
1. 部署模式
1.1 会话模式Session Mode
先启动一个集群,保持一个会话,在这个会话中通过客户端提交作业。集群启动时所有的资源都已经确定,所以所有提交的作业会竞争集群中的资源
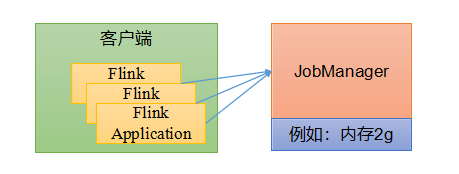
会话模式适合单个规模小,执行时间段的大量作业
1.2 单作业模式Per-Job Mode
会话模式因为资源共享会导致很多问题,所以为了更好地资源隔离,每个提交的作业启动一个集群,这就是所谓的单作业模式。
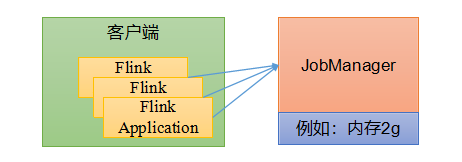
作业完成后,集群就会关闭,所有资源也会释放
这些特性使得但作业模式在生产环境运行更加稳定,实际应用的首选模式注意:flink本身无法直接运行,单作业模式一般需要借助一些资源管理框架yarn、k8s
1.3 应用模式Application Mode
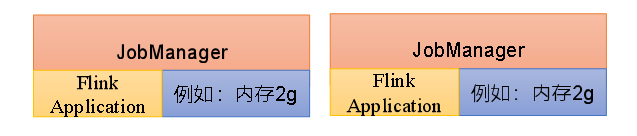
前面提到的两种模式下,应用代码都是在客户端上执行,然后客户端提交给jobmanager。但是这种方式客户端需要占用大量网络带宽,去下载依赖和把二进制数据发送给jobmanager。加上我们提交作业用的是同一个客户端,就会加重客户端所在节点的资源消耗。
所以直接把应用提交到jobmanager,这就表示我们需要每一个提交的应用单独启动一个jobmanaager,就创建一个集群。这个jobmanager只为执行这一个应用而存在,执行结束之后jobmanager也就会关闭了,这就是应用模式。
应用模式与单作业模式,都是提交作业之后才创建集群;单作业模式是通过客户端来提交的,客户端解析出的每一个作业对应一个集群;而在应用模式下,是直接由jobmanager执行应用程序的。
2. 运行模式
2.1 standlone运行模式(了解)
独立模式是独立运行的,不依赖任务外部的资源管理平台;当然也是有代价的,如果资源不足,或者出现故障,没有自动扩展或者重分配资源的保证,必须手动处理。所以一般只在开发、测试或者作业非常少的场景下。
- 运行时架构
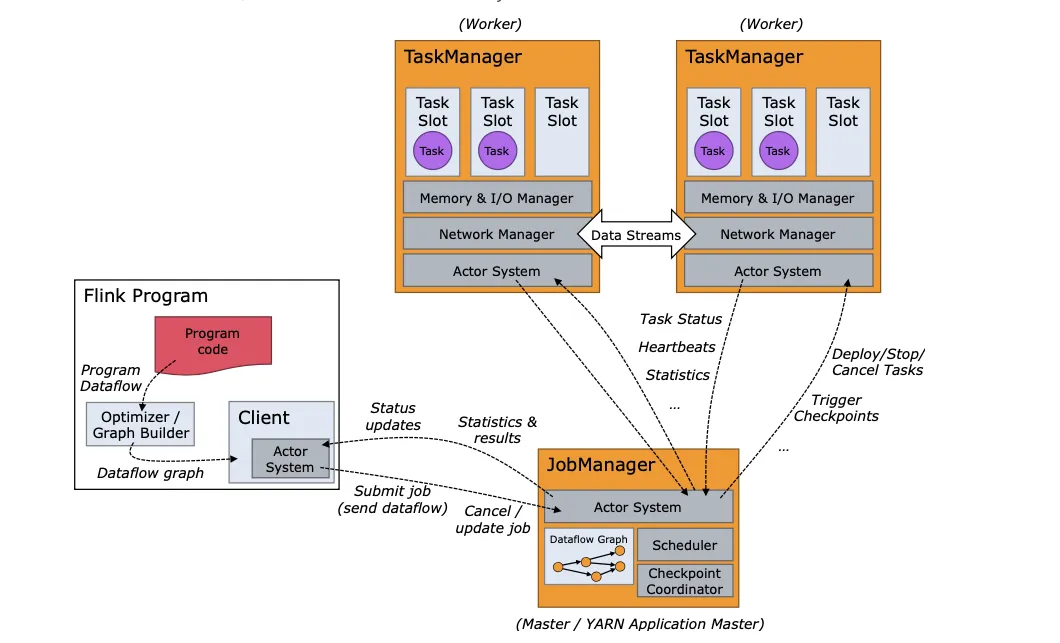
作业提交流程
逻辑流图->作业图->执行图->物理图
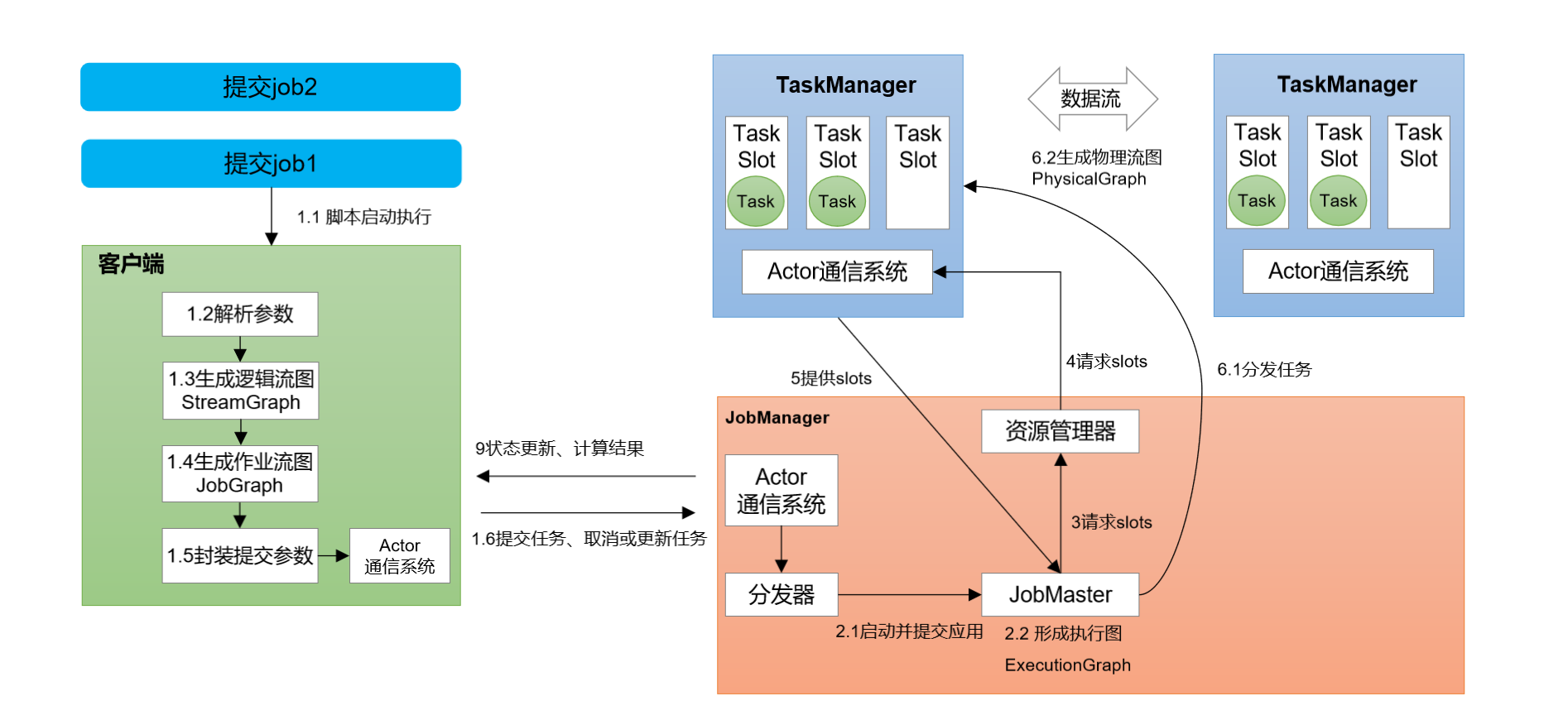
运行模式
会话模式部署
提前启动集群,并通过web页面客户端提交任务(可以提交多个任务,但是集群资源固定)

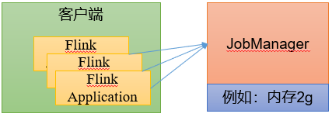
单作业模式(不支持)部署
应用模式部署
应用模式下不会提前创建集群,所以不能调用start-cluster.sh脚本。我们可以使用同样在bin目录下的standalone-job.sh来创建一个JobManager。
这里的使用的环境是新搭建的一个单机版的flink环境。
1)环境准备。
1
[root@spark01 ~]# nc -lk 7777
2)进入到Flink的安装路径下,将应用程序的jar包放到lib/目录下。
1
[root@spark01 flink-1.6.1-standlone]# mv FlinkTutorial-1.0-SNAPSHOT.jar lib/
3)执行以下命令,启动JobManager。
1
[root@spark01 flink-1.6.1-standlone]# bin/standalone-job.sh start --job-classname com.atguigu.wc.StreamWordCount
4)同样是使用bin目录下的脚本,启动TaskManager。
1
[root@spark01 flink-1.6.1-standlone]# bin/taskmanager.sh start
5)在spark01上模拟发送单词数据。
1
2[root@spark01 ~]# nc -lk 7777
hello6)在spark01:8081地址中观察输出数据。
7)果希望停掉集群,同样可以使用脚本,命令如下。
1
2
3
4
5
6
7[root@spark01 flink-1.6.1-standlone]# bin/taskmanager.sh stop
Stopping taskexecutor daemon (pid: 8238) on host spark01.
[root@spark01 flink-1.6.1-standlone]#
[root@spark01 flink-1.6.1-standlone]#
[root@spark01 flink-1.6.1-standlone]#
[root@spark01 flink-1.6.1-standlone]# bin/standalone-job.sh stop
Stopping standalonejob daemon (pid: 7791) on host spark01.

2.2 yarn运行模式(重点)
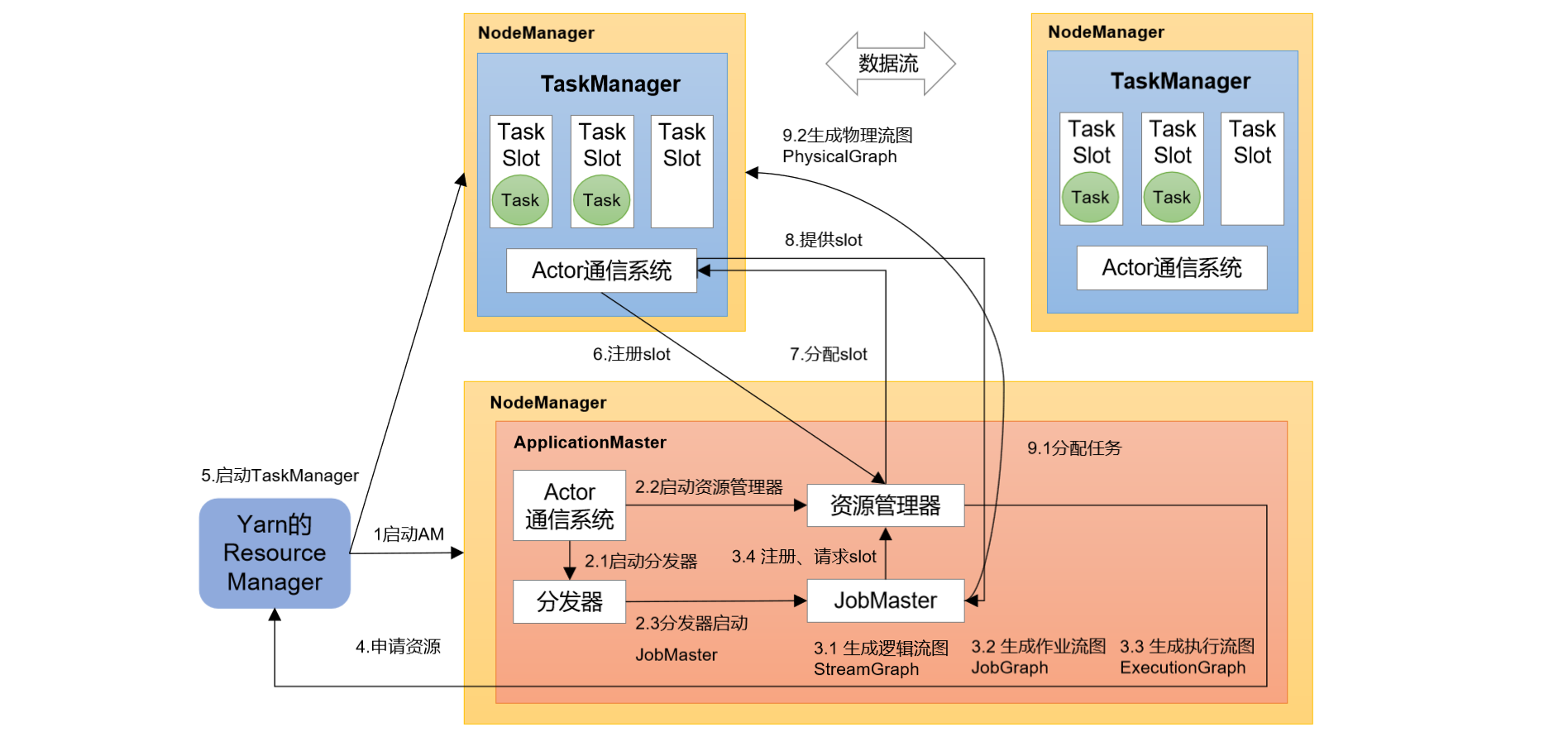
YARN上部署的过程是:客户端把Flink应用提交给Yarn的ResourceManager,Yarn的ResourceManager会向Yarn的NodeManager申请容器。在这些容器上,Flink会部署JobManager和TaskManager的实例,从而启动集群。Flink会根据运行在JobManger上的作业所需要的Slot数量动态分配TaskManager资源。
- 运行时架构
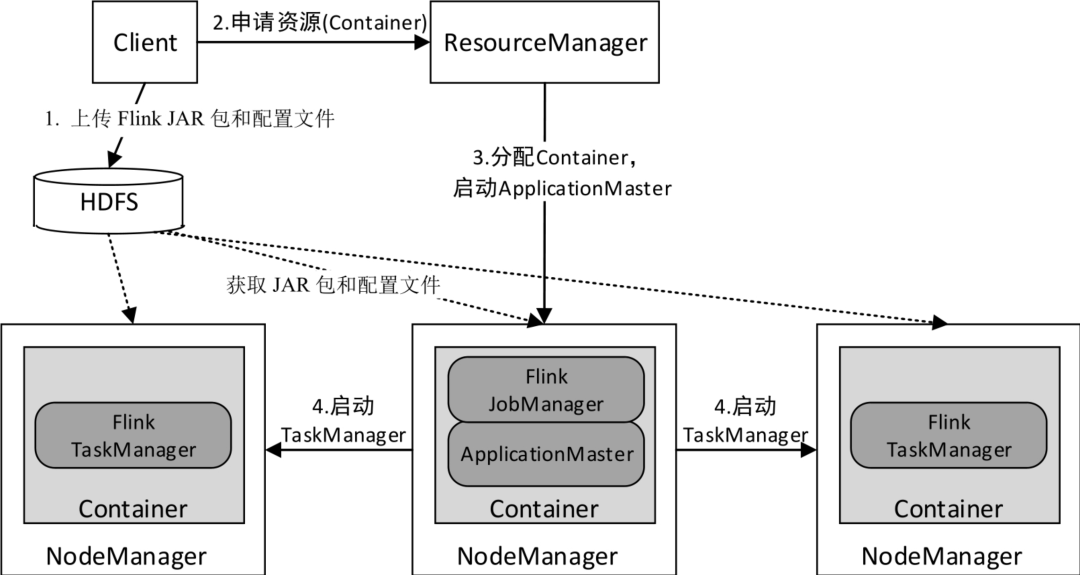
- 作业提交流程
前置准备
在将Flink任务部署至YARN集群之前,需要确认集群是否安装有Hadoop,保证Hadoop版本至少在2.2以上,并且集群中安装有HDFS服务。具体配置步骤如下:
1)配置环境变量,增加环境变量配置如下:
1
2
3
4
5
6##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.2.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`2)启动Hadoop集群,包括HDFS和YARN。
1
[root@spark01 module]# hadoopCluster.sh start
3)在spark01中执行以下命令启动netcat。
1
[root@spark01 ~]# nc -lk 7777
运行模式
会话模式部署
首先申请一个YARN会话(YARN Session)来启动Flink集群。具体步骤如下:
启动集群
1)启动Hadoop集群(HDFS、YARN)。
2)执行脚本命令向YARN集群申请资源,开启一个YARN会话,启动Flink集群。
1
bin/yarn-session.sh -nm test
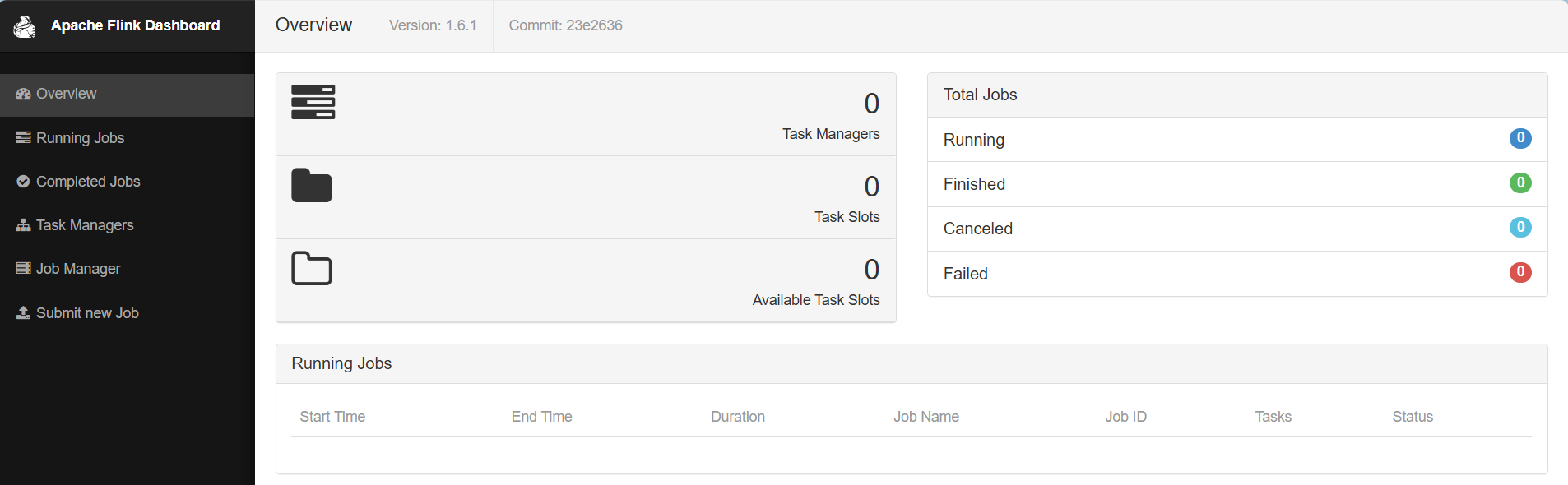
yarn session启动之后会给出一个web ui地址以及一个yarn application id,如下图所示,用户可以通过web ui或者命令行两种方式提交作业。
1
2
32024-07-21 07:28:49,452 INFO org.apache.flink.runtime.rest.RestClient - Rest client endpoint started.
Flink JobManager is now running on spark02:45283 with leader id 00000000-0000-0000-0000-000000000000.
JobManager Web Interface: http://spark02:45283提交作业
1)通过web ui提交作业
2)通过命令行提交作业
①、jar包上传到任务至集群
②、将任务提交到已经开启的yarn-session中运行:
1
[root@spark01 flink-1.6.1]# bin/flink run -c com.atguigu.wc.StreamWordCount /opt/module/flink-1.6.1/lib/FlinkTutorial-1.0-SNAPSHOT.jar
③、yarn ui 界面查询运行情况。
④、flink web ui查询提交任务的运行情况。
单作业模式
在YARN环境中,由于有了外部平台做资源调度,所以我们也可以直接向YARN提交一个单独的作业,从而启动一个Flink集群。
1)执行命令提交作业。
1
[root@spark01 flink-1.6.1]# bin/flink run -d -t yarn-per-job -c com.atguigu.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar
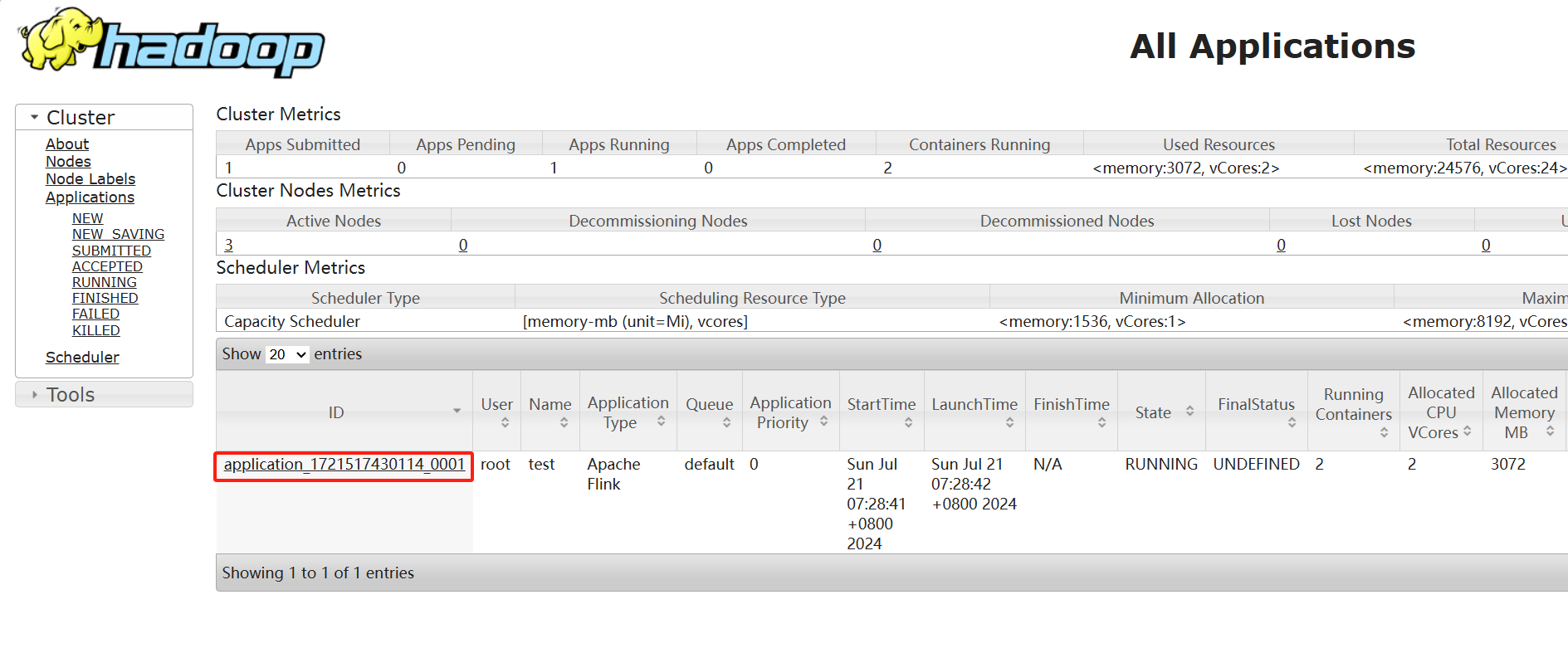
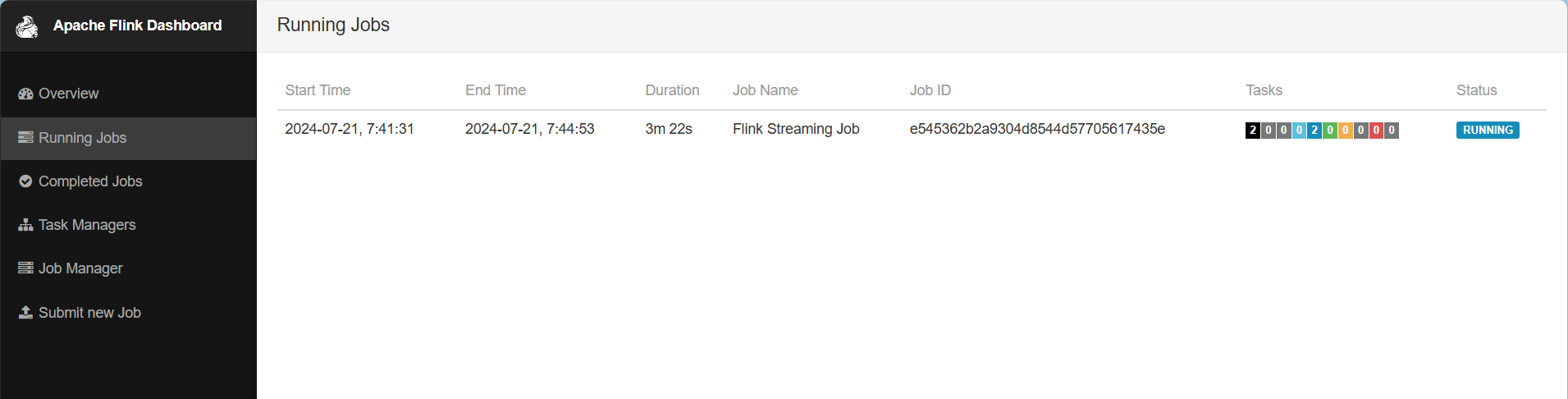
2)在YARN的ResourceManager界面查看执行情况。或者打开flink web ui查看执行情况。
3)可以使用命令行查看或取消作业,命令如下。
1
2[root@spark01 flink-1.6.1]# bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY
[root@spark01 flink-1.6.1]# bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>应用模式
直接执行flink run-application命令即可
1)命令行提交
执行命令提交作业
1
[root@spark01 flink-1.6.1]# bin/flink run-application -t yarn-application -c com.atguigu.wc.SocketStreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar
在命令行中查看或取消作业
1
2[root@spark01 flink-1.6.1]# bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY
[root@spark01 flink-1.6.1]# bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>
2)上传HDFS提交
上传flink的lib和plugins到HDFS上
1
2
3[root@spark01 flink-1.6.1]# hadoop fs -mkdir /flink-dist
[root@spark01 flink-1.6.1]# hadoop fs -put lib/ /flink-dist
[root@spark01 flink-1.6.1]# hadoop fs -put plugins/ /flink-dist上传自己的jar包到HDFS
1
2[root@spark01 flink-1.6.1]# hadoop fs -mkdir /flink-jars
[root@spark01 flink-1.6.1]# hadoop fs -put FlinkTutorial-1.0-SNAPSHOT.jar /flink-jars提交作业
1
[root@spark01 flink-1.6.1]# bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://spark01:8020/flink-dist" -c com.atguigu.wc.StreamWordCount hdfs://spark02:8020/flink-jars/FlinkTutorial-1.0-SNAPSHOT.jar
2.3 k8s
3. 历史服务器
略