1. 主题的概念
Kafka中的消息以主题为单位进行归类,生产者负责将消息发送到特定的主题(发送到 Kafka集群中的每一条消息都要指定一个主题),而消费者负责订阅主题并进行消费。主题是一个逻辑上的概念。
2. 主题管理
主题的管理包括创建主题、 查看主题信息、修改主题和删除主题等操作。
- kafka-topics.sh 脚本
- KafkaAdminClient方式
- 直接操纵日志文件和 ZooKeeper 节点来实现
实质上是在 ZooKeeper中的 /brokers/topics节点下创建与该主题对应的子节点并写入分区副本分配方案, 并且在 /config/topics/节点下创建与该主题对应的子节点并写入主题相关的配置信息。
2.1 创建主题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| # 创建了一个分区数为4、副本因子为2的主题,主题名为topic-create
bin/kafka-topics.sh --zookeeper hadoop101:2181 --create --topic topic-create --partitions 4 --replication-factor 2
# 1、查询节点1创建的主题分区
[root@hadoop101 logs]# ll -ls |grep topic-create
0 drwxr-xr-x. 2 root root 141 Jun 8 23:37 topic-create-0
0 drwxr-xr-x. 2 root root 141 Jun 8 23:37 topic-create-2
0 drwxr-xr-x. 2 root root 141 Jun 8 23:37 topic-create-3
# 2、查询节点2创建的主题分区
[root@hadoop102 logs]# ll -ls |grep topic-create
0 drwxr-xr-x. 2 root root 141 Jun 8 23:37 topic-create-0
0 drwxr-xr-x. 2 root root 141 Jun 8 23:37 topic-create-1
# 3、查询节点3创建的主题分区
[root@hadoop103 logs]# ll -ls |grep topic-create
0 drwxr-xr-x. 2 root root 141 Jun 8 23:37 topic-create-1
0 drwxr-xr-x. 2 root root 141 Jun 8 23:37 topic-create-2
0 drwxr-xr-x. 2 root root 141 Jun 8 23:37 topic-create-3
|
该主题在三个节点一共创建了8(4 * 2)个文件夹,按照3,2,3的分区副本个数分配给各个broker。
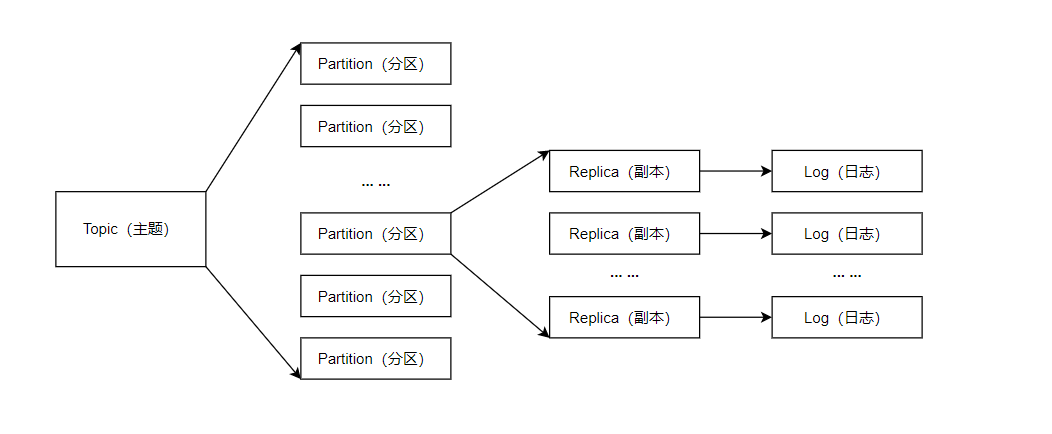
主题、分区、副本和log的关系如下图所示:
2.2 分区副本的分配
kafka-topics.sh 脚本创建主题时的内部分配逻辑按照机架信息划分成两种策略:指定机架信息和未指定机架信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| private def assignReplicasToBrokersRackUnaware(
nPartitions: Int,
replicationFactor: Int,
brokerList: Seq[Int],
fixedStartIndex: Int,
startPartitionId: Int): Map[Int, Seq[Int]] =
{
val ret = mutable.MapInt, Seq[Int]
val brokerArray = brokerList.toArray
val startIndex = if (fixedStartIndex >= 0) fixedStartIndex else rand.nextInt(brokerArray.length)
var currentPartitionId = math.max(0, startPartitionId)
var nextReplicaShift = if (fixedStartIndex >= 0) fixedStartIndex else rand.nextInt(brokerArray.length)
for (_ <- 0 until nPartitions) {
if (currentPartitionId > 0 && (currentPartitionId % brokerArray.length == 0))
nextReplicaShift += 1
val firstReplicaIndex = (currentPartitionId + startIndex) % brokerArray.length
val replicaBuffer = mutable.ArrayBuffer(brokerArray(firstReplicaIndex))
for (j <- 0 until replicationFactor - 1)
replicaBuffer += brokerArray(replicaIndex(firstReplicaIndex, nextReplicaShift, j, brokerArray.length))
ret.put(currentPartitionId, replicaBuffer)
currentPartitionId += 1
}
ret
}
private def replicaIndex(
firstReplicaIndex : Int,
secondReplicaShift : Int,
replicaIndex : Int,
nBrokers : Int) : Int =
{
val shift = 1 + (secondReplicaShift + replicaIndex ) % ( nBrokers - 1 )
(firstReplicaIndex + shift) % nBrokers
}
|
assignReplicasToBrokersRackUnaware() 方法的核心是遍历每个分区 partition , 然后从brokerArray(brokerld 的列表)中选取replicationFactor 个 brokerld分配给这个partition 。
该方法首先创建一个可变的 Map 用来存放该方法将要返回的结果 ,即分区 partition 和分配副本的映射关系 。 由于 fixedStartlndex为 -1 ,所以 startlndex 是一个随机数,用来计算一个起始分配的 brokerId ,同时又因为 startPartitionld 为 -1 , 所以 currentPartitionld 的值为 0,可见默认情况下创建主题时总是从编号为0的分区依次轮询进行分配 。
举例说明:
1
2
3
4
5
6
7
8
9
10
11
12
| # 创建一个6分区3副本的主题
bin/kafka-topics.sh --zookeeper hadoop101:2181 --create --topic topic-test2 --replication-factor 3 --partitions 6
# 查询主题详情
bin/kafka-topics.sh --zookeeper hadoop101:2181 --describe --topic topic-test2
Topic:topic-test2 PartitionCount:6 ReplicationFactor:3 Configs:
Topic: topic-test2 Partition: 0 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
Topic: topic-test2 Partition: 1 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: topic-test2 Partition: 2 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Topic: topic-test2 Partition: 3 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: topic-test2 Partition: 4 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Topic: topic-test2 Partition: 5 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
|
假设目前有三个机架rack1、rack2、rack3,kafka集群中的9个broker节点都部署在这3个机架之上,机架和broker节点的对照关系如下:
| 机架标识 |
节点标识 |
| RACK1 |
0、1、2 |
| RACK2 |
3、4、5 |
| RACK3 |
6、7、8 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| private def assignReplicasToBrokersRackAware(
nPartitions: Int,
replicationFactor: Int,
brokerMetadatas: Seq[BrokerMetadata],
fixedStartIndex: Int,
startPartitionId: Int): Map[Int, Seq[Int]] =
{
val brokerRackMap = brokerMetadatas.collect {
case BrokerMetadata(id, Some(rack)) => id -> rack
}.toMap
val numRacks = brokerRackMap.values.toSet.size
val arrangedBrokerList = getRackAlternatedBrokerList(brokerRackMap)
val numBrokers = arrangedBrokerList.size
val ret = mutable.Map[Int, Seq[Int]]()
val startIndex = if (fixedStartIndex >= 0) fixedStartIndex else rand.nextInt(arrangedBrokerList.size)
var currentPartitionId = math.max(0, startPartitionId)
var nextReplicaShift = if (fixedStartIndex >= 0) fixedStartIndex else rand.nextInt(arrangedBrokerList.size)
for (_ <- 0 until nPartitions) {
if (currentPartitionId > 0 && (currentPartitionId % arrangedBrokerList.size == 0))
nextReplicaShift += 1
val firstReplicaIndex = (currentPartitionId + startIndex) % arrangedBrokerList.size
val leader = arrangedBrokerList(firstReplicaIndex)
val replicaBuffer = mutable.ArrayBuffer(leader)
val racksWithReplicas = mutable.Set(brokerRackMap(leader))
val brokersWithReplicas = mutable.Set(leader)
var k = 0
for (_ <- 0 until replicationFactor - 1) {
var done = false
while (!done) {
val broker = arrangedBrokerList(replicaIndex(firstReplicaIndex, nextReplicaShift * numRacks, k, arrangedBrokerList.size))
val rack = brokerRackMap(broker)
if ((!racksWithReplicas.contains(rack) || racksWithReplicas.size == numRacks) && (!brokersWithReplicas.contains(broker) || brokersWithReplicas.size == numBrokers)) {
replicaBuffer += broker
racksWithReplicas += rack
brokersWithReplicas += broker
done = true
}
k += 1
}
}
ret.put(currentPartitionId, replicaBuffer)
currentPartitionId += 1
}
ret
}
private def replicaIndex(
firstReplicaIndex : Int,
secondReplicaShift : Int,
replicaIndex : Int, nBrokers : Int) : Int =
{
val shift = 1 + (secondReplicaShift + replicaIndex ) % ( nBrokers - 1 )
(firstReplicaIndex + shift) % nBrokers
}
|
当创建一个主题时,无论是通过kafka-topic.sh脚本,还是通过其他方式创建主题;实质是在zk中的/brokers/topics节点下创建与该主题对应的子节点并写入分区副本分配方案,并且在/config/topics/节点下创建与该主题对应的子节点并写入主题相关的配置信息(这个步骤可以省略不执行)。而kafka创建主题的实行动作是交由控制器异步去完成的。
知道了kafka-topic脚本的实质后,我们可以直接使用zk的客户端在/broker/topics节点下创建响应的主题节点 并写入预先设定好的分配方案,这样就可以创建一个新的主题了。而且这种方式还可以绕过一些原本使用kafka-topic.sh创建主题时的一些限制,比如分区的序号可以不用从0开始连续累加。
1
2
3
4
5
6
7
8
9
| # zk创建节点
create /brokers/topics/topic-create-zk {"version":1,"partitions":{"2":[1,2],"1":[0,1],"3":[2,1],"0":[2,0]}}
# 查询主题详情
bin/kafka-topics.sh --zookeeper hadoop101:2181 --describe --topic topic-create-zk
Topic:topic-create-zk PartitionCount:4 ReplicationFactor:2 Configs:
Topic: topic-create-zk Partition: 0 Leader: 2 Replicas: 2,0 Isr: 2,0
Topic: topic-create-zk Partition: 1 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: topic-create-zk Partition: 2 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: topic-create-zk Partition: 3 Leader: 2 Replicas: 2,1 Isr: 2,1
|
2.3 查看主题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # list 查看所有主题
bin/kafka-topics.sh --zookeeper hadoop101:2181 --list
# describe 查看主题详细信息
bin/kafka-topics.sh --zookeeper hadoop101:2181 --describe --topic topic-create,topic-demo
# topics-with-overrides 找出所有包含覆盖配置的主题
bin/kafka-topics.sh --zookeeper hadoop101:2181 --describe --topics-with-overrides
# under-replicated-partitions 找出所有包含失效副本的分区;包含失效副本的分区肯能正在进行同步操作,也有可能同步发生异常,此时分区的ISR集合小于AR集合
bin/kafka-topics.sh --zookeeper hadoop101:2181 --describe --topic topic-create --under-replicated-partitions
# unavailable-partitions 查看主题中没有leader副本的分区,这些副本已经处于离线状态,对于外界的生产者和消费者来说处于不可用的状态
bin/kafka-topics.sh --zookeeper hadoop101:2181 --describe --topic topic-create --unavailable-partitions
|
2.4 修改主题
1
2
3
4
5
6
| # alter 增加分区
bin/kafka-topics.sh --zookeeper hadoop101:2181 --alter --topic topic-config --partitions 3
# 查看主题详情
bin/kafka-topics.sh --zookeeper hadoop101:2181 --describe --topic topic-config
# alter 减少分区;目前kafka只支持增加分区数而不支持减少分区数
|
2.5 删除主题
1
2
3
4
5
6
7
8
9
10
11
12
| # 1. 常规删除 topicConfig.sh ;delete.topic.enable配置为true才可以删除成功
bin/kafka-topics.sh --zookeeper hadoop101:2181 --delete --topic topic-delete
# 2. 手动删除
# 2.1 删除zk中的节点/config/topics/topic-delete
rmr /config/topics/topic-delete
# 2.2 删除zk中的节点/brokers/topics/topic-delete
delete /brokers/topics/topic-delete
# 2.3 删除集群中所有与主题topic-delete有关的文件
rm -rf /tmp/kafka-logs/topic-delete*
|