1. 目的
1、支持多分片组合
比如订单表需要按照用户编号 user_id 和区域编号 area_id 组合分片 , 也就是相同(用户 + 区域)的订单位于同一分片中 。
2、通过主键 ID 可以直接路由到目标分片
因此,我们必须选择复合分片算法,它支持对多个分片键(字段)为依据的分库分表,分片键 shardingcolumns 需要设置成 id,user_id,area_id,然后自定义复合分片算法 HashSlotAlgorithm (shardingsphere JDBC 4.X 版本)。
2. 哈希算法
分片算法和阿里开源的数据库中间件 cobar 路由算法非常类似的。
假设现在需要将订单表平均拆分到 4 个分库 shard0 ,shard1 ,shard2 ,shard3 (分片数量必须是 2 的次幂) 。
首先将 [0-1023] 平均分为4个区段:[0-255],[256-511],[512-767],[768-1023],然后对字符串(或子串,由用户自定义)做 hash, hash 结果对 1024 取模,最终得出的结果 slot 落入哪个区段,便路由到哪个分库。
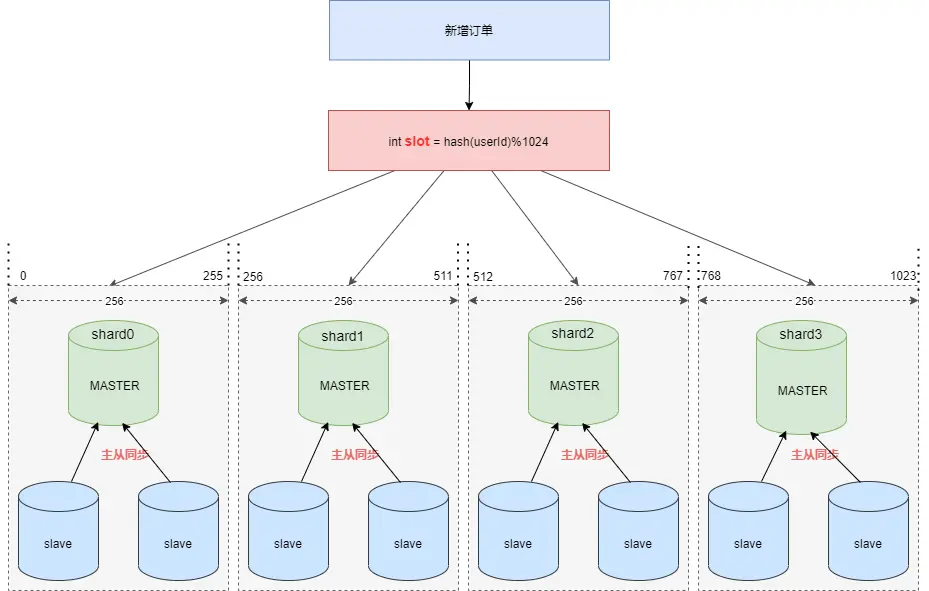
路由算法见下图:
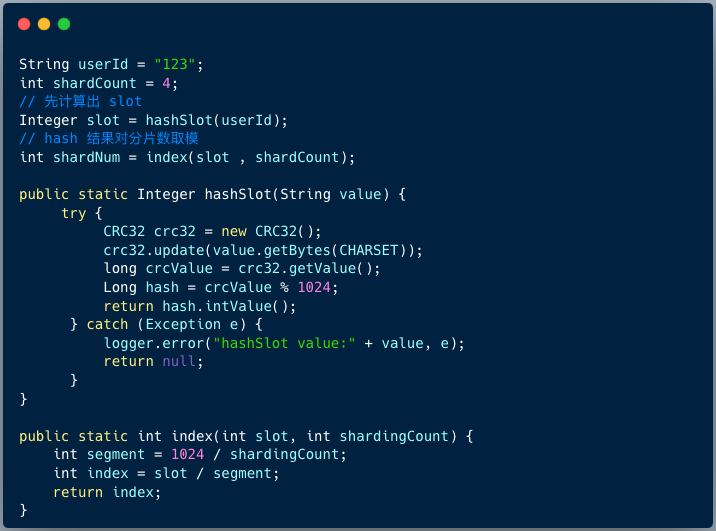
首先调用 hashSlot 方法计算分片键 user_id 的 slot ,然后 slot 对分片数取余,即可得到路由的目标分片。
假如是多分片组合用户编号 user_id、区域编号 area_id ,那么我们可以将这两个分片键做一个简单排序转换为 [area_id,user_id] , 它们的值分别为”111”、 “123” , 那么计算分片键的值为: “111” + “123” = “111123” , 最后按照 “123111” 计算路由的目标分片即可。
最后一个问题,虽然解决了多分片组合,但我们需要按照订单 ID 查询订单信息时依然需要路由四个分片,效率不高,那么如何优化呢 ?
答案就是:基因法。
3. 基因法
基因法是指在订单主键 ID 中携带企业用户编号信息,我们可以在创建订单 ID时使用雪花算法,然后将 slot 的值保存在 10位工作机器 ID 里。
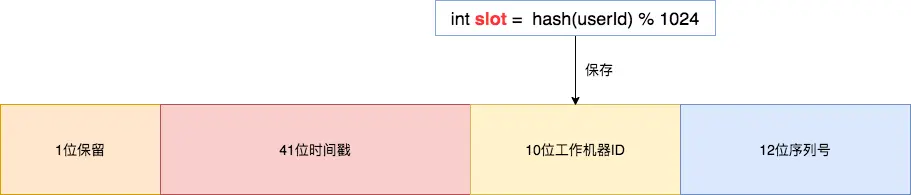
因此,当我们指定分片字段为 id、user_id 时,实现分片算法 HashSlotAlgorithm 首先会判断是否解析出主键 ID 字段,假如 ID 值存在,则通过 ID 值就可以反查出 雪花算法里的 10位工作机器ID - workerId ,也就是 slot 。
1 | Integer getWorkerId(Long orderId){ |
然后我们直接用 slot 对分片数取模,即可得到路由的目标分片。
4. 源码解释
HashSlotAlgorithm 需要实现复合分片算法接口的 doSharding 方法,该方法返回路由的目标分片集合。
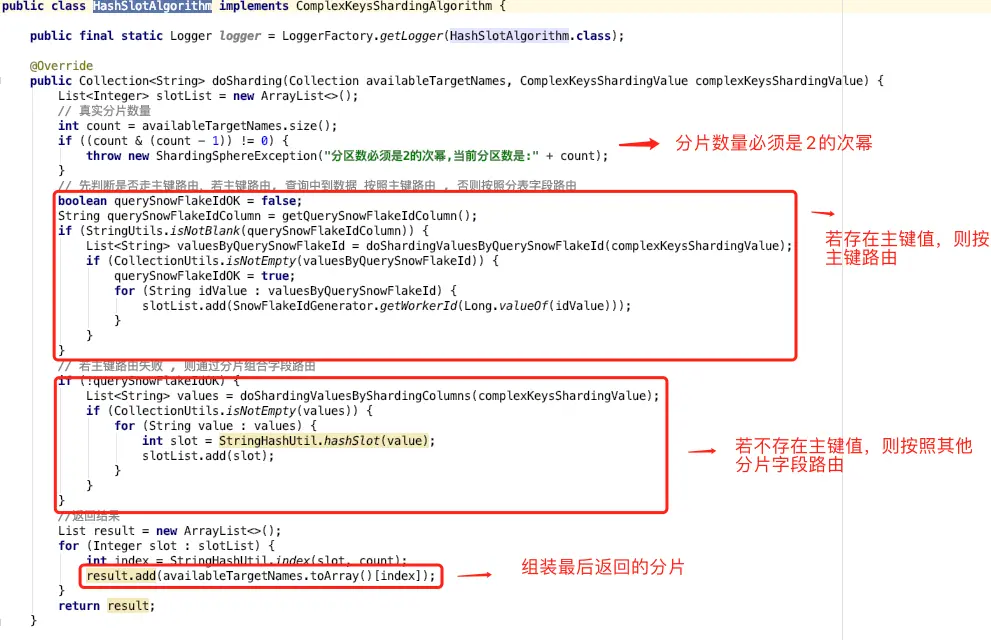
分片流程分为四个步骤:
1、判断分片数目,分片数目必须是2的次幂
我们是按照 [0-1023] 生成 sharingCount 个区段,2的次幂可以保证数据相对均匀,同时实现起来也相对简单。
分片数不满足2的次幂,则直接返回异常,执行 SQL 失败。
2、分片键中有主键值,则直接通过主键解析出路由分片;
配置文件中分片字段是 id,ent_id , 但对于分片算法来讲,它必须知道到底哪个字段是主键 ID ,所以算法中我们定义了一个方法 getQuerySnowFlakeIdColumn 定义哪个字段是雪花算法生成的主键 ID , 默认主键 ID 字段名是 “id”。
1 | public String getQuerySnowFlakeIdColumn(){ |
相比 shardingsphere JDBC 4.X ,shardingsphere JDBC 5.X 可以自定义属性,更加灵活。
首先需要从复合分片值 complexKeysShardingValue 中获取主键的值 。

图中,保存订单信息时,shardingsphere JDBC 解析出复合分片值对象 complexKeysShardingValue ,包含两个列的值 ,我们只需要从 Map 中解析出 key=“id” 对应的 value 值即可获得主键 ID 值。
接下来,通过 主键 ID 值就反查出雪花算法里的 10位工作机器ID - workerId ,也就是 slot 。
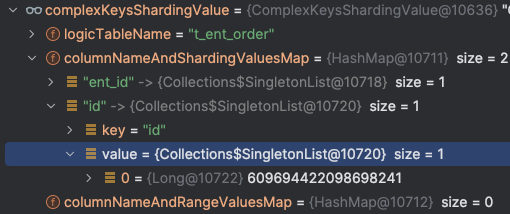
将主键 ID 值对于的 slot 添加到列表里,在步骤四统一组装目标分片集合。
3、分片键中不存在主键值 ,则按照其他分片字段值解析出路由分片。
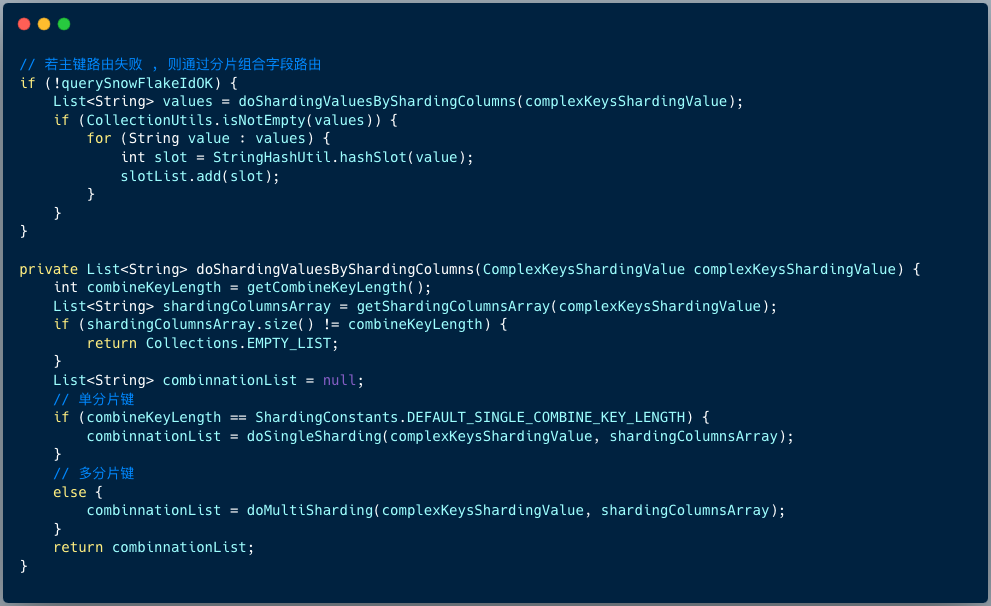
假如当前 SQL 中并没有主键 ID ,那么则需要从解析其他分片值,假如只有 ent_id ,那么就是单分片键,直接从复合分片值对象 complexKeysShardingValue 解析出 ent_id 即可。假如分片键是 ent_id,area_id ,则是多分片键,则需要分别解析这两个字段的值,并做好排序,将这两个字段值拼接在一起,计算拼接值对应的 slot 。
4、组装返回的分片集合
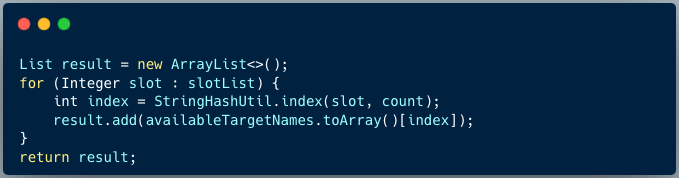
5. 总结
1、自定义复合分片算法实现了如下两点需求:
- 支持多分片组
- 基因法通过主键 ID 可以直接路由到目标分片
2、哈希算法
分片算法和阿里开源的数据库中间件 cobar 路由算法非常类似的。
假设现在需要将订单表平均拆分到 4 个分库 shard0 ,shard1 ,shard2 ,shard3 (分片数量必须是 2 的次幂) 。
首先将 [0-1023] 平均分为4个区段:[0-255],[256-511],[512-767],[768-1023],然后对字符串(或子串,由用户自定义)做 hash, hash 结果对 1024 取模,最终得出的结果 slot 落入哪个区段,便路由到哪个分库。
3、分片流程
- 判断分片数目,分片数目必须是2的次幂;
- 分片键中有主键值,则直接通过主键解析出路由分片;
- 分片键中不存在主键值 ,则按照其他分片字段值解析出路由分片;
- 组装返回的分片集合