1 全量同步工具
同步组件工具地址:
https://github.com/makemyownlife/shardingsphere-jdbc-demo/tree/main/swift-data-transfer/data-sync
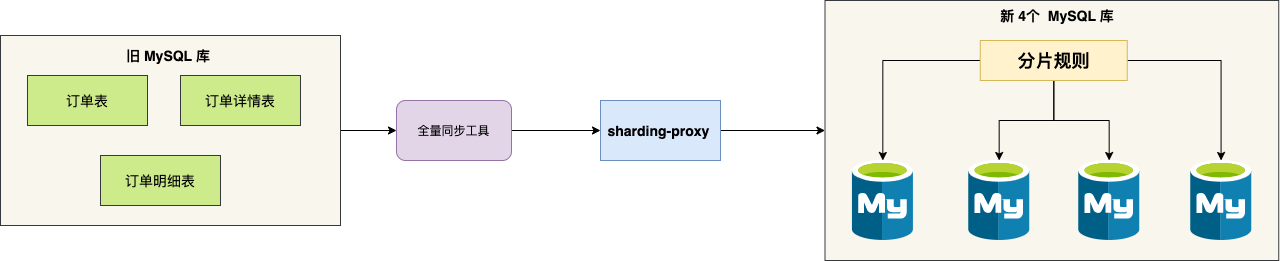
如图中,同步组件会将老订单库的三张表的数据通过 shardingsphere-proxy 数据桥梁均匀分布到新的 4 个 订单 MySQL 库里。
2 实战演示
首先,我们编辑配置文件:
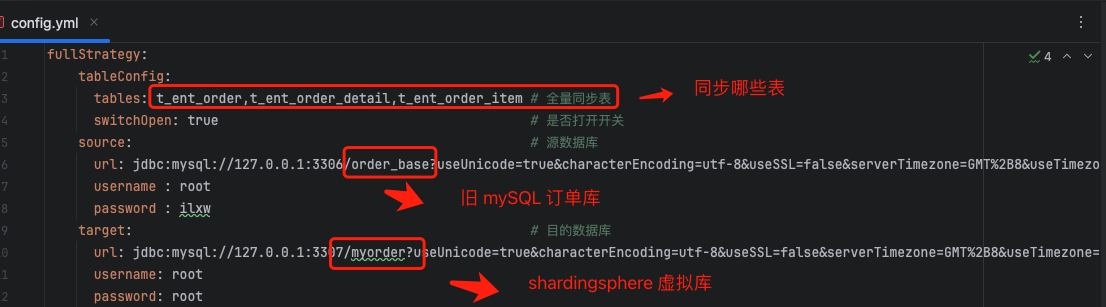
配置文件包含三个元素:
- 同步表:哪些表需要同步
- 源数据源:旧 MySQL 订单库
- 目标数据源:shardingsphere-proxy 虚拟库 (背后是 4 个 MySQL 新分库)
然后启同步服务 Main 函数 :
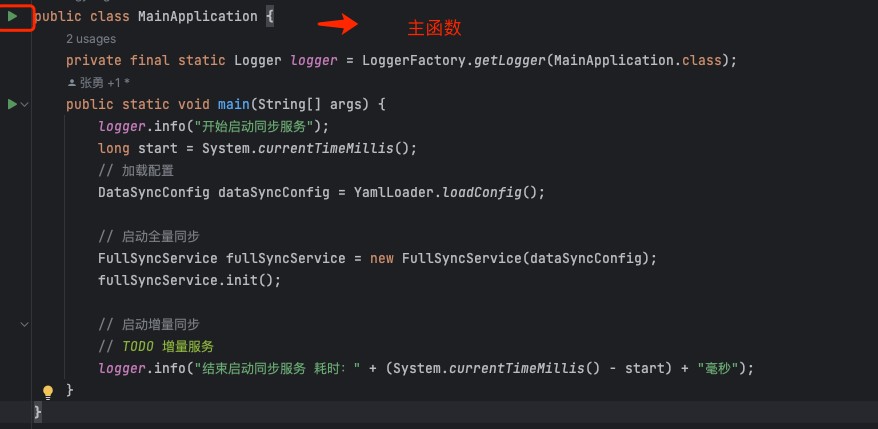
启动成功之后,我们可以看到表的执行结果:

3 组件原理
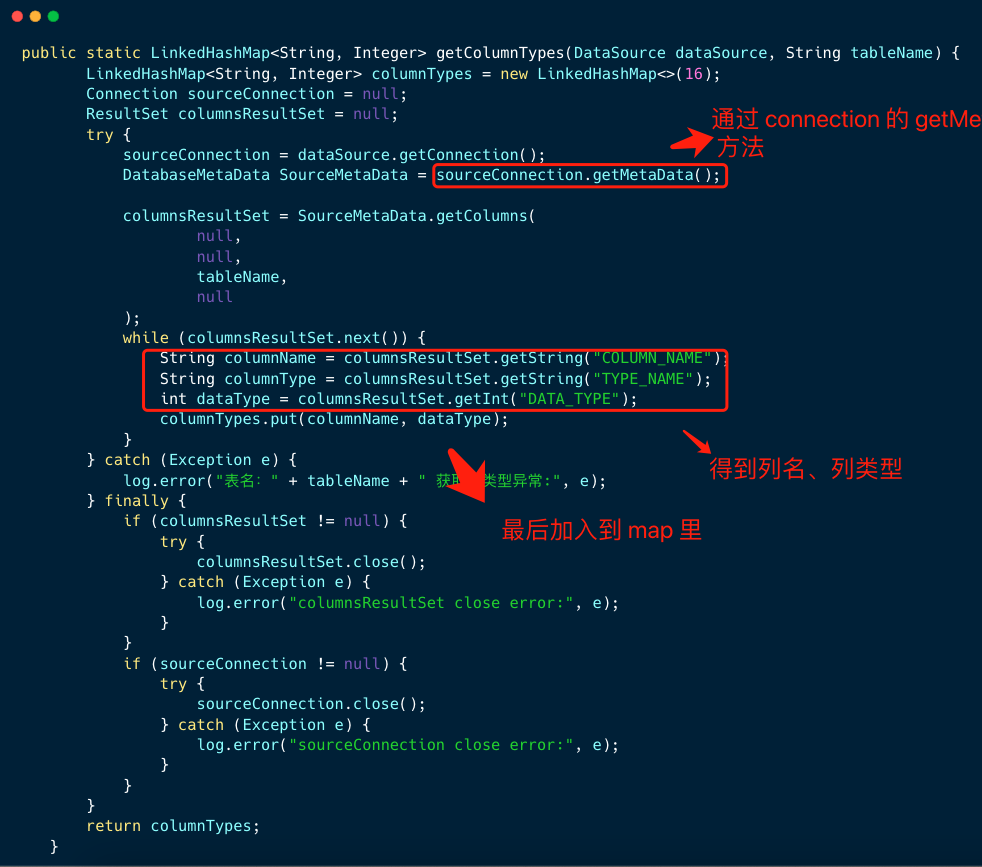
1、获取表的元数据
因此最终我们需要将表的数据 insert 到目标数据库,所以,我们必须知道表包含了哪些列,以及列对应的类型。
1 | LinkedHashMap<String, Integer> columnTypes = Utils.getColumnTypes(sourceDataSource, tableName); |
在 Utils 工具类里,定义 getColumnTypes 方法:
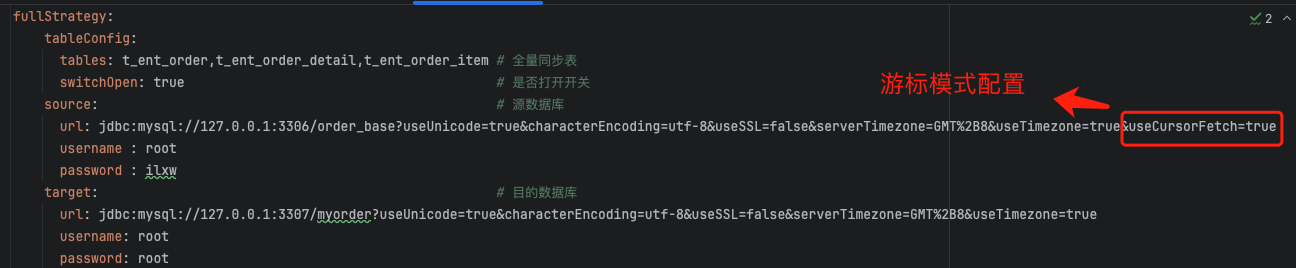
2、执行 SQL 语句(游标模式)

首先我们获取源数据源的 JDBC 连接,然后通过预编译执行查询语句 , 预编译定义为游标模式。
为了满足游标模式,我们在 JDBC url 连接需要如下配置:
3、得到源数据库查询结果集
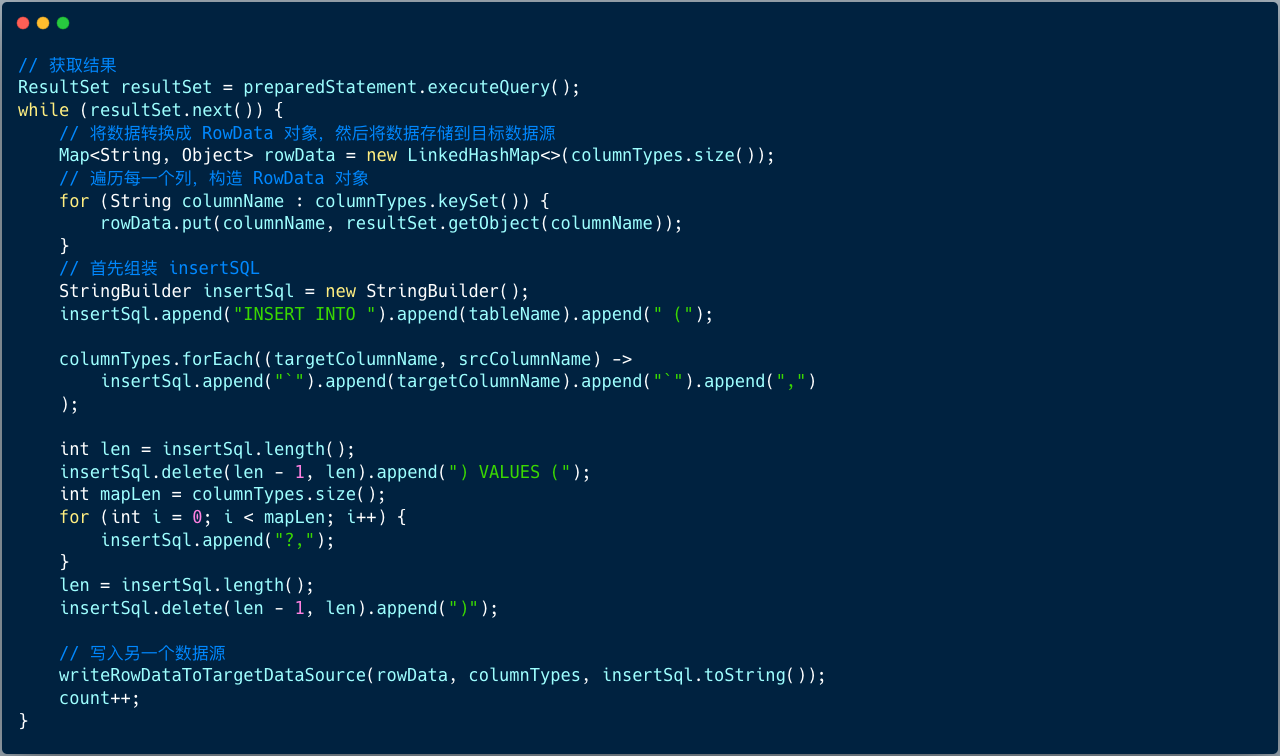
开始执行查询 SQL 后, 得到结果集,并遍历结果集,让结果集中的数据插入到 目标数据库表。
这里面分为三个步骤:
- 将数据转换成 RowData 对象
- 组装 Insert SQL
- 写入到另一个数据源
4、将数据转换成 RowData 对象

5、组装 Insert SQL
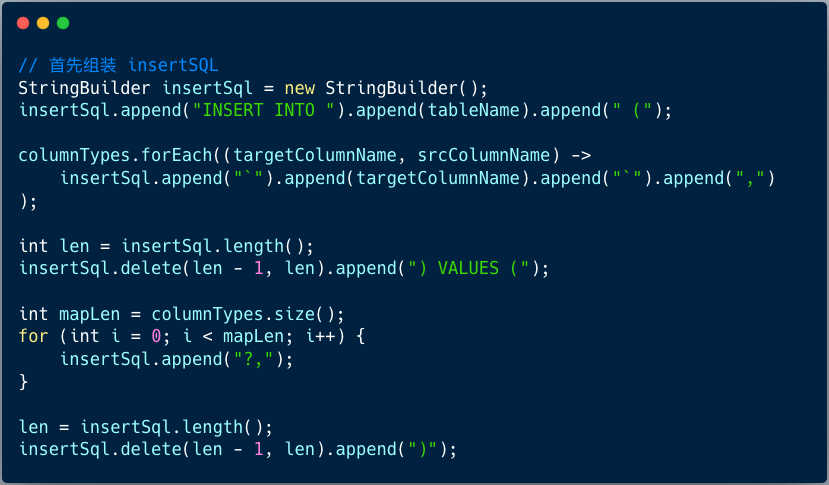
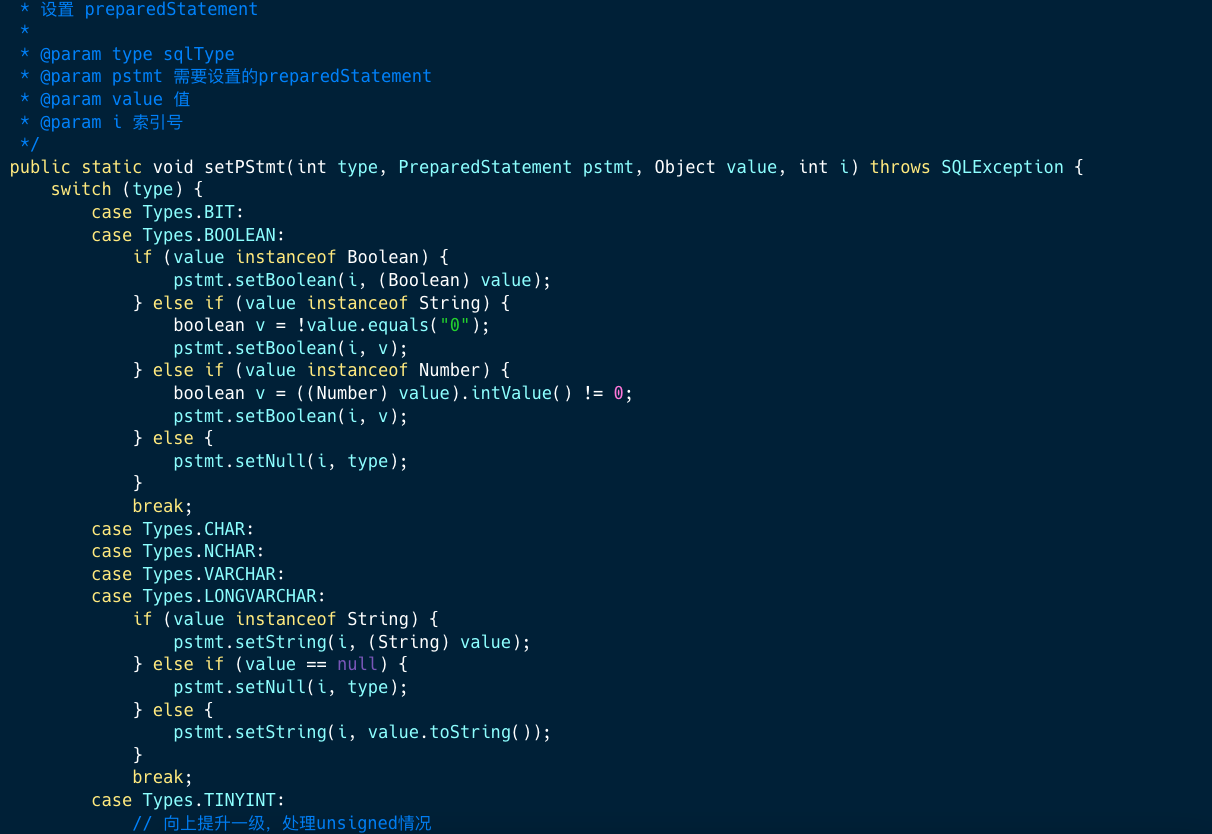
6、写入到目标数据源表

这一段是非常典型的 JDBC 执行 UPDATE 写法,最核心的如何动态赋值。
以下是动态赋值部分代码截图:
4 思维升级
写到这里,我们展示了如何简单设计一个全量同步的工具。
但还是非常粗糙,还需要从如下几点进行优化:
- 任务模型:可否并行支持多个任务并行处理
- checkpoint 机制: 当任务执行时,假如突发宕机或者线程执行异常,需要保存执行点,以便下次调度重新执行
- 更灵活的 ETL 机制