1. 判断是否存在数据倾斜
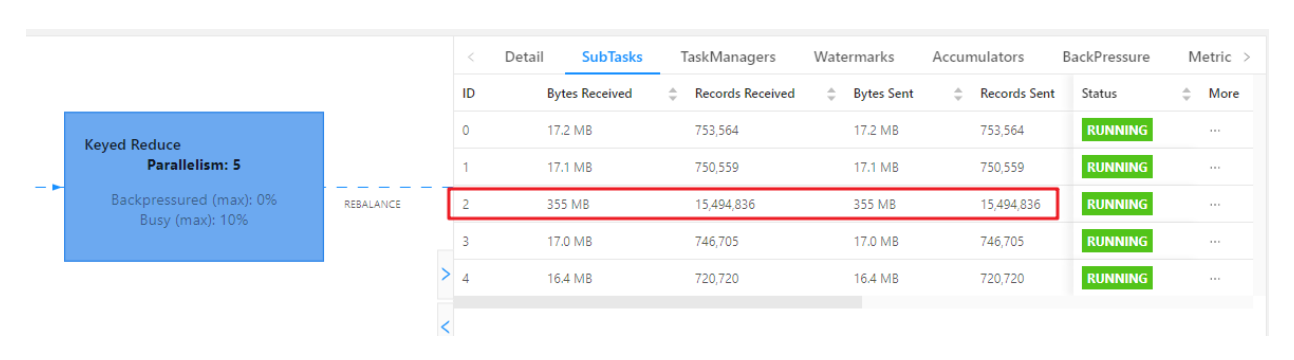
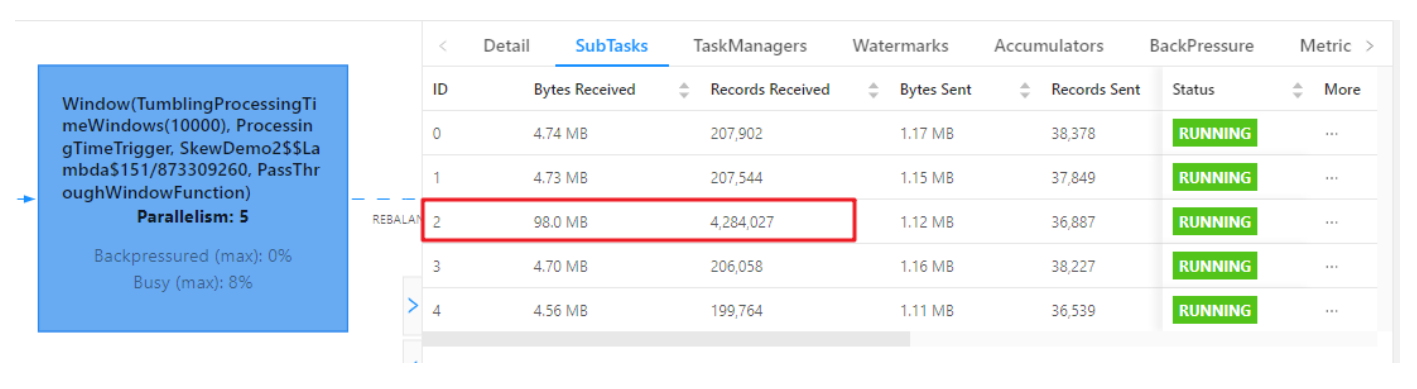
相同 Task 的多个 Subtask 中,个别 Subtask 接收到的数据量明显大于其他Subtask 接收到的数据量,通过 Flink Web UI 可以精确地看到每个 Subtask 处理了多少数据,即可判断出 Flink 任务是否存在数据倾斜。通常,数据倾斜也会引起反压。
另外,有时 Checkpoint detail 里不同 SubTask 的 State size 也是一个分析数据倾斜的有用指标。
2. 数据倾斜的解决
2.1 keyBy后的聚合操作存在数据倾斜
提交案例:
1
2
3
4
5
6
7
8
9
10
11
12
| bin/flink run \
-t yarn-per-job \
-d \
-p 5 \
-Drest.flamegraph.enabled=true \
-Dyarn.application.queue=test \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=2048mb \
-Dtaskmanager.numberOfTaskSlots=2 \
-c com.atguigu.flink.tuning.SkewDemo1 \
/opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar \
--local-keyby false
|
查看 webui:
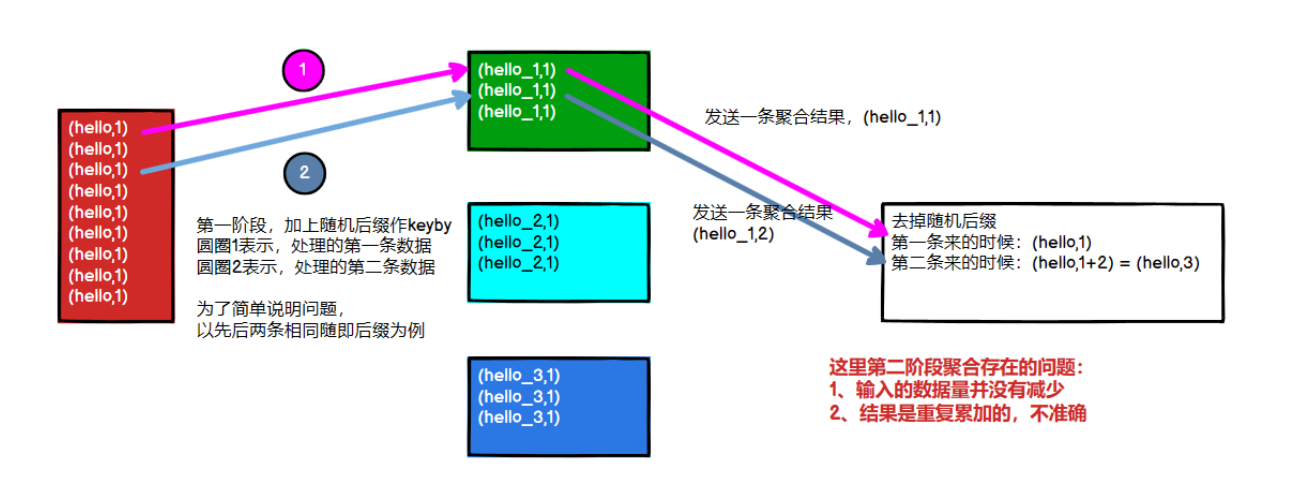
1)为什么不能直接用二次聚合来处理
Flink 是实时流处理,如果 keyby 之后的聚合操作存在数据倾斜,且没有开窗口(没攒批)的情况下,简单的认为使用两阶段聚合,是不能解决问题的。因为这个时候 Flink 是来一条处理一条,且向下游发送一条结果,对于原来 keyby 的维度(第二阶段聚合)来讲,数据量并没有减少,且结果重复计算(非 FlinkSQL,未使用回撤流),如下图所示:
2)使用 LocalKeyBy 的思想
在 keyBy 上游算子数据发送之前,首先在上游算子的本地对数据进行聚合后,再发送到下游,使下游接收到的数据量大大减少,从而使得keyBy 之后的聚合操作不再是任务的瓶颈。类似 MapReduce 中 Combiner 的思想,但是这要求聚合操作必须是多条数据或者一批数据才能聚合,单条数据没有办法通过聚合来减少数据量。从 Flink LocalKeyBy 实现原理来讲,必然会存在一个积攒批次的过程,在上游算子中必须攒够一定的数据量,对这些数据聚合后再发送到下游。
实现方式:
➢ DataStreamAPI 需要自己写代码实现
➢ SQL 可以指定参数,开启 miniBatch 和 LocalGlobal 功能(推荐,后续介绍)
3)DataStream API 自定义实现的案例
以计算每个 mid 出现的次数为例,keyby 之前,使用 flatMap 实现 LocalKeyby 功能
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
| import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction;
import org.apache.flink.util.Collector;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.atomic.AtomicInteger;
public class LocalKeyByFlatMapFunc extends RichFlatMapFunction<Tuple2<String, Long>, Tuple2<String, Long>> implements CheckpointedFunction {
//Checkpoint 时为了保证 Exactly Once,将 buffer 中的数据保存到该 ListState 中
private ListState<Tuple2<String, Long>> listState;
//本地 buffer,存放 local 端缓存的 mid 的 count 信息
private HashMap<String, Long> localBuffer;
//缓存的数据量大小,即:缓存多少数据再向下游发送
private int batchSize;
//计数器,获取当前批次接收的数据量
private AtomicInteger currentSize;
//构造器,批次大小传参
public LocalKeyByFlatMapFunc(int batchSize) {
this.batchSize = batchSize;
}
@Override
public void flatMap(Tuple2<String, Long> value, Collector<Tuple2<String, Long>> out) throws Exception {
// 1、将新来的数据添加到 buffer 中,本地聚合
Long count = localBuffer.getOrDefault(value.f0, 0L);
localBuffer.put(value.f0, count + 1);
// 2、如果到达设定的批次,则将 buffer 中的数据发送到下游
if (currentSize.incrementAndGet() >= batchSize) {
// 2.1 遍历 Buffer 中数据,发送到下游
for (Map.Entry<String, Long> midAndCount : localBuffer.entrySet()) {
out.collect(Tuple2.of(midAndCount.getKey(), midAndCount.getValue()));
}
// 2.2 Buffer 清空,计数器清零
localBuffer.clear();
currentSize.set(0);
}
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
// 将 buffer 中的数据保存到状态中,来保证 Exactly Once
listState.clear();
for (Map.Entry<String, Long> midAndCount : localBuffer.entrySet()) {
listState.add(Tuple2.of(midAndCount.getKey(), midAndCount.getValue()));
}
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
// 从状态中恢复 buffer 中的数据
listState = context.getOperatorStateStore().getListState(
new ListStateDescriptor<Tuple2<String, Long>>(
"localBufferState",
Types.TUPLE(Types.STRING, Types.LONG)
)
);
localBuffer = new HashMap();
if (context.isRestored()) {
// 从状态中恢复数据到 buffer 中
for (Tuple2<String, Long> midAndCount : listState.get()) {
// 如果出现 pv != 0,说明改变了并行度,ListState 中的数据会被均匀分发到新的 subtask中
// 单个 subtask 恢复的状态中可能包含多个相同的 mid 的 count数据
// 所以每次先取一下buffer的值,累加再put
long count = localBuffer.getOrDefault(midAndCount.f0, 0L);
localBuffer.put(midAndCount.f0, count + midAndCount.f1);
}
// 从状态恢复时,默认认为 buffer 中数据量达到了 batchSize,需要向下游发
currentSize = new AtomicInteger(batchSize);
} else {
currentSize = new AtomicInteger(0);
}
}
}
|
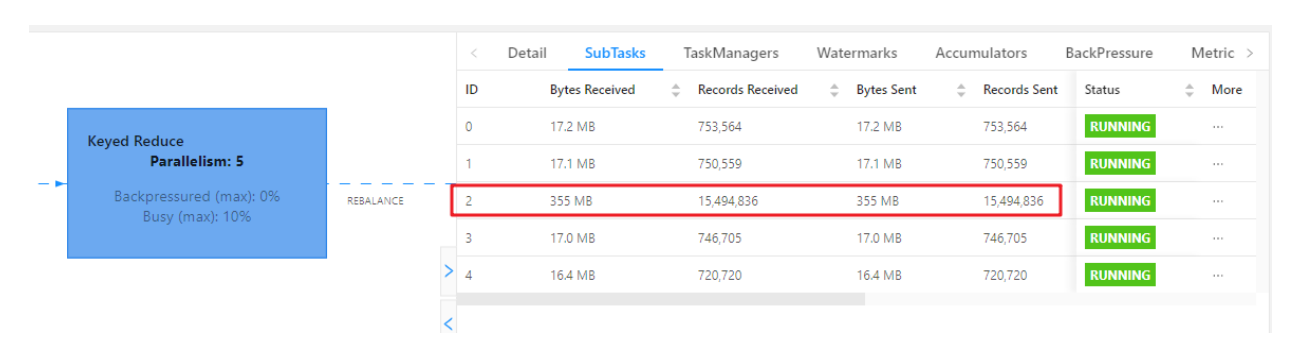
提交 localkeyby 案例:
1
2
3
4
5
6
7
8
9
10
11
12
| bin/flink run \
-t yarn-per-job \
-d \
-p 5 \
-Drest.flamegraph.enabled=true \
-Dyarn.application.queue=test \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=2048mb \
-Dtaskmanager.numberOfTaskSlots=2 \
-c com.atguigu.flink.tuning.SkewDemo1 \
/opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar \
--local-keyby true
|
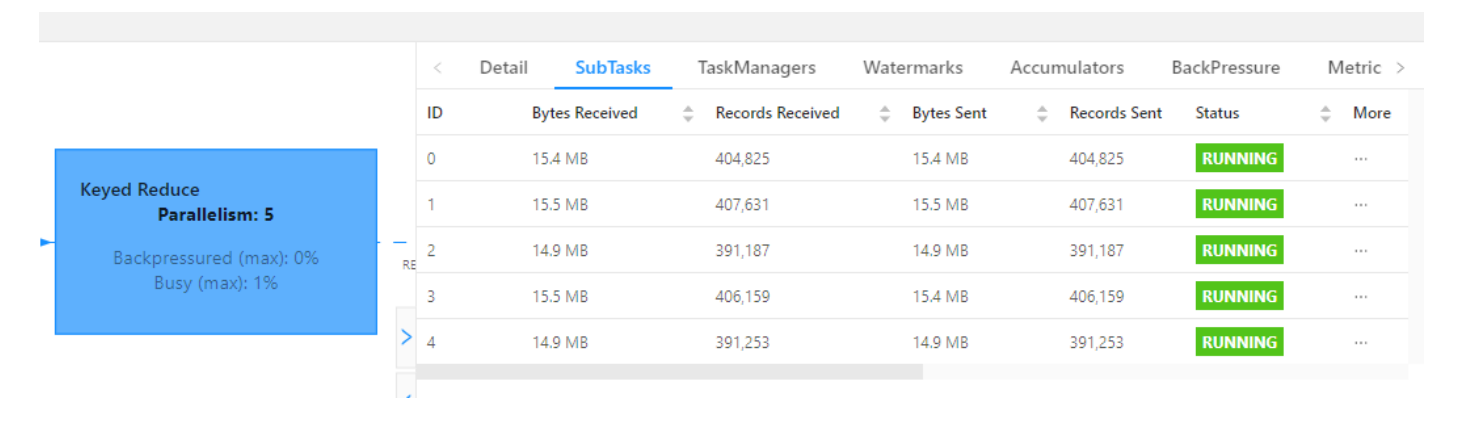
查看 webui:
可以看到每个 subtask 处理的数据量基本均衡,另外处理的数据量相比原先少了很多。
2.2 keyBy前发生的数据倾斜
如果 keyBy 之前就存在数据倾斜,上游算子的某些实例可能处理的数据较多,某些实例可能处理的数据较少,产生该情况可能是因为数据源的数据本身就不均匀,例如由于某些原因 Kafka 的 topic 中某些 partition 的数据量较大,某些 partition 的数据量较少。
对于不存在 keyBy 的 Flink 任务也会出现该情况。这种情况,需要让 Flink 任务强制进行 shuffle。使用 shuffle、rebalance 或 rescale算子即可将数据均匀分配,从而解决数据倾斜的问题。
2.3 keyBy后的窗口聚合操作存在数据倾斜
因为使用了窗口,变成了有界数据(攒批)的处理,窗口默认是触发时才会输出一条结果发往下游,所以可以使用两阶段聚合的方式:
1)实现思路:
➢ 第一阶段聚合:key 拼接随机数前缀或后缀,进行 keyby、开窗、聚合
注意:聚合完不再是 WindowedStream,要获取 WindowEnd 作为窗口标记作为第二阶段分组依据,避免不同窗口的结果聚合到一起)
➢ 第二阶段聚合:按照原来的 key 及 windowEnd 作 keyby、聚合
2)提交原始案例
1
2
3
4
5
6
7
8
9
10
11
12
| bin/flink run \
-t yarn-per-job \
-d \
-p 5 \
-Drest.flamegraph.enabled=true \
-Dyarn.application.queue=test \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=2048mb \
-Dtaskmanager.numberOfTaskSlots=2 \
-c com.atguigu.flink.tuning.SkewDemo2 \
/opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar \
--two-phase false
|
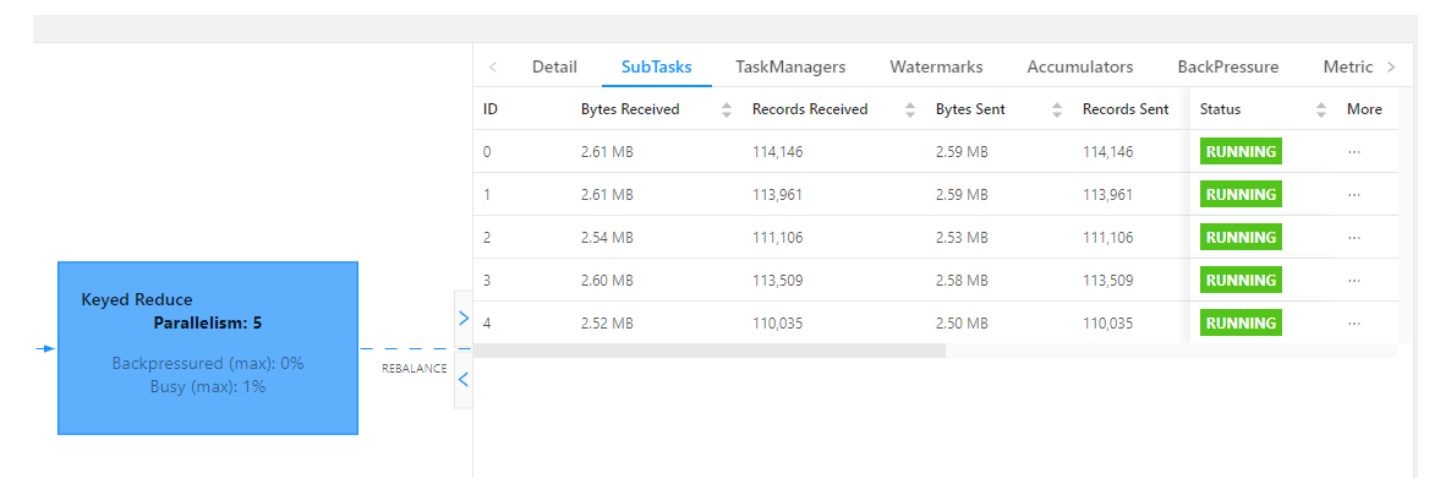
查看 WebUI:
3)提交两阶段聚合的案例
1
2
3
4
5
6
7
8
9
10
11
12
13
| bin/flink run \
-t yarn-per-job \
-d \
-p 5 \
-Drest.flamegraph.enabled=true \
-Dyarn.application.queue=test \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=2048mb \
-Dtaskmanager.numberOfTaskSlots=2 \
-c com.atguigu.flink.tuning.SkewDemo2 \
/opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar \
--two-phase true \
--random-num 16
|
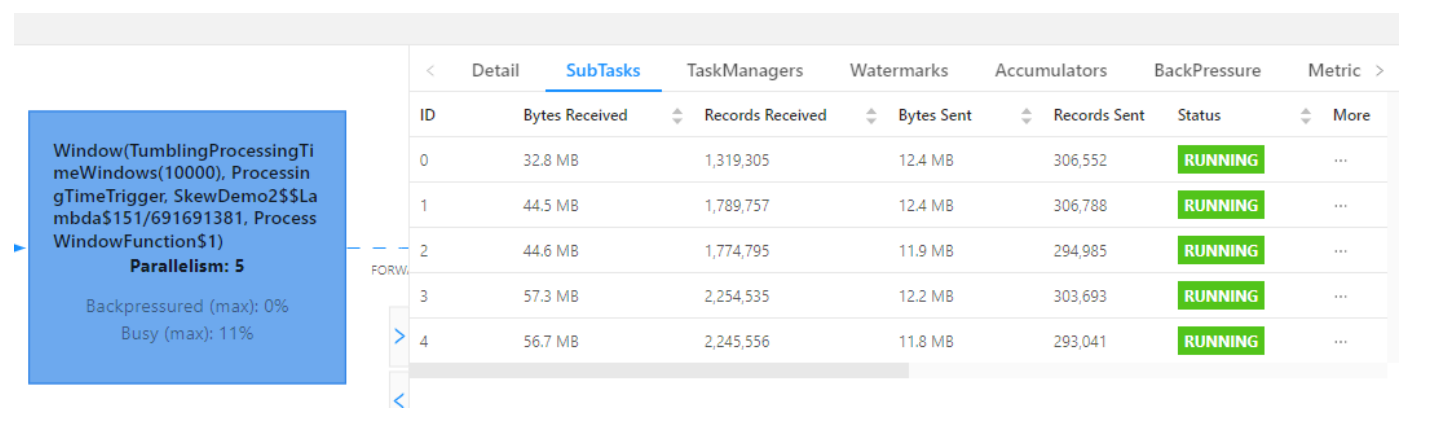
查看 WebUI:可以看到第一次打散的窗口聚合,比较均匀
第二次聚合,也比较均匀:
随机数范围,需要自己去测,因为 keyby 的分区器是(两次 hash*下游并行度/最大并行度)
SQL 写法参考:https://zhuanlan.zhihu.com/p/197299746