RocketMQ 的传输模型是:发布订阅模型 。
发布订阅模型具有如下特点:
消费独⽴;相⽐队列模型的匿名消费⽅式,发布订阅模型中消费⽅都会具备的身份,⼀般叫做订阅组(订阅关系),不同订阅组之间相互独⽴不会相互影响。
⼀对多通信;基于独⽴身份的设计,同⼀个主题内的消息可以被多个订阅组处理,每个订阅组都可以拿到全量消息。因此发布订阅模型可以实现⼀对多通信。
RocketMQ ⽀持两种消息模式:集群消费( Clustering )和⼴播消费( Broadcasting )。
集群消费:同⼀Topic 下的⼀条消息只会被同⼀消费组中的⼀个消费者消费。也就是说,消息被负载均衡到了同⼀个消 费组的多个消费者实例上。
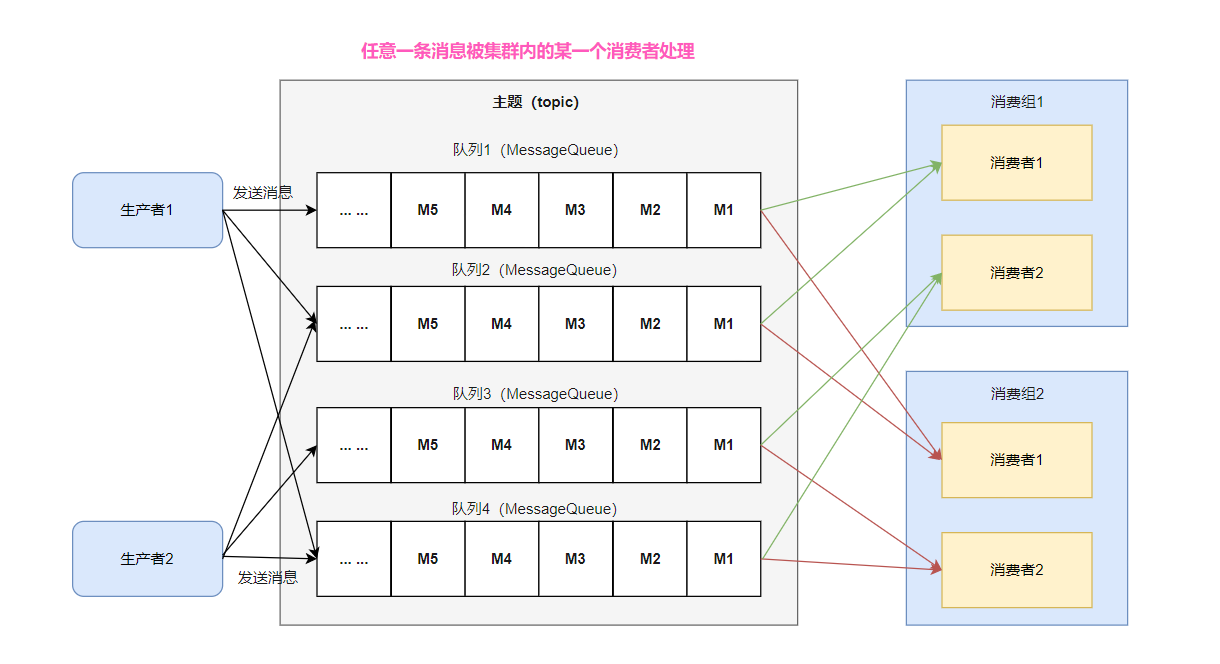
⼴播消费:当使⽤⼴播消费模式时,每条消息推送给集群内所有的消费者,保证消息⾄少被每个消费者消费⼀次。
我们简单模拟下 RocketMQ 存储模型如何满⾜发布订阅模型。
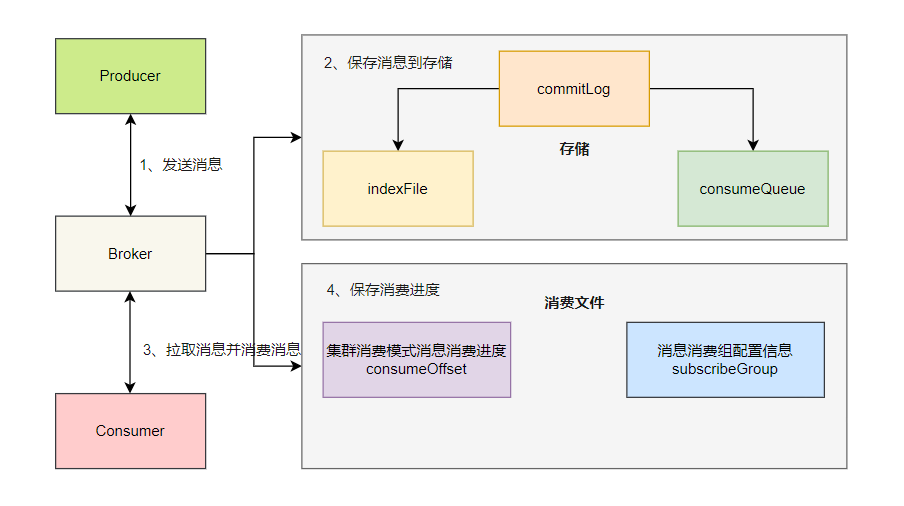
1、发送消息:⽣产者发送消息到 Broker ;
2、保存消息:Broker 将消息存储到 commitlog ⽂件 ,异步线程会构建消费⽂件 consumequeue ;
3、消费流程:消费者启动后,会通过负载均衡分配对应的队列,然后向 Broker 发送拉取消息请求。Broker 收到消费者拉取请求之后,根据订阅组,消费者编号,主题,队列名,逻辑偏移量等参数 ,从该主题下的 consumequeue ⽂件查 询消息消费条⽬,然后从 commitlog ⽂件中获取消息实体。消费者在收到消息数据之后,执⾏消费监听器,消费完消息;
4、保存进度:消费者将消费进度提交到 Broker ,Broker 会将该消费组的消费进度存储在进度⽂件⾥。
1. 消费流程
我们重点讲解下集群消费的消费流程 ,因为集群消费是使⽤最普遍的消费模式,理解了集群消费,⼴播消费也就能顺理成章的掌握了。
1 | public class Consumer { |
集群消费示例代码⾥,启动消费者,我们需要配置三个核⼼属性:消费组名、订阅主题、消息监听器,最后调⽤ start ⽅法启动。
消费者启动后,我们可以将整个流程简化成:
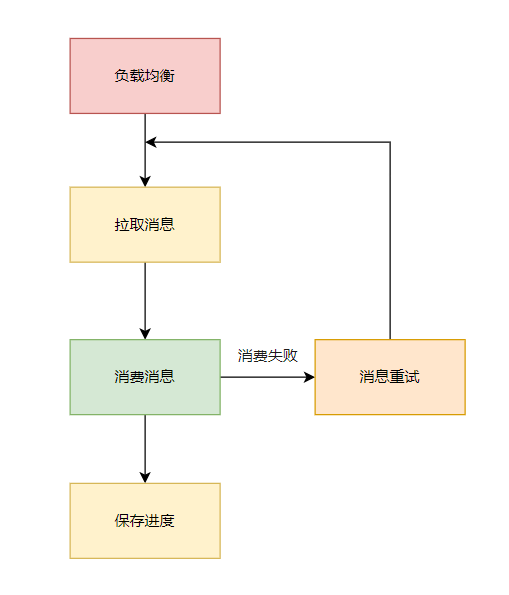
2. 负载均衡
消费端的负载均衡是指将 Broker 端中多个队列按照某种算法分配给同⼀个消费组中的不同消费者,负载均衡是客户端开始消费的起点。
RocketMQ 负载均衡的核⼼设计理念是:
消费队列在同⼀时间只允许被同⼀消费组内的⼀个消费者消费
⼀个消费者能同时消费多个消息队列
负载均衡是每个客户端独⽴进⾏计算,那么何时触发呢 ?
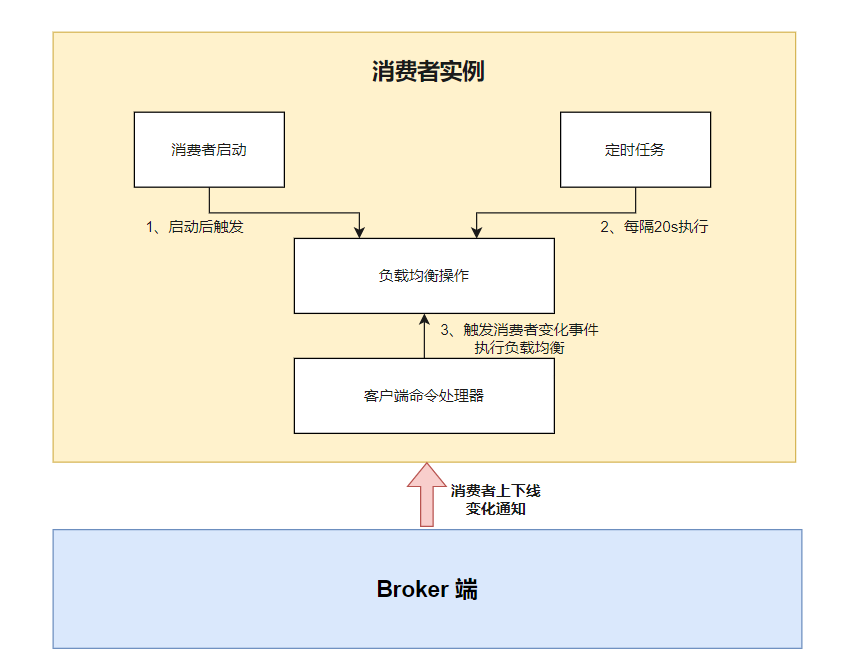
- 消费端启动时,⽴即进⾏负载均衡;
- 消费端定时任务每隔 20 秒触发负载均衡;
- 消费者上下线,Broker 端通知消费者触发负载均衡。
负载均衡流程如下:
1、发送心跳
消费者启动后,它就会通过定时任务不断地向 RocketMQ 集群中的所有 Broker 实例发送⼼跳包(消息消费分组名称、 订阅关系集合、消息通信模式和客户端实例编号等信息)。
Broker 端在收到消费者的⼼跳消息后,会将它维护在 ConsumerManager 的本地缓存变量 consumerTable,同时并将封装后的客户端⽹络通道信息保存在本地缓存变量 channelInfoTable 中,为之后做消费端的负载均衡提供可以依据的元数据信息。
2、启动负载均衡服务
负载均衡服务会根据消费模式为”⼴播模式”还是“集群模式”做不同的逻辑处理,这⾥主要来看下集群模式下的主要处理流程:
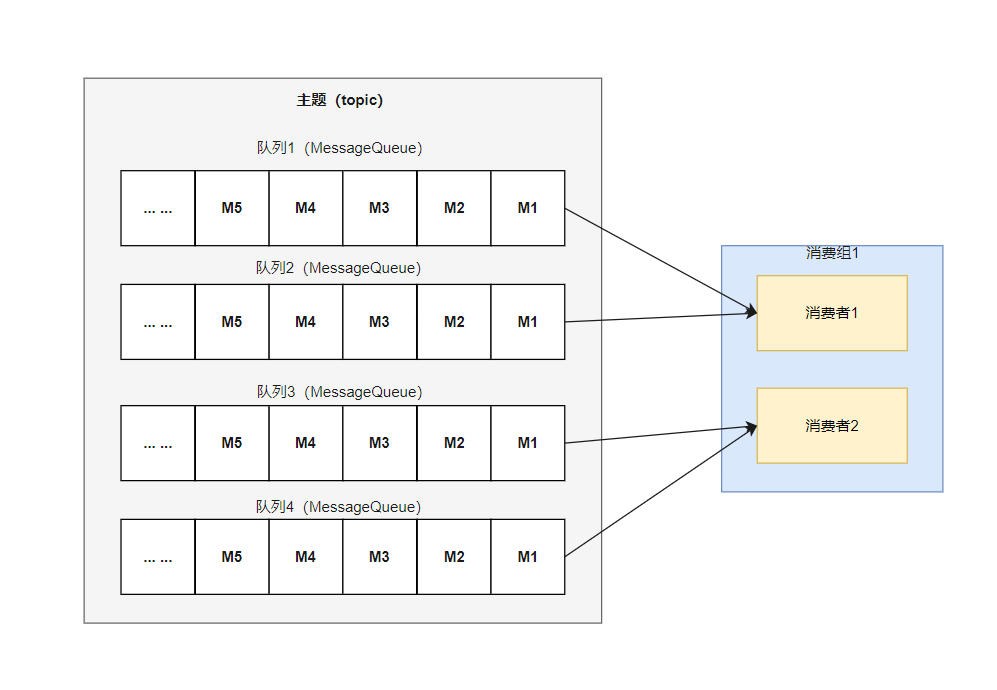
(1) 获取该主题下的消息消费队列集合;
(2) 查询 Broker 端获取该消费组下消费者 Id 列表;
(3) 先对 Topic 下的消息消费队列、消费者 Id 排序,然后⽤消息队列分配策略算法(默认为:消息队列的平均分配算法),计算出待拉取的消息队列;
1 | public class AllocateMessageQueueAveragely implements AllocateMessageQueueStrategy { |
这⾥的平均分配算法,类似于分⻚的算法,将所有 MessageQueue 排好序类似于记录,将所有消费端排好序类似⻚数, 并求出每⼀⻚需要包含的平均 size 和每个⻚⾯记录的范围 range ,最后遍历整个 range ⽽计算出当前消费端应该分配到的记录。
(4) 分配到的消息队列集合与 processQueueTable 做⼀个过滤⽐对操作。
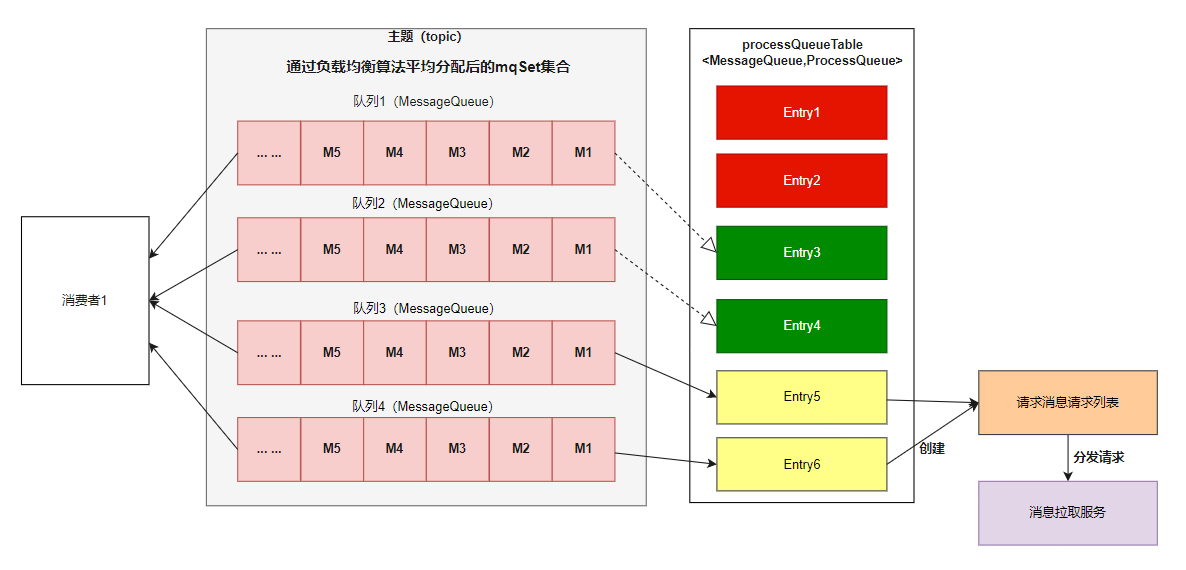
消费者实例内 ,processQueueTable 对象存储着当前负载均衡的队列 ,以及该队列的处理队列 processQueue (消费快照)。
1、标红的 Entry 部分表示与分配到的消息队列集合互不包含,则需要将这些红⾊队列 Dropped 属性为 true , 然后从 processQueueTable 对象中移除。
2、绿⾊的 Entry 部分表示与分配到的消息队列集合的交集,processQueueTable 对象中已经存在该队列。
3、⻩⾊的 Entry 部分表示这些队列需要添加到 processQueueTable 对象中,为每个分配的新队列创建⼀个消息拉取 请求 pullRequest , 在消息拉取请求中保存⼀个处理队列 processQueue (队列消费快照),内部是红⿊树 ( TreeMap ),⽤来保存拉取到的消息。
最后创建拉取消息请求列表,并将请求分发到消息拉取服务,进入拉取消息环节。
3. 长轮询
在负载均衡这⼀⼩节,我们已经知道负载均衡触发了拉取消息的流程。
消费者启动的时候,会创建⼀个拉取消息服务 PullMessageService ,它是⼀个单线程的服务。
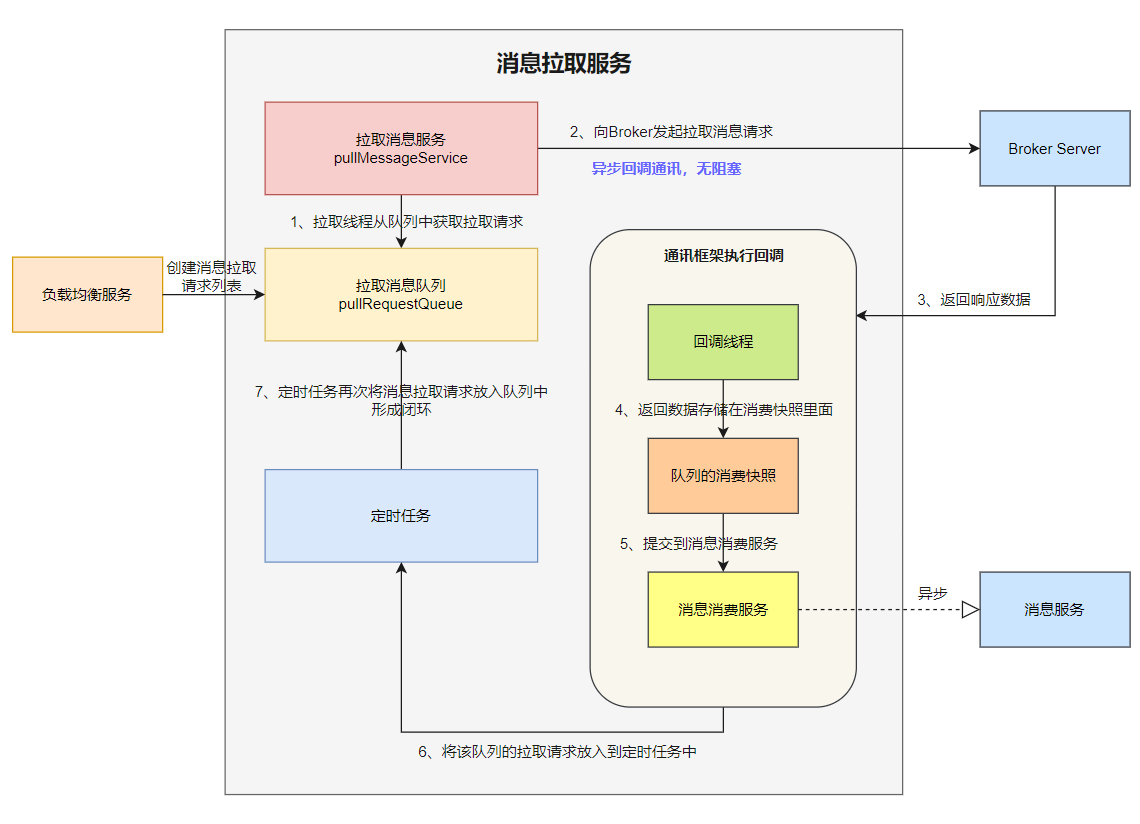
核⼼流程如下:
1、负载均衡服务将消息拉取请求放⼊到拉取请求队列 pullRequestQueue , 拉取消息服务从队列中获取拉取消息请求 ;
2、拉取消息服务向 Brorker 服务发送拉取请求 ,拉取请求的通讯模式是异步回调模式 ;
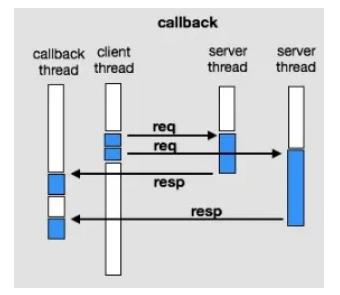
消费者的拉取消息服务本身就是⼀个单线程,使⽤异步回调模式,发送拉取消息请求到 Broker 后,拉取消息线程并不会 阻塞 ,可以继续处理队列 pullRequestQueue 中的其他拉取任务。
3、Broker 收到消费者拉取消息请求后,从存储中查询出消息数据,然后返回给消费者;
4、消费者的⽹络通讯层会执⾏拉取回调函数相关逻辑,⾸先会将消息数据存储在队列消费快照 processQueue ⾥;消费快照使⽤红⿊树 msgTreeMap 存储拉取服务拉取到的消息 。
1 | // key是偏移量offset,value是消息对象 |
5、回调函数将消费请求提交到消息消费服务 ,⽽消息消费服务会异步的消费这些消息;
6、回调函数会将处理中队列的拉取请放⼊到定时任务中;
7、定时任务再次将消息拉取请求放⼊到队列 pullRequestQueue 中,形成了闭环:负载均衡后的队列总会有任务执⾏拉 取消息请求,不会中断。
细⼼的同学肯定有疑问:既然消费端是拉取消息,为什么是⻓轮询呢 ?
虽然拉模式的主动权在消费者这⼀侧,但是缺点很明显。
因为消费者并不知晓 Broker 端什么时候有新的消息 ,所以会不停地去 Broker 端拉取消息,但拉取频率过⾼, Broker 端压⼒就会很⼤,频率过低则会导致消息延迟。
所以要想消费消息的延迟低,服务端的推送必不可少。
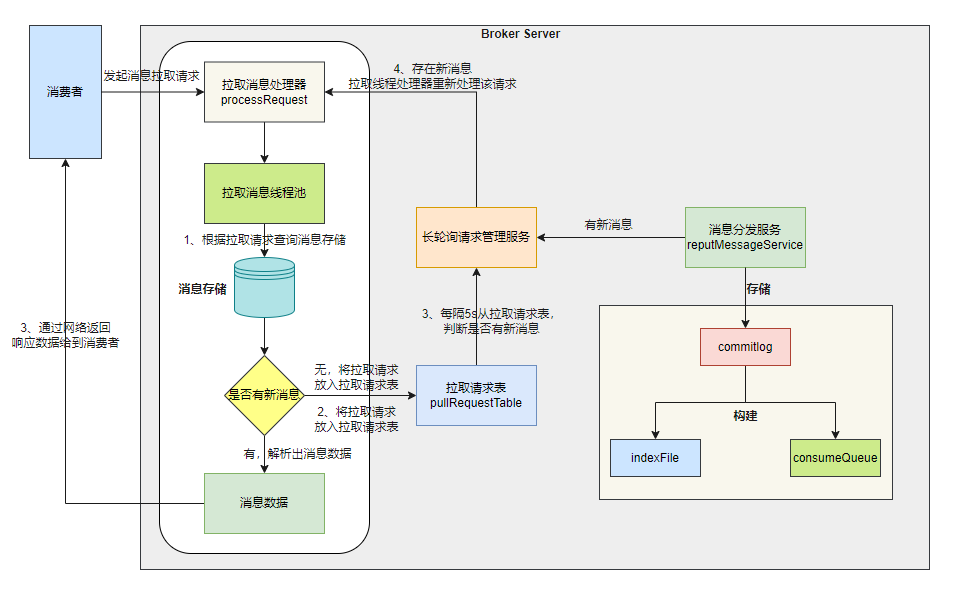
下图展示了 RocketMQ 如何通过⻓轮询减⼩拉取消息的延迟。
核⼼流程如下:
1、Broker 端接收到消费者的拉取消息请求后,拉取消息处理器开始处理请求,根据拉取请求查询消息存储 ;
2、从消息存储中获取消息数据 ,若存在新消息 ,则将消息数据通过⽹络返回给消费者。若⽆新消息,则将拉取请求放 ⼊到拉取请求表 pullRequestTable 。
3、⻓轮询请求管理服务 pullRequestHoldService 每隔 5 秒从拉取请求表中判断拉取消息请求的队列是否有新的消息。 判定标准是:拉取消息请求的偏移量是否⼩于当前消费队列最⼤偏移量,如果条件成⽴则说明有新消息了。 若存在新的消息 , ⻓轮询请求管理服务会触发拉取消息处理器重新处理该拉取消息请求。
4、当 commitlog 中新增了新的消息,消息分发服务会构建消费⽂件和索引⽂件,并且会通知⻓轮询请求管理服务,触发拉取消息处理器重新处理该拉取消息请求。
4. 消费消息
在拉取消息的流程⾥, Broker 端返回消息数据,消费者的通讯框架层会执⾏回调函数。
回调线程会将数据存储在队列消费快照 processQueue(内部使⽤红⿊树 msgTreeMap)⾥,然后将消息提交到消费消 息服务,消费消息服务会异步消费这些消息。
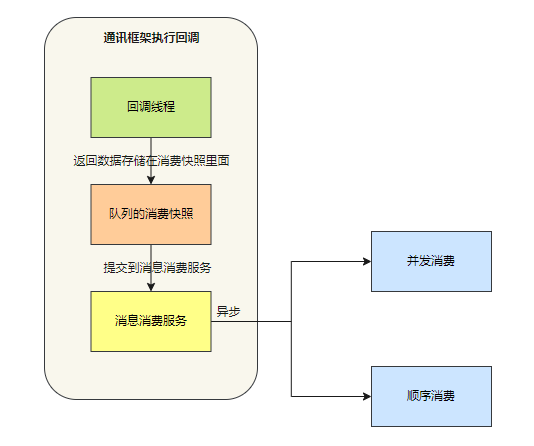
消息消费服务有两种类型:并发消费服务和顺序消费服务 。
1 | public interface ConsumeMessageService { |
4.1 并发消费
并发消费是指消费者将并发消费消息,消费的时候可能是⽆序的。
消费消息并发服务启动后,会初始化三个组件:消费线程池、清理过期消息定时任务、处理失败消息定时任务。
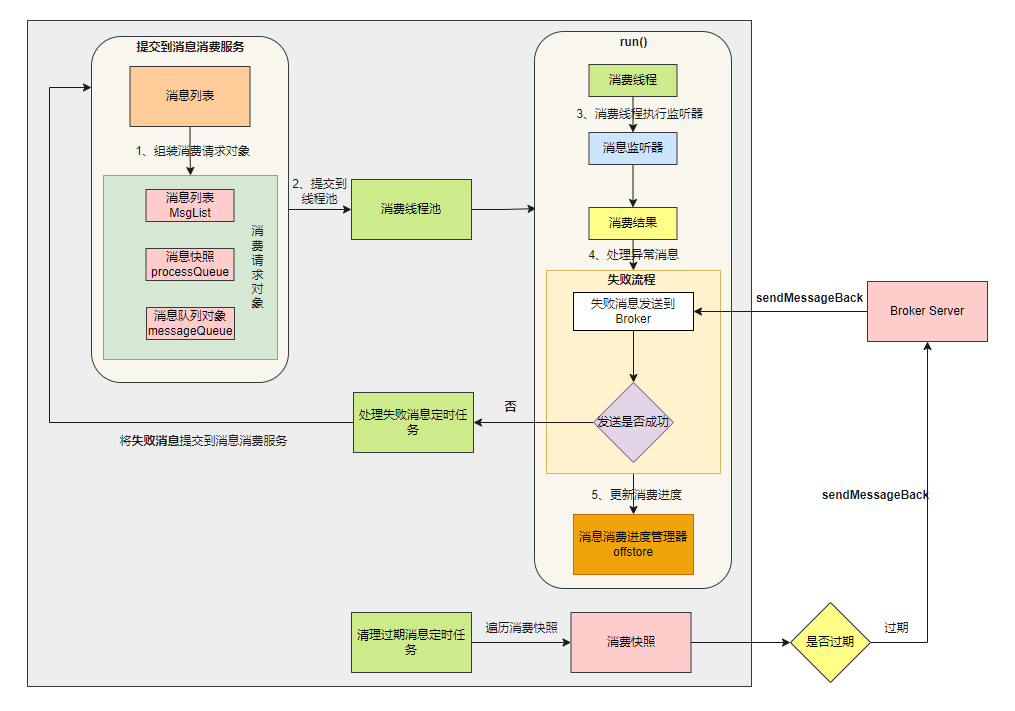
核⼼流程如下:
0、通讯框架回调线程会将数据存储在消费快照⾥,然后将消息列表 msgList 提交到消费消息服务
1、 消息列表 msgList 组装成消费对象
2、将消费对象提交到消费线程池
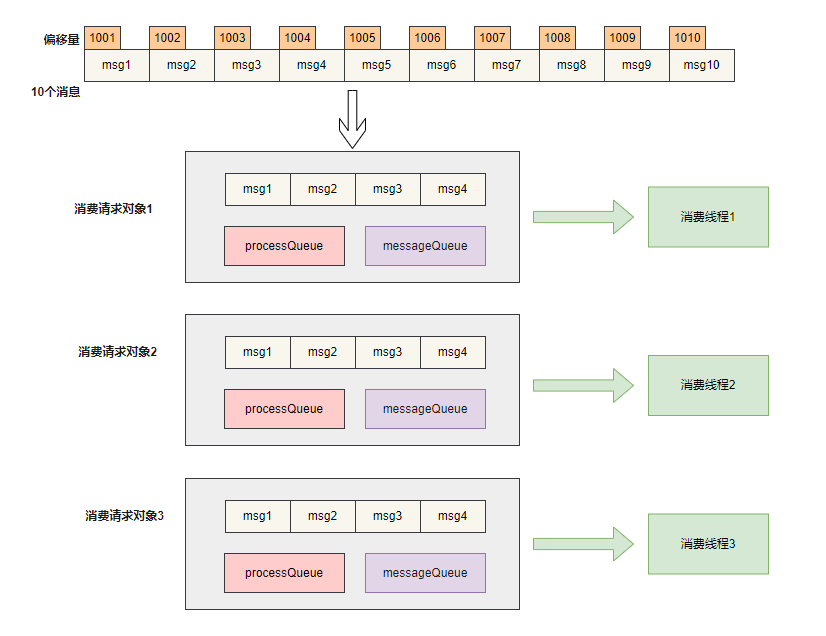
我们看到10 条消息被组装成三个消费请求对象,不同的消费线程会执⾏不同的消费请求对象。
3、消费线程执行消息监听器。
1 | // 消费端启动时会注册监听器 |
执⾏完消费监听器,会返回消费结果。
1 | public enum ConsumeConcurrentlyStatus { |
4、处理异常消息
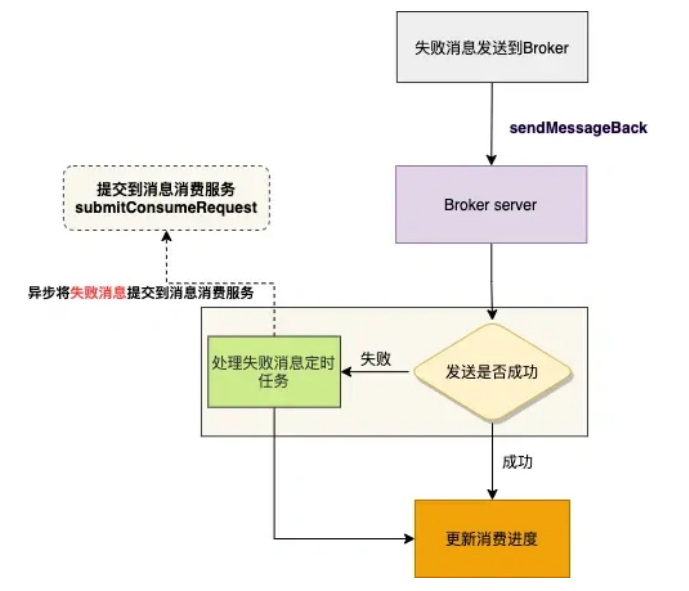
当消费异常时,异常消息将重新发回 Broker 端的重试队列( RocketMQ 会为每个 topic 创建⼀个重试队列,以 %RETRY% 开头),达到重试时间后将消息投递到重试队列中进⾏消费重试。
我们将在重试机制这⼀节重点讲解 RocketMQ 如何实现延迟消费功能 。
假如异常的消息发送到 Broker 端失败,则重新将这些失败消息通过处理失败消息定时任务重新提交到消息消费服务。
5、更新本地消费进度 消费者消费⼀批消息完成之后,需要保存消费进度到进度管理器的本地内存。

⾸先我们会从队列消费快照 processQueue 中移除消息,返回消费快照 msgTreeMap 第⼀个偏移量 ,然后调⽤消费消息进度管理器 offsetStore 更新消费进度。
待更新的偏移量是如何计算的呢?
1 | public long removeMessage(final List<MessageExt> msgs) { |
- 场景1:快照中1001(消息1)到1010(消息10)消费了,快照中没有了消息,返回已消费的消息最⼤偏移量 + 1 也就是1011。

- 场景2:快照中1001(消息1)到1008(消息8)消费了,快照中只剩下两条消息了,返回最⼩的偏移量 1009。

- 场景3:1001(消息1)在消费对象中因为某种原因⼀直没有被消费,即使后⾯的消息1005-1010都消费完成了,返 回的最⼩偏移量是1001。

在场景3,RocketMQ 为了保证消息肯定被消费成功,消费进度只能维持在1001(消息1),直到1001也被消费完,本地的消费进度才会⼀下⼦更新到1011。
假设1001(消息1)还没有消费完成,消费者实例突然退出(机器断电,或者被 kill ),就存在重复消费的⻛险。
因为队列的消费进度还是维持在1001,当队列重新被分配给新的消费者实例的时候,新的实例从 Broker 上拿到的消费进度还是维持在1001,这时候就会⼜从1001开始消费,1001-1010这批消息实际上已经被消费过还是会投递⼀次。
所以业务必须要保证消息消费的幂等性。
写到这⾥,我们会有⼀个疑问:假设1001(消息1)因为加锁或者消费监听器逻辑⾮常耗时,导致极⻓时间没有消费完 成,那么消费进度就会⼀直卡住 ,怎么解决呢 ?
RocketMQ 提供两种⽅式⼀起配合解决:
- 拉取服务根据并发消费间隔配置限流
1 | private int consumeConcurrentlyMaxSpan = 2000; |
拉取消息服务在拉取消息时候,会判断当前队列的 processQueue 消费快照⾥消息的最⼤偏移量 - 消息的最⼩偏移量⼤于消费并发间隔(2000)的时候 , 就会触发流控 , 这样就可以避免消费者⽆限循环的拉取新的消息。
- 清理过期消息
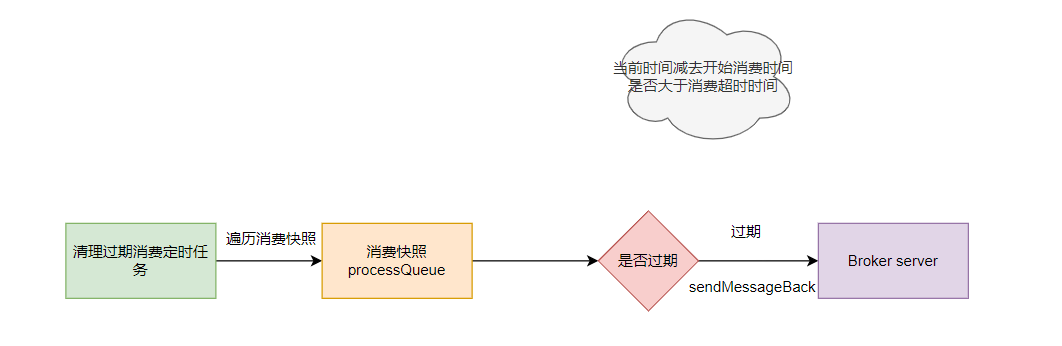
消费消息并发服务启动后,会定期扫描所有消费的消息,若当前时间减去开始消费的时间⼤于消费超时时间,⾸先会将过期消息发送 sendMessageBack 命令发送到 Broker ,然后从快照中删除该消息。
4.2 顺序消费
顺序消息是指对于⼀个指定的 Topic ,消息严格按照先进先出(FIFO)的原则进⾏消息发布和消费,即先发布的消息先消费,后发布的消息后消费。
顺序消息分为分区顺序消息和全局顺序消息。
1、分区顺序消息 对于指定的⼀个 Topic ,所有消息根据 Sharding Key 进⾏区块分区,同⼀个分区内的消息按照严格的先进先出(FIFO) 原则进⾏发布和消费。同⼀分区内的消息保证顺序,不同分区之间的消息顺序不做要求。
- 适⽤场景:适⽤于性能要求⾼,以 Sharding Key 作为分区字段,在同⼀个区块中严格地按照先进先出(FIFO)原则进⾏消息发布和消费的场景。
- 示例:电商的订单创建,以订单 ID 作为 Sharding Key ,那么同⼀个订单相关的创建订单消息、订单⽀付消息、订单退款消息、订单物流消息都会按照发布的先后顺序来消费。
2、全局顺序消息
对于指定的⼀个 Topic ,所有消息按照严格的先⼊先出(FIFO)的顺序来发布和消费。
- 适⽤场景:适⽤于性能要求不⾼,所有的消息严格按照 FIFO 原则来发布和消费的场景。
- 示例:在证券处理中,以⼈⺠币兑换美元为 Topic,在价格相同的情况下,先出价者优先处理,则可以按照 FIFO 的 ⽅式发布和消费全局顺序消息。
全局顺序消息实际上是⼀种特殊的分区顺序消息,即 Topic 中只有⼀个分区,因此全局顺序和分区顺序的实现原理 相同。 因为分区顺序消息有多个分区,所以分区顺序消息⽐全局顺序消息的并发度和性能更⾼。
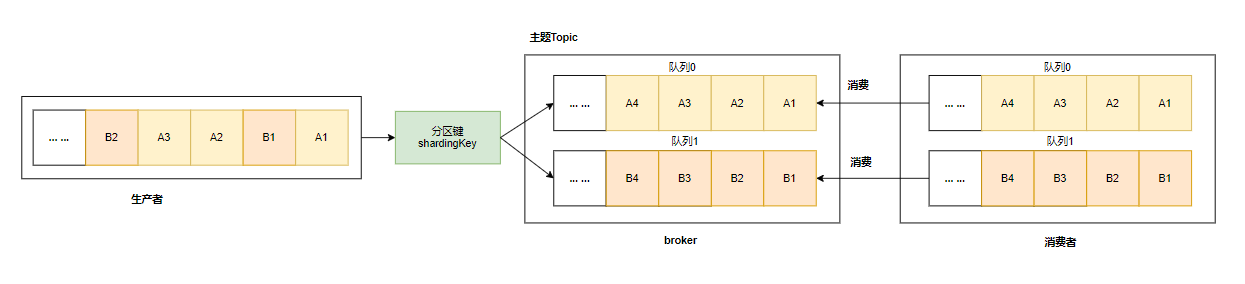
消息的顺序需要由两个阶段保证:
- 消息发送
如上图所示,A1、B1、A2、A3、B2、B3 是订单 A 和订单 B 的消息产⽣的顺序,业务上要求同⼀订单的消息保持 顺序,例如订单 A 的消息发送和消费都按照 A1、A2、A3 的顺序。
如果是普通消息,订单A 的消息可能会被轮询发送到不同的队列中,不同队列的消息将⽆法保持顺序,⽽顺序消息 发送时 RocketMQ ⽀持将 Sharding Key 相同(例如同⼀订单号)的消息序路由到同⼀个队列中。
下图是⽣产者发送顺序消息的封装,原理是发送消息时,实现 MessageQueueSelector 接⼝, 根据 Sharding Key 使⽤ Hash 取模法来选择待发送的队列。
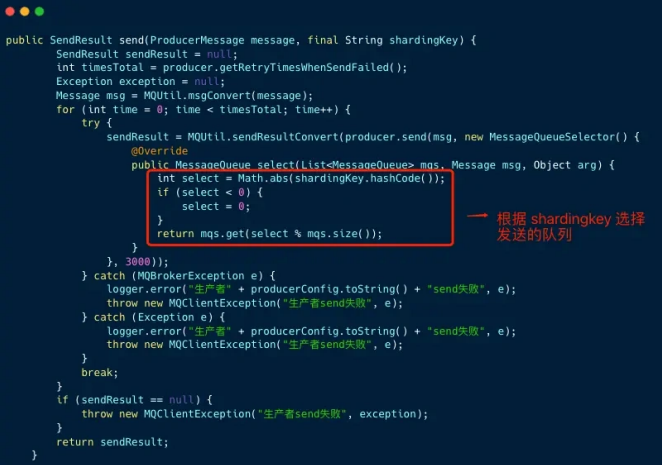
- 消息消费
消费者消费消息时,需要保证单线程消费每个队列的消息数据,从⽽实现消费顺序和发布顺序的⼀致。
顺序消费服务的类是 ConsumeMessageOrderlyService ,在负载均衡阶段,并发消费和顺序消费并没有什么⼤的差 别。
最⼤的差别在于:顺序消费会向 Borker 申请锁 。消费者根据分配的队列 messageQueue ,向 Borker 申请锁 ,如果申 请成功,则会拉取消息,如果失败,则定时任务每隔20秒会重新尝试。
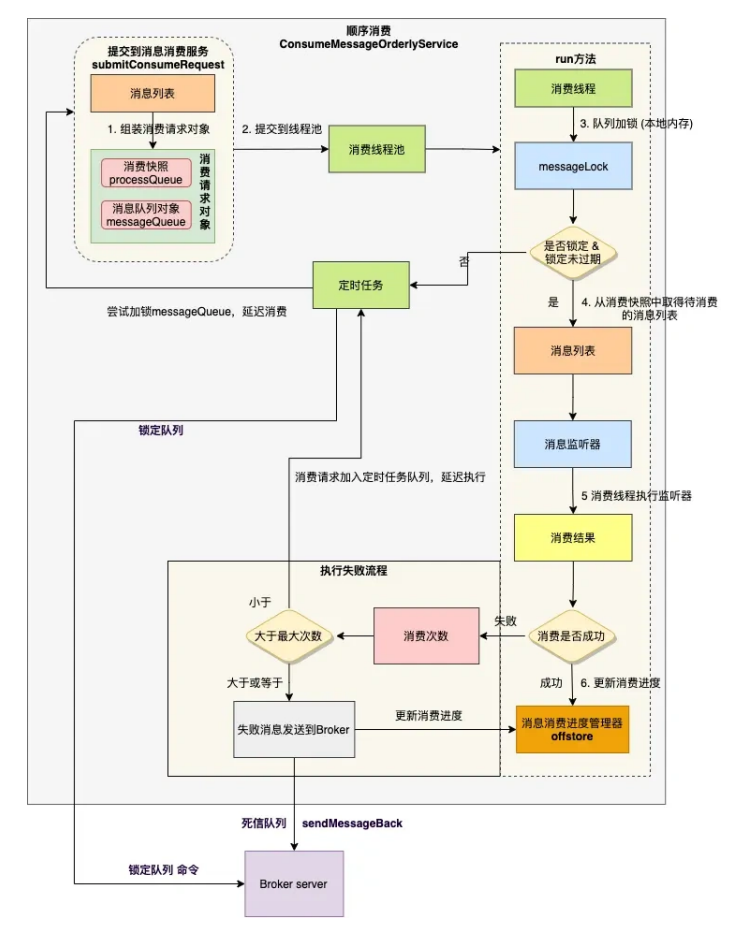
顺序消费核⼼流程如下:
1、 组装成消费对象
2、 将请求对象提交到消费线程池
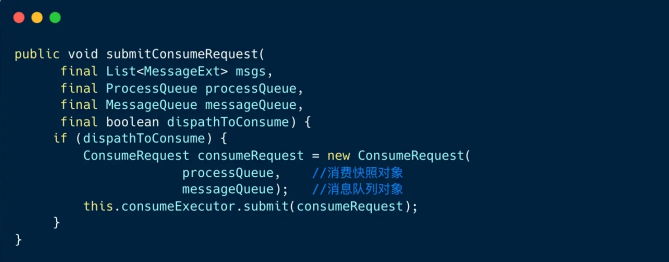
和并发消费不同的是,这⾥的消费请求包含消费快照 processQueue ,消息队列 messageQueue 两个对象,并不对消息列表做任何处理。
3、 消费线程内,对消费队列加锁
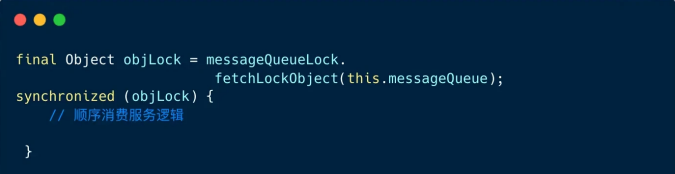
顺序消费也是通过线程池消费的,synchronized 锁⽤来保证同⼀时刻对于同⼀个队列只有⼀个线程去消费它
4、 从消费快照中取得待消费的消息列表
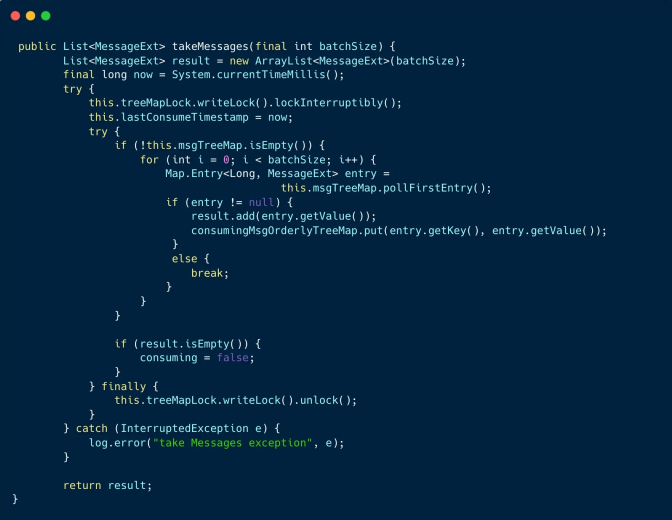
消费快照 processQueue 对象⾥,创建了⼀个红⿊树对象 consumingMsgOrderlyTreeMap ⽤于临时存储的待消费的消息。
5、 执⾏消息监听器
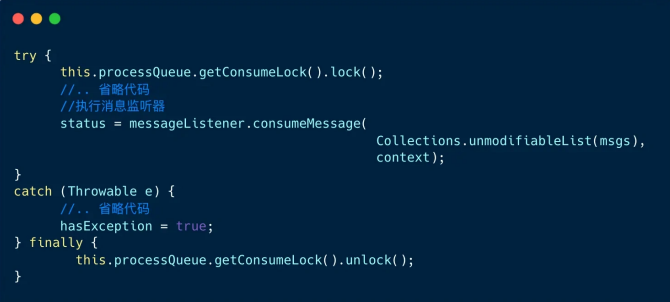
消费快照的消费锁 consumeLock 的作⽤是:防⽌负载均衡线程把当前消费的 MessageQueue 对象移除掉。
6、 处理消费结果
消费成功时,⾸先计算需要提交的偏移量,然后更新本地消费进度。
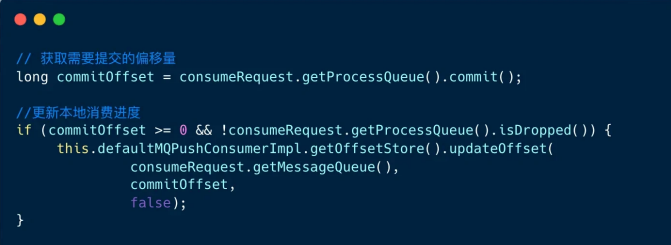
消费失败时,分两种场景:
- 假如已消费次数⼩于最⼤重试次数,则将对象 consumingMsgOrderlyTreeMap 中临时存储待消费的消息,重新加⼊到消费快照红⿊树 msgTreeMap 中,然后使⽤定时任务尝试重新消费。
- 假如已消费次数⼤于等于最⼤重试次数,则将失败消息发送到 Broker ,Broker 接收到消息后,会加⼊到死信队列⾥ , 最后计算需要提交的偏移量,然后更新本地消费进度。
我们做⼀个关于顺序消费的总结 :
1、 顺序消费需要由两个阶段消息发送和消息消费协同配合,底层⽀撑依靠的是 RocketMQ 的存储模型;
2、 顺序消费服务启动后,队列的数据都会被消费者实例单线程的执⾏消费;
3、 假如消费者扩容,消费者重启,或者 Broker 宕机 ,顺序消费也会有⼀定⼏率较短时间内乱序,所以消费者的业务逻辑还是要保障幂等。
5. 保存进度
RocketMQ 消费者消费完⼀批数据后, 会将队列的进度保存在本地内存,但还需要将队列的消费进度持久化。
1、 集群模式
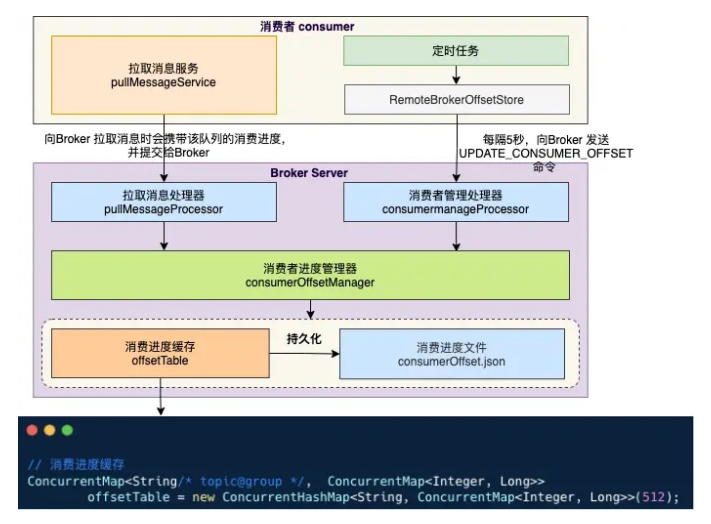
集群模式下,分两种场景:
- 拉取消息服务会在拉取消息时,携带该队列的消费进度,提交给 Broker 的拉取消息处理器。
- 消费者定时任务,每隔5秒将本地缓存中的消费进度提交到 Broker 的消费者管理处理器。
Broker 的这两个处理器都调⽤消费者进度管理器 consumerOffsetManager 的 commitOffset ⽅法,定时任务异步将消 费进度持久化到消费进度⽂件 consumerOffset.json 中。
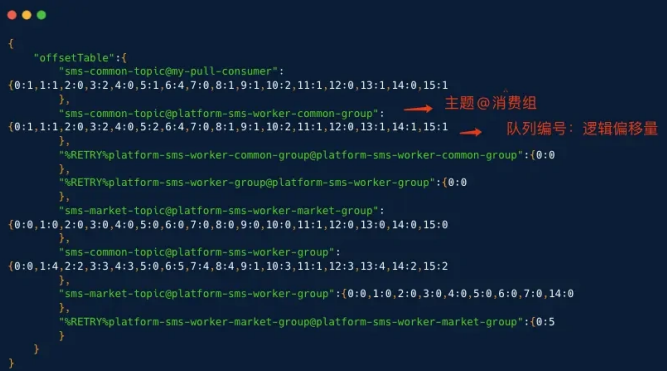
2、 ⼴播模式
⼴播模式消费进度存储在消费者本地,定时任务每隔 5 秒通过 LocalFileOffsetStore 持久化到本地⽂件 offsets.json ,数据格式为 MessageQueue:Offset 。
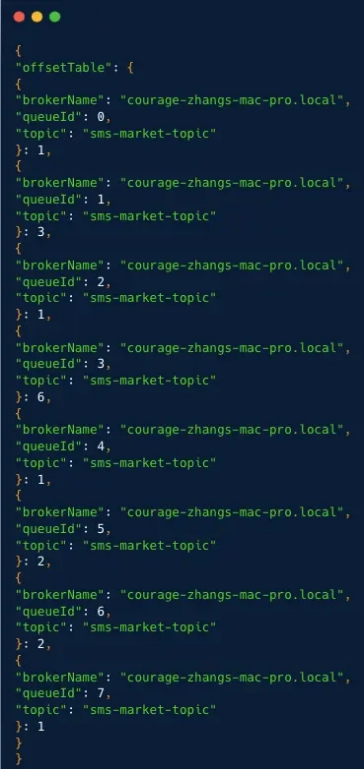
⼴播模式下,消费进度和消费组没有关系,本地⽂件 offsets.json 存储在配置的⽬录,⽂件中包含订阅主题中所有的队列以及队列的消费进度。
6. 重试机制
集群消费下,重试机制的本质是 RocketMQ 的延迟消息功能。
消费消息失败后,消费者实例会通过 CONSUMER_SEND_MSG_BACK 请求,将失败消息发回到 Broker 端。
Broker 端会为每个 topic 创建⼀个重试队列 ,队列名称是:%RETRY% + 消费者组名 ,达到重试时间后将消息投递到重 试队列中进⾏消费重试(消费者组会⾃动订阅重试 Topic)。最多重试消费 16 次,重试的时间间隔逐渐变⻓,若达到最⼤重试次数后消息还没有成功被消费,则消息将被投递⾄死信队列。
| 第几次重试 | 与上次重试的间隔时间 | 第几次重试 | 与上次重试的间隔时间 |
|---|---|---|---|
| 1 | 10s | 9 | 7min |
| 2 | 30s | 10 | 8min |
| 3 | 1min | 11 | 9min |
| 4 | 2min | 12 | 10min |
| 5 | 3min | 13 | 20min |
| 6 | 4min | 14 | 30min |
| 7 | 5min | 15 | 1h |
| 8 | 6min | 16 | 2h |
- SCHEDULE_TOPIC_XXX : 调度队列
- %RETRY%platform-sms-worker-market-group : 重试队列
- %DLQ%platform-sms-worker-market-group : 死信队列
开源 RocketMQ 4.9.X ⽀持延迟消息,默认⽀持18 个 level 的延迟消息,这是通过 broker 端的 messageDelayLevel 配 置项确定的,如下:
1 | messageDelayLevel = 1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h |
Broker 在启动时,内部会创建⼀个内部主题:SCHEDULE_TOPIC_XXXX,根据延迟 level 的个数,创建对应数量的队 列,也就是说18个 level 对应了18个队列。
我们先梳理下延迟消息的实现机制。
1、⽣产者发送延迟消息
1 | Message msg = new Message(); |
2、Broker端存储延迟消息 延迟消息在 RocketMQ Broker 端的流转如下图所示:
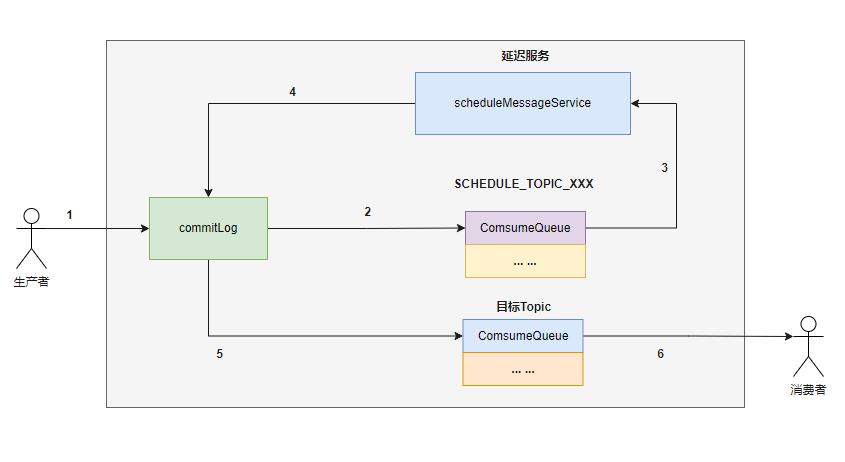
第⼀步:修改消息 Topic 名称和队列信息
Broker 端接收到⽣产者的写⼊消息请求后,⾸先都会将消息写到 commitlog 中。假如是正常⾮延迟消息, MessageStore 会根据消息中的 Topic 信息和队列信息,将其转发到⽬标 Topic 的指定队列 consumequeue 中。
但由于消息⼀旦存储到 consumequeue 中,消费者就能消费到,⽽延迟消息不能被⽴即消费,所以 RocketMQ 将 Topic 的名称修改为SCHEDULE_TOPIC_XXXX,并根据延迟级别确定要投递到哪个队列下。
同时,还会将消息原来要发送到的⽬标 Topic 和队列信息存储到消息的属性中。
1 | public CompletableFuture<PutMessageResult> asyncPutMessage(final MessageExtBrokerInner msg) { |
第⼆步:构建 consumequeue ⽂件时,计算并存储投递时间
1 | public DispatchRequest checkMessageAndReturnSize(java.nio.ByteBuffer byteBuffer, final boolean checkCRC, |
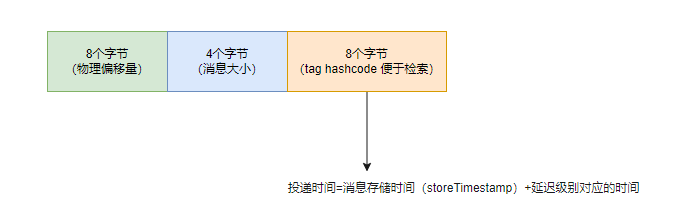
上图是 consumequeue ⽂件⼀条消息的格式,最后 8 个字节存储 Tag 的哈希值,此时存储消息的投递时间。
第三步:定时调度服务启动
ScheduleMessageService 类是⼀个定时调度服务,读取 SCHEDULE_TOPIC_XXXX 队列的消息,并将消息投递到⽬标 Topic 中。
定时调度服务启动时,创建⼀个定时调度线程池 ,并根据延迟级别的个数,启动对应数量的 HandlePutResultTask ,每个 HandlePutResultTask 负责⼀个延迟级别的消费与投递。
1 | if (started.compareAndSet(false, true)) { |
第四步:投递时间到了,将消息数据重新写⼊到 commitlog 消息到期后,需要投递到⽬标 Topic 。第⼀步已经记录了原来的 Topic 和队列信息,这⾥需要重新设置,再存储到 commitlog 中。
第五步:将消息投递到⽬标 Topic 中 Broker 端的后台服务线程会不停地分发请求并异步构建 consumequeue(消费⽂件)和 indexfile(索引⽂件)。因此消息会直接投递到⽬标 Topic 的 consumequeue 中,之后消费者就可以消费到这条消息。
回顾了延迟消息的机制,消费消息失败后,消费者实例会通过 CONSUMER_SEND_MSG_BACK 请求,将失败消息发回到 Broker 端。
Broker 端 SendMessageProcessor 处理器会调⽤ asyncConsumerSendMsgBack ⽅法。
1 |
|
⾸先判断消息的当前重试次数是否⼤于等于最⼤重试次数,如果达到最⼤重试次数,或者配置的重试级别⼩于0,则重新创建 Topic ,规则是 %DLQ% + consumerGroup,后续处理消息发送到死信队列。
正常的消息会进⼊ else 分⽀,对于⾸次重试的消息,默认的 delayLevel 是 0 ,RocketMQ 会将 delayLevel + 3,也就是 加到 3 ,这就是说,如果没有显示的配置延时级别,消息消费重试⾸次,是延迟了第三个级别发起的重试,也就是距离⾸次发送 10s 后重试,其主题的默认规则是 %RETRY% + consumerGroup。
当延时级别设置完成,刷新消息的重试次数为当前次数加 1 ,Broker 端将该消息刷盘,逻辑如下:
1 | MessageExtBrokerInner msgInner = new MessageExtBrokerInner(); |
延迟消息写⼊到 commitlog ⾥ ,这⾥其实和延迟消息机制的第⼀步类似,后⾯按照延迟消息机制的流程执⾏即可(第⼆步到第六步)。
7. 总结
下图展示了集群模式下消费者并发消费流程 :
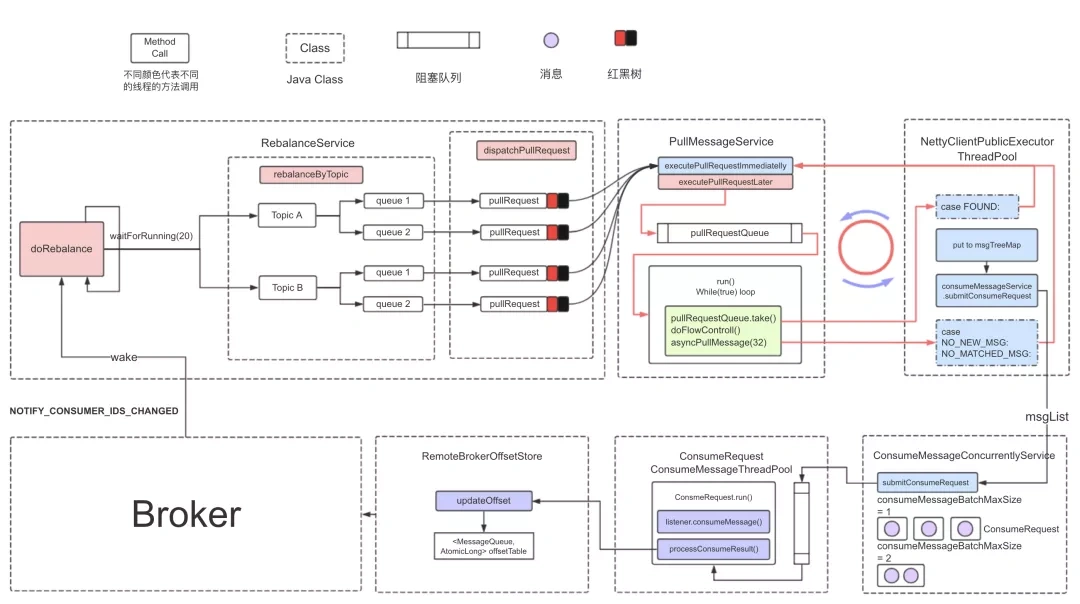
核⼼流程如下:
1、消费者启动后,触发负载均衡服务 ,负载均衡服务为消费者实例分配对应的队列 ;
2、分配完队列后,负载均衡服务会为每个分配的新队列创建⼀个消息拉取请求 pullRequest , 拉取请求保存⼀个处理 队列 processQueue ,内部是红⿊树( TreeMap ),⽤来保存拉取到的消息 ;
3、拉取消息服务单线程从拉取请求队列 pullRequestQueue 中弹出拉取消息,执⾏拉取任务 ,拉取请求是异步回调 模式,将拉取到的消息放⼊到处理队列;
4、拉取请求在⼀次拉取消息完成之后会复⽤,重新被放⼊拉取请求队列 pullRequestQueue 中 ;
5、拉取完成后,调⽤消费消息服务 consumeMessageService 的 submitConsumeRequest ⽅法 ,消费消息服务内 部有⼀个消费线程池;
6、消费线程池的消费线程从消费任务队列中获取消费请求,执⾏消费监听器 listener.consumeMessage ;
7、消费完成后,若消费成功,则更新偏移量 updateOffset ,先更新到内存 offsetTable ,定时上报到 Broker ; 若消费失败,则将失败消费发送到 Broker 。
8、Broker 端接收到请求后, 调⽤消费进度管理器的 commitOffset ⽅法修改内存的消费进度,定时刷盘到 consumerOffset.json 。
RocketMQ 4.9.X 的消费逻辑有两个⾮常明显的特点:
- 客户端代码逻辑较重。假如要⽀持⼀种新的编程语⾔,那么客户端就必须实现完整的负载均衡逻辑,此外还需要实现拉消息、位点管理、消费失败后将消息发回 Broker 重试等逻辑。这给多语⾔客户端的⽀持造成很⼤的阻碍。
- 保证幂等⾮常重要。当客户端升级或者下线时,或者 Broker 宕机,都要进⾏负载均衡操作,可能造成消息堆积, 同时有⼀定⼏率造成重复消费。