1. 性能瓶颈
很多系统最开始都是单数据库架构。
面对越来越大的业务流量时,系统层面就会有瓶颈,体现在如下两点:
- 数据库瓶颈显现。频繁的磁盘操作导致数据库服务器 IO 消耗增加,同时多表关联,排序,分组,非索引字段条件查询也会让 cpu 飙升,最终都会导致数据库连接数激增;
- 网关大规模超时。在高并发场景下,大量请求直接操作数据库,数据库连接资源不够用,大量请求处于阻塞状态。
为了缓解主数据库的压力,很容易就想到的策略:SQL 优化。
- 合理添加索引;
- 减少多表 JOIN 关联,通过程序组装,减少数据库读压力;
- 减少大事务,尽快释放数据库连接。
另外一个策略是:读写分离。
读写分离可以减少主库写压力,同时读从库可水平扩展。当然,读写分离依然有局限性:
- 读写分离可能面临主从延迟的问题,不太适合实时性要求较高的场景;
- 读写分离可以缓解读压力,但是写操作的压力随着业务爆发式的增长并没有很有效的缓解。
分库分表就是 海量数据下,为了解决单库、表数据量过大,导致数据库性能持续下降的问题,演变出的技术方案。
2. 基本概念
分库和分表是两个概念,但通常会把它们合在一起简称为分库分表。所谓分库分表,业界并没有一个统一的定义,你可以简单理解为:
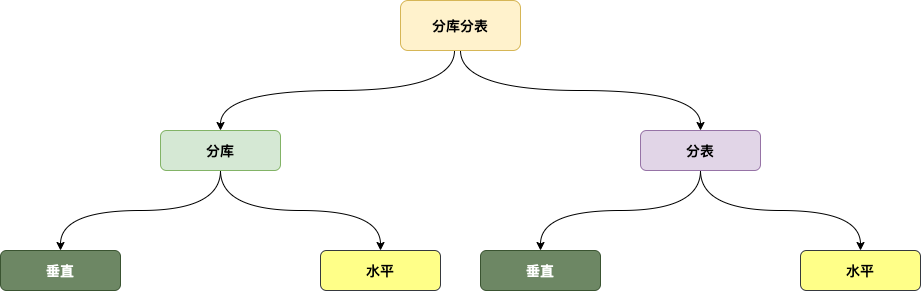
分库分表分为分库和分表两个维度,在开发过程中,对于每个维度都可以采用两种拆分思路,即 垂直拆分 和 水平拆分
3. 分库维度
3.1 垂直分库
垂直分库通常根据业务和功能的维度进行拆分,将不同业务数据分别存储在不同的数据库中,遵循核心理念“专库专用”。
按照业务类型对数据进行分离,将相关表放置在相应的数据库中,例如订单库、支付库、会员库和促销库等。
同时,将服务进行拆分,比如订单服务、支付服务、会员服务等,不同服务禁止跨库直连,而是通过 API 接口或者远程 RPC 进行数据交互。
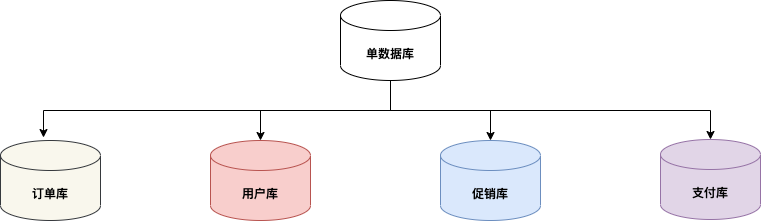
垂直分库可以有效将一个数据库的压力分散到多个库中,从而提升整体系统的吞吐。
然而,垂直分库并不能完全解决某一业务表(比如电商订单表)数据量过大,单库查询和写入性能急剧下降的问题,我们可以采用水平分库的方案。
3.2 水平分库
水平分库是将同一个表按照特定规则拆分到不同的数据库中,每个数据库可以位于不同的服务器上。
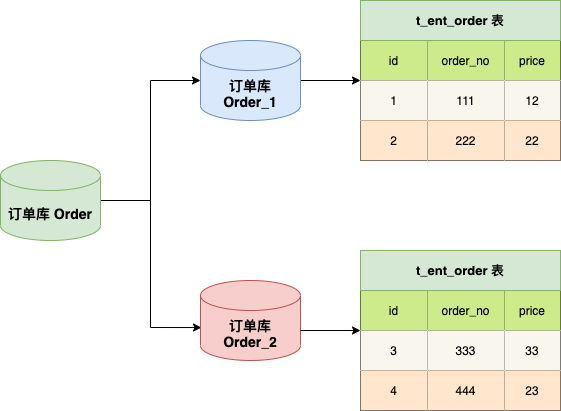
图中我们将订单库拆分成两个数据库,两个库内有完全相同的订单表 t_ent_order ,我们在访问某一笔订单时可以通过对订单的订单编号取模的方式 订单编号 mod 2 (数据库实例数) ,指定该订单应该在哪个数据库中操作。
假如订单表一共有 1 亿条,拆分到 8 个订单库中,那么每个库存储 1000 多万条,相比单库来讲,订单服务的性能能大幅提升。
4. 分表维度
4.1 垂直分表
垂直分表针对业务上字段比较多的大表进行的,一般是把业务宽表中比较独立的字段,或者不常用的字段拆分到单独的数据表中,是一种大表拆小表的模式。
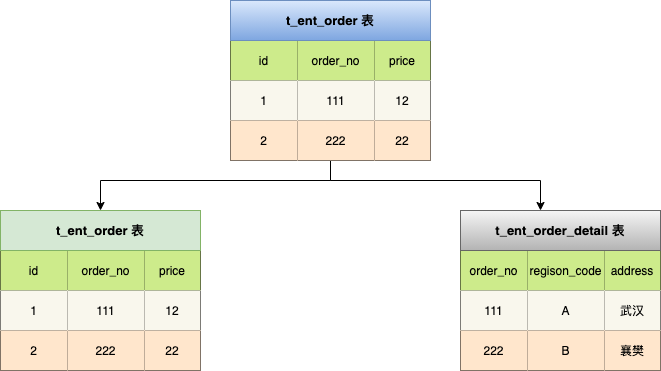
我们可以将订单表按照业务领域拆分成两个表,本别是订单信息核心表和订单详情表。
数据库它是以行为单位将数据加载到内存中,这样拆分以后核心表大多是访问频率较高的字段,而且字段长度也都较短,因而可以加载更多数据到内存中,减少磁盘 IO ,增加索引查询的命中率,进一步提升数据库性能。
4.2 水平分表
水平分表是在 同一个数据库内,把一张大数据量的表按一定规则,切分成多个结构完全相同表,而每个表只存原表的一部分数据。
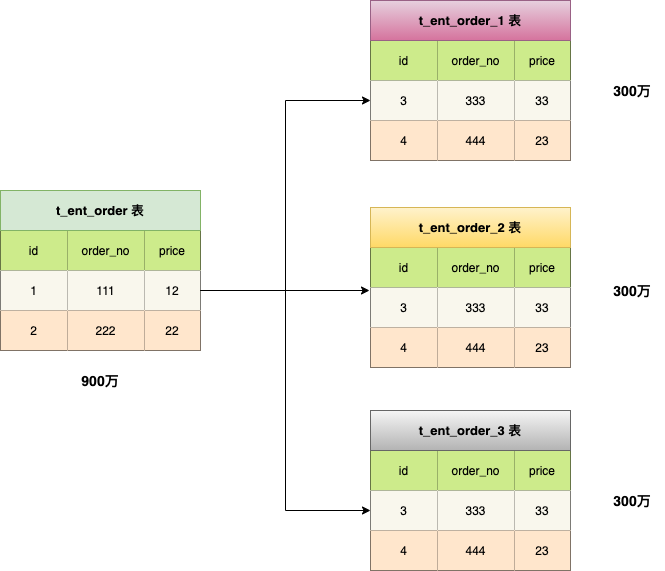
订单表有 900 万数据,水平拆分出来三个表,t_ent_order_1、t_ent_order_2、t_ent_order_3 ,每张表存储 300 万条。
5. 选择分库还是分表
写到这里,有的读者肯定会问:什么时候选择分库,什么时候选择分表呢 ?
5.1 分库
提升数据库实例的磁盘存储容量、支撑更多的数据库连接,最终大幅度提升数据的写入和读取 (磁盘 IO 指标)。
分库会增加服务器成本和运维成本,需要考虑性价比。
5.2 分表
减少单表的存储容量,提升数据的查询效率,并没有将拆分后的表分散到不同的物理机器上。这些子表仍然在竞争同一个物理机的 CPU、内存、网络 IO 等资源,依然存在性能上限。
分表的优势很明显,操作简单,不会增加服务器成本,运维成本有一定增加。
因此在真实场景中,我们是根据实际场景 混合使用:
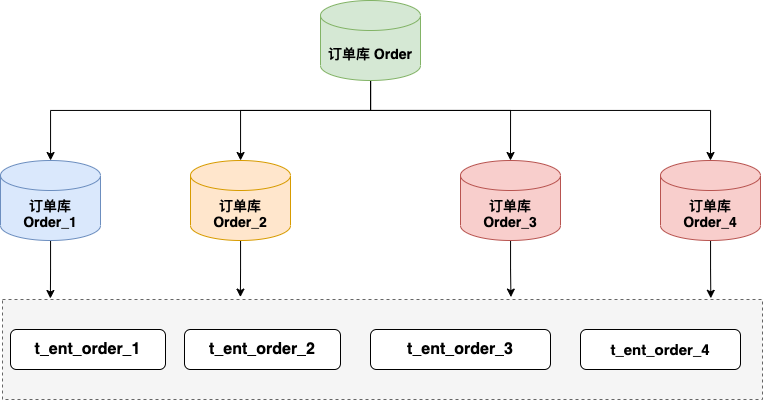
图中,我们将订单库拆分四个订单库实例,每个订单库都包含四个订单分表。这种分库分表策略可以大幅提升订单服务的性能,同时也可以充分利用数据库资源。
6. 代理模式和客户端模式
分库分表架构分为两种模式:客户端模式 和 代理模式。
6.1 客户端模式
在客户端模式下,分库分表的逻辑完全由系统应用内部控制。应用直接连接多个数据库执行拆分后的 SQL 操作,然后在本地进行数据的合并和汇总等操作。
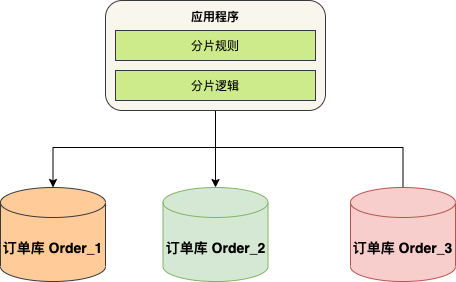
应用层分片方案业界有 sharding-jdbc ,TDDL 等。
它的优点:直连数据库,额外开销小,实现简单,轻量级中间件。缺点:无法减少连接数消耗,有一定的侵入性,多数只支持 Java 语言。
6.2 代理模式
代理模式将应用程序与 MySQL 数据库隔离,业务方的应用不在需要直连数据库,而是连接代理服务,代理服务实现了 MySQL 的协议,对业务方来说代理服务就是数据库,它会将 SQL 分发到具体的数据库进行执行,并返回结果。
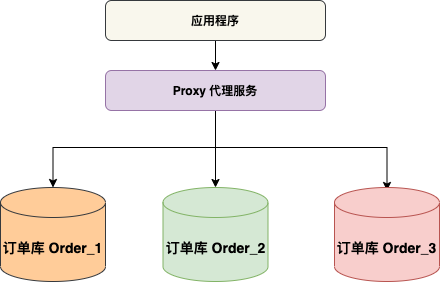
代理层分片方案业界有 Mycat ,Cobar,ShardingSPhere Proxy 等 。
它的优点:应用零改动,和语言无关,可以通过连接共享减少连接数消耗。缺点:因为是代理层,存在额外的时延。
7. 分库分表缺点
分库分表本质上是为了解决数据的写入和读取性能,但也带来了复杂性,主要体现在如下几点:
7.1 跨库关联查询
在数据切分之前,应用可以通过 SQL 的 JOIN 操作关联多张表查询数据,但引入分库分表之后,数据可能分布在不同的数据库节点上,那么如何 JOIN 呢 ?
字段冗余: 在每个分片中冗余存储关联表的部分数据,尽量包含查询中所需的字段,以避免跨分片进行 JOIN 操作。
全局表: 创建一个全局表,其中包含所有分片中的关键信息。这个全局表可能包含一些通用的、经常需要联合查询的数据。这样,在某些情况下,应用可以直接在全局表中查询,而不需要进行 JOIN 操作。
应用层组装: 在应用层,通过业务逻辑进行数据的组装。当查询涉及到多个分片时,应用层负责获取并组装分片中的数据,避免在数据库层进行复杂的 JOIN 操作。
7.2 分布式事务
单数据库可以使用本地事务,一旦涉及到多数据库,也就只能通过分布式事务来解决。
常用解决方案有:基于可靠消息(MQ)的解决方案、两阶段事务提交、柔性事务等。
7.3 排序、分页、函数计算问题
跨节点多库进行查询时,会出现 limit 分页、order by 排序等问题。分页需要按照指定字段进行排序,当排序字段就是分片字段时,通过分片规则就比较容易定位到指定的分片;当排序字段非分片字段时,就变得比较复杂了。需要先在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序,最终返回给用户。
7.4 分布式 ID
常见的分布式 ID 算法:UUID、雪花算法、百度 uid-generator 、美团 Leaf、滴滴 Tinyid 。