler.cc):
创建一张表:
1 | CREATE TABLE db1.t1 (i INT NOT NULL PRIMARY KEY, j INT UNIQUE KEY, k INT UNIQUE KEY); |
写入一条数据:
1 | INSERT INTO db1.t1 VALUES(1, 2, 3); |
这里 write set 将有三个值:
1 | i -> PRIMARYdb13t1211 => PRIMARY 是主键名 (由主键生成的 write set) |
从上面例子可以看出,会基于记录的主键索引、唯一索引生成不同的 write set,那么仅仅只用主键索引生成一个 write set 是否可以呢?
其实是不可以的,因为不仅主键冲突需要检测,唯一索引的冲突也需要检测。只有主键索引的 write set 无法判断出唯一索引是否违反了唯一性约束。
5. 一致
5.1 事务一致性配置
在 MGR 中,可以通过配置 group_replication_consistency 变量来配置一致性级别,具体可配置的值及含义如下:
- EVENTUAL
RO 和 RW 事务在执行之前都不会等待前面的事务被应用。在发生主故障转移的情况下,在前一个主事务全部应用之前,新的主事务可以接受新的 RO 和 RW 事务。RO 事务可能会导致过期的值,RW 事务可能会由于冲突导致回滚。
- BEFORE_ON_PRIMARY_FAILOVER
新选出的主服务器需要应用完旧主服务器的事务,在应用任何待办事项之前,将不应用新的 RO 或 RW 事务。这确保了当主节点发生故障转移时,无论是否有意,客户机总是看到主节点上的最新值。这保证了一致性,但也意味着客户端必须能够在应用 backlog 时处理延迟。通常这种延迟应该是最小的,但它确实取决于积压的大小(可靠性优先)。
- BEFORE
RW 等待所有前面的事务完成后才应用新的事务。RO 事务等待所有前一个事务完成后才执行。这确保该事务仅通过影响事务的延迟读取最新的值。通过确保只在 RO 事务上使用同步,这减少了每个 RW 事务上的同步开销。这个一致性级别还包括 BEFORE_ON_PRIMARY_FAILOVER 提供的一致性保证。
- AFTER
RW 会等待它的更改被应用到所有其他成员。该值对 RO 事务没有影响。此模式确保在本地成员上提交事务时,任何后续事务都将读取已写入的值或任何组成员上最近的值。应用程序可以使用这一点来确保后续读取最新的数据,其中包括最新的写操作。这个一致性级别还包括 BEFORE_ON_PRIMARY_FAILOVER 提供的一致性保证。
- BEFORE_AND_AFTER
RW,RO 事务都需要等待所有之前的事务完成后才被应用。这个一致性级别还包括BEFORE_ON_PRIMARY_FAILOVER提供的一致性保证。
5.2 事务一致性选择
MGR 设置 BEFORE_ON_PRIMARY_FAILOVER 的目的,也是为了方便我们根据不同的业务场景选择合适的一致性级别,下面就列出一些场景下的一致性级别选择:
- 通常情况下,不建议设置为 AFTER 模式,一方面可能导致集群吞吐量下降,另一方面在节点故障切换时,等待时间相对其他模式会非常长。
- 有大量写操作,偶尔读取数据,并且不必担心读取到过期数据,则可以选择 BEFORE。
- 希望特定事务总是从组中读取最新的数据,这种情况,选择 BEFORE。
- 有一个组,其中主要是只读数据,希望读写(RW)事务总是从组中读取最新的数据,并在提交后应用到所有地方, 这样,后续的读操作都是在最新的数据上完成的,包括你最新的写操作,你不需要在每个只读(RO)事务上花费同步成本,而只在 RW 事务上。在本例中,应该选择 BEFORE_AND_AFTER
- 每天都有一条指令需要做一些分析处理,因此它总是需要读取最新的数据。要实现这一点,您只需要设置 SET @@SESSION.group_replication_consistency= ‘BEFORE’。
5.3 事务一致性修改
查看当前会话的一致性级别:
1 | mysql> select @@session.group_replication_consistency;+-----------------------------------------+| @@session.group_replication_consistency |+-----------------------------------------+| EVENTUAL |+-----------------------------------------+1 row in set (0.00 sec) |
修改当前会话的一致性级别:
1 | mysql> SET @@SESSION.group_replication_consistency= 'BEFORE';Query OK, 0 rows affected (0.00 sec) |
如果需要修改当前实例所有会话的一致性级别,则把上面例子中的 SESSION 改为 GLOBAL。
6. 分割
通常情况下,如果某个节点发生故障,如果多数成员将其视为可疑成员,则将该问题节点剔除。
但是,可能会出现一些极端情况,比如组中多数成员出现问题,那么组将无法继续进行工作,因为剩余节点无法确保法定成员数。
比如 5 个节点的组,有 3 个节点出现问题,则剩下的 2 个节点无法达到法定投票成员数(成员个数和法定投票成员数对应关系可见下表),也就无法判断其他 3 个服务器是否已经崩溃,所以组不能自动更新元数据。这种情况就是 MGR 的网络分隔。
| 组成员个数 | 法定投票成员数 | 能接受的故障成员个数 |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 3 | 2 |
| 6 | 4 | 2 |
| 7 | 4 | 3 |
这里补充另外一种情况:
如果有节点主动退出组,那他们会指示组重新配置自己。这意味着其他成员可以正确地重新配置组,保持成员的一致性,并重新计算法定投票成员数。比如上面的例子中,如果 3 个节点告知组一个接一个地离开,那么组成员数将从 5 变成 2,而组成员个数为 2 的组法定投票成员数也为 2,因此确保了法定投票成员数。
下面来聊聊如果系统被分隔,导致服务器不能自动实现仲裁(也就是无法达到法定投票人数)时,我们应该做什么。
6.1 检测分割
在 performance_schema 库的 replication_group_members 表中,可以看到每个成员的状态。在正常情况下,也就是未分区的时候,该表显示的信息在组中的所有服务器都是一致的,如下所示:
1 | mysql> select * from performance_schema.replication_group_members\G |
如果网络分区了,并且无法实现仲裁,则无法访问到的成员在表中显示为 UNREACHABLE。这种情况下,需要重新配置组成员,或者停掉组中存活的成员,并判断问题节点发生了什么,然后重新启动组。
6.2 解决分割
MGR 可以通过强制执行特定配置来重置组成员关系列表。比如 5 个成员的组,3 个成员出现问题,则可以强制为剩下两个成员配置一致的组成员关系。大致操作步骤如下:
首先检查剩下两个未出问题成员的组通信标识符,分别登录两个节点执行下面的语句:
1 | mysql> SELECT @@group_replication_local_address; |
获取到剩下两个成员的组通信标识符之后,就可以在两个服务器中的一台上使用下面语句注入新的成员配置,从而覆盖已经丢失法定人数的现有成员配置。
注意:
在强制执行新的成员配置之前,务必确保要排除的服务器确实已经关闭,否则可能造成人为脑裂情况。
具体语句如下:
1 | mysql> SET GLOBAL group_replication_force_members="node1:33061,node2:33061,node3:33061"; |
执行完之后,检查两个成员的 replication_group_members 表:
1 | mysql> SELECT MEMBER_ID,MEMBER_STATE FROM performance_schema.replication_group_members; |
看是否只剩下这两个成员,并且确定 MEMBER_STATE 是否都为 ONLINE。
7. Orch
7.1 架构介绍
7.1.1 Orch自身高可用集群架构
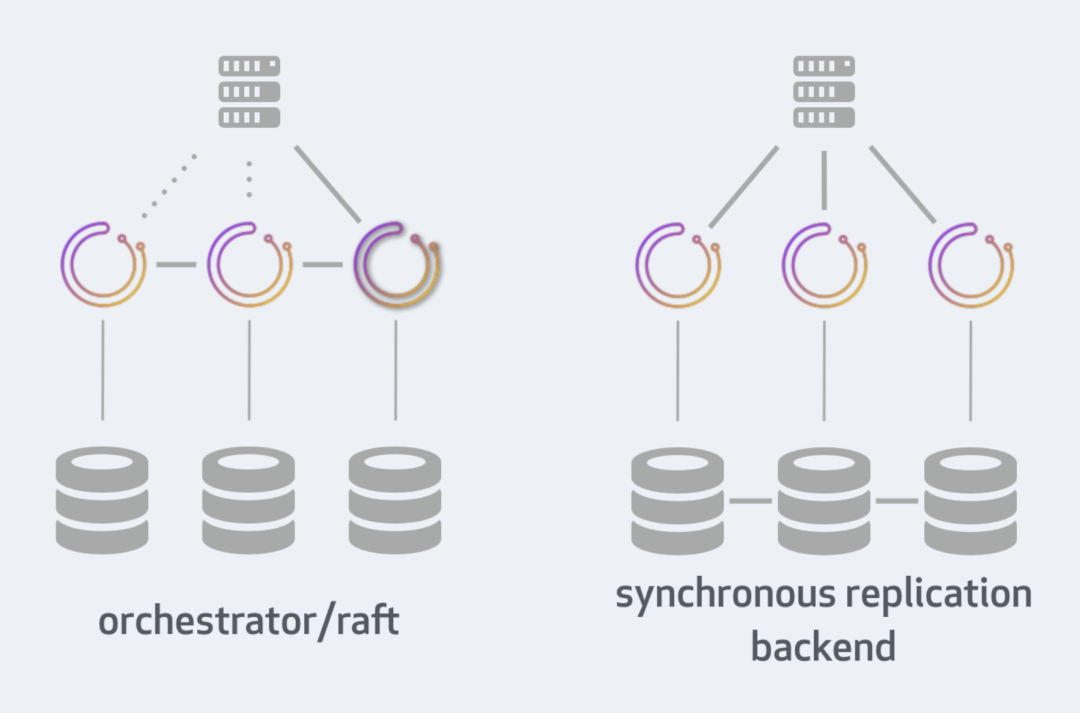
Orch自身的高可用可以通过两种方式实现:
- Orch/Raft(架构如上图左):通过Raft一致性协议进行互相通讯;
- 通过后端高可用组件来保证数据同步(架构如上图右):比如 Galera、XtraDB Cluster、InnoDB Cluster、NDB Cluster。
这一节内容,就采用Orch/Raft方案。在这种方案中,每一个Orch实例都需要一套单独的后端MySQL(当然,也可以是SQLite,这篇文章只讲后端数据库是MySQL的场景)。
7.1.2 Orch实现MySQL故障切换实验的架构介绍
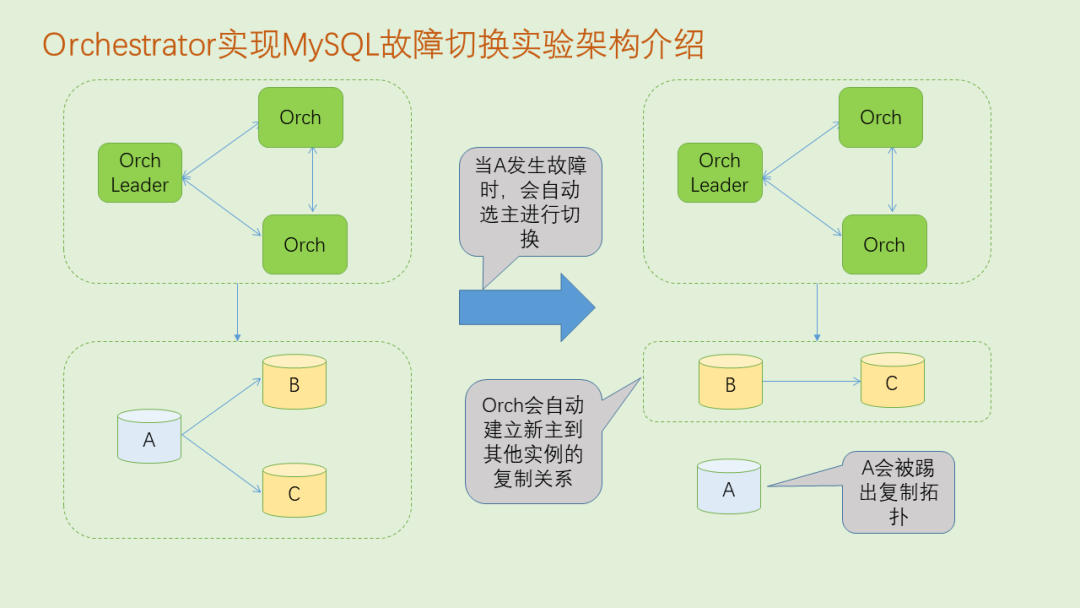
Orch负责监听MySQL一主两从架构中三个MySQL实例(A、B和C)的状态,当A发生故障时,Orch会自动从B和C中选择一个新主进行切换,假设B为新主,Orch会自动创建B到C的复制关系,旧主会被踢出复制拓扑(如果旧主需要重新加入拓扑,需要手动与B或者C建立复制关系)。
在切换之后,如果为了客户端能正常找到新主,可能会涉及到VIP修改、DNS修改等操作,可以放在PostFailoverProcesses的Hook中。关于Hook的用法,后面有机会再写一篇。
当然,如果生产环境考虑使用Orch,可以使用一套Orch集群,管理上百套MySQL拓扑,类似Redis Sentinel管理多套Redis主从。
另外,被管理的MySQL拓扑只有主从也行,这篇文章选择一主两从是为了验证其他从是否会自动接到新主下进行复制。
7.1.3 实验环境
Orch集群环境:
| 作用 | IP:Port | Orch的后端数据库 |
|---|---|---|
| Orch Leader | 192.168.21.11:3000 | 192.168.21.11:3306 |
| Orch | 192.168.21.14:3000 | 192.168.21.14:3306 |
| Orch | 192.168.21.28:3000 | 192.168.21.28:3306 |
用户测试高可用的MySQL一主两从环境:
| 作用 | IP:Port |
|---|---|
| MySQL 服务 A | 192.168.21.11:3307 |
| MySQL 服务 B | 192.168.21.14:3307 |
| MySQL 服务 C | 192.168.21.28:3307 |
配置主为A,从为B和C的一主两从环境,这个环境可自行部署,这篇文章就不赘述了。
7.2 安装和配置Orch
在三台Orch机器上执行
7.2.1 获取Orch安装包
1 | wget https://github.com/openark/orchestrator/releases/download/v3.2.6/orchestrator-3.2.6-1.x86_64.rpm |
7.2.2 安装Orch
1 | yum install orchestrator-3.2.6-1.x86_64.rpm |
7.2.3 配置数据库
在前面我们也讲到,每个Orch实例都需要准备一套单独的MySQL来存放Orch的元数据。
在这每一套Orch数据库中创建Orch用户:
1 | CREATE USER 'orc_server_user'@'127.0.0.1' IDENTIFIED BY 'BdgwetY123'; |
7.2.4 配置Orch
1 | cd /usr/local/orchestratormkdir -p {log,conf,raftdata}cp orchestrator-sample.conf.json ./conf/orchestrator.conf.json |
编辑配置文件./conf/orchestrator.conf.json,修改如下参数:
1 | ...... |
参数解释:
- MySQLTopologyUser:拓扑发现用户;
- MySQLTopologyPassword:拓扑发现密码;
- MySQLOrchestratorHost:Orch后端数据库地址;
- MySQLOrchestratorPort:Orch后端数据库端口;
- MySQLOrchestratorDatabase:Orch后端数据库;
- MySQLOrchestratorUser:Orch后端数据库用户;
- MySQLOrchestratorPassword:Orch后端数据库密码;
- AuthenticationMethod:认证方式,如果开启,页面、命令行、API都需要通过用户密码才能访问;
- HTTPAuthUser:认证用户;
- HTTPAuthPassword:认证密码;
- RaftEnabled:开启Raft集群模式;
- RaftDataDir:Raft集群工作目录,存放临时数据;
- RaftBind:Raft集群监听IP地址,这里填写本机IP,注意,三个节点只有这个位置配置不一样;
- DefaultRaftPort:Raft集群监听端口;
- RaftNodes:所有Orch节点的IP;
- RecoveryPeriodBlockSeconds:该时间内再次发生故障,不会再次转移;
- RecoveryIgnoreHostnameFilters:恢复会忽略的主机;
- RecoverMasterClusterFilters:只在匹配这些正则表达式模式的集群上进行主恢复,“*”表示所有集群都能恢复;
- RecoverIntermediateMasterClusterFilters:仅在与这些正则表达式模式匹配的集群上进行IM恢复,“*”表示所有都能恢复。
7.3 将测试高可用的MySQL配置到Orch中
7.3.1 在测试高可用的MySQL中创建Orch连接用户
1 | create user 'orc_client_user'@'192.168.21.%' identified by 'iqadgurad1q8'; |
7.3.2 启动 Orch
如果三个Orch节点之间有防火墙限制,则需要互相开放10008和3000端口。
1 | cd /usr/local/orchestrator./orchestrator -config ./conf/orchestrator.conf.json http >> ./log/orchestrator.log 2>&1 & |
7.3.3 在页面查看Orch集群信息
登录页面:Orch IP:3000
会进入到如下界面,
输入下面两行配置的用户和密码就可以登录
“HTTPAuthUser”: “admin”,
“HTTPAuthPassword”: “uq81sgca1da”,
点击 Home –> Status
可以看到 Orch 集群信息
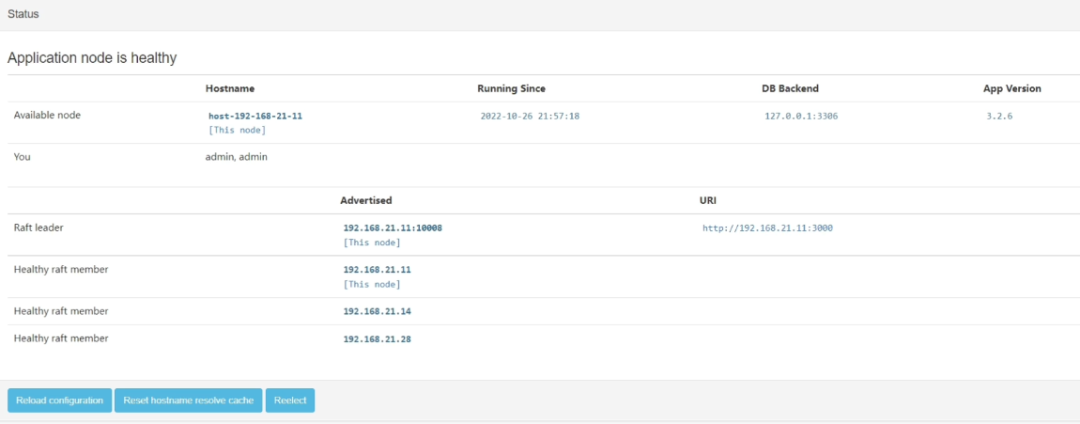
根据上面的信息,登录到leader节点,后面的操作都是在leader节点执行的。
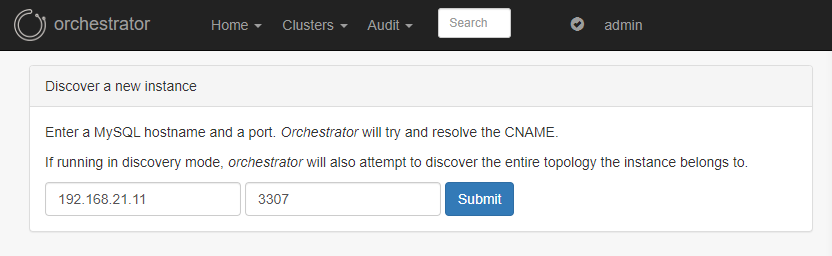
7.3.4 将业务MySQL添加到Orch中
Cluster–>Discover,添加主的IP和端口,只要DiscoverByShowSlaveHosts参数设置为true,则可以自动发现这个主实例下面的所有从实例。
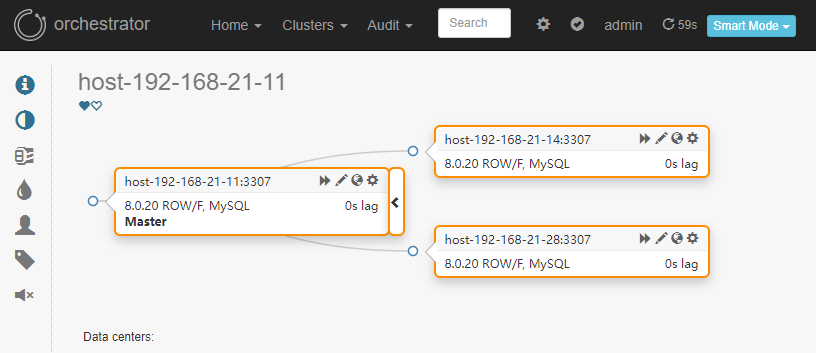
7.3.5 查看拓扑集群
Cluster–>Dashboard
7.4 测试高可用
把刚才新增拓扑的Master节点(也就是172.168.21.11:3307)关闭
再次查看拓扑,变成了
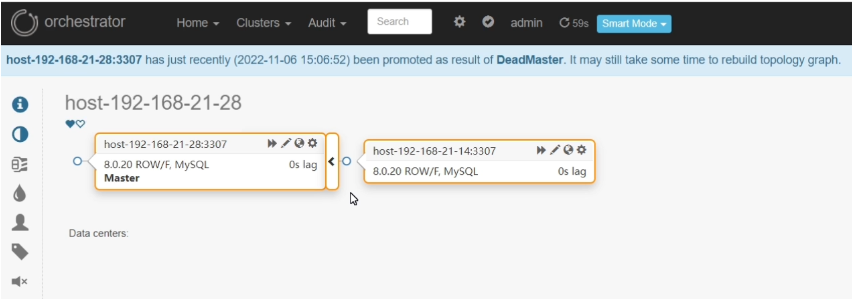
其中,192.168.21.28:3307变成了主,192.168.21.14:3307之前接在192.168.21.11:3307后面,现在接在192.168.21.28:3307后面了。
也就是Orch除了实现自动切换,也会把其他节点接在新主下复制数据。