
1. 协议设计
2. 时间轮
使用场景:kafka中存在大量延时操作,比如延时生产、延时拉取和延时删除等。
选型对比:jdk自带的Timer或DeplayQueue(删除、插入操作的平均时间复杂度O(nlogn));时间轮算法O(1);
实现方式:
时间轮(TimingWheel)使用一个存储定时任务的环形队列,底层采用数组实现,数组中每隔元素可以存放一个定时任务列表(TimerTaskList);TimerList是一个环形的双向链表,链表中的每一项表示的都是定时任务项(TimerTaskEntry),其中封装了真正的定时任务。
时间轮由多个时间格组成,每个时间格代表当前时间轮的基本时间跨度。时间轮的时间格个数是度定的,可用wheelSize来表示,那么整个时间轮的总体时间跨度可以通过公式tickMs*wheelSize计算得出。时间轮还有一个表盘指针,用来表示时间轮当前所处的时间,currentTime是tickMs的整数倍。currentTime可以整个时间轮划分为到期部分和未到期部分,currentTime当前指向的时间格也属于到期部分,表示刚好到期,需要处理此事件格所对应的TimerTaskList中所有任务。
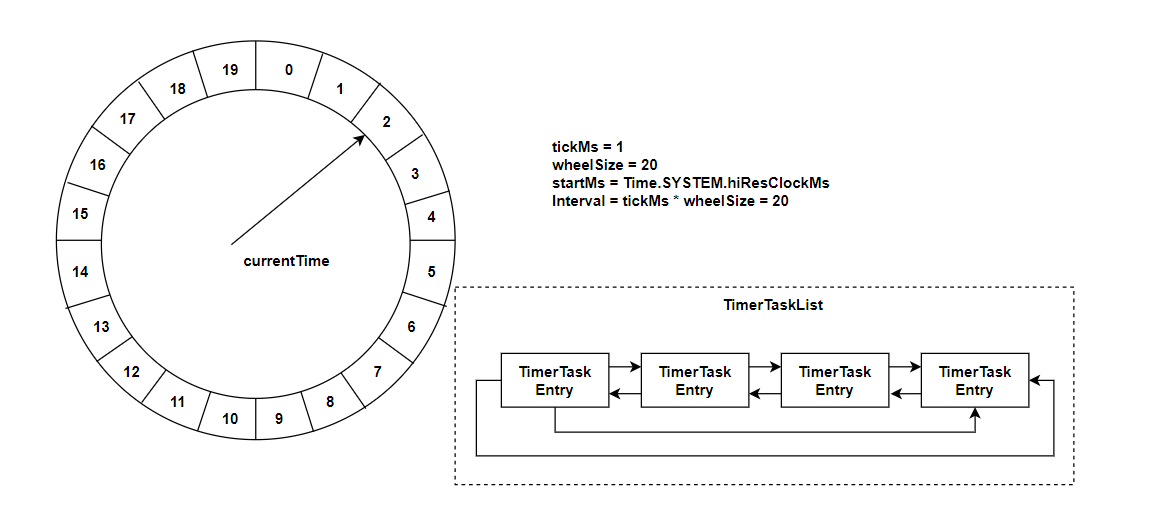
若时间轮的tickMs为1ms且wheelSize等于20,那么可以计算得出总体时间跨度interval为20ms。初始情况下表盘指针currentTime指向时间格0,此时有一个定时为2ms的任务插进来会存放到时间格为2的TimerList中。随着时间不断推移,指针currentTime不断向前推进,过了2ms之后,当到达时间格2时,就需要将时间格2对应的TimerTaskList中的任务进行相应的到期操作。此时若有一个定时为8ms的任务插入进来,则会存放到时间格10中,current Time再过8ms后会指向时间格10。如果同时有一个定时为19ms的任务插进来怎么办?新来的TimerTaskEntry会复用原来的TimerTaskList,所以它会插入原本已经到期的时间格1。总之,整个时间轮的总体跨度是不变化的,随着指针currentTime的不断推进,当前时间轮所能处理的时间段也在不断后移,总体时间范围在current Time和current Time + interval之间。
此时有一个定时为350ms的任务该如何处理?直接扩充wheelSize的大小?Kafka中不乏几万甚至几十万毫秒的定时任务,这个wheelSize的扩充没有底线,就算将所有的定时任务的到期时间都设定一个上限,比如100万毫秒,那么这个wheelSize为100万毫秒的时间轮不仅占用很大的内存空间,而且也会拉低效率。kafka为此引入了层级时间轮的概念,当任务的到期时间超过了当前时间轮所表示的时间范围时,就会尝试添加到上层时间轮中。
多层时间轮举例说明:
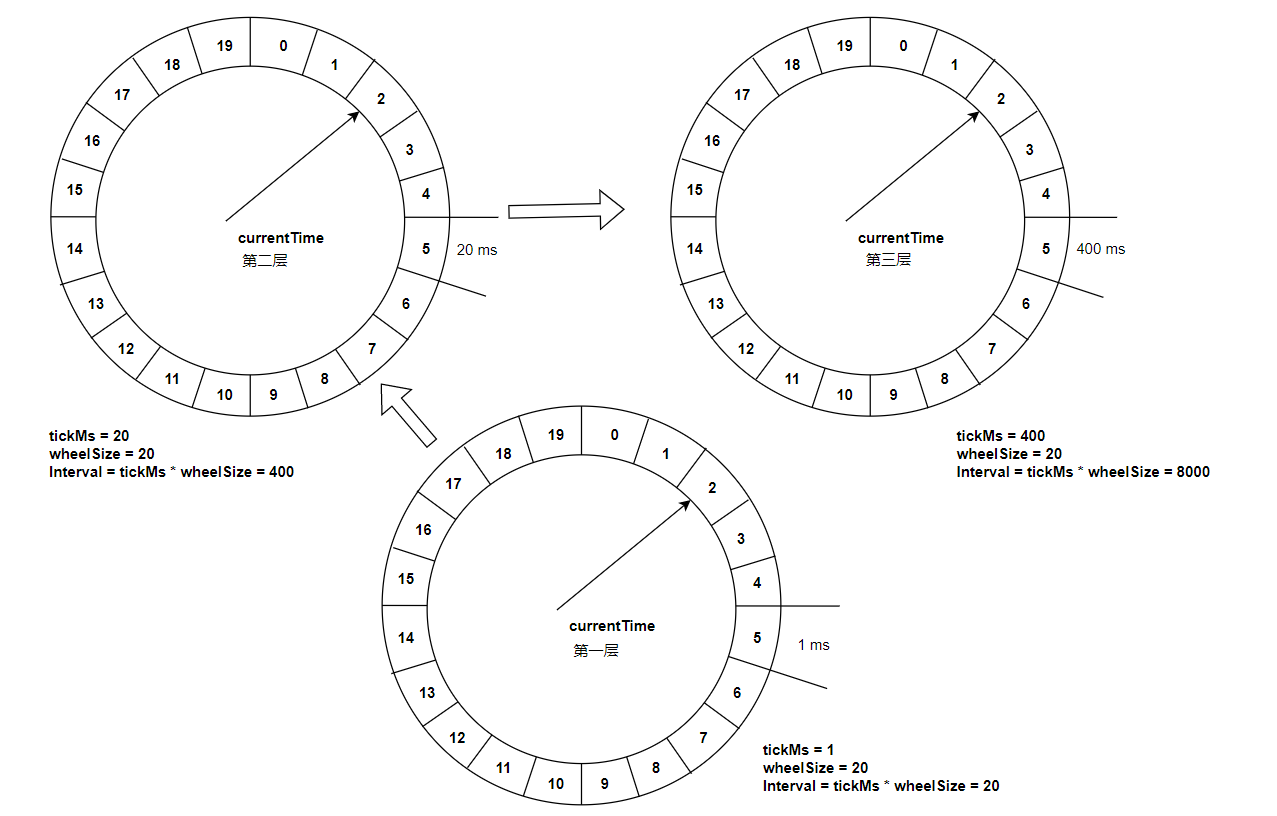
kafka在具体时间轮TimingWheel时还有一些小细节:
- TimingWheel 在创建的时候以当前系统时间为第一层时间轮的起始时间(startMs),这里的当前系统时间并没有简单地调用System.currentTimeMills(),而是调用了Time.SYSTEM.hiResClockMs,这是因为currentTimeMills()方法的时间精度依赖于操作系统的具体实现,有些操作系统下并不能达到毫秒级别精度,而Time.SYSTEM.hiResClockMs实质上采用了System.nanoTime/1_000_000来将精度调整到毫秒级别。
- TimingWheel中每个双向环形链表TimerTaskList都会有一个哨兵节点,引入哨兵节点可以简化便捷条件。哨兵节点也称为哑元节点,它是一个附加的链表节点,该节点作为第一个节点,它的值域中并不存储任何东西,只是为了操作的方便而引入的。如果一个链表有哨兵节点,那么线性表的第一个元素应该是链表的第二个节点。
- 除了第一层时间轮,其余高层时间轮的起始时间都设置为创建此层时间轮时前面第一层的currentTime。每一层currentTime都必须是tickMs的整数倍,如果不满足则会将currentTime修剪为tickMs整数倍,以此与时间轮中的时间格的到期时间范围对应起来。修剪方法为: currentTime = startMs - (startMs % tickMs) 。currentTime 会随着时间推移而推进, 但不会改变为tickMs 的整数倍的既定事实。 若某一 时刻的时间为timeMs, 那么此时时间轮的currentTime = timeMs - (timeMs % tickMs), 时间每推进一次, 每个层级的时间轮的currentTime都会依据此公式执行推进。
- Kafka中的定时器只需待有TimingWheel 的第一层时间轮的引用, 并不会直接持有其他高层的时间轮, 但每一层时间轮都会有一 个引用(overflowWheel)指向更高一层的应用, 以此层级调用可以实现定时器间接持有各个层级时间轮的引用。
随着时间的流逝或者随着时间的推移,在kafka中到底是怎么推进时间的呢?
kafka中定时器借了JDK中的DeplayQueue来协助推进时间轮。具体做法是对于每个使用到的TimerTaskList都加入DeplayQueue,“每个用到的TimerTaskList”特指非哨兵节点的定时任务项TimerTaskEntry对应的TimerTaskList。DelayQueue会根据TimerTaskList对应的超时时间expiration来排序,最短expiration的TimerTaskList会被排在DepayQueue的队头。kafka中会有一个线程来获取DepayQueue中到期的任务列表,有意思的是这个线程所对应的名称叫做“ExpiredOperationReaper”,可以直译为“过期操作收割机”。当收割机线程获取DelayQueue中超时的任务列表TimerTaskList之后,既可以根据TimerTaskList的expiration来推进时间轮的时间,也可以就获取的TimerTaskList执行相应的的操作,对立面的TimerEntry该执行过期操作的就执行过期操作,该降级时间的就降级时间轮。
读到这里或许会感到困惑,开头明确指明的DelayQueue 不适合Kafka这种高性能要求的定时任务为何这里还要引入DelayQueue呢?注意对定时任务项TimerTaskEntry的插入和删除操作而言,TimingWheel 时间复杂度为0(1),性能高出DelayQueue很多,如果直接将TimerTaskEntry插入DelayQueue, 那么性能显然难以支撑。就算我们根据一 定的规则将若干TimerTaskEntry划分到TimerTaskList这个组中, 然后将TimerTaskList 插入DelayQueue, 如果在TimerTaskList中又要多添加一个TimerTaskEntry时该如何处理呢?对DelayQueue 而言 ,这类操作显然变得力不从心。
分析到这里可以发现,Kafka中的TimingWheel专门用来执行插入和删除TimerTaskEntry的操作, 而 DelayQueue专门负责时间推进的任务。试想一下, DelayQueue中的第一个超时任务列表的expiration 为200ms, 第二个超时任务为840ms, 这里获取DelayQueue 的队头只需要0(1)的时间复杂度(获取之后DelayQueue 内部才会再次切换出新的队头)。如果采用每秒定时推进, 那么获取第一个超时的任务列表时执行的200 次推进中有199次属于 “空推进” , 而获取第二个超时任务时又需要执行639次 “空推进” , 这样会无故空耗机器的性能资源,这里采用DelayQueue 来辅助以少量空间换时间, 从而做到了“精准推进” 。Kaflca中的定时器真可谓“知人善用” ,用TimingWheel做最擅长的任务添加和删除操作, 而用DelayQueue做最擅长的时间推进工作, 两者相辅相成。
3. 延时操作
在kafka中有多种延时操作,比如延时生产、延时拉取、延时数据删除等。延时操作需要返回响应的结果,首先它必须有一个超时时间,如果在这个超时时间内没有完成既定的任务,那么就需要强制完成以返回响应结果给客户端。其次,延时操作不同于定时操作,定时操作是指在塔顶时间之后执行的操作,而延时操作可以在所设定的超时时间之前完成,所以延时操作能够支持外部事件触发。就延时生产操作而言,它的外部事件是所要写入消息的某个分区的HW发生增长。也就是说,随着follower副本不断地与leader副本进行消息同步,进而促使HW进一步增长,HW每增长一次都会检测是否能够完成此次延时生产操作,如果可以就执行以此返回响应结果给客户端;如果在超时时间内始终无法完成,则强制执行。
4. 控制器
在kafka集群中会有一个或多个broker,其中有一个broker会被选举为控制器,它负责管理整个集群中所有分区和副本的状态。当某个分区的leader副本出现故障时,由控制器负责为该分区选举新的leader副本。当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有broker更新其元数据信息。当使用kafka-topics.sh脚本为某个topic增减分区数量时,同样还是由控制器负责分区的重新分配。
4.1 控制器的选举及异常恢复
Kafka中的控制器选举工作依赖于ZooKeeper, 成功竞选为控制器的broker会在ZooKeeper 中创建/controller这个临时(EPHEMERAL)节点, 此临时节点的内容参考如下:
其中version在目前版本中固定为1,brokerid表示成为控制器的broker的id编号, timestamp表示竞选成为控制器时的时间戳。
在任意时刻,集群中有且仅有一个控制器。每个broker启动的时候会去尝试读取/controller节点的brokerid的值,,如果读取到brokerid的值不为-1,则表示已经有其 他broker 节点成功竞选为控制器, 所以当前broker就会放弃竞选;如果ZooKeeper中不存在 /controller节点, 或者这个节点中的数据异常, 那么就会尝试去创建/controller节点。 当前broker去创建节点的时候, 也有可能其他broker同时去尝试创建这个节点, 只有创建成功的那个broker才会成为控制器, 而创建失败的broker竞选失败。每个broker都会在内存中保存当前控制器的brokerid值, 这个值可以标识为activeController。
ZooKeeper 中还有一个与控制器有关的/controller_epoch节点, 这个节点是待久(PERSISTENT)节点, 节点中存放的是一个整型的controller_epoch值。controller_epoch用于记录控制器发生变更的次数, 即记录当前的控制器是第几代控制器, 我们也可以称之为“控制器的纪元”。
controller_epoch的初始值为1, 即集群中第一个控制器的纪元为1, 当控制器发生变更时,每选出一个新的控制器就将该字段值加1。每个和控制器交互的请求都会携带controller_epoch这个字段,如果请求的controller_epoch值小于内存中的controller_epoch值, 则认为这个请求是向已经过期的控制器所发送的请求, 那么这个请求会被 认定为无效的请求 。 如果请求的controller_epoch值小于内存中的controller_epoch值, 那么说明已经有新的控制器当选了。 由此可见, Kafka通过controller_epoch来保证控制器的唯一性, 进而保证相关操作的一致性。
具备控制器身份的broker需要比其他普通的broker多一分职责,如下:
- 监听分区相关的变化
- 监听主题相关的变化
- 监听broker相关的变化
- 从zookeeper中读取获取当前所有与主题、分区及broker有关的信息并进行相应的管理
- 启动并管理分区状态机和副本状态机
- 更新集群的额元数据信息
- 如果参数auto.leader.rebalance.enable设置为true,则还会开启一个名为“auto-leader-rebalance-task”的定时任务来负责维护分区的优先副本的均衡。
控制器在选举成功后读取zookeeper中各个节点的数据来初始化上下文信息,并且需要管理这些上下文信息。 比如为某个主题增加了若干分区, 控制器在负责创建这些分区的同时要更新上下文信息, 并且需要将这些变更信息同步到其他普通的broker节点中。不管是监听器触发的事件, 还是定时任务触发的事件, 或者是其他事件都会读取或更新控制器中的上下文信息, 那么这样就会涉及多线程间的同步。 如果单纯使用锁机制来实现, 那么整体的性能会 大打折扣。 针对这一现象, Kafka 的控制器使用单线程基于事件队列的模型, 将每个事件都做一层封装, 然后按照事件发生的先后顺序暂存到LinkedBlockingQueue 中 , 最后使用 一 个专用的线程(ControllerEventThread)按照 FIFO (First Input First Output, 先入先出)的原则顺序处理各个事件, 这样不需要锁机制就可以在多线程间维护线程安全。
在 Kafka的早期版本中, 并没有采用 Kafka Controller这样 一个概念来对分区和副本的状态进行管理, 而是依赖于ZooKeeper, 每个 broker都会在ZooKeeper上为分区和副本注册大量的监听器(Watcher)。 当分区 或副本状态变化时, 会唤醒很多不必要的监听器 , 这种严重依赖ZooKeeper 的设计会有脑裂、 羊群效应, 以及造成 ZooKeeper 过载的隐患。 在目前的新版本的设计中, 只有 Kafka Controller 在 ZooKeeper 上注册相应的监听器, 其他的 broker 极少需要再监听 ZooKeeper 中的数据变化, 这样省去了很多不必要的麻烦。 不过每个 broker 还是会对**/controller** 节点添加监听器, 以此来监听此节点的数据变化 (ControllerCbangeHandler) 。
当 /controller 节点的数据发生变化时, 每个 broker 都会更新自身内存中保存的 activeControllerld。 如果 broker 在数据变更前是控制器, 在数据变更后自身的 brokerid 值与新的 activeControllerld 值不一致, 那么就需要 “退位 ” , 关闭相应的资源, 比如关闭状态机、 注销相应的监听器等。 有可能控制器由于异常而下线, 造成**/controller** 这个临时节点被自动删除; 也有可能是其他原因将此节点删除了。
当 /controller 节点被删除时, 每个 broker 都会进行选举, 如果broker 在节点被删除前是控制器, 那么在选举前还需要有一个 “ 退位 ” 的动作。 如果有特殊需要, 则可以手动删除 /controller 节点来触发新一轮的选举。 当然关闭控制器所对应的 broker, 以及手动向 /controller 节点写入新的 brokerid 的所对应的数据, 同样可以触发新一轮的选举。
4.2 优雅关闭
kafka-server-stop.sh
4.3 分区leader的选举
分区leader副本的选举由控制器负责具体实施。当创建分区(创建主题或增加分区都有创建分区的动作) 或分区上线(比如分区中原先的leader副本下线, 此时分区需要选举一个新的leader 上线来对外提供服务)的时候都需要执行 leader 的选举动作, 对应的选举策略为OftlinePartitionLeaderElectionStrategy。这种策略的基本思路是按照AR 集合中副本的顺序查找第一个存活的副本,并且这个副本在JSR集合中。 一个分区的AR集合在分配的时候就被指定, 并且只要不发生重分配的情况,集合内部副本的顺序是保待不变的,而分区的ISR集合中副本的顺序可能会改变。
注意这里是根据AR的顺序而不是ISR的顺序进行选举的 。举个例子,集群中有3个节点: broker0、 broker1和broker2, 在某一时刻具有3个分区且副本因子为3的主题topic-leader的具体信息如下:
此时关闭broker0, 那么对于分区2而言,存活的AR就变为[1,2], 同时ISR变为[2,1]。此时查看主题topic-leader的具体信息(参考如下),分区2的 leader就变为了1而不是2。
leader选举的触发时机:从AR列表中找到第一个存活的副本,且这个副本在目前的ISR列表中
- 当分区进行重分配
- 当发生优选副本的选举
- 当某节点被优雅地关闭