1. 普通分页查询
首先我们想到的是:通过分页查询 t_ent_order 表中的数据,并按 id 升序排列,每次查询最多返回 1000 条记录 (即分页大小是 1000 条) 。
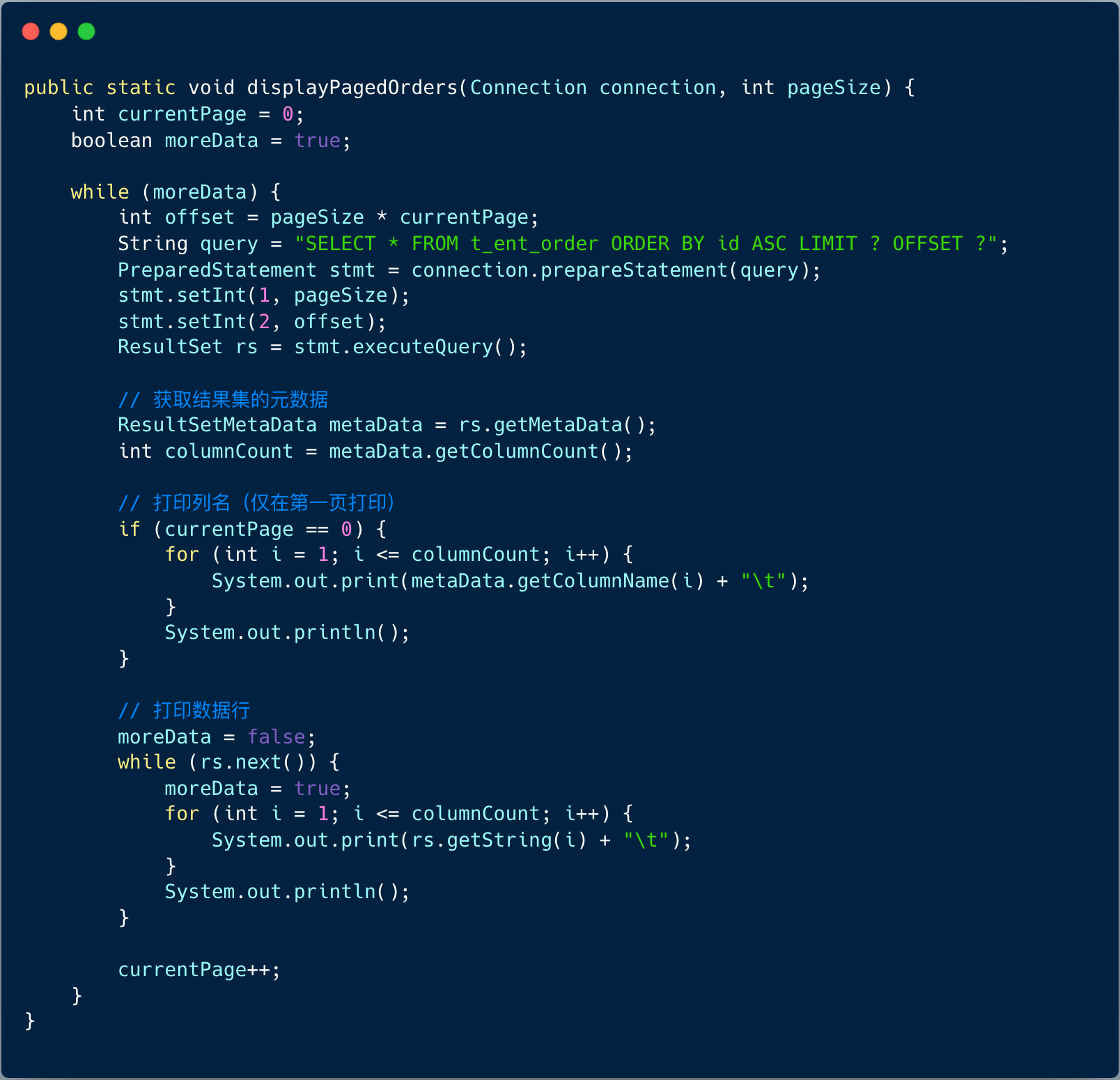
该代码核心要点如下:
1、查询逻辑:每次分页查询都会根据当前页码计算偏移量,offset 由 pageSize * currentPage 得到。
2、按照订单 id 升序:之所以必须添加排序,是为了避免在查询过程中,出现的数据重复。
3、分页控制: 通过 moreData 属性控制循环,判断是否还有更多数据,若当前分页查询没有返回数据,则停止循环。
我们都知道,当表数据量非常大,随着页码的不断增加,数据库需要扫描和跳过更多的行。这意味着查询会变得越来越慢。
例如,LIMIT 10 OFFSET 1000000 需要扫描和跳过前 1000000 行,然后再返回 10 行,这会消耗大量的 数据库 CPU 和 IO 资源。
因此,普通分页查询适合数据量较少的全量查询场景,建议数量级在100 万条以内。
2. 主键分页查询
使用普通分页方式时,没有办法使用到主键索引,我们可以借助主键 id 天然索引的特性 ,通过记录每次查询结果的最后一条记录的主键值,在下一次查询时使用这个值进行分页,从而避免了 OFFSET 带来的性能问题。

示例代码:
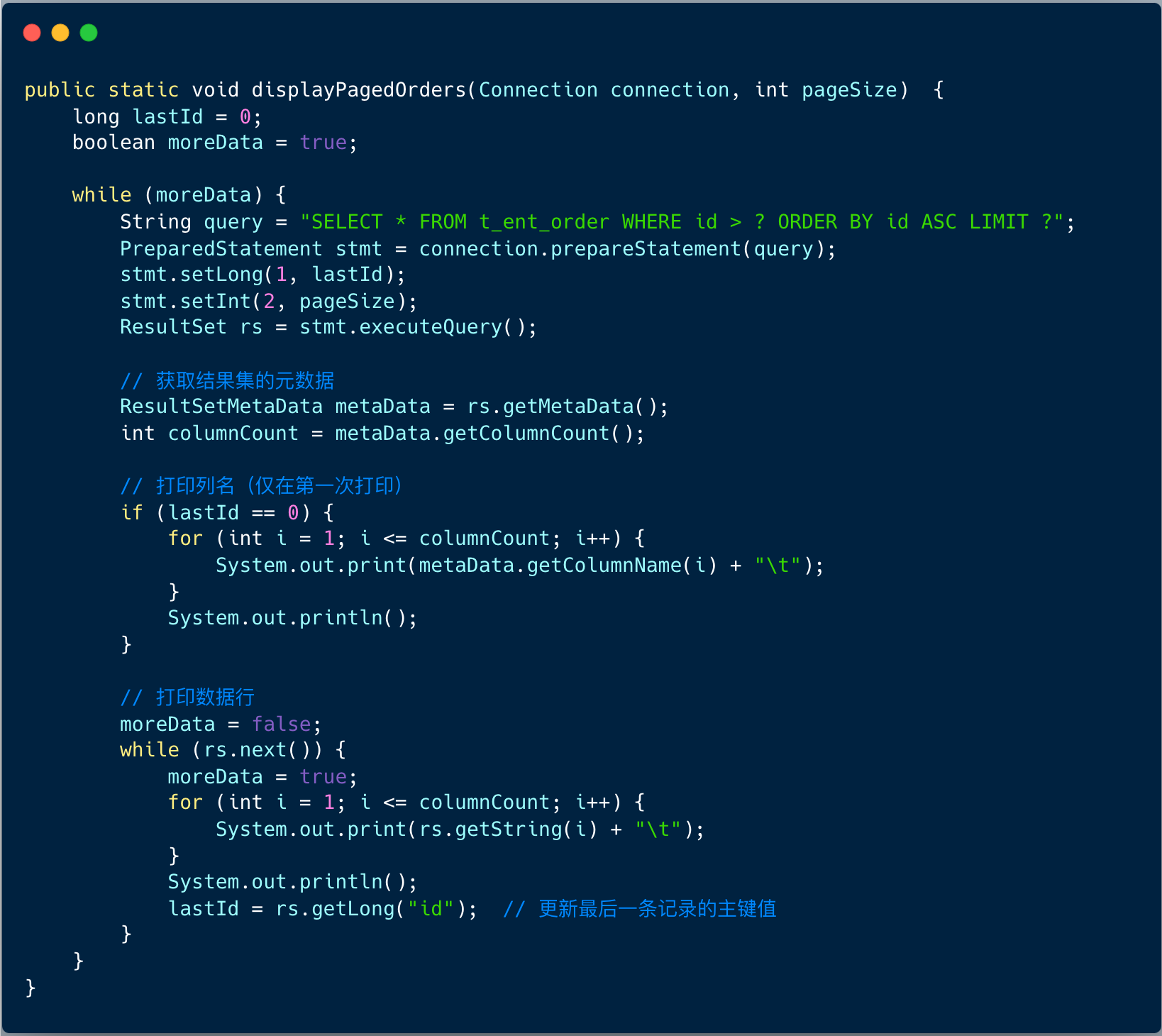
主键分页查询是非常优秀的查询全表的方式,性能也非常好,也容易理解,也是我非常推荐的方式。
3. 时间范围查询
假如订单数据每个小时的数据非常均匀,我们可以将整个数据按照小时分为多个分片,每次只查询 N 个小时内的订单数据 。

示例代码如下:
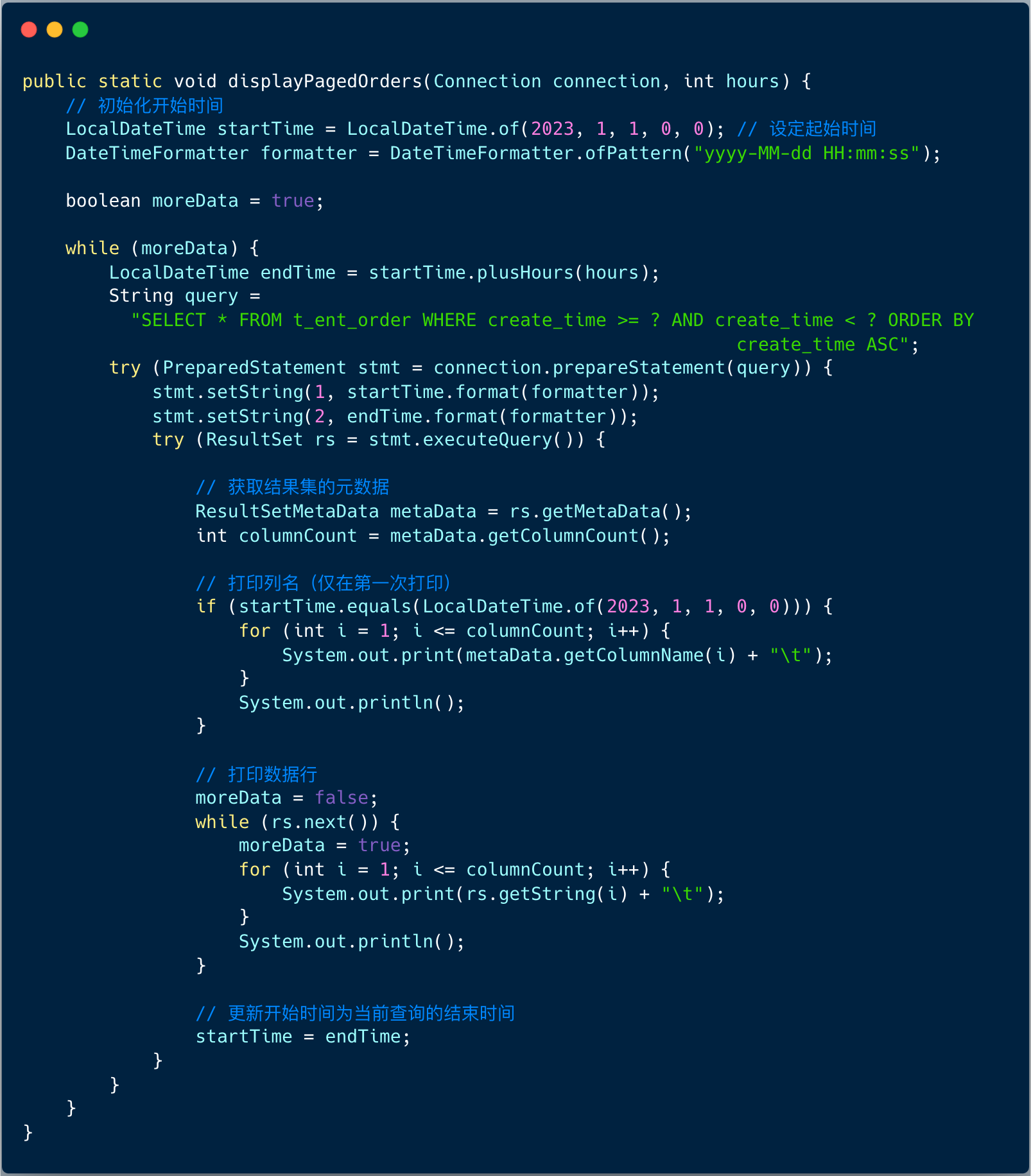
这种方式其实和主键分页查询的目的是一样的,尽量减少每次查询的数据量,避免 OOM 的风险,同时也可以不断的按照顺序查询,避免出现数据丢失和重复。
4. Cursor游标模式
当我们使用分页方式查询全表时,我们需要考虑分页大小,规避 OOM 事故的产生,同时也需要考虑查询顺序,尽量避免遗漏数据,以及重复查询数据。
使用游标模式进行数据库查询,可以有效地处理大量数据而不会一次性将所有数据加载到内存中,非常适合大数据量查询。
示例代码如下:
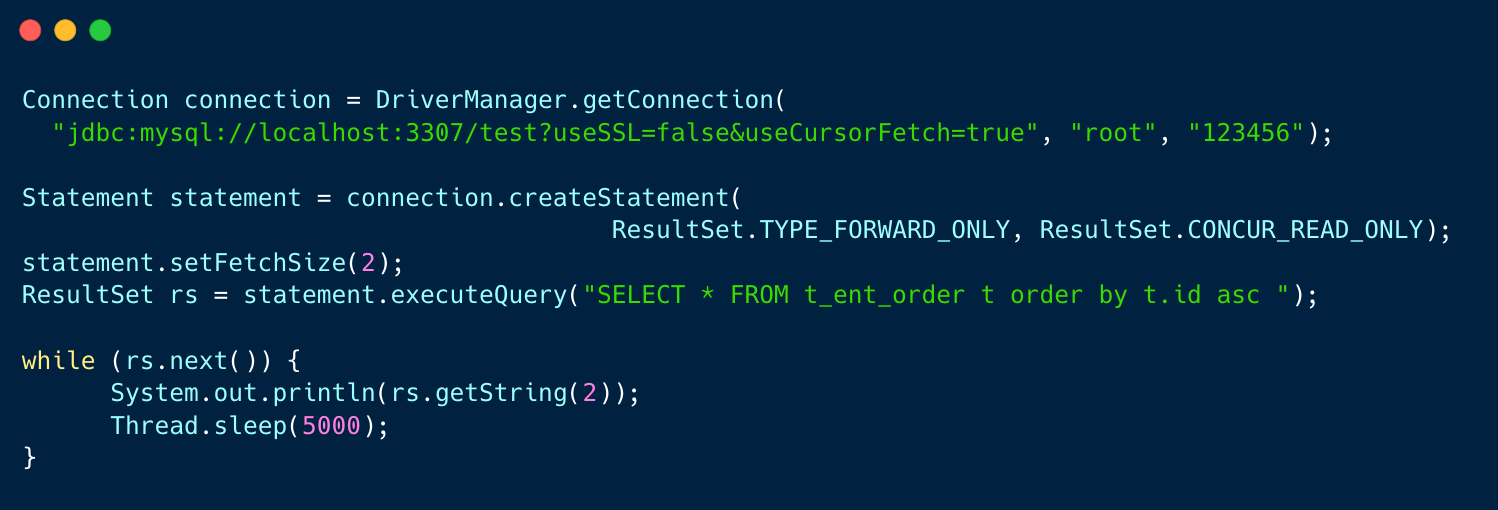
核心要点:
- 在连接参数中需要拼接 useCursorFetch=true;
- 创建Statement时需要设置 ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY
- 设置 fetchSize 控制每一次获取多少条数据
通过 wireshark 抓包,可以看到每执行一次 rs.next() 就会向 mysql 服务发送一个请求,同时 mysql 服务返回两条数据:
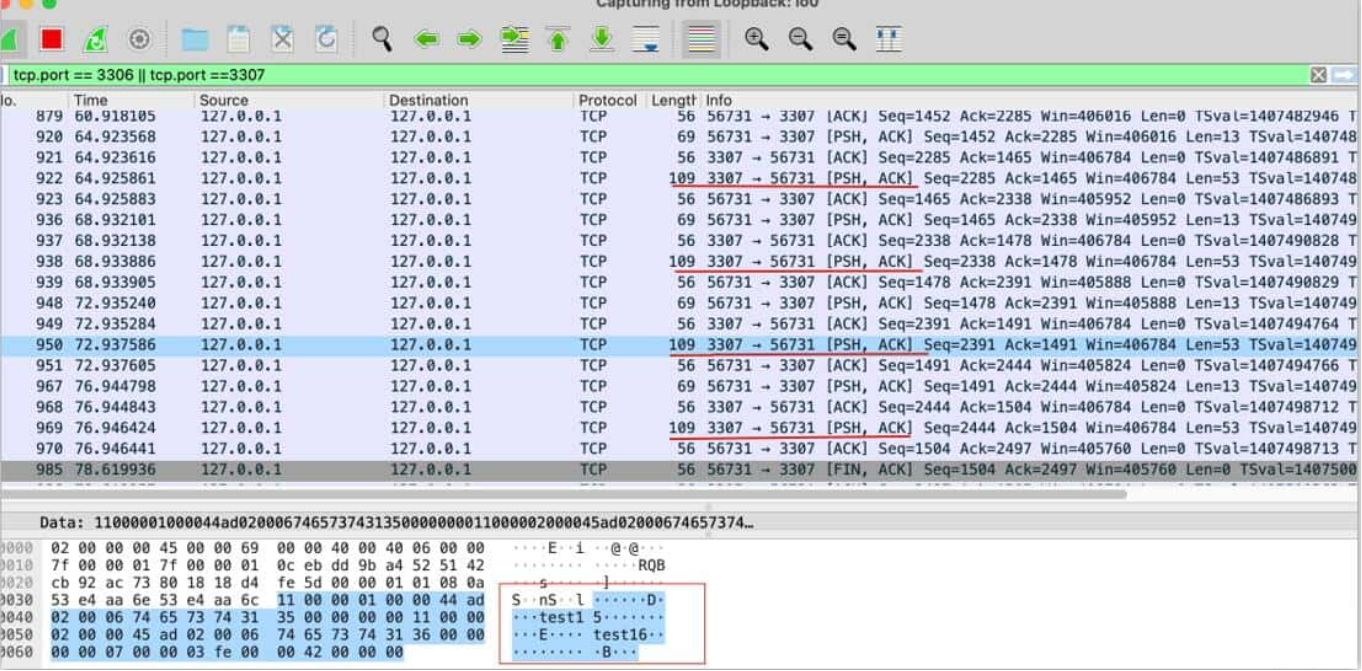
由于 MySQL 服务端并不知道客户端什么时候将数据消费完,而自身的对应表可能会有 DML 写入操作,此时 MySQL 需要建立一个临时空间来存放需要拿走的数据。
启用 useCursorFetch 读取大表的时候会观察到 MySQL 上的几个现象:
- IOPS 飙升(磁盘每秒的读写次数)
- 磁盘占用空间激增;
- 客户端 JDBC 发起 SQL 后,长时间等 待SQL 响应数据,这段时间就是服务端在准备数据 ;
- 在数据准备完成后,开始传输数据的阶段,网络响应开始飙升,IOPS 由“读写”转变为“读取”;
- CPU 和 内存 会有一定比例的上升
5. 总结
1、普通分页查询:
适合数据量较少的全量查询场景 ,页码越大,则越消耗数据库资源。
2、主键分页查询:
借助主键 id 天然索引的特性 ,通过记录每次查询结果的最后一条记录的主键值,在下一次查询时使用这个值进行分页,从而避免了 OFFSET 带来的性能问题。
3、时间范围查询:
将数据按照时间分为多个片段,每次查询一个时间分片,这种方式和主键分页查询的目的是一样的,尽量减少每次查询的数据量,避免 OOM 的风险,同时也可以不断的按照顺序查询,避免出现数据丢失和重复。
4、Cursor 游标模式:
使用游标模式进行数据库查询,编程模型非常简单,可以有效地处理大量数据而不会一次性将所有数据加载到内存中,非常适合大数据量查询。
但同时我们也需要理解:
任何技术都不是完美的,当我们使用 MySQL JDBC 游标模式时,MySQL 服务端的 IOPS 飙升 ,同时磁盘占用空间激增 。