1. 执行环境
Flink程序可以在各种上下文环境中运行:我们可以在本地JVM中执行程序,也可以提交到远程集群上运行。
不同的环境,代码的提交运行的过程会有所不同。这就要求我们在提交作业执行计算时,首先必须获取当前Flink的运行环境,从而建立起与Flink框架之间的联系。
1.1 创建执行环境
我们要获取的执行环境,是StreamExecutionEnvironment类的对象,这是所有Flink程序的基础。在代码中创建执行环境的方式,就是调用这个类的静态方法,具体有以下三种。
1)getExecutionEnvironment
最简单的方式,就是直接调用getExecutionEnvironment方法。它会根据当前运行的上下文直接得到正确的结果:如果程序是独立运行的,就返回一个本地执行环境;如果是创建了jar包,然后从命令行调用它并提交到集群执行,那么就返回集群的执行环境。也就是说,这个方法会根据当前运行的方式,自行决定该返回什么样的运行环境。
1
| StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
|
这种方式,用起来简单高效,是最常用的一种创建执行环境的方式。
2)createLocalEnvironment
这个方法返回一个本地执行环境。可以在调用时传入一个参数,指定默认的并行度;如果不传入,则默认并行度就是本地的CPU核心数。
1
| StreamExecutionEnvironment localEnv = StreamExecutionEnvironment.createLocalEnvironment();
|
3)createRemoteEnvironment
这个方法返回集群执行环境。需要在调用时指定JobManager的主机名和端口号,并指定要在集群中运行的Jar包。
1
2
3
4
5
6
| StreamExecutionEnvironment remoteEnv = StreamExecutionEnvironment
.createRemoteEnvironment(
"host",
1234,
"path/to/jarFile.jar"
);
|
在获取到程序执行环境后,我们还可以对执行环境进行灵活的设置。比如可以全局设置程序的并行度、禁用算子链,还可以定义程序的时间语义、配置容错机制。
1.2 设置执行模式
从Flink 1.12开始,官方推荐的做法是直接使用DataStream API,在提交任务时通过将执行模式设为BATCH来进行批处理。不建议使用DataSet API。
1
2
|
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
|
DataStream API执行模式包括:流执行模式、批执行模式和自动模式。
这是DataStream API最经典的模式,一般用于需要持续实时处理的无界数据流。默认情况下,程序使用的就是Streaming执行模式。
专门用于批处理的执行模式。
在这种模式下,将由程序根据输入数据源是否有界,来自动选择执行模式。
批执行模式的使用。主要有两种方式:
(1)通过命令行配置
1
| bin/flink run -Dexecution.runtime-mode=BATCH ...
|
在提交作业时,增加execution.runtime-mode参数,指定值为BATCH。
(2)通过代码配置
1
2
3
| StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
|
在代码中,直接基于执行环境调用setRuntimeMode方法,传入BATCH模式。
实际应用中一般不会在代码中配置,而是使用命令行,这样更加灵活。
1.3 触发程序执行
需要注意的是,写完输出(sink)操作并不代表程序已经结束。因为当main()方法被调用时,其实只是定义了作业的每个执行操作,然后添加到数据流图中;这时并没有真正处理数据——因为数据可能还没来。Flink是由事件驱动的,只有等到数据到来,才会触发真正的计算,这也被称为“延迟执行”或“懒执行”。
所以我们需要显式地调用执行环境的execute()方法,来触发程序执行。execute()方法将一直等待作业完成,然后返回一个执行结果(JobExecutionResult)。
2. 源算子
Flink可以从各种来源获取数据,然后构建DataStream进行转换处理。一般将数据的输入来源称为数据源(data source),而读取数据的算子就是源算子(source operator)。所以,source就是我们整个处理程序的输入端。
在Flink1.12以前,旧的添加source的方式,是调用执行环境的addSource()方法:
1
| DataStream<String> stream = env.addSource(...);
|
方法传入的参数是一个“源函数”(source function),需要实现SourceFunction接口。
从Flink1.12开始,主要使用流批统一的新Source架构:
1
| DataStreamSource<String> stream = env.fromSource(…)
|
Flink直接提供了很多预实现的接口,此外还有很多外部连接工具也帮我们实现了对应的Source,通常情况下足以应对我们的实际需求。
准备工作:
为了方便练习,这里使用WaterSensor作为数据模型。
| 字段名 |
数据类型 |
说明 |
| id |
String |
水位传感器类型 |
| ts |
Long |
传感器记录时间戳 |
| vc |
Integer |
水位记录 |
具体代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| public class WaterSensor {
public String id;
public Long ts;
public Integer vc;
public WaterSensor() {
}
public WaterSensor(String id, Long ts, Integer vc) {
this.id = id;
this.ts = ts;
this.vc = vc;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public Long getTs() {
return ts;
}
public void setTs(Long ts) {
this.ts = ts;
}
public Integer getVc() {
return vc;
}
public void setVc(Integer vc) {
this.vc = vc;
}
@Override
public String toString() {
return "WaterSensor{" +
"id='" + id + '\'' +
", ts=" + ts +
", vc=" + vc +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
WaterSensor that = (WaterSensor) o;
return Objects.equals(id, that.id) &&
Objects.equals(ts, that.ts) &&
Objects.equals(vc, that.vc);
}
@Override
public int hashCode() {
return Objects.hash(id, ts, vc);
}
}
|
这里需要注意,我们定义的WaterSensor,有这样几个特点:
类是公有(public)的
有一个无参的构造方法
所有属性都是公有(public)的
所有属性的类型都是可以序列化的
Flink会把这样的类作为一种特殊的POJO(Plain Ordinary Java Object简单的Java对象,实际就是普通JavaBeans)数据类型来对待,方便数据的解析和序列化。另外我们在类中还重写了toString方法,主要是为了测试输出显示更清晰。
2.1 从集合中读取数据
1
2
3
4
5
6
7
8
9
10
11
12
| public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
List<Integer> data = Arrays.asList(1, 22, 3);
DataStreamSource<Integer> ds = env.fromCollection(data);
stream.print();
env.execute();
}
|
2.2 从文件中读取数据
1
2
3
4
5
| <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
|
1
2
3
4
5
6
7
8
9
10
11
| public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
FileSource<String> fileSource = FileSource.forRecordStreamFormat(new TextLineInputFormat(), new Path("input/word.txt")).build();
env.fromSource(fileSource,WatermarkStrategy.noWatermarks(),"file")
.print();
env.execute();
}
|
说明:
2.3 从socket中读取数据
1
| DataStream<String> stream = env.socketTextStream("localhost", 7777);
|
2.4 从kafka中读取数据
1
2
3
4
5
| <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public class SourceKafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers("hadoop102:9092")
.setTopics("topic_1")
.setGroupId("atguigu")
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> stream = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafka-source");
stream.print("Kafka");
env.execute();
}
}
|
2.5 从数据生成器中读取数据
1
2
3
4
5
| <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-datagen</artifactId>
<version>${flink.version}</version>
</dependency>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| public class DataGeneratorDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataGeneratorSource<String> dataGeneratorSource =
new DataGeneratorSource<>(
new GeneratorFunction<Long, String>() {
@Override
public String map(Long value) throws Exception {
return "Number:"+value;
}
},
Long.MAX_VALUE,
RateLimiterStrategy.perSecond(10),
Types.STRING
);
env
.fromSource(dataGeneratorSource, WatermarkStrategy.noWatermarks(), "datagenerator")
.print();
env.execute();
}
}
|
2.6 flink支持的数据类型
1)Flink的类型系统
Flink使用“类型信息”(TypeInformation)来统一表示数据类型。TypeInformation类是Flink中所有类型描述符的基类。它涵盖了类型的一些基本属性,并为每个数据类型生成特定的序列化器、反序列化器和比较器。
2)Flink支持的数据类型
对于常见的Java和Scala数据类型,Flink都是支持的。Flink在内部,Flink对支持不同的类型进行了划分,这些类型可以在Types工具类中找到:
(1)基本类型
所有Java基本类型及其包装类,再加上Void、String、Date、BigDecimal和BigInteger。
(2)数组类型
包括基本类型数组(PRIMITIVE_ARRAY)和对象数组(OBJECT_ARRAY)。
(3)复合数据类型
Java元组类型(TUPLE):这是Flink内置的元组类型,是Java API的一部分。最多25个字段,也就是从Tuple0~Tuple25,不支持空字段。
Scala 样例类及Scala元组:不支持空字段。
行类型(ROW):可以认为是具有任意个字段的元组,并支持空字段。
POJO:Flink自定义的类似于Java bean模式的类。
(4)辅助类型
Option、Either、List、Map等。
(5)泛型类型(GENERIC)
Flink支持所有的Java类和Scala类。不过如果没有按照上面POJO类型的要求来定义,就会被Flink当作泛型类来处理。Flink会把泛型类型当作黑盒,无法获取它们内部的属性;它们也不是由Flink本身序列化的,而是由Kryo序列化的。
在这些类型中,元组类型和POJO类型最为灵活,因为它们支持创建复杂类型。而相比之下,POJO还支持在键(key)的定义中直接使用字段名,这会让我们的代码可读性大大增加。所以,在项目实践中,往往会将流处理程序中的元素类型定为Flink的POJO类型。
Flink对POJO类型的要求如下:
类是公有(public)的
有一个无参的构造方法
所有属性都是公有(public)的
所有属性的类型都是可以序列化的
3)类型提示(Type Hints)
Flink还具有一个类型提取系统,可以分析函数的输入和返回类型,自动获取类型信息,从而获得对应的序列化器和反序列化器。但是,由于Java中泛型擦除的存在,在某些特殊情况下(比如Lambda表达式中),自动提取的信息是不够精细的——只告诉Flink当前的元素由“船头、船身、船尾”构成,根本无法重建出“大船”的模样;这时就需要显式地提供类型信息,才能使应用程序正常工作或提高其性能。
为了解决这类问题,Java API提供了专门的“类型提示”(type hints)。
回忆一下之前的word count流处理程序,我们在将String类型的每个词转换成(word, count)二元组后,就明确地用returns指定了返回的类型。因为对于map里传入的Lambda表达式,系统只能推断出返回的是Tuple2类型,而无法得到Tuple2<String, Long>。只有显式地告诉系统当前的返回类型,才能正确地解析出完整数据。
1
2
3
| .map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
|
Flink还专门提供了TypeHint类,它可以捕获泛型的类型信息,并且一直记录下来,为运行时提供足够的信息。我们同样可以通过.returns()方法,明确地指定转换之后的DataStream里元素的类型。
1
| returns(new TypeHint<Tuple2<Integer, SomeType>>(){})
|
3. 转换算子
3.1 基本转换算子(map\filter\flatMap)
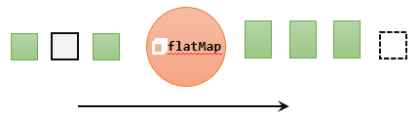
flatMap操作又称为扁平映射,主要是将数据流中的整体(一般是集合类型)拆分成一个一个的个体使用。消费一个元素,可以产生0到多个元素。flatMap可以认为是“扁平化”(flatten)和“映射”(map)两步操作的结合,也就是先按照某种规则对数据进行打散拆分,再对拆分后的元素做转换处理。
3.2 聚合算子(Aggregation)
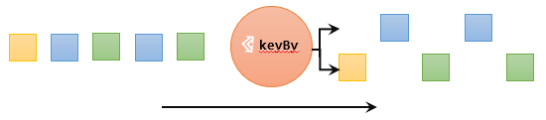
对于Flink而言,DataStream是没有直接进行聚合的API的。因为我们对海量数据做聚合肯定要进行分区并行处理,这样才能提高效率。所以在Flink中,要做聚合,需要先进行分区;这个操作就是通过keyBy来完成的。
keyBy是聚合前必须要用到的一个算子。keyBy通过指定键(key),可以将一条流从逻辑上划分成不同的分区(partitions)。这里所说的分区,其实就是并行处理的子任务。
基于不同的key,流中的数据将被分配到不同的分区中去;这样一来,所有具有相同的key的数据,都将被发往同一个分区。
需要注意的是,keyBy得到的结果将不再是DataStream,而是会将DataStream转换为KeyedStream。KeyedStream可以认为是“分区流”或者“键控流”,它是对DataStream按照key的一个逻辑分区,所以泛型有两个类型:除去当前流中的元素类型外,还需要指定key的类型。
KeyedStream也继承自DataStream,所以基于它的操作也都归属于DataStream API。但它跟之前的转换操作得到的SingleOutputStreamOperator不同,只是一个流的分区操作,并不是一个转换算子。KeyedStream是一个非常重要的数据结构,只有基于它才可以做后续的聚合操作(比如sum,reduce)。
- 简单聚合(sum\min\max\minBy\maxBy)
有了按键分区的数据流KeyedStream,我们就可以基于它进行聚合操作了。Flink为我们内置实现了一些最基本、最简单的聚合API,主要有以下几种:
①sum():在输入流上,对指定的字段做叠加求和的操作。
②min():在输入流上,对指定的字段求最小值。
③max():在输入流上,对指定的字段求最大值。
④minBy():与min()类似,在输入流上针对指定字段求最小值。不同的是,min()只计算指定字段的最小值,其他字段会保留最初第一个数据的值;而minBy()则会返回包含字段最小值的整条数据。
⑤maxBy():与max()类似,在输入流上针对指定字段求最大值。两者区别与min()/minBy()完全一致。
简单聚合算子使用非常方便,语义也非常明确。这些聚合方法调用时,也需要传入参数;但并不像基本转换算子那样需要实现自定义函数,只要说明聚合指定的字段就可以了。指定字段的方式有两种:指定位置,和指定名称。
简单聚合算子返回的,同样是一个SingleOutputStreamOperator,也就是从KeyedStream又转换成了常规的DataStream。所以可以这样理解:keyBy和聚合是成对出现的,先分区、后聚合,得到的依然是一个DataStream。而且经过简单聚合之后的数据流,元素的数据类型保持不变。
一个聚合算子,会为每一个key保存一个聚合的值,在Flink中我们把它叫作“状态”(state)。所以每当有一个新的数据输入,算子就会更新保存的聚合结果,并发送一个带有更新后聚合值的事件到下游算子。对于无界流来说,这些状态是永远不会被清除的,所以我们使用聚合算子,应该只用在含有有限个key的数据流上。
reduce可以对已有的数据进行归约处理,把每一个新输入的数据和当前已经归约出来的值,再做一个聚合计算。
reduce操作也会将KeyedStream转换为DataStream。它不会改变流的元素数据类型,所以输出类型和输入类型是一样的。
调用KeyedStream的reduce方法时,需要传入一个参数,实现ReduceFunction接口。接口在源码中的定义如下:
public interface ReduceFunction extends Function, Serializable {
T reduce(T value1, T value2) throws Exception;
}
ReduceFunction接口里需要实现reduce()方法,这个方法接收两个输入事件,经过转换处理之后输出一个相同类型的事件。在流处理的底层实现过程中,实际上是将中间“合并的结果”作为任务的一个状态保存起来的;之后每来一个新的数据,就和之前的聚合状态进一步做归约。
我们可以单独定义一个函数类实现ReduceFunction接口,也可以直接传入一个匿名类。当然,同样也可以通过传入Lambda表达式实现类似的功能。
为了方便后续使用,定义一个WaterSensorMapFunction:
1
2
3
4
5
6
7
| public class WaterSensorMapFunction implements MapFunction<String,WaterSensor> {
@Override
public WaterSensor map(String value) throws Exception {
String[] datas = value.split(",");
return new WaterSensor(datas[0],Long.valueOf(datas[1]) ,Integer.valueOf(datas[2]) );
}
}
|
案例:使用reduce实现max和maxBy的功能。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env
.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapFunction())
.keyBy(WaterSensor::getId)
.reduce(new ReduceFunction<WaterSensor>()
{
@Override
public WaterSensor reduce(WaterSensor value1, WaterSensor value2) throws Exception {
System.out.println("Demo7_Reduce.reduce");
int maxVc = Math.max(value1.getVc(), value2.getVc());
if (value1.getVc() > value2.getVc()){
value1.setVc(maxVc);
return value1;
}else {
value2.setVc(maxVc);
return value2;
}
}
})
.print();
env.execute();
|
reduce同简单聚合算子一样,也要针对每一个key保存状态。因为状态不会清空,所以我们需要将reduce算子作用在一个有限key的流上。
3.3 用户自定义函数
用户自定义函数(user-defined function,UDF),即用户可以根据自身需求,重新实现算子的逻辑。
用户自定义函数分为:函数类、匿名函数、富函数类。
Flink暴露了所有UDF函数的接口,具体实现方式为接口或者抽象类,例如MapFunction、FilterFunction、ReduceFunction等。所以用户可以自定义一个函数类,实现对应的接口。
需求:用来从用户的点击数据中筛选包含“sensor_1”的内容:
方式一:实现FilterFunction接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| public class TransFunctionUDF {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<WaterSensor> stream = env.fromElements(
new WaterSensor("sensor_1", 1, 1),
new WaterSensor("sensor_1", 2, 2),
new WaterSensor("sensor_2", 2, 2),
new WaterSensor("sensor_3", 3, 3)
);
DataStream<String> filter = stream.filter(new UserFilter());
filter.print();
env.execute();
}
public static class UserFilter implements FilterFunction<WaterSensor> {
@Override
public boolean filter(WaterSensor e) throws Exception {
return e.id.equals("sensor_1");
}
}
}
|
方式二:通过匿名类来实现FilterFunction接口:
1
2
3
4
5
6
| DataStream<String> stream = stream.filter(new FilterFunction< WaterSensor>() {
@Override
public boolean filter(WaterSensor e) throws Exception {
return e.id.equals("sensor_1");
}
});
|
方式二的优化:为了类可以更加通用,我们还可以将用于过滤的关键字”home”抽象出来作为类的属性,调用构造方法时传进去。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| DataStreamSource<WaterSensor> stream = env.fromElements(
new WaterSensor("sensor_1", 1, 1),
new WaterSensor("sensor_1", 2, 2),
new WaterSensor("sensor_2", 2, 2),
new WaterSensor("sensor_3", 3, 3)
);
DataStream<String> stream = stream.filter(new FilterFunctionImpl("sensor_1"));
public static class FilterFunctionImpl implements FilterFunction<WaterSensor> {
private String id;
FilterFunctionImpl(String id) { this.id=id; }
@Override
public boolean filter(WaterSensor value) throws Exception {
return thid.id.equals(value.id);
}
}
|
方式三:采用匿名函数(Lambda)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public class TransFunctionUDF {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<WaterSensor> stream = env.fromElements(
new WaterSensor("sensor_1", 1, 1),
new WaterSensor("sensor_1", 2, 2),
new WaterSensor("sensor_2", 2, 2),
new WaterSensor("sensor_3", 3, 3)
);
//map函数使用Lambda表达式,不需要进行类型声明
SingleOutputStreamOperator<String> filter = stream.filter(sensor -> "sensor_1".equals(sensor.id));
filter.print();
env.execute();
}
}
|
- 富函数类Rich Function Classes
“富函数类”也是DataStream API提供的一个函数类的接口,所有的Flink函数类都有其Rich版本。富函数类一般是以抽象类的形式出现的。例如:RichMapFunction、RichFilterFunction、RichReduceFunction等。
与常规函数类的不同主要在于,富函数类可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能。
Rich Function有生命周期的概念。典型的生命周期方法有:
①open()方法,是Rich Function的初始化方法,也就是会开启一个算子的生命周期。当一个算子的实际工作方法例如map()或者filter()方法被调用之前,open()会首先被调用。
②close()方法,是生命周期中的最后一个调用的方法,类似于结束方法。一般用来做一些清理工作。
需要注意的是,这里的生命周期方法,对于一个并行子任务来说只会调用一次;而对应的,实际工作方法,例如RichMapFunction中的map(),在每条数据到来后都会触发一次调用。
来看一个例子说明:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| public class RichFunctionExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
env
.fromElements(1,2,3,4)
.map(new RichMapFunction<Integer, Integer>() {
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
System.out.println("索引是:" + getRuntimeContext().getIndexOfThisSubtask() + " 的任务的生命周期开始");
}
@Override
public Integer map(Integer integer) throws Exception {
return integer + 1;
}
@Override
public void close() throws Exception {
super.close();
System.out.println("索引是:" + getRuntimeContext().getIndexOfThisSubtask() + " 的任务的生命周期结束");
}
})
.print();
env.execute();
}
}
|
3.4 物理分区算子
常见的物理分区策略有:随机分配(Random)、轮询分配(Round-Robin)、重缩放(Rescale)和广播(Broadcast)。
3.4.1随机分区shuffle
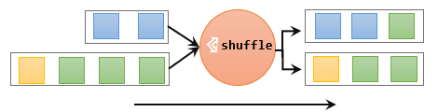
随机分区服从均匀分布(uniform distribution),所以可以把流中的数据随机打乱,均匀地传递到下游任务分区。因为是完全随机的,所以对于同样的输入数据, 每次执行得到的结果也不会相同。
经过随机分区之后,得到的依然是一个DataStream。
3.4.2 轮训分区Round-Robin
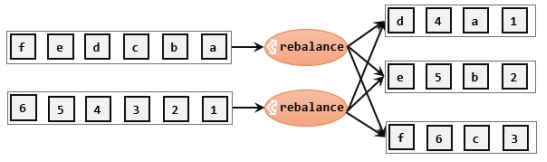
轮询,简单来说就是“发牌”,按照先后顺序将数据做依次分发。通过调用DataStream的.rebalance()方法,就可以实现轮询重分区。rebalance使用的是Round-Robin负载均衡算法,可以将输入流数据平均分配到下游的并行任务中去。
3.4.3 重缩放分区rescale
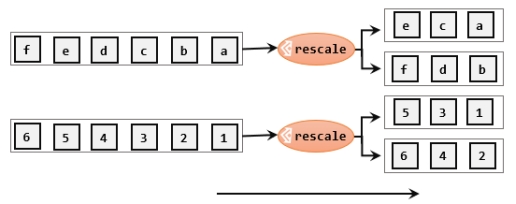
重缩放分区和轮询分区非常相似。当调用rescale()方法时,其实底层也是使用Round-Robin算法进行轮询,但是只会将数据轮询发送到下游并行任务的一部分中。rescale的做法是分成小团体,发牌人只给自己团体内的所有人轮流发牌。
3.4.4 广播
这种方式其实不应该叫做“重分区”,因为经过广播之后,数据会在不同的分区都保留一份,可能进行重复处理。可以通过调用DataStream的broadcast()方法,将输入数据复制并发送到下游算子的所有并行任务中去。
3.4.5 全局分区
全局分区也是一种特殊的分区方式。这种做法非常极端,通过调用.global()方法,会将所有的输入流数据都发送到下游算子的第一个并行子任务中去。这就相当于强行让下游任务并行度变成了1,所以使用这个操作需要非常谨慎,可能对程序造成很大的压力。
3.4.6 自定义分区
当Flink提供的所有分区策略都不能满足用户的需求时,我们可以通过使用partitionCustom()方法来自定义分区策略。
1)自定义分区器
1
2
3
4
5
6
| public class MyPartitioner implements Partitioner<String> {
@Override
public int partition(String key, int numPartitions) {
return Integer.parseInt(key) % numPartitions;
}
}
|
2)使用自定义分区
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public class PartitionCustomDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setParallelism(2);
DataStreamSource<String> socketDS = env.socketTextStream("hadoop102", 7777);
DataStream<String> myDS = socketDS
.partitionCustom(
new MyPartitioner(),
value -> value);
myDS.print();
env.execute();
}
}
|
3.5 分流
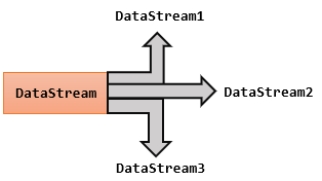
所谓“分流”,就是将一条数据流拆分成完全独立的两条、甚至多条流。也就是基于一个DataStream,定义一些筛选条件,将符合条件的数据拣选出来放到对应的流里。
案例需求:读取一个整数数字流,将数据流划分为奇数流和偶数流。
①代码实现1:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public class SplitStreamByFilter {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
SingleOutputStreamOperator<Integer> ds = env.socketTextStream("hadoop102", 7777)
.map(Integer::valueOf);
//将ds 分为两个流 ,一个是奇数流,一个是偶数流
//使用filter 过滤两次
SingleOutputStreamOperator<Integer> ds1 = ds.filter(x -> x % 2 == 0);
SingleOutputStreamOperator<Integer> ds2 = ds.filter(x -> x % 2 == 1);
ds1.print("偶数");
ds2.print("奇数");
env.execute();
}
}
|
这种实现非常简单,但代码显得有些冗余——我们的处理逻辑对拆分出的三条流其实是一样的,却重复写了三次。而且这段代码背后的含义,是将原始数据流stream复制三份,然后对每一份分别做筛选;这明显是不够高效的。我们自然想到,能不能不用复制流,直接用一个算子就把它们都拆分开呢?
②使用侧输出流
只需要调用上下文ctx的.output()方法,就可以输出任意类型的数据了。而侧输出流的标记和提取,都离不开一个“输出标签”(OutputTag),指定了侧输出流的id和类型。
代码实现2:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| public class SplitStreamByOutputTag {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
SingleOutputStreamOperator<WaterSensor> ds = env.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapFunction());
OutputTag<WaterSensor> s1 = new OutputTag<>("s1", Types.POJO(WaterSensor.class)){};
OutputTag<WaterSensor> s2 = new OutputTag<>("s2", Types.POJO(WaterSensor.class)){};
SingleOutputStreamOperator<WaterSensor> ds1 = ds.process(new ProcessFunction<WaterSensor, WaterSensor>()
{
@Override
public void processElement(WaterSensor value, Context ctx, Collector<WaterSensor> out) throws Exception {
if ("s1".equals(value.getId())) {
ctx.output(s1, value);
} else if ("s2".equals(value.getId())) {
ctx.output(s2, value);
} else {
out.collect(value);
}
}
});
ds1.print("主流,非s1,s2的传感器");
SideOutputDataStream<WaterSensor> s1DS = ds1.getSideOutput(s1);
SideOutputDataStream<WaterSensor> s2DS = ds1.getSideOutput(s2);
s1DS.printToErr("s1");
s2DS.printToErr("s2");
env.execute();
}
}
|
3.6 基本合流操作
在实际应用中,我们经常会遇到来源不同的多条流,需要将它们的数据进行联合处理。所以Flink中合流的操作会更加普遍,对应的API也更加丰富。
3.6.1 联合Union
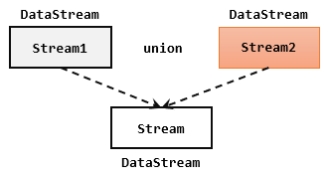
最简单的合流操作,就是直接将多条流合在一起,叫作流的“联合”(union)。联合操作要求必须流中的数据类型必须相同,合并之后的新流会包括所有流中的元素,数据类型不变。
在代码中,我们只要基于DataStream直接调用.union()方法,传入其他DataStream作为参数,就可以实现流的联合了;得到的依然是一个DataStream:
1
| stream1.union(stream2, stream3, ...)
|
注意:union()的参数可以是多个DataStream,所以联合操作可以实现多条流的合并。
代码实现:我们可以用下面的代码做一个简单测试:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public class UnionExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Integer> ds1 = env.fromElements(1, 2, 3);
DataStreamSource<Integer> ds2 = env.fromElements(2, 2, 3);
DataStreamSource<String> ds3 = env.fromElements("2", "2", "3");
ds1.union(ds2,ds3.map(Integer::valueOf))
.print();
env.execute();
}
}
|
3.6.2 连接Connect
流的联合虽然简单,不过受限于数据类型不能改变,灵活性大打折扣,所以实际应用较少出现。除了联合(union),Flink还提供了另外一种方便的合流操作——连接(connect)。
①连接流
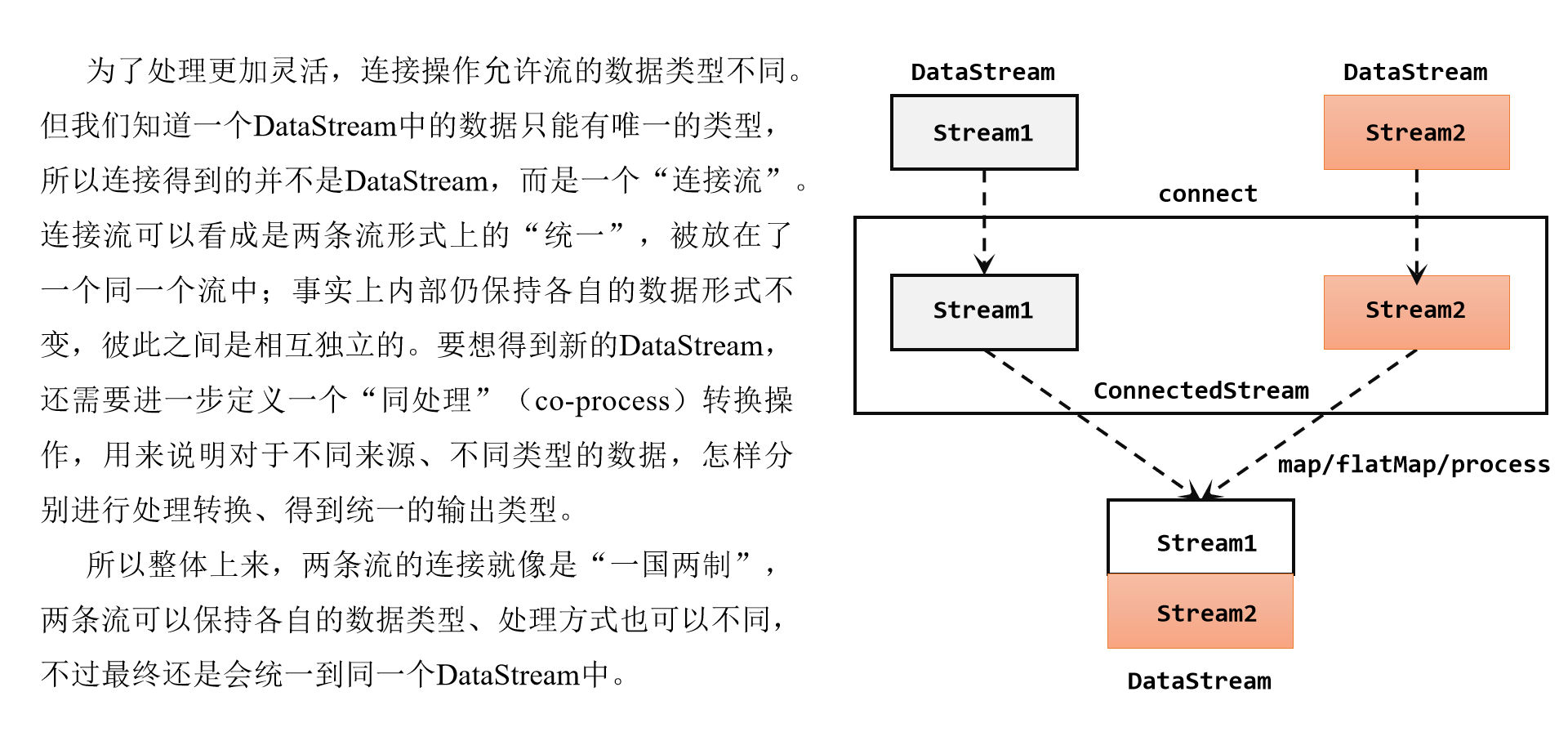
代码实现:需要分为两步:首先基于一条DataStream调用.connect()方法,传入另外一条DataStream作为参数,将两条流连接起来,得到一个ConnectedStreams;然后再调用同处理方法得到DataStream。这里可以的调用的同处理方法有.map()/.flatMap(),以及.process()方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| public class ConnectDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Integer> source1 = env
.socketTextStream("hadoop102", 7777)
.map(i -> Integer.parseInt(i));
DataStreamSource<String> source2 = env.socketTextStream("hadoop102", 8888);
ConnectedStreams<Integer, String> connect = source1.connect(source2);
SingleOutputStreamOperator<String> result = connect.map(new CoMapFunction<Integer, String, String>() {
@Override
public String map1(Integer value) throws Exception {
return "来源于数字流:" + value.toString();
}
@Override
public String map2(String value) throws Exception {
return "来源于字母流:" + value;
}
});
result.print();
env.execute(); }
}
|
②CoProcessFunction
与CoMapFunction类似,如果是调用.map()就需要传入一个CoMapFunction,需要实现map1()、map2()两个方法;而调用.process()时,传入的则是一个CoProcessFunction。它也是“处理函数”家族中的一员,用法非常相似。它需要实现的就是processElement1()、processElement2()两个方法,在每个数据到来时,会根据来源的流调用其中的一个方法进行处理。
值得一提的是,ConnectedStreams也可以直接调用.keyBy()进行按键分区的操作,得到的还是一个ConnectedStreams:
connectedStreams.keyBy(keySelector1, keySelector2);
这里传入两个参数keySelector1和keySelector2,是两条流中各自的键选择器;当然也可以直接传入键的位置值(keyPosition),或者键的字段名(field),这与普通的keyBy用法完全一致。ConnectedStreams进行keyBy操作,其实就是把两条流中key相同的数据放到了一起,然后针对来源的流再做各自处理,这在一些场景下非常有用。
案例需求:连接两条流,输出能根据id匹配上的数据(类似inner join效果)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
| public class ConnectKeybyDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
DataStreamSource<Tuple2<Integer, String>> source1 = env.fromElements(
Tuple2.of(1, "a1"),
Tuple2.of(1, "a2"),
Tuple2.of(2, "b"),
Tuple2.of(3, "c")
);
DataStreamSource<Tuple3<Integer, String, Integer>> source2 = env.fromElements(
Tuple3.of(1, "aa1", 1),
Tuple3.of(1, "aa2", 2),
Tuple3.of(2, "bb", 1),
Tuple3.of(3, "cc", 1)
);
ConnectedStreams<Tuple2<Integer, String>, Tuple3<Integer, String, Integer>> connect = source1.connect(source2);
ConnectedStreams<Tuple2<Integer, String>, Tuple3<Integer, String, Integer>> connectKey = connect.keyBy(s1 -> s1.f0, s2 -> s2.f0);
SingleOutputStreamOperator<String> result = connectKey.process(
new CoProcessFunction<Tuple2<Integer, String>, Tuple3<Integer, String, Integer>, String>() {
Map<Integer, List<Tuple2<Integer, String>>> s1Cache = new HashMap<>();
Map<Integer, List<Tuple3<Integer, String, Integer>>> s2Cache = new HashMap<>();
@Override
public void processElement1(Tuple2<Integer, String> value, Context ctx, Collector<String> out) throws Exception {
Integer id = value.f0;
if (!s1Cache.containsKey(id)) {
List<Tuple2<Integer, String>> s1Values = new ArrayList<>();
s1Values.add(value);
s1Cache.put(id, s1Values);
} else {
s1Cache.get(id).add(value);
}
if (s2Cache.containsKey(id)) {
for (Tuple3<Integer, String, Integer> s2Element : s2Cache.get(id)) {
out.collect("s1:" + value + "<--------->s2:" + s2Element);
}
}
}
@Override
public void processElement2(Tuple3<Integer, String, Integer> value, Context ctx, Collector<String> out) throws Exception {
Integer id = value.f0;
if (!s2Cache.containsKey(id)) {
List<Tuple3<Integer, String, Integer>> s2Values = new ArrayList<>();
s2Values.add(value);
s2Cache.put(id, s2Values);
} else {
s2Cache.get(id).add(value);
}
if (s1Cache.containsKey(id)) {
for (Tuple2<Integer, String> s1Element : s1Cache.get(id)) {
out.collect("s1:" + s1Element + "<--------->s2:" + value);
}
}
}
});
result.print();
env.execute();
}
}
|
4. 输出算子
4.1 连接到外部系统
Flink的DataStream API专门提供了向外部写入数据的方法:addSink。与addSource类似,addSink方法对应着一个“Sink”算子,主要就是用来实现与外部系统连接、并将数据提交写入的;Flink程序中所有对外的输出操作,一般都是利用Sink算子完成的。
Flink1.12以前,Sink算子的创建是通过调用DataStream的.addSink()方法实现的。
1
| stream.addSink(new SinkFunction(…));
|
addSink方法同样需要传入一个参数,实现的是SinkFunction接口。在这个接口中只需要重写一个方法invoke(),用来将指定的值写入到外部系统中。这个方法在每条数据记录到来时都会调用。
Flink1.12开始,同样重构了Sink架构,
4.2 输出到文件
Flink专门提供了一个流式文件系统的连接器:FileSink,为批处理和流处理提供了一个统一的Sink,它可以将分区文件写入Flink支持的文件系统。
FileSink支持行编码(Row-encoded)和批量编码(Bulk-encoded)格式。这两种不同的方式都有各自的构建器(builder),可以直接调用FileSink的静态方法:
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| public class SinkFile {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);
DataGeneratorSource<String> dataGeneratorSource = new DataGeneratorSource<>(
new GeneratorFunction<Long, String>() {
@Override
public String map(Long value) throws Exception {
return "Number:" + value;
}
},
Long.MAX_VALUE,
RateLimiterStrategy.perSecond(1000),
Types.STRING
);
DataStreamSource<String> dataGen = env.fromSource(dataGeneratorSource, WatermarkStrategy.noWatermarks(), "data-generator");
FileSink<String> fieSink = FileSink
.<String>forRowFormat(new Path("f:/tmp"), new SimpleStringEncoder<>("UTF-8"))
.withOutputFileConfig(
OutputFileConfig.builder()
.withPartPrefix("atguigu-")
.withPartSuffix(".log")
.build()
)
.withBucketAssigner(new DateTimeBucketAssigner<>("yyyy-MM-dd HH", ZoneId.systemDefault()))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(1))
.withMaxPartSize(new MemorySize(1024*1024))
.build()
)
.build();
dataGen.sinkTo(fieSink);
env.execute();
}
}
|
4.3输出到kafka
(1)添加依赖
(2)启动kafka集群
(3)输出到kafka的示例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| public class SinkKafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);
SingleOutputStreamOperator<String> sensorDS = env
.socketTextStream("hadoop102", 7777);
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()
.setBootstrapServers("hadoop102:9092,hadoop103:9092,hadoop104:9092")
.setRecordSerializer(
KafkaRecordSerializationSchema.<String>builder()
.setTopic("ws")
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.setTransactionalIdPrefix("atguigu-")
.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 10*60*1000+"")
.build();
sensorDS.sinkTo(kafkaSink);
env.execute();
}
}
|
自定义序列化器,实现带key的record:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| public class SinkKafkaWithKey {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);
env.setRestartStrategy(RestartStrategies.noRestart());
SingleOutputStreamOperator<String> sensorDS = env
.socketTextStream("hadoop102", 7777);
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()
.setBootstrapServers("hadoop102:9092,hadoop103:9092,hadoop104:9092")
.setRecordSerializer(
new KafkaRecordSerializationSchema<String>() {
@Nullable
@Override
public ProducerRecord<byte[], byte[]> serialize(String element, KafkaSinkContext context, Long timestamp) {
String[] datas = element.split(",");
byte[] key = datas[0].getBytes(StandardCharsets.UTF_8);
byte[] value = element.getBytes(StandardCharsets.UTF_8);
return new ProducerRecord<>("ws", key, value);
}
}
)
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.setTransactionalIdPrefix("atguigu-")
.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 10 * 60 * 1000 + "")
.build();
sensorDS.sinkTo(kafkaSink);
env.execute();
}
}
|
(4)运行代码
1
| > bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic ws
|
4.4 输出到mysql(jdbc)
(1)添加依赖:
1
2
3
4
5
| <dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.27</version>
</dependency>
|
官方还未提供flink-connector-jdbc的1.17.0的正式依赖,暂时从apache snapshot仓库下载,pom文件中指定仓库路径:
1
2
3
4
5
6
7
| <repositories>
<repository>
<id>apache-snapshots</id>
<name>apache snapshots</name>
<url>https://repository.apache.org/content/repositories/snapshots/</url>
</repository>
</repositories>
|
添加依赖:
1
2
3
4
5
| <dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>1.17-SNAPSHOT</version>
</dependency>
|
如果不生效:
1
2
3
4
5
6
| <mirror>
<id>aliyunmaven</id>
<mirrorOf>*,!apache-snapshots</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
|
(2)启动mysql,在test库下建表ws
建表语句:
1
2
3
4
5
6
7
| mysql>
CREATE TABLE `ws` (
`id` varchar(100) NOT NULL,
`ts` bigint(20) DEFAULT NULL,
`vc` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
|
(3)输出到MySQL的示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| public class SinkMySQL {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapFunction());
/**
* TODO 写入mysql
* 1、只能用老的sink写法: addsink
* 2、JDBCSink的4个参数:
* 第一个参数: 执行的sql,一般就是 insert into
* 第二个参数: 预编译sql, 对占位符填充值
* 第三个参数: 执行选项 ---》 攒批、重试
* 第四个参数: 连接选项 ---》 url、用户名、密码
*/
SinkFunction<WaterSensor> jdbcSink = JdbcSink.sink(
"insert into ws values(?,?,?)",
new JdbcStatementBuilder<WaterSensor>() {
@Override
public void accept(PreparedStatement preparedStatement, WaterSensor waterSensor) throws SQLException {
//每收到一条WaterSensor,如何去填充占位符
preparedStatement.setString(1, waterSensor.getId());
preparedStatement.setLong(2, waterSensor.getTs());
preparedStatement.setInt(3, waterSensor.getVc());
}
},
JdbcExecutionOptions.builder()
.withMaxRetries(3) // 重试次数
.withBatchSize(100) // 批次的大小:条数
.withBatchIntervalMs(3000) // 批次的时间
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://hadoop102:3306/test?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8")
.withUsername("root")
.withPassword("000000")
.withConnectionCheckTimeoutSeconds(60) // 重试的超时时间
.build()
);
sensorDS.addSink(jdbcSink);
env.execute();
}
}
|
(4)运行代码,用客户端连接mysql,查看数据是否写入
4.5 自定义sink输出
如果我们想将数据存储到我们自己的存储设备中,而Flink并没有提供可以直接使用的连接器,就只能自定义Sink进行输出了。与Source类似,Flink为我们提供了通用的SinkFunction接口和对应的RichSinkDunction抽象类,只要实现它,通过简单地调用DataStream的.addSink()方法就可以自定义写入任何外部存储。
stream.addSink(new MySinkFunction());
在实现SinkFunction的时候,需要重写的一个关键方法invoke(),在这个方法中我们就可以实现将流里的数据发送出去的逻辑。
这种方式比较通用,对于任何外部存储系统都有效;不过自定义Sink想要实现状态一致性并不容易,所以一般只在没有其它选择时使用。实际项目中用到的外部连接器Flink官方基本都已实现,而且在不断地扩充,因此自定义的场景并不常见。