1. 分片键
分片键也称为 Sharding key,是数据库拆分时的关键字,也就是你以哪个维度来分库分表的,比如你按用户 ID 分片、按时间分片、按地区分片,那么用户 ID 、时间、地区就是分片键。
理论上讲:分片字段应具有高度离散的特点,而且分片键的值不能被更新。因为更换分片键需重分布数据,代价非常大。
分片键的选择建议:
- 选择具有共性的字段作为分片键,即查询中高频出现的条件字段;
- 可均匀各分片的数据存储和读写压力,避免片内出现热点数据;
- 使用分库分表时,建议所有 SQL 语句的查询条件都能携带分片键,这样可以达到最高的执行效率,避免 SQL 广播。
- 同一个业务中心的表,按照同一个维度进行数据拆分,比如订单中心,都按照用户 ID 进行分片,每次对订单进行操作的时候,都是在单节点上执行,这样可以最大程度减少分布式事务、分布式 JOIN 的情况,降低系统负载。
2. 分片算法
2.1 哈希分片
哈希分片是指:对某个字段进行哈希计算,然后根据哈希值将数据映射到不同的库或表。
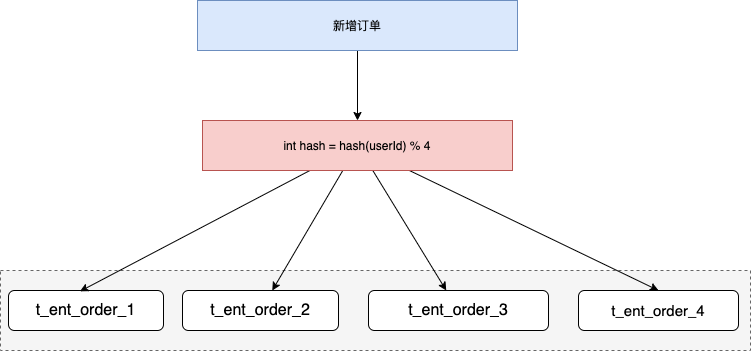
海量数据库高并发的 OLTP 业务中,选择 Hash 算法相对更合适,它会将数据相对均匀的分布在各分片中,可有效规避热点问题。
2.2 范围分片
范围分片是指:根据某个字段的数值范围将数据分布到不同的库或表中,比如可以根据订单创建时间的范围将订单数据分布到不同的数据库或表中。
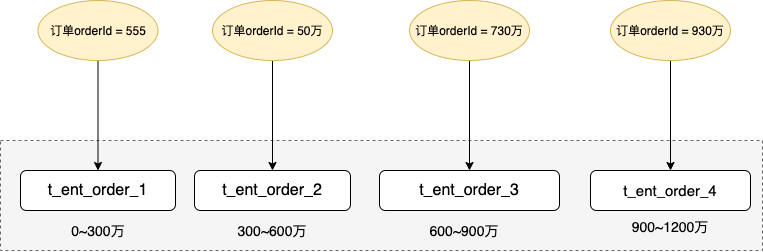
按照字段的取值范围对数据进行分片,对于范围条件的数据检索有较高的性能优势,基于 Range 的分片扩容也非常容易。
在分布式架构中,Range 相对 Hash 没有那么通用化,热点问题是最大的劣势,它适合数据体量较大且并发不高的场景,比如离线检索。
3. 基因法
基因法说明
基因替换(拼接)法:
目的:通过分片算法将一个用户的所有数据放入一张表;
通过用户id或者通过订单id都能够路由到一张表内。
原理举个例子说明:189%16 = 13 (189对16取余数)
其中:189 对应二进制:10111101
13 对应二进制:1101
将1101这个基因拼接到任意一个订单二进制数的后四位,对16取余数结果都是13.
举例说明:订单id:90123456,90123457,90123458;用户id:29;分表数:16
90123456%16=0、90123457%16=1、90123458%16=2;如果不对订单id加以改造,一个客户的订单会路由到不同的表;
29%16=13;客户id为29的订单都会路由到table_13中。
如何做也能够“按照订单id路由”也能将一个客户的订单路由到同一个表呢?
使用13的二进制1101连接到订单id二进制后面
| 原始订单id | 对16取余 | 二进制 | 将1101拼接到二进制后面 | 基因拼接后的订单id | 对16取余 |
|---|---|---|---|---|---|
| 90123456 | 0 | 101010111110010110011000000 | 1010101111100101100110000001101 | 720987661 | 13 |
| 90123457 | 1 | 101010111110010110011000001 | 1010101111100101100110000011101 | 1441975325 | 13 |
| 90123458 | 2 | 101010111110010110011000010 | 1010101111100101100110000101101 | 1441975341 | 13 |
缺点:
1、本质还是取模,一旦扩容就要迁移数据
2、容易生成重复订单号
我们来思考一个电商场景中,使用订单 ID 和买家 ID 查询数据的问题。
用户下单后,经常需要查看订单信息,那么我们选择使用订单 ID 作为分片键是并没有什么问题。因为查询订单信息时,查询参数包含 订单 ID , 通过分库分表组件可以直接路由到对应的分片,查询效率很高。
但假如我们通过 APP 来查询自己的订单时,查询条件变为了分片键之外的买家 ID,默认情况下,查询语句中不带有分片键会导致全路由情况。
面对这样的情况,应如何设计一个高效的分片策略?
大厂常常使用的方案是基因法,即将买家 ID 融入到订单 ID 中,作为订单 ID 后缀。
这样,指定买家的所有订单就在同一分片内了,如下图所示。
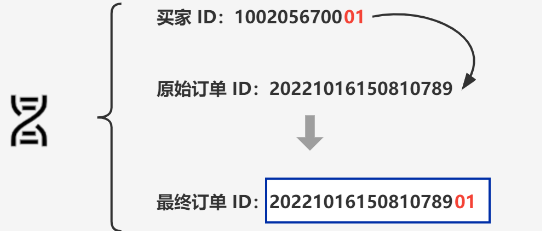
最终订单 ID:原始订单 ID + 买家 ID % 100 –>2022101615081078901
首先订单数据按照买家 ID 进行分片,我们在创建订单 ID 时,将买家 ID 融入到订单 ID 中。当通过订单 ID 查询时,可以查询出融入的买家 ID 信息,从而确定路由到哪个分片。
4. 广播表
业务中存在一些配置表,存储重要的配置,读多写少。在实际业务查询中,很多业务表会和配置表进行联合数据查询。
但在数据库水平拆分后,配置表是无法拆分的。
因此,分库分表组件提供了小表广播功能,支持配置表同步至目标数据库的所有分库。
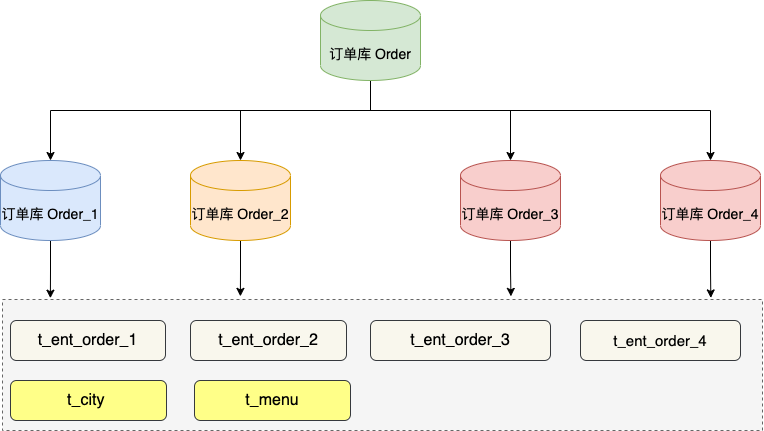
图中,订单库分了四个库,同时每个库中分了四张订单表,因为需要关联城市表 t_city ,所以每个库中都包含这些配置表。
每个库的配置表数据都是一样的,可以通过分库分表组件的广播机制同步,也可以业务自己写异构组件来实现。
小表广播可以解决业务表和配置表进行联合数据查询,需要跨库的问题