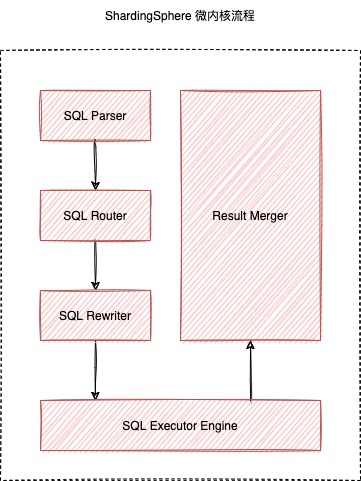
shardingsphere 执行 SQL 流程由 SQL解析 => SQL路由 => SQL改写 => SQL执行 => 结果归并的流程组成。
1. SQL引擎生成域模型statement对象
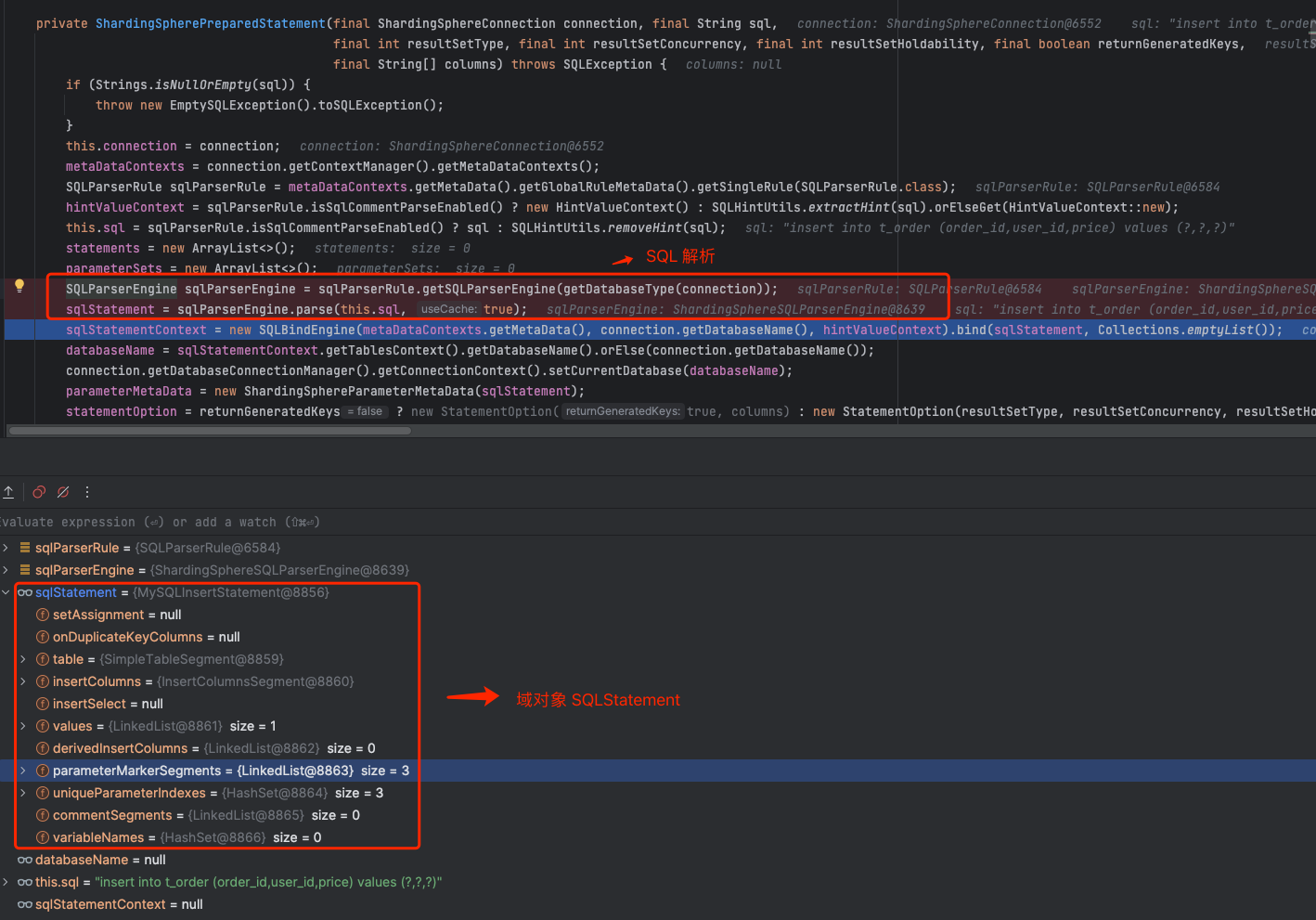
图中,ShardingSpherePreparedStatement 的构造函数内部完成了 SQL 解析 , 域对象是 MySQLInsertStatement 。
2. 包装域模型上下文SQL StatementContext
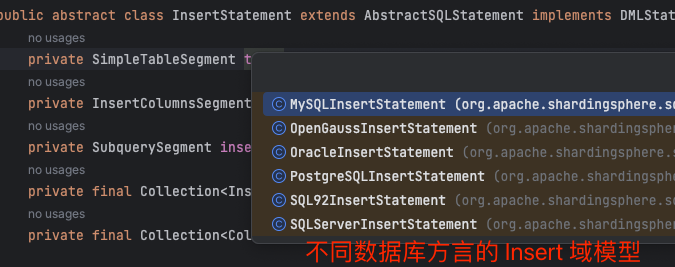
虽然我们生成了域模型,但 shardingsphere 生态的目的是满足 MySQL 、Oracle 、PostgreSQL 等分片需求 ,所以生成了 MySQLInsertStatement 之后,需要将域模型做一次转换。
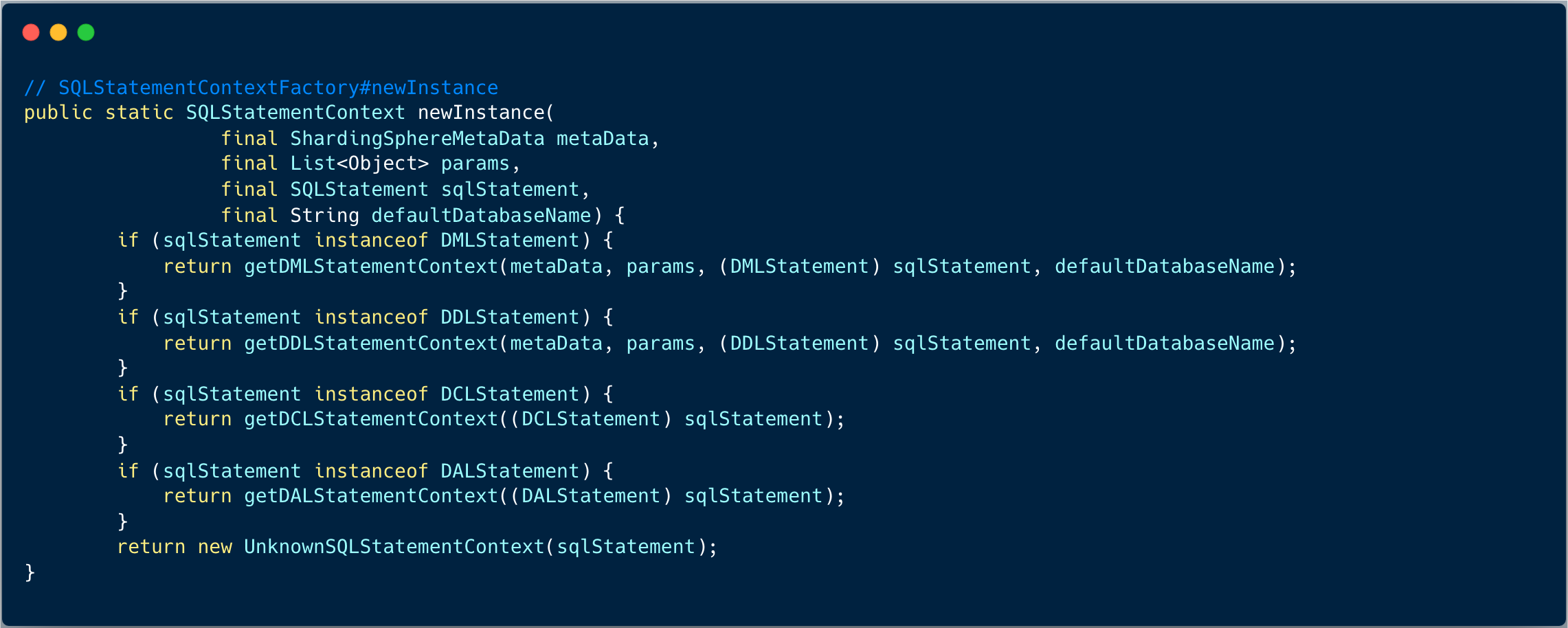
下图展示了域模型 MySQLInsertStatement 转换成通用域模型上下文 SQLStatementContext :
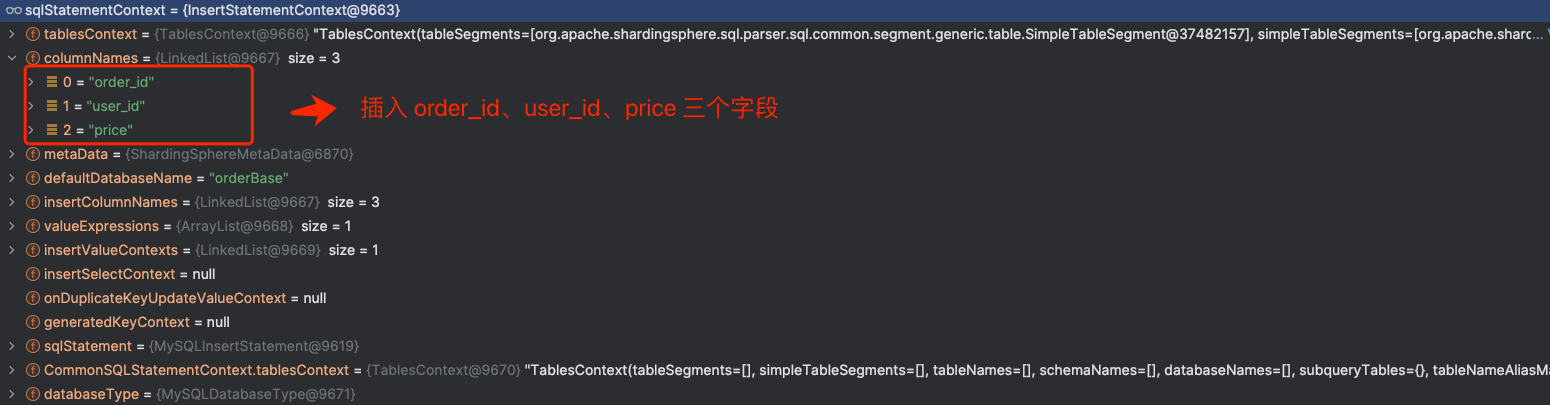
通用域模型上下文 SQLStatementContext 的属性对于任何数据库方言来讲都是一样的,比如字段名称、值表达式等。
3. 预编译赋值
将 MySQLInsertStatement 转换为 域模型上下文 SQLStatementContext 之后,接着就需要设置字段值了。
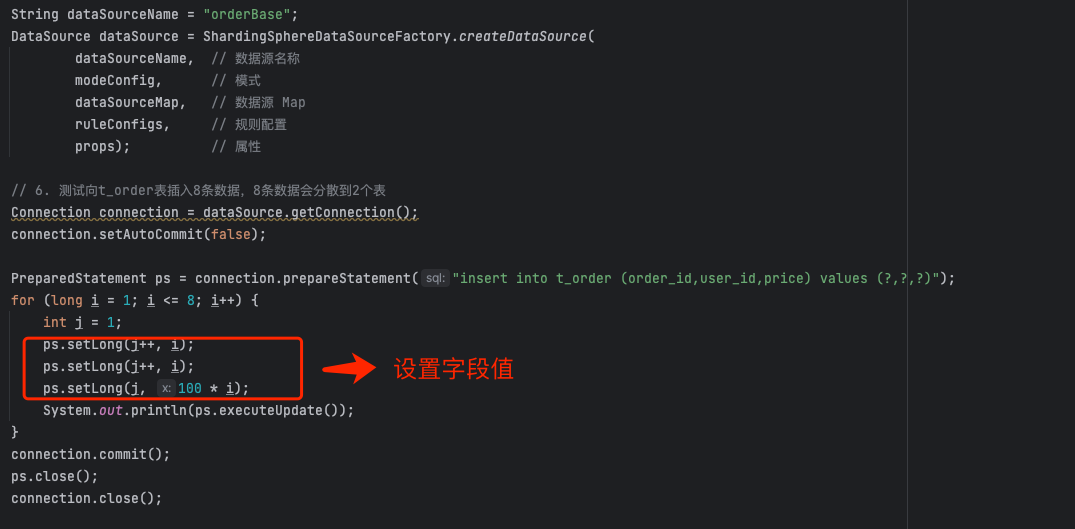
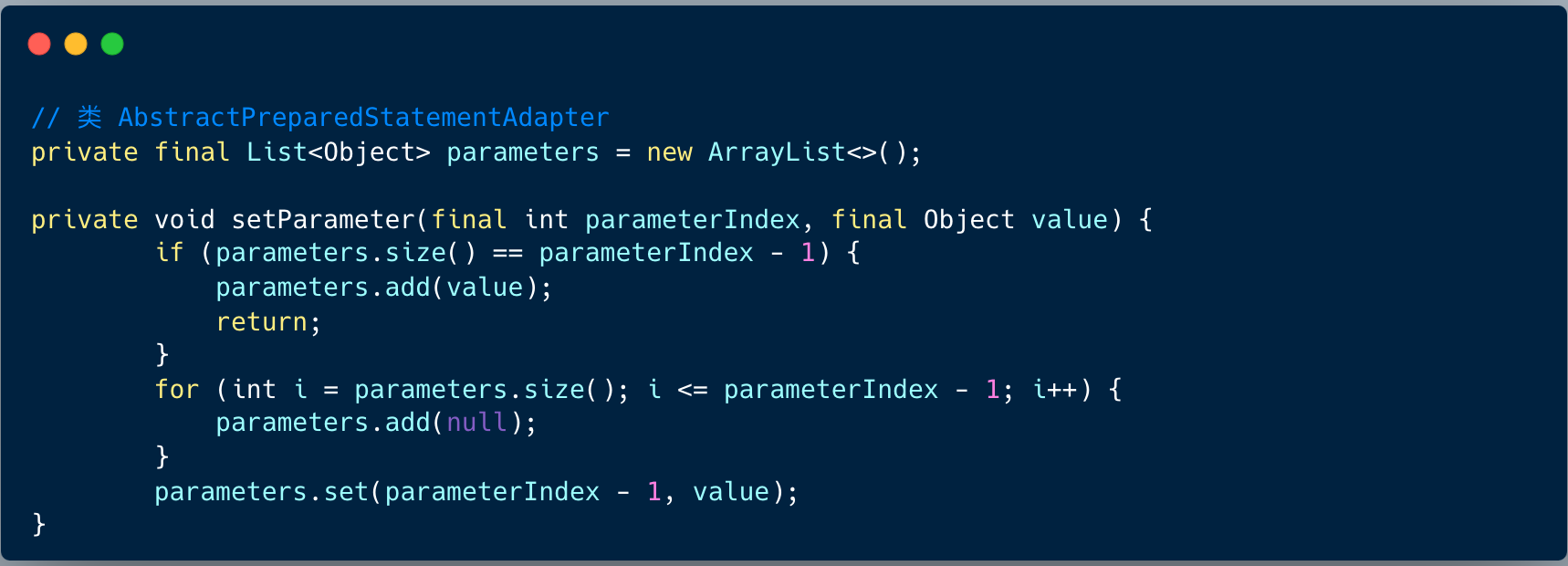
预编译赋值之后,开始执行 executeUpdate 方法 。
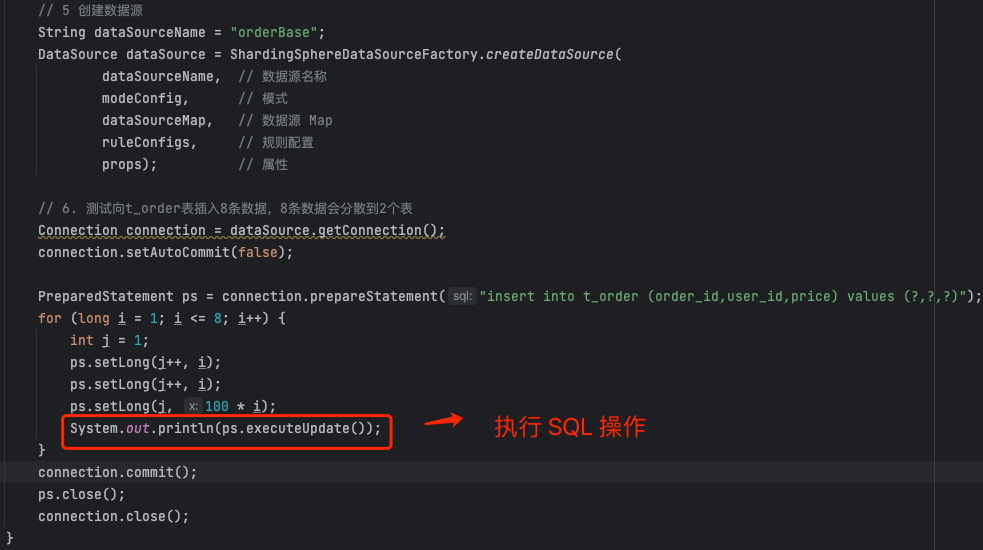
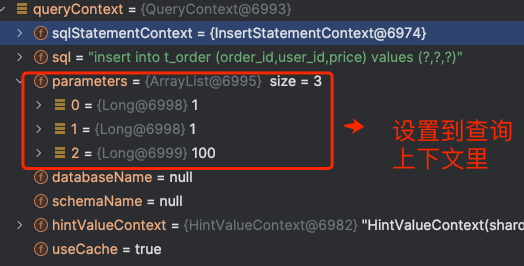
executeUpdate 方法的第一步是:创建查询上下文对象 QueryContext , 将 模型上下文 SQLStatementContext 、预编译参数对象包装起来。
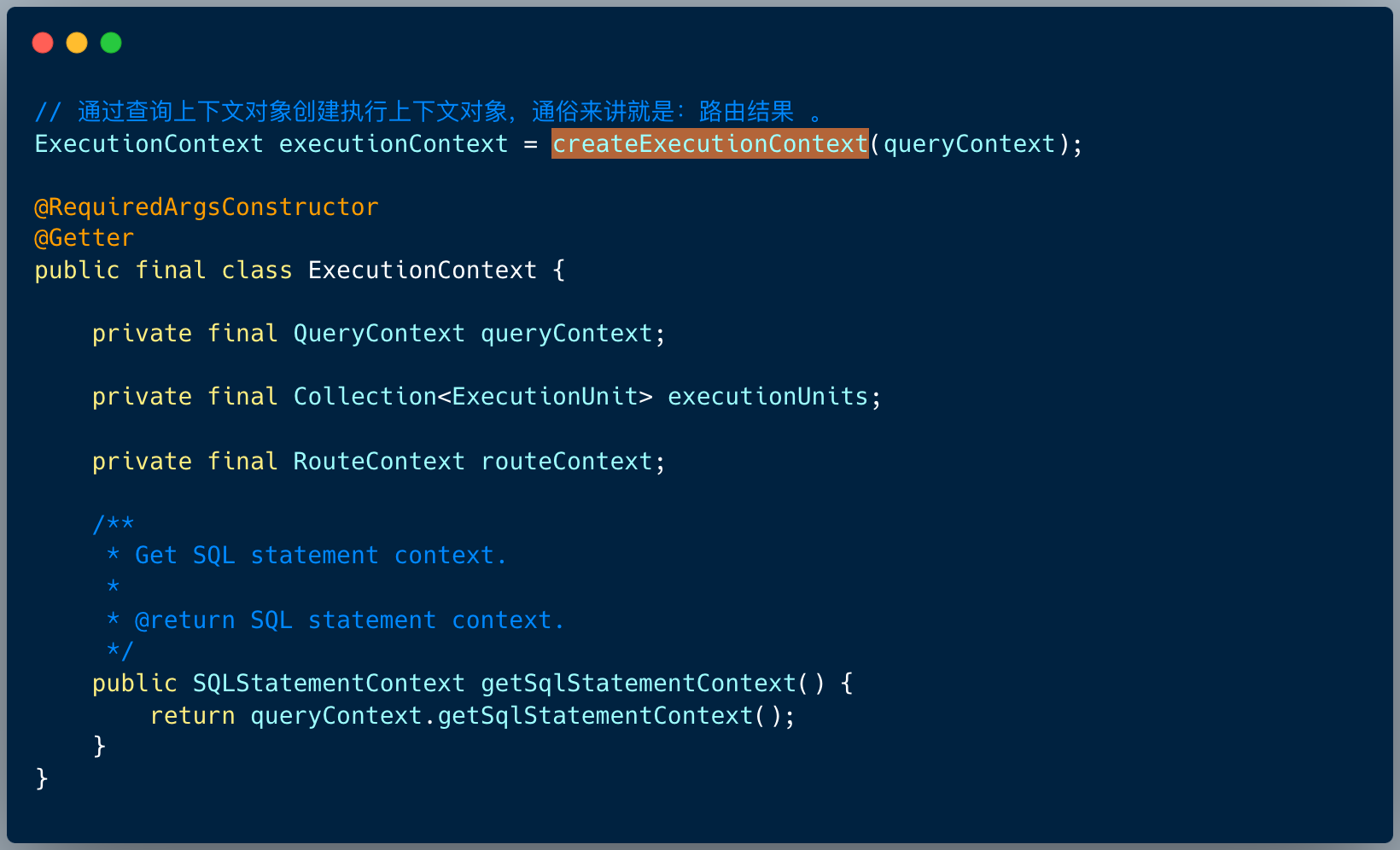
4. 生成执行上下文对象(路由、重写)
1、路由结果集合:路由到哪个数据分片、该分片对应的逻辑表、该分片对应的真实表。
2、执行单元集合:路由到哪个数据分片、该分片执行的 真实 SQL 语句 。
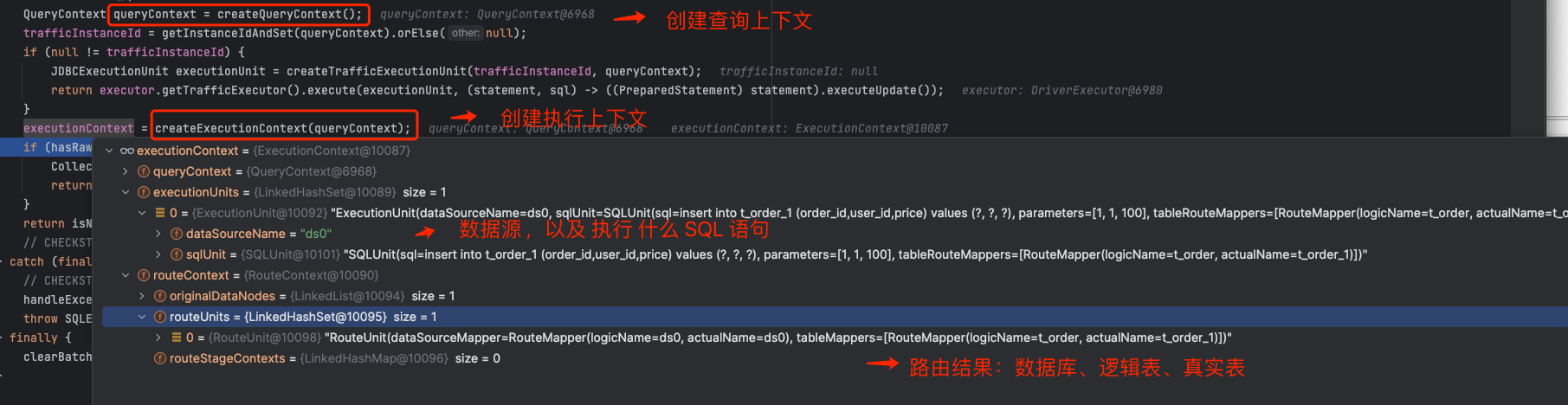
接下来,我们看内核处理器如何创建执行上下文对象 :
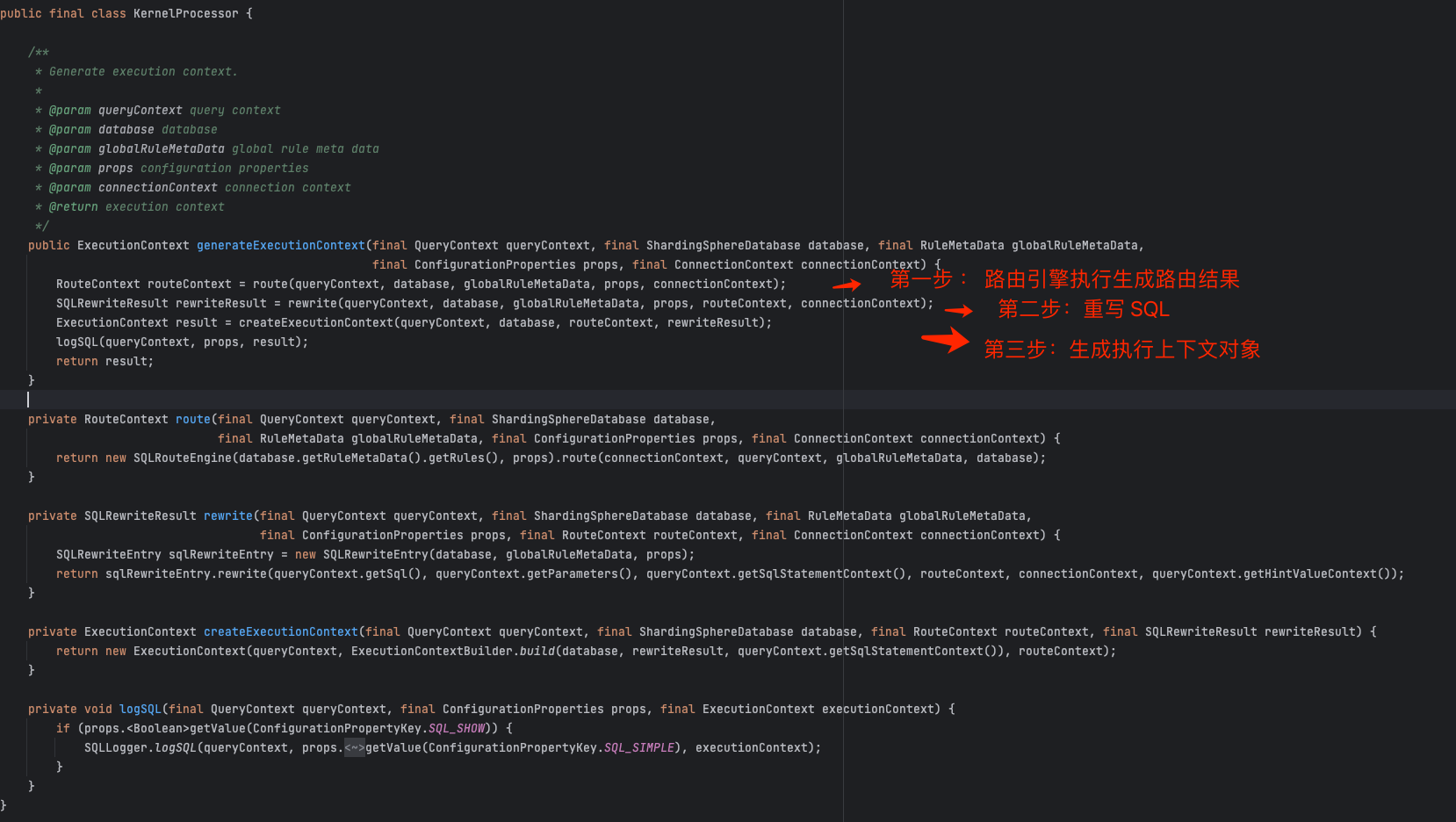
我们看到生成执行上下文对象包含三个步骤:
1、路由引擎执行生成路由结果 ;
2、重写引擎将执行 SQL 重写 ;
3、生成执行上下文对象;
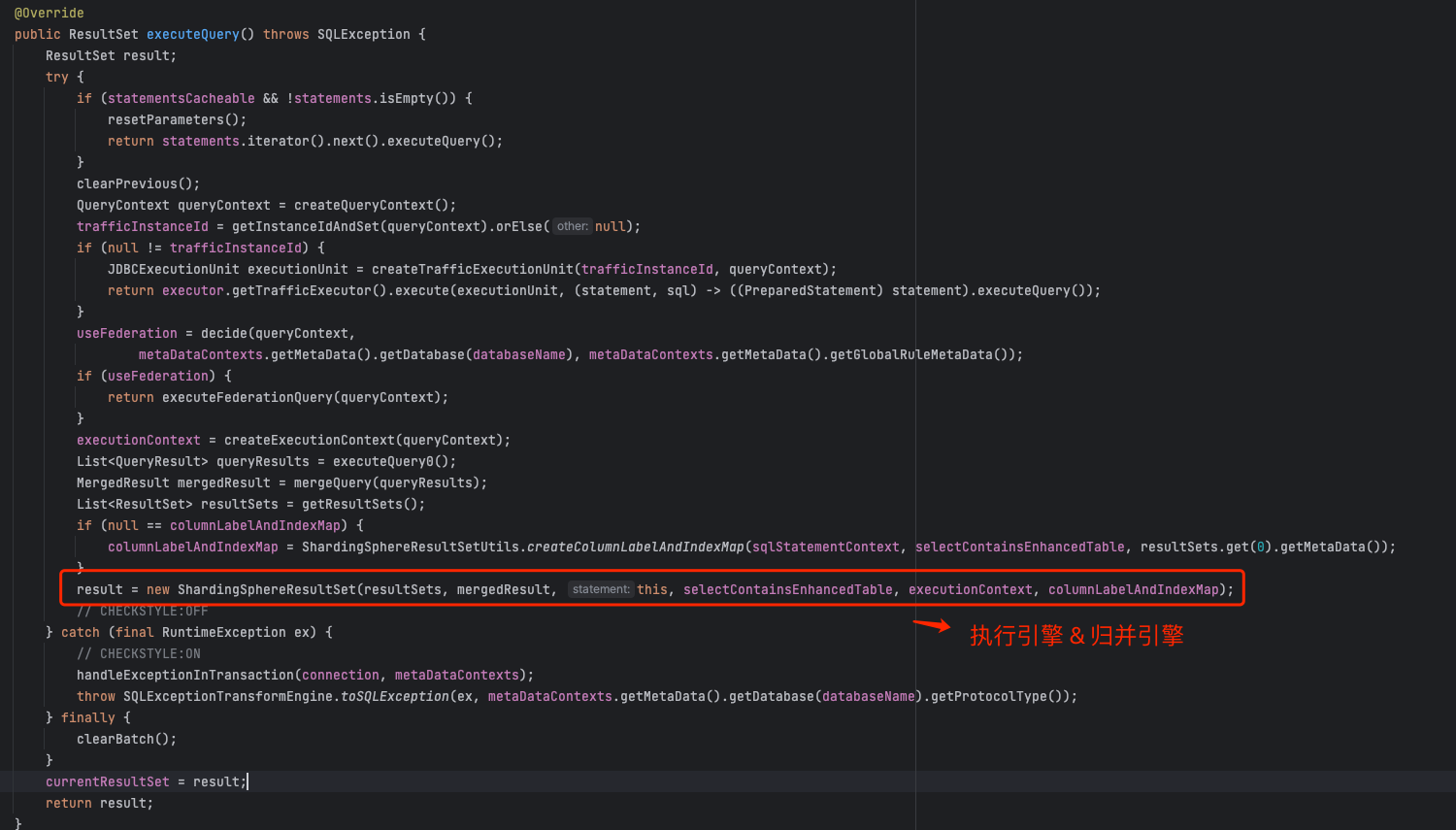
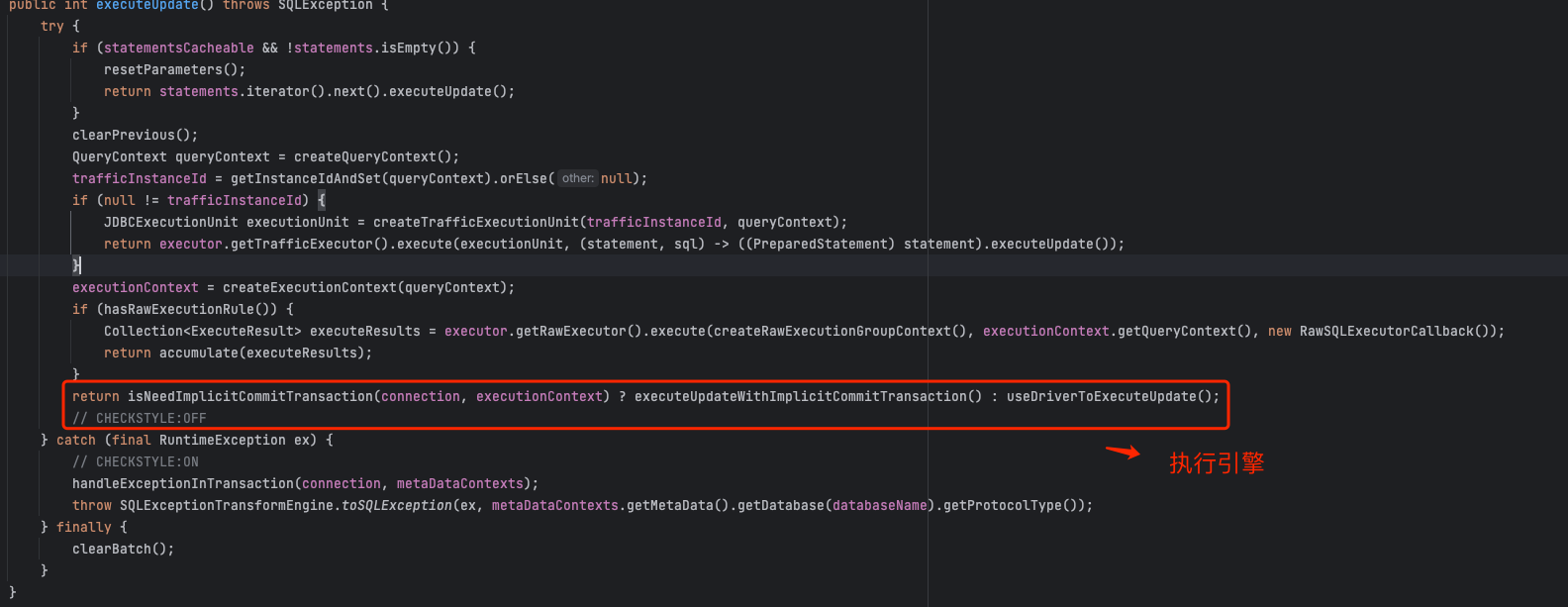
5. 生成结果(执行引擎、归并引擎)
当我们得到执行上下文对象,分别调用执行引擎、归并引擎获取执行结果:
1、查询操作 executeQuery
2、修改操作executeUpdate
6. 总结
shardingsphere 整体分片流程,我们做一个简单的梳理:
1、ShardingSpherePreparedStatement 的构造函数内部完成了 SQL 解析 ,生成域模型对象 statement ,并将 statement 转换成域模型上下文 SQLStatementContext (适配多种数据库方言)。
2、预编译赋值:ShardingSpherePreparedStatement 内部有一个 List 对象 parameters ,用于存储预编译的赋值。
3、开始执行查询/修改操作, 创建查询上下文对象 QueryContext,将模型上下文 SQLStatementContext 、预编译参数对象包装起来起来。
4、生成执行上下文对象 ,这里包含三个步骤:
- 路由引擎执行生成路由结果 ;
- 重新引擎将 SQL 重写 ;
- 生成真正的执行上下文对象;
5、通过执行引擎,获取执行结果,并通过归并引擎将结果归并。