1. 基本原理
下图展示了 MySQL 主从复制的原理:
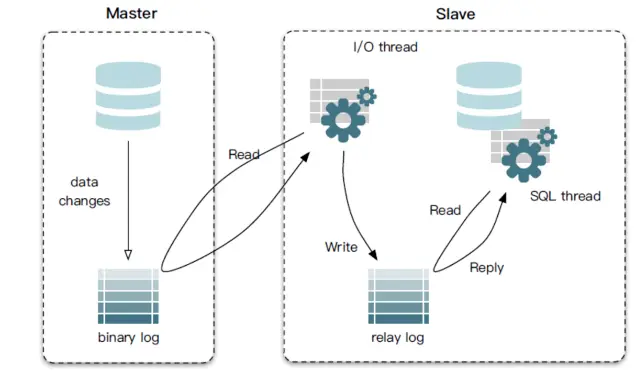
MySQL主备复制原理:
1、MySQL master 将数据变更写入二进制日志;
2、MySQL slave 将 master 的 binary log events 拷贝到它的中继日志( relay log );
3、MySQL slave 重放 relay log 中的事件,使得从节点数据和主节点的保持一致。
canal 工作原理如下:
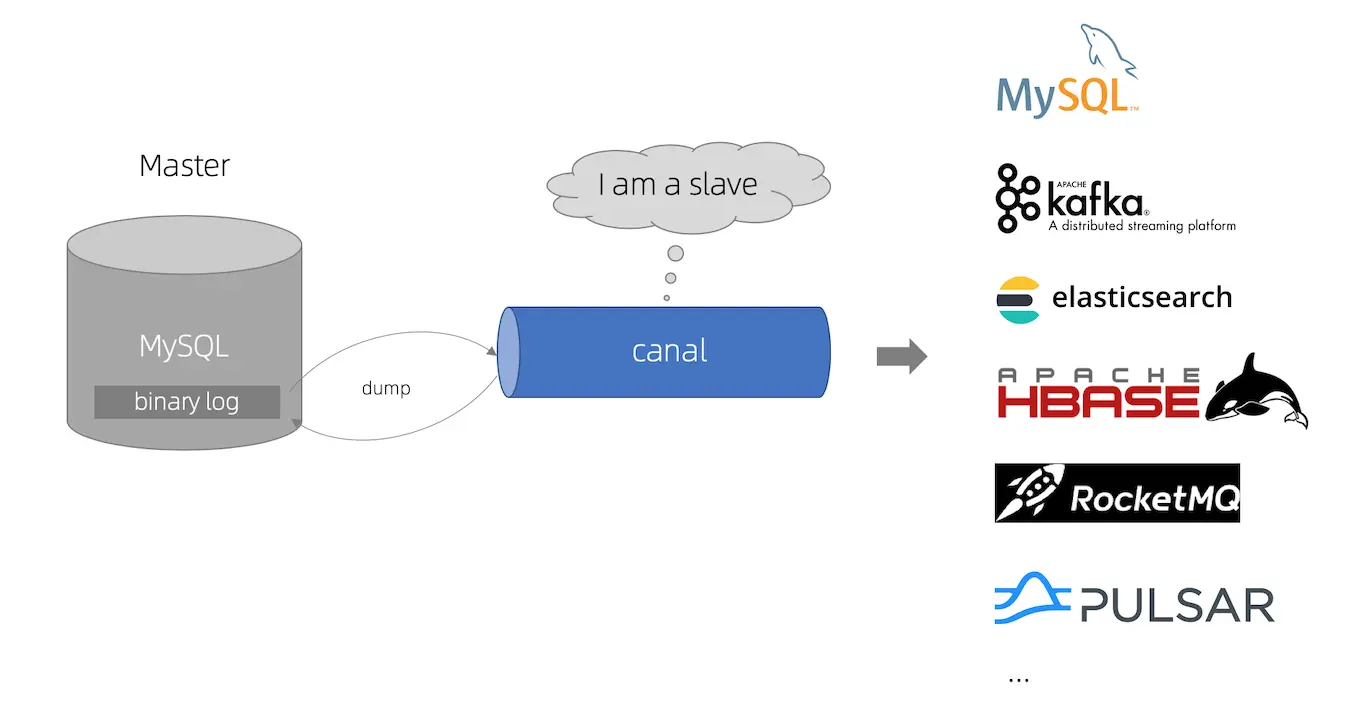
1、canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 请求;
2、MySQL master 收到 dump 请求,开始推送 binary log 给 canal ;
3、canal 解析 binary log 对象( 原始为 byte 流 ) ,将 binlog 数据分发给客户端。
2. 应用场景
笔者曾经曾经服务于神州优车集团,负责专车订单研发。
专车技术团队大量使用 canal 用于异构场景,典型场景有两点:分库分表增量同步和索引构建和实时维护。
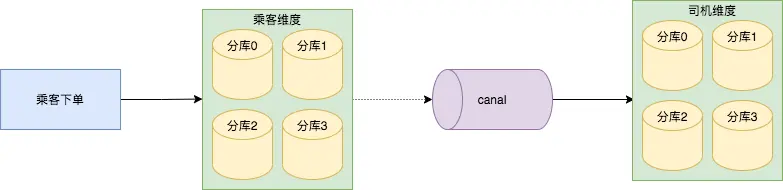
1、分库分表增量同步
专车订单按照乘客 user_id 作为 sharding key ,做了四个分片,若按照司机 driver_id 查询订单的话,需要广播到每一个分库并聚合返回,基于此,技术团队选择将乘客维度的订单数据异构到以司机维度的数据库里。
司机维度的分库分表策略和乘客维度逻辑是一样的,只不过 sharding key 变成了司机 driver_id 。
异构神器 canal 解析乘客维度四个分库的 binlog ,通过 SDDL (神州自研分库分表中间件)写入到司机维度的四个分库里。
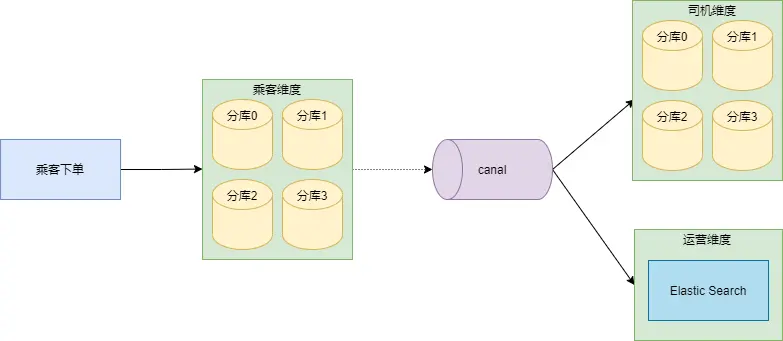
2、索引构建和实时维护
专车管理后台,运营人员经常需要查询订单信息,查询条件会比较复杂。
专车技术团队采用的做法是:订单数据落盘在乘客维度的订单分库之后,通过 canal 把数据同步到 Elastic Search。
3. 整体架构
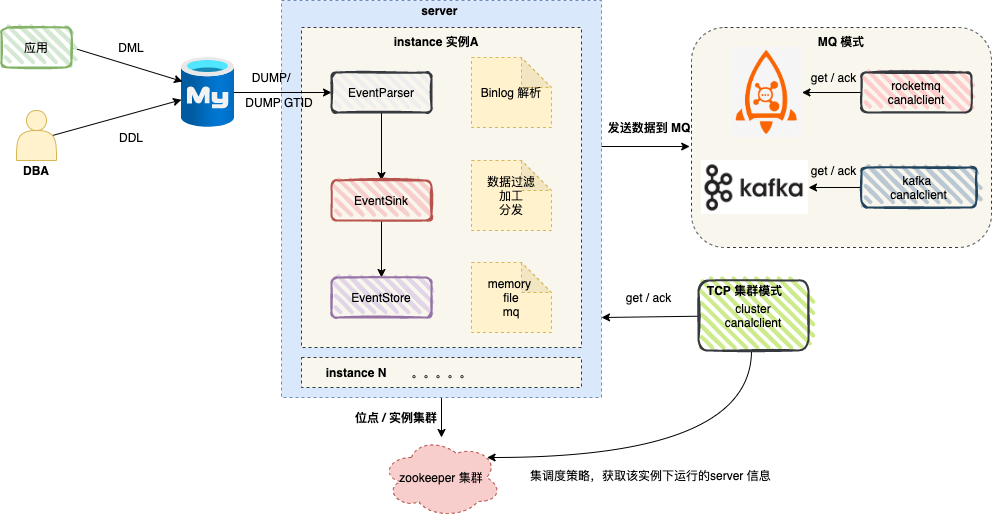
上图展示了 canal 集群模式的整体架构 ,server 代表一个 canal 运行实例,对应于一个 jvm , 而 instance 对应于一个数据队列 (1个 server 对应 n 个 instance )。
HA 机制的控制主要是依赖了zookeeper 的两个特性:watcher、EPHEMERAL 节点。
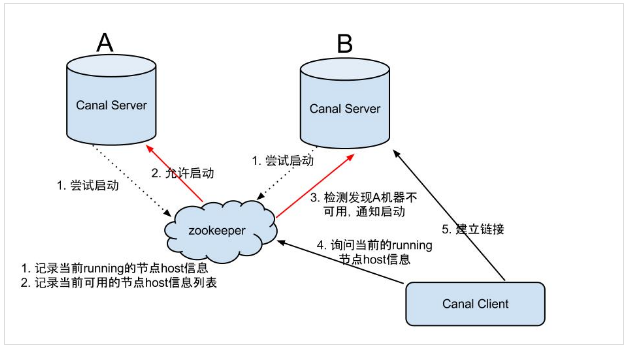
canal server 启动流程如下:
1、canal server 要启动某个 canal instance 时都先向 zookeeper 进行一次尝试启动判断 (创建 EPHEMERAL 节点,谁创建成功就允许谁启动);
2、创建 zookeeper 节点成功后,对应的 canal server 就启动对应的 canal instance,没有创建成功的 canal instance 就会处于 standby 状态;
3、一旦 zookeeper 发现 canal server A 创建的节点消失后,立即通知其他的 canal server 再次进行步骤1的操作,重新选出一个 canal server 启动 instance ;
为了减少对 mysql dump 的请求,不同 server 上的 instance 要求同一时间只能有一个处于 running ,其他的处于 standby 状态。
Canal 包含 TCP 和 MQ 两种模式 。
1、TCP 模式
Canal client 直接和 Canal Server 连接, 每次进行 connect 时,会首先向 zookeeper 询问当前是谁启动了 canal instance,然后和其建立链接,一旦链接不可用,会重新尝试 connect 。
和 canal server 方式类似,Canal client 也是利用 zookeeper 的抢占 EPHEMERAL 节点的方式进行控制。为了保证有序性,一份 instance 同一时间只能由一个 canal client 进行 get/ack/rollback 操作,否则客户端接收无法保证有序。
2、MQ 模式
Canal 支持将监听到的 Binlog 数据发送到 MQ( RabbitMQ、Kafka、RocketMQ ) ,此时 Canal Server 是作为消息队列的生产者的角色 ,客户端并不会和 Canal Server 交互,而是作为消费者的角色与消息队列交互。
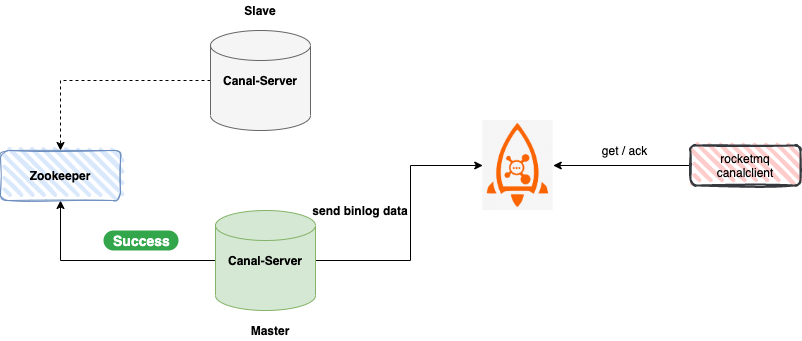
接下来,笔者分别为大家展示如何使用 Canal TCP 模式 和 MQ 模式。
4. Mysql配置
1、对于自建 MySQL , 需要先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,my.cnf 中配置如下
1 | [mysqld] |
注意:针对阿里云 RDS for MySQL , 默认打开了 binlog , 并且账号默认具有 binlog dump 权限 , 不需要任何权限或者 binlog 设置,可以直接跳过这一步。
2、授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant 。
1 | CREATE USER canal IDENTIFIED BY 'canal'; |
3、创建数据库商品表 t_product 。
1 | CREATE TABLE `t_product` ( |
5. TCP模式例子
首先从官网下载稳定版本:https://github.com/alibaba/canal/releases 。

我们选取 canal 版本 1.1.6 (大家可以选择最新版 1.1.7),进入 conf 目录。
1、配置 canal.properties
1 | #集群模式 zk地址 |
集群版需要配置 zookeeper 地址 ,以及实例目标 ,我们配置的是:product-syn 。
2、配置 instance.properties
在 conf 目录下创建实例目录 product-syn , 在 product-syn 目录创建配置文件 :instance.properties。
1 | # 按需修改成自己的数据库信息 |
启动 canal server :
1 | sh bin/startup.sh |
查看 server 日志:
1 | vim logs/canal/canal.log |

查看 instance 的日志:
1 | vim logs/product-syn/product-syn.log |
接下来,我们来看看 Zookeeper 的存储情况,笔者使用的工具是 prettyZoo :
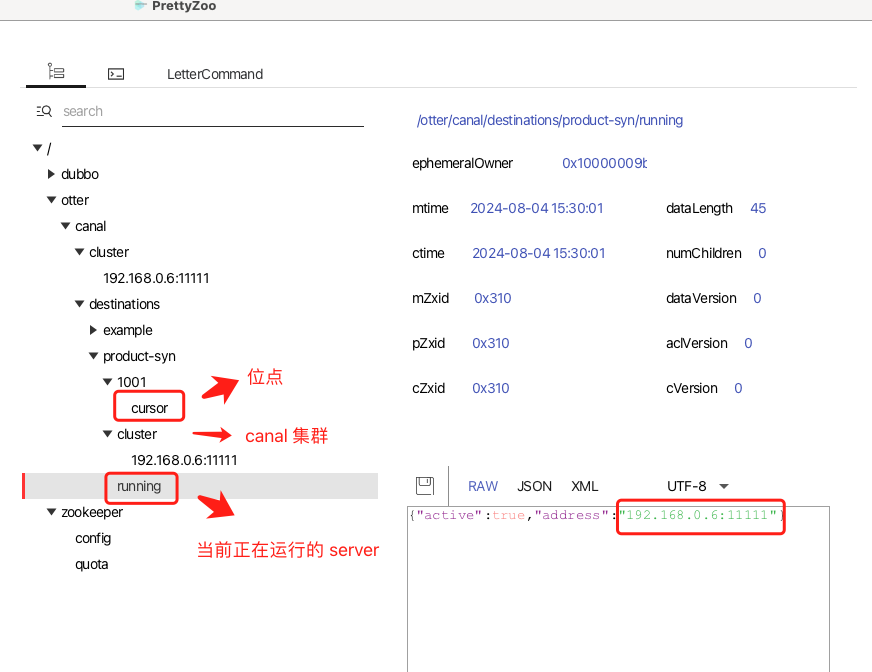
接下来,我们运行一个 Canal 客户端从 Canal Server 读取,并将信息同步到缓存里。
我们的例子采用 Canal 源码中的集群客户端的测试例子 ClusterCanalClientTest :
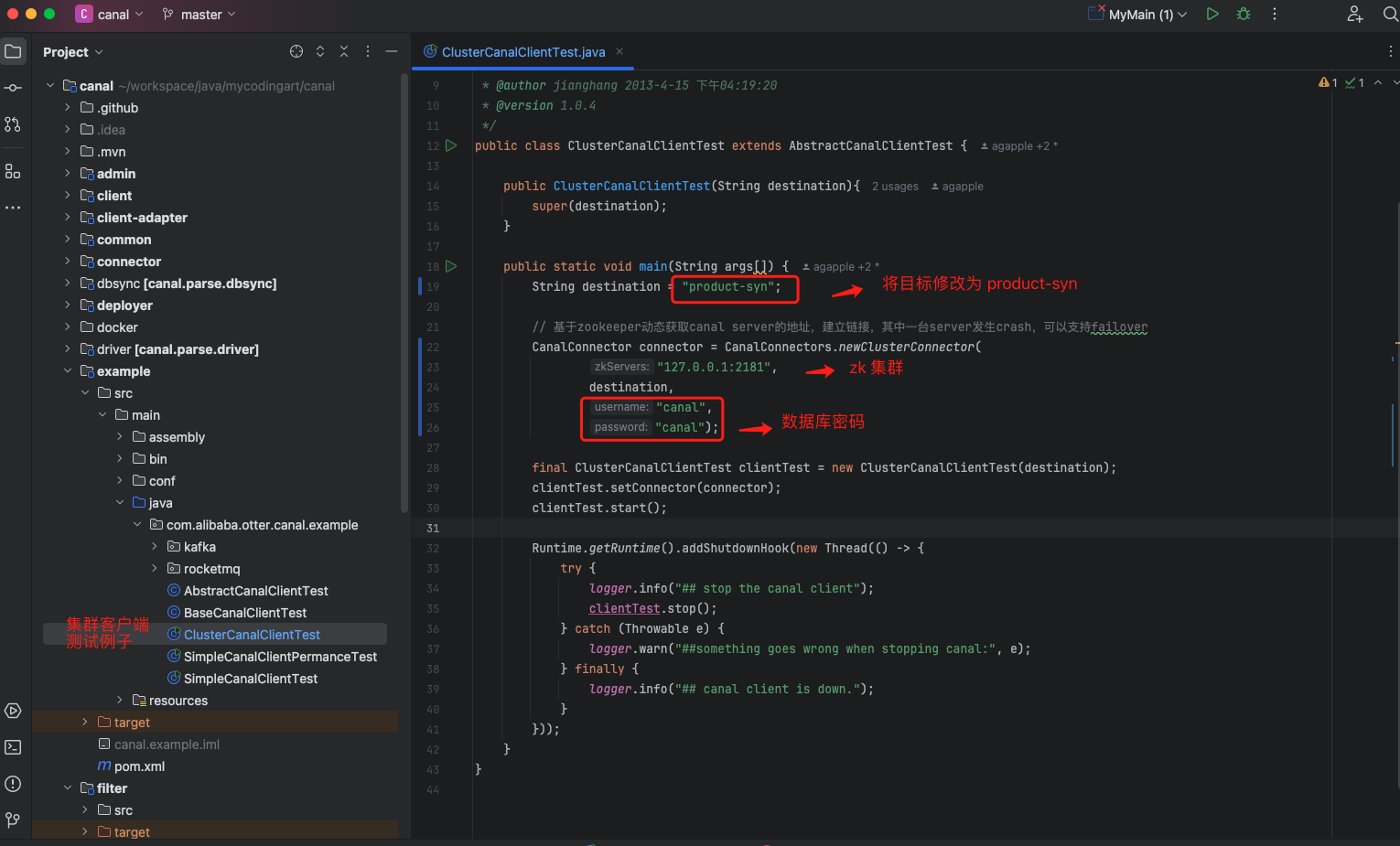
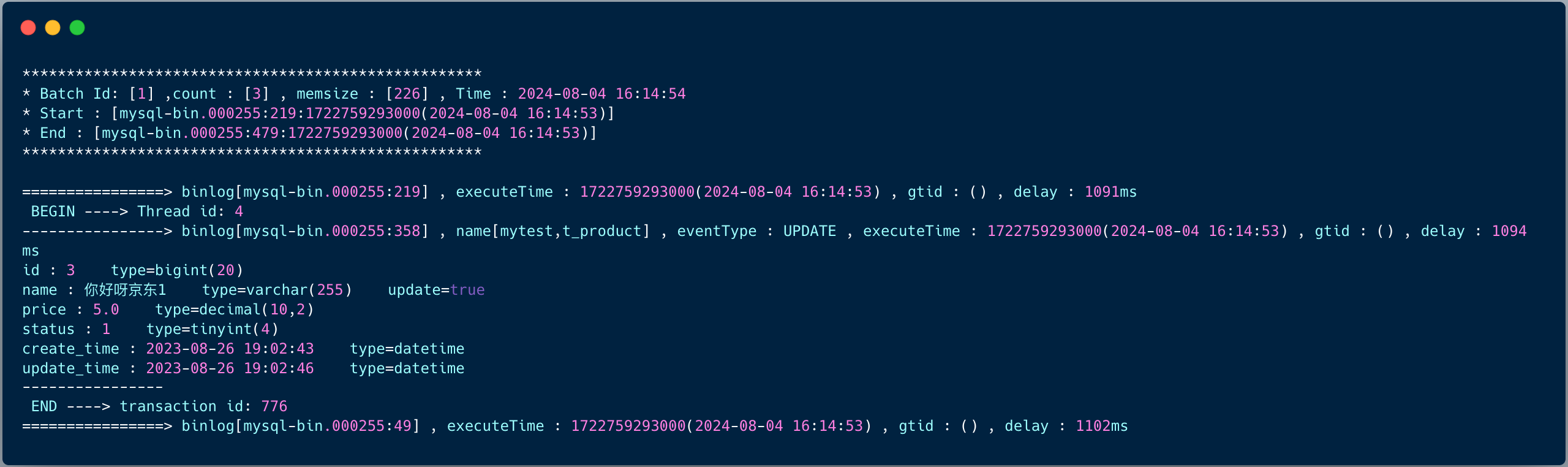
启动成功之后,修改商品表的数据:

控制台立即会打印如下日志:
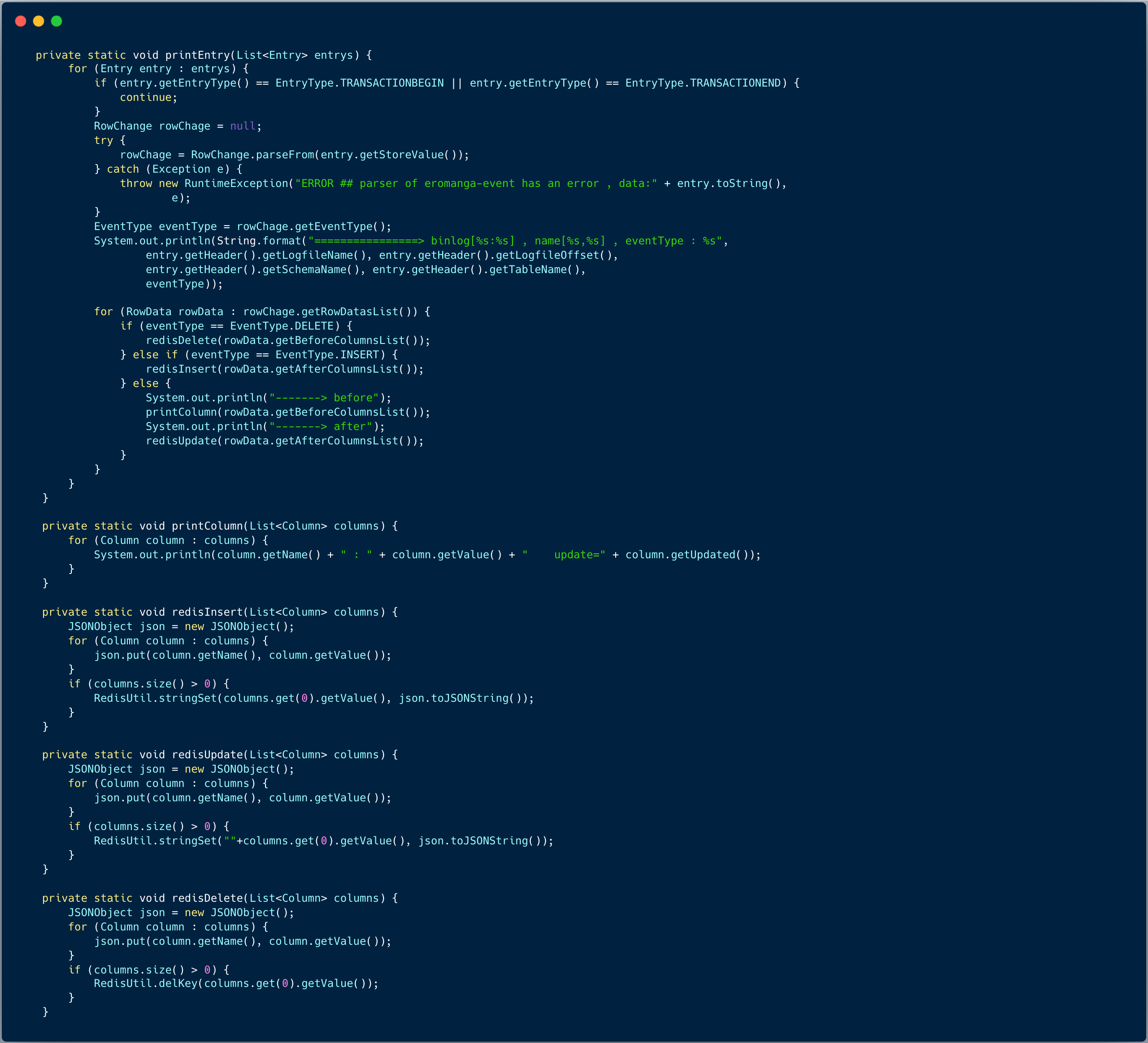
假如需要实现商品缓存同步的功能,我们将例子做一点修改:
将原来打印 BinLog message ,修改成缓存同步代码如下:
我们修改商品标题后,日志打印如下:

接下来,我们演示 Canal MQ 模式将商品表更新同步到分布式缓存里。
6. MQ模式例子
MQ 模式 和 TCP 模式有比较大的区别,因为 MQ 模式最大的优势是解耦,CanalServer 作为生产者只需要将 Binlog 数据以消息
的形式发送到消息队列。
配置和 TCP 模式差别较大:
1、配置 canal.properties
1 | #集群模式 zk地址 |
2、instance 配置文件
在 conf 目录下创建实例目录 product-syn , 在 product-syn 目录创建配置文件 :instance.properties。
1 | 按需修改成自己的数据库信息 |
修改一条 t_product 表记录,可以从 RocketMQ 控制台中观测到新的消息。
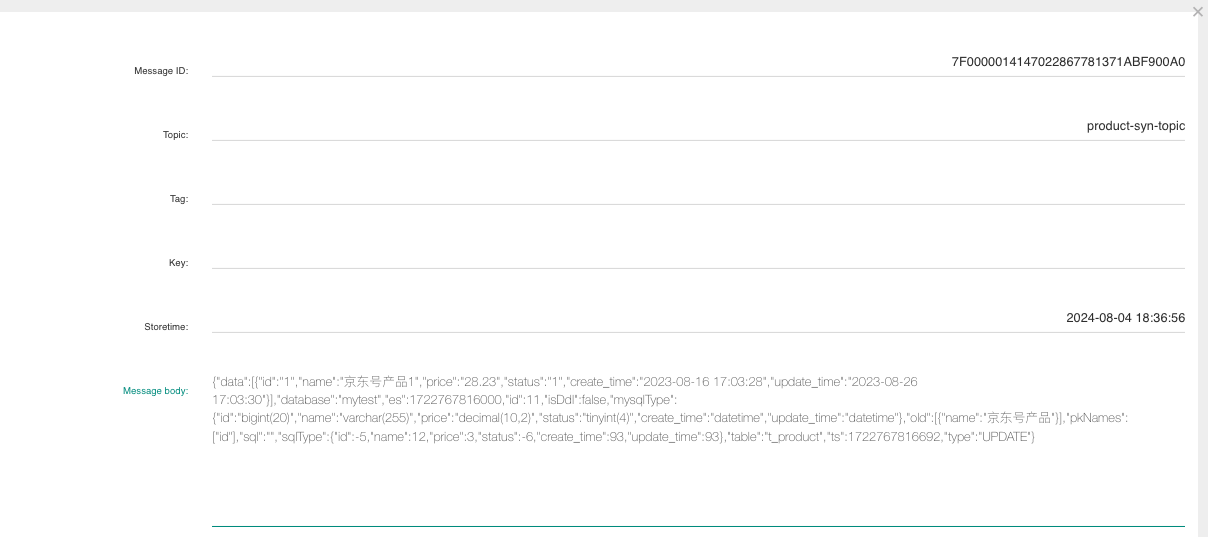
接下来,我们建立一个顺序消费者即可获取 binlog 消息:
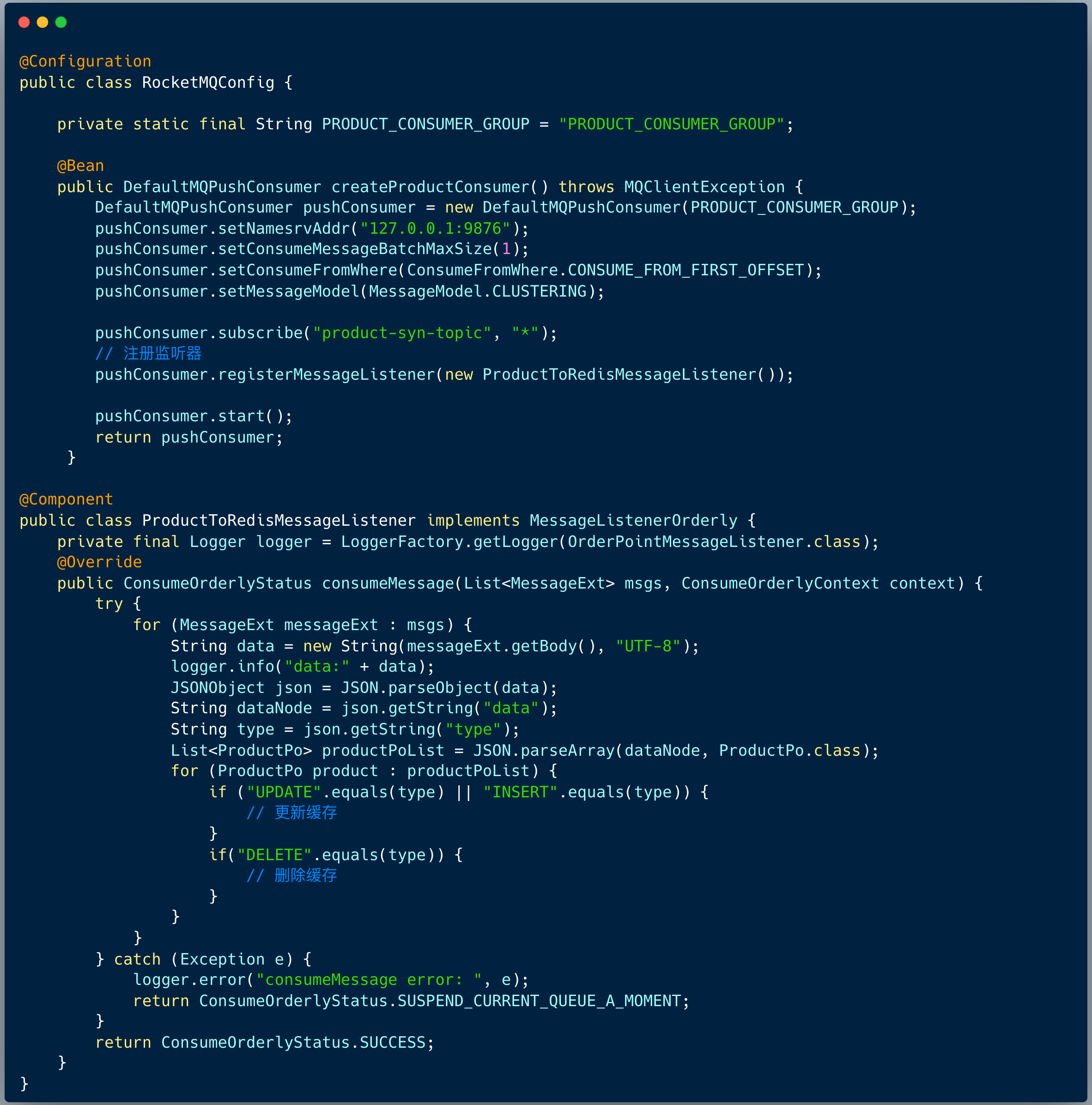
消费者逻辑重点有两点:
- 顺序消费监听器
- 将消息数据转换成 JSON 字符串,从 data 节点中获取表最新数据(批量操作可能是多条)。然后根据操作类型 UPDATE、 INSERT、DELETE 执行 缓存更新或者删除方法。
当然,我们也可以使用 canal 提供的标准 API CanalMQConnector 接口
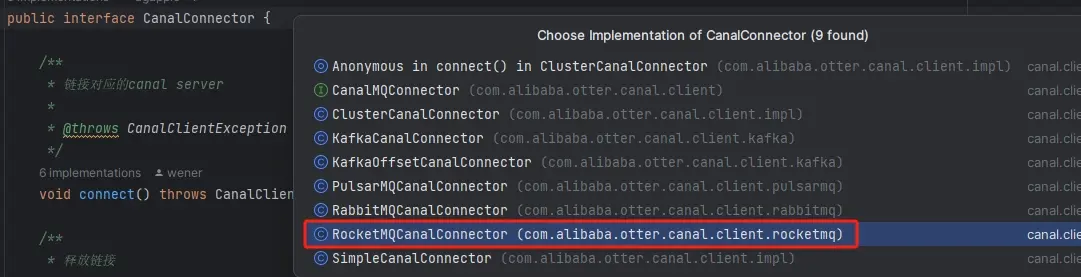
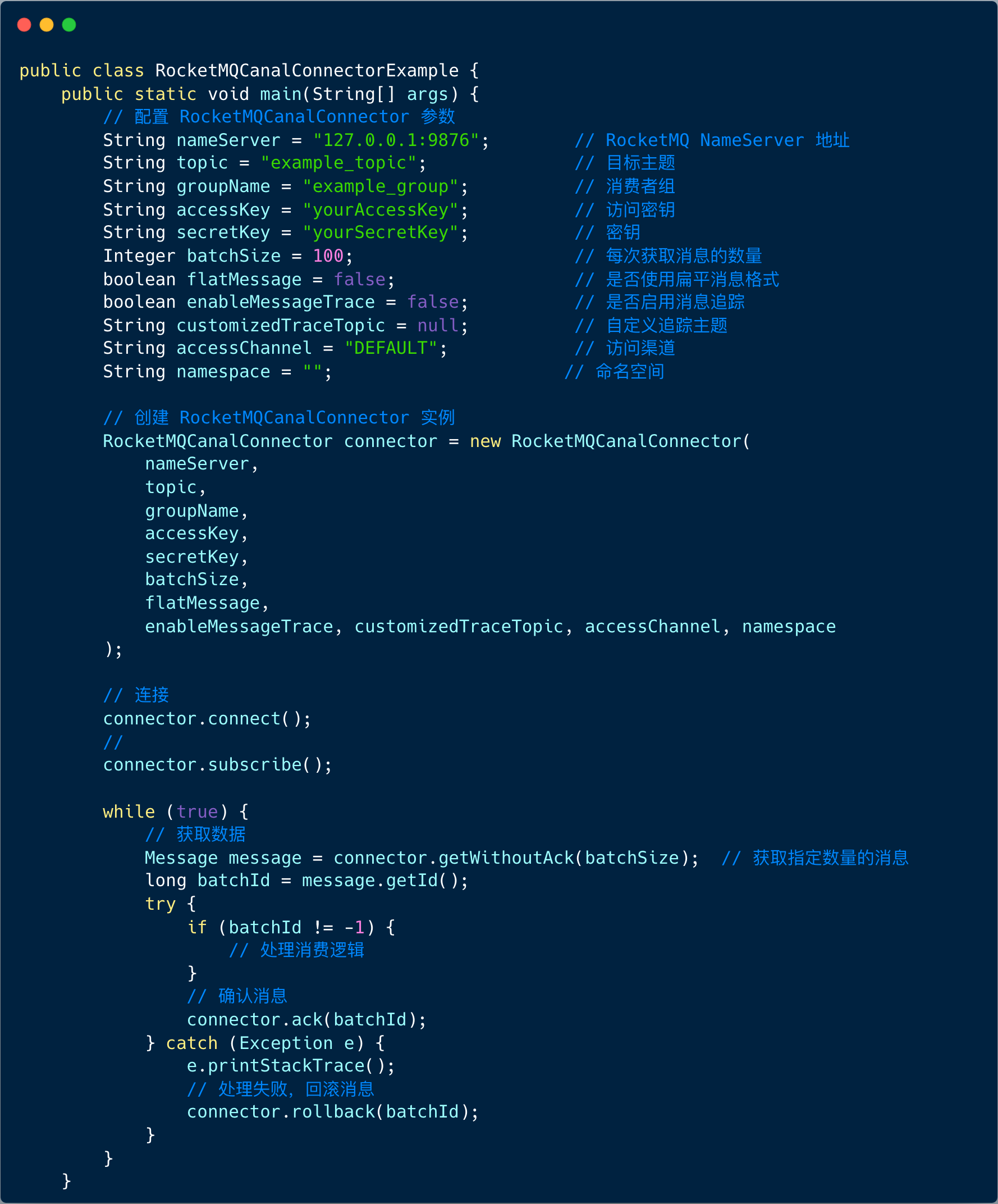
TCP 模式使用的是 ClusterCanalConnector ,而 RocketMQ Client 则是使用 RocketMQCanalConnector 。
编程范式如下图:
7. 总结
1、Canal 基本原理
canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 请求。MySQL master 收到 dump 请求,开始推送 binary log 给 canal ,canal 解析 binary log 对象( 原始为 byte 流 ) ,将 binlog 数据分发给客户端。
2、应用场景
笔者曾服务与神州专车订单团队,Canal 主要应用于:分库分表增量同步和索引构建和实时维护。
3、MySQL 配置
- 先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式
- 授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限
4、TCP 模式和 MQ 模式
Canal 包含 TCP 和 MQ 两种模式,TCP 模式是 Canal client 直接和 Canal Server 连接,而 MQ 模式 最大的优势是解耦,客户端只需要和 MQ 交互即可。