1. 例子准备
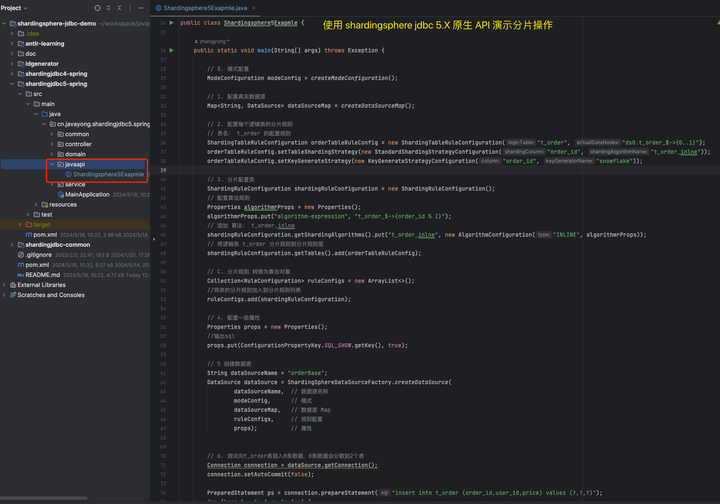
首先我们在项目中新建一个 Java 类 Shardingsphere5Exapmle 用来演示 shardingsphere 5.X 原生 API 演示分片操作。
然后创建一个数据库 sj_ds0 ,然后执行 doc 目录下的 演示 SQL 。
执行完成之后,数据库显示如下:
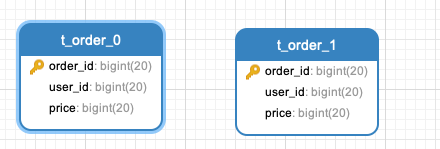
接下来,我们从源码角度解析例子的分片流程,分片规则是单数据内,订单表按照 order_id 进行分表。
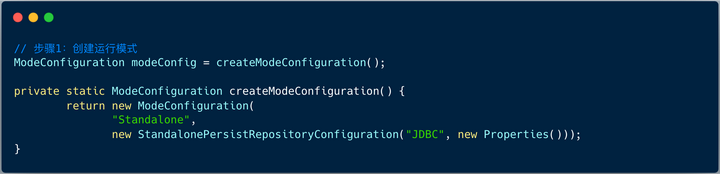
2. 模式配置
shardingsphere 的运行模式包含:Standalone 模式 和 Cluster 模式 。
对于 JDBC 分片来讲,我们选择默认 Standalone 模式即可。
3. 数据源Map
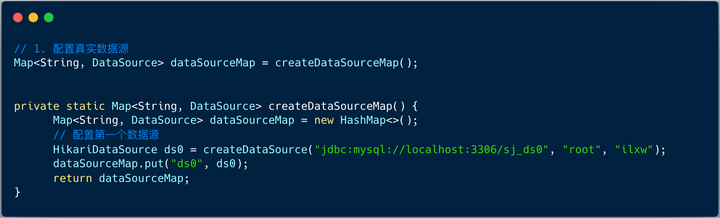
我们发现这里的配置和 shardingsphere jdbc 4.X 相同 ,数据源 HashMap 的 key 是数据源的别名,在后面的分片规则里会用到。
4. 逻辑表t_order分片配置
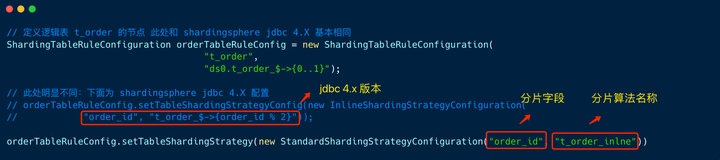
和 shardingsphere jdbc 4.X 明显不同的是,定义逻辑表 t_order 分片规则时,需要指定 分片字段和分片算法名称。
大家也可以这么理解:每个逻辑表的分片算法都被独立出来配置了。
5. 定义分片规则配置对象
首先定义了分片规则配置对象 shardingRuleConfiguration , 该对象包含所有逻辑表的分片规则。
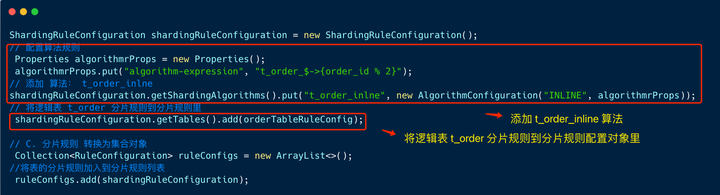
然后定义逻辑表 t_order 的分片算法,算法名称是:t_order_inline 。
最后,将分片规则配置对象 shardingRuleConfiguration 组装到一个分片规则对象集合里,之所以是集合,是因为整体的分片规则可能包括广播分片、绑定表等配置。
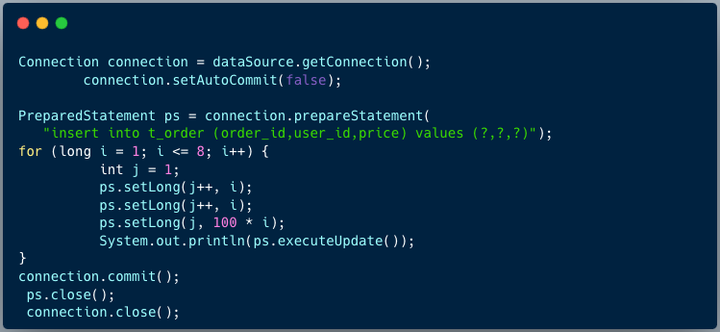
6. 定义数据源

这里的配置和 shardingsphere jdbc 4.X 还是有差别的 ,需要定义数据源名称、运行模式 。
接下来, 获取连接,测试向 t_order 表插入8条数据,8条数据会分散到2个表 。
7. 总结
shardingsphere jdbc 5.x 的原生 API 和 jdbc 4.x 差别还是非常大的,第一次使用还是会有很多坑。
笔者思考 shardingsphere 之所以这么设计,原因有如下两点:
1、运行模式扩展,比如 proxy 模式支持集群模式运行 ,这是完善生态的一种表现 ;
2、支持将分片配置独立出来,并且可以配置分片算法的属性,这样可以更加灵活。
演示代码地址: