改写类型为四种,分别是:标识符改写、补列改写、分页修正、 批量拆分 。
这篇文章,我们聊聊 shardingsphere 改写引擎的「 标识符改写」的底层原理。
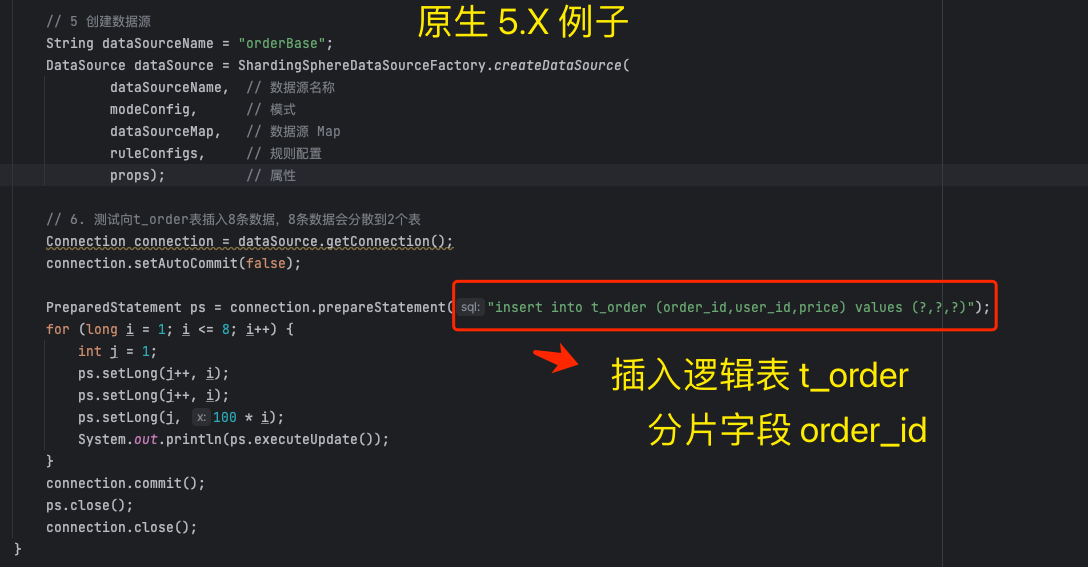
标识符改写使用的例子是:
1. 内核处理器KernelProcessor
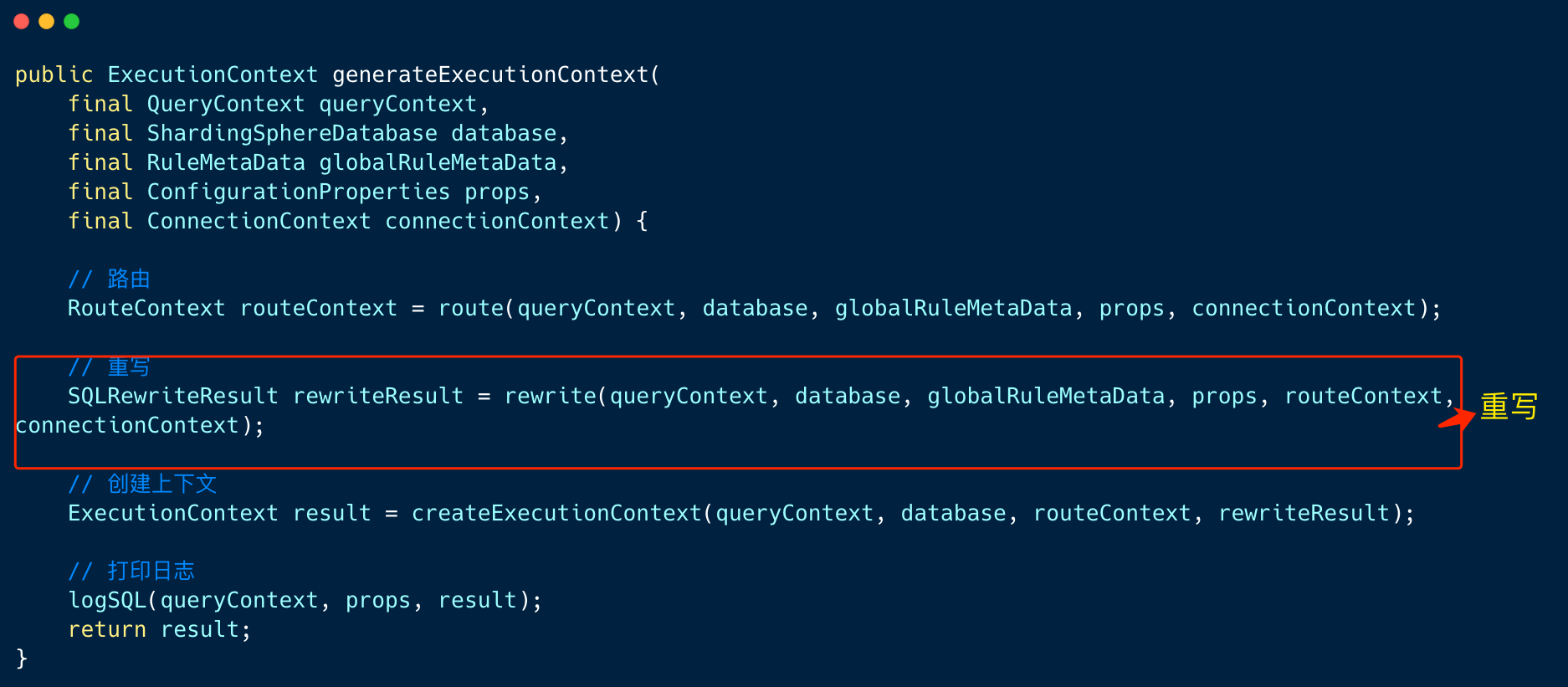
shardingsphere 内核处理器在生成「 执行上下文」时,会执行三个操作,分别是: 路由、改写、创建执行上下文。
生成路由结果之后,接下来就是执行改写操作。
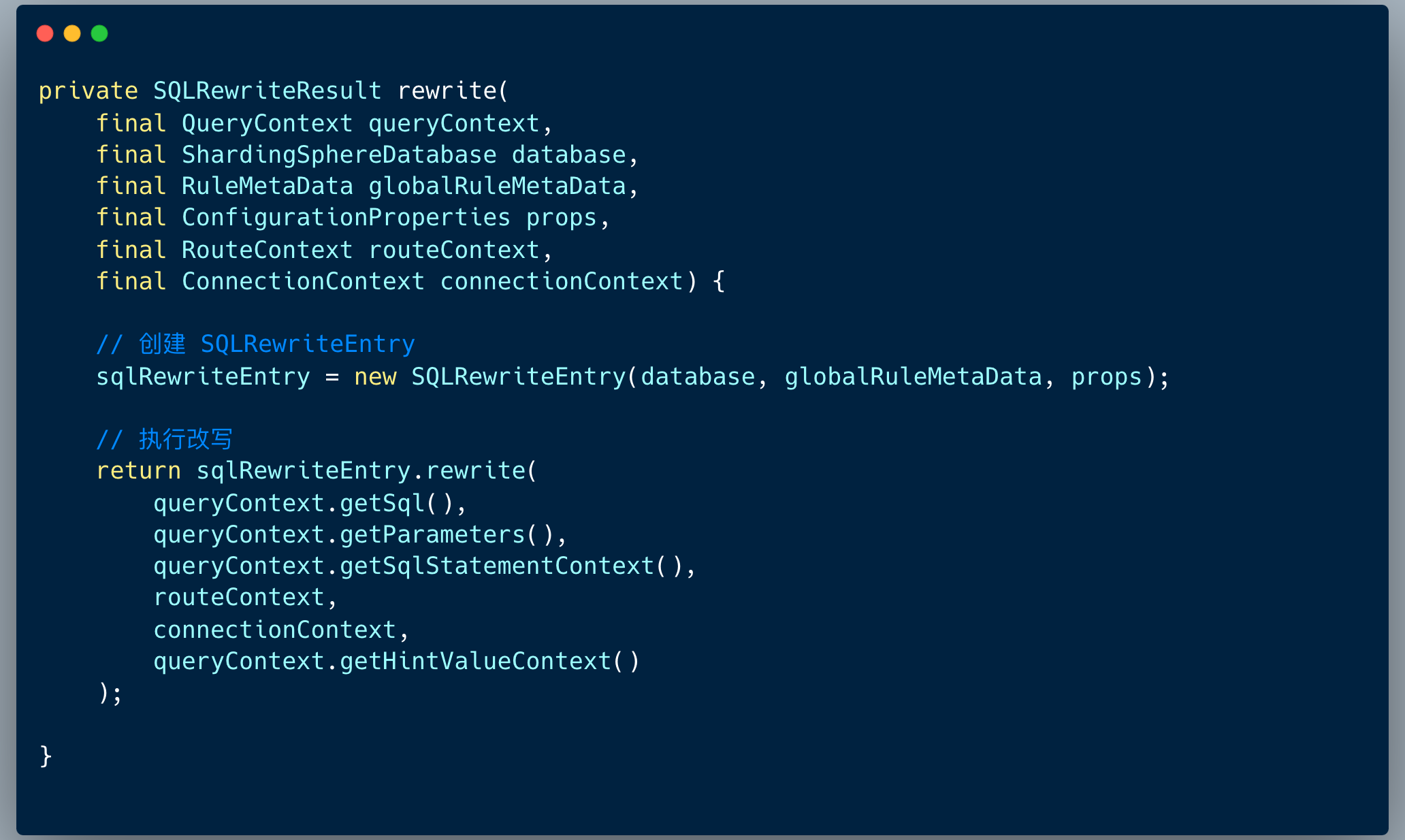
2. 核心流程一览
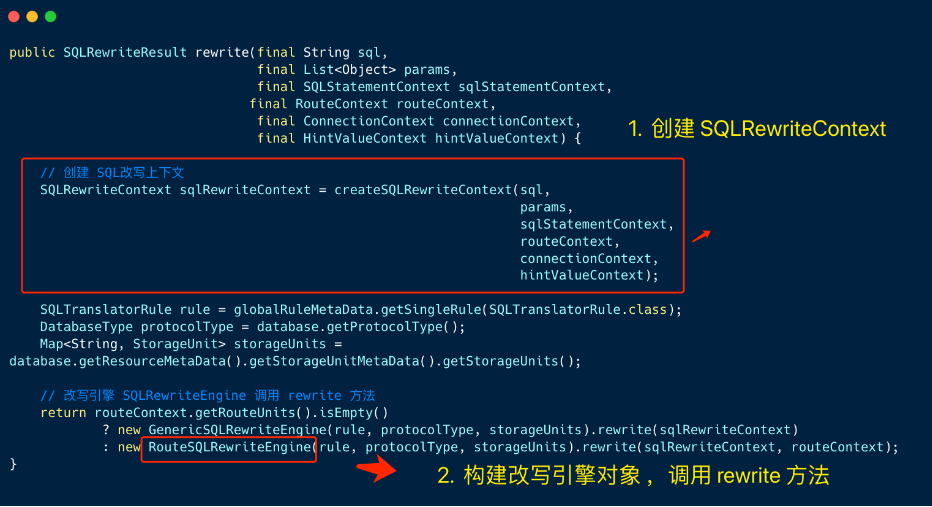
改写方法本质上分为两个步骤 :
1、创建 「SQL 改写上下文」SQLRewriteContext对象
2、构建改写引擎对象,并调用改写方法
3. 创建 「SQL 改写上下文」SQLRewriteContext对象
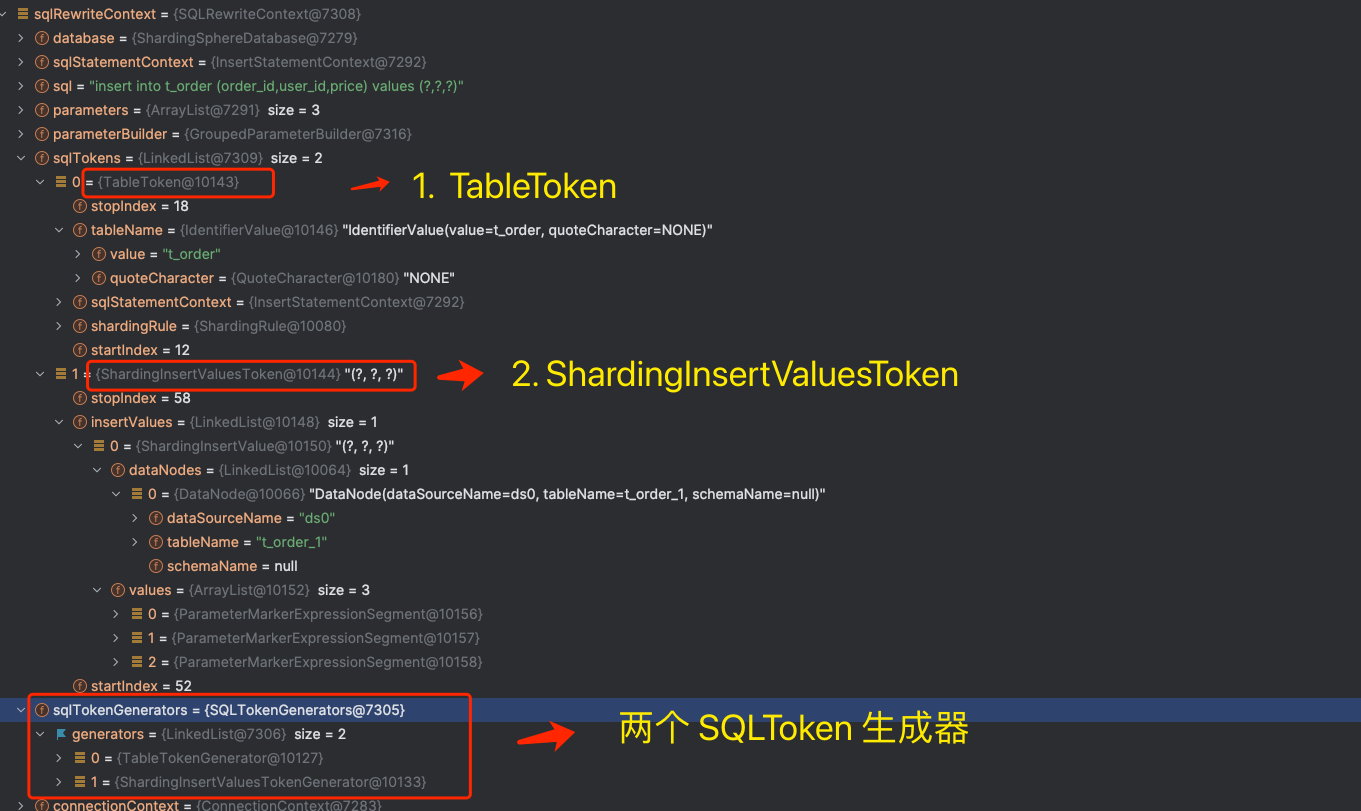
上图是 SQLRewriteContext 对象的 DEBUG 图,「SQL 改写上下文」包含两个对象:
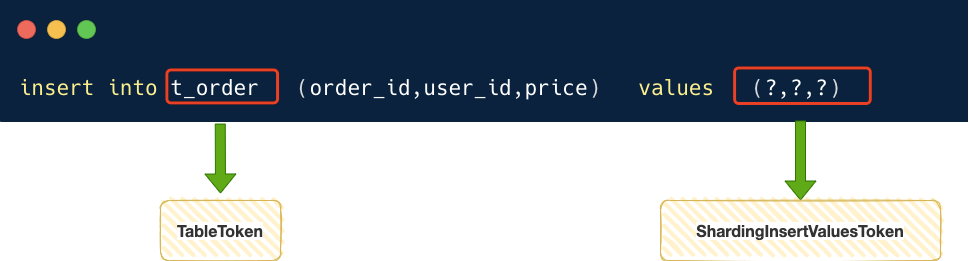
- SQLToken 列表 : 分别是 TableToken 和 ShardingInsertValuesToken 。
- SQLToken 生成器:用于生成 TableToken 、ShardingInsertValuesToken 。
SQLTokenGenerator 通过 ShardingTokenGenerateBuilder 类来处理 ,见如下的代码:
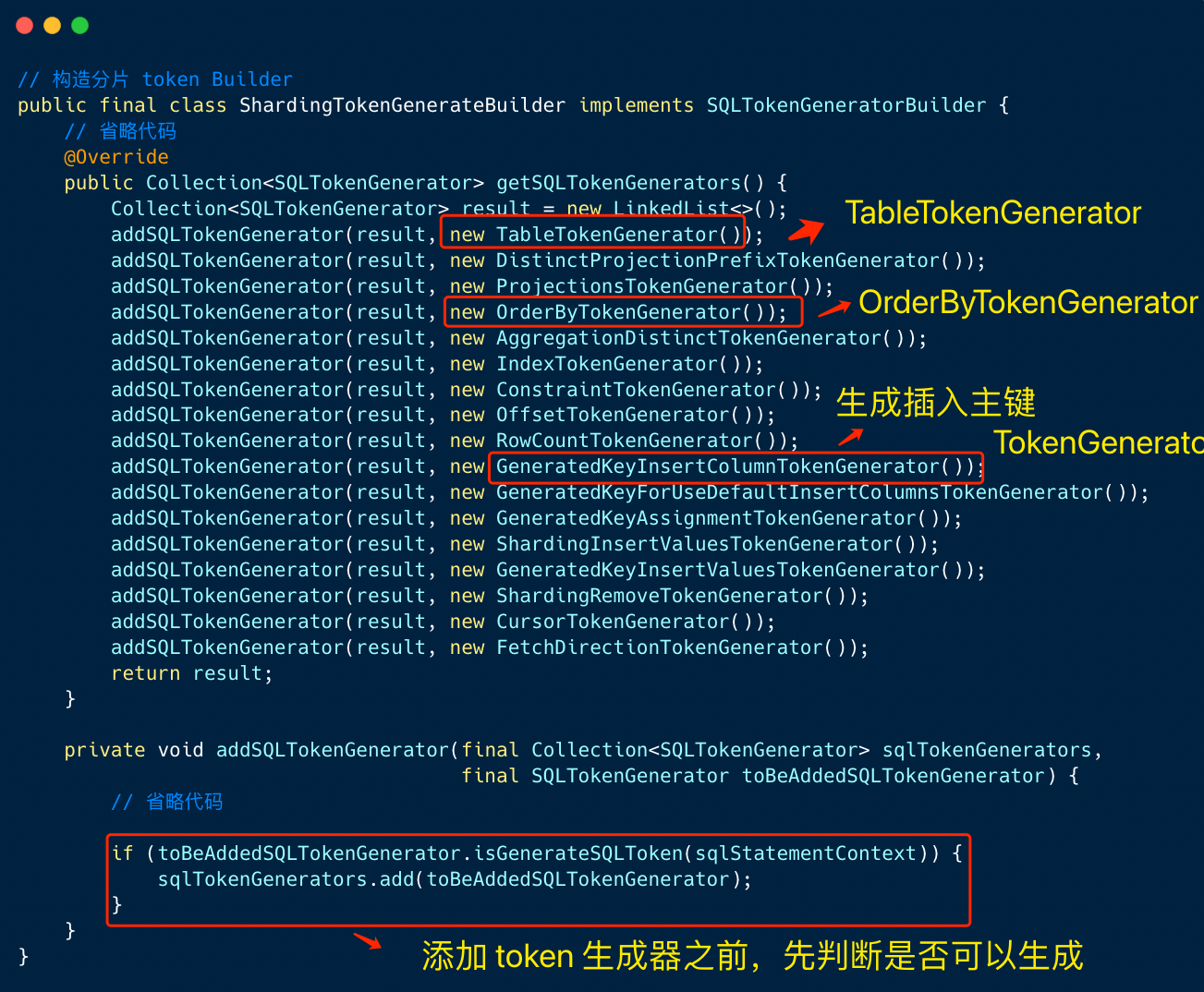
如上图,Token 生成器构建器在创建 SQLTokenGenerator 列表时,会首先会根据域模型上下文 SQLStatementContext 对象(此处是解析引擎生成的对象)判断是否需要生成 SQLToken 。
- TableTokenGenerator 的判断规则
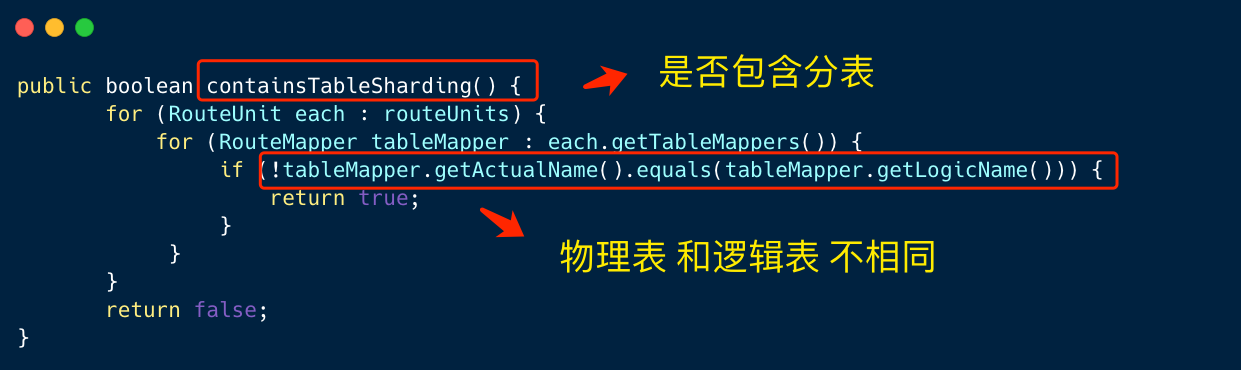
路由单元中,若物理表和逻辑表不同,则可以推论包含分表。
- ShardingInsertValuesTokenGenerator 的判断规则

我们构建了两个 SQLToken 对象,分别是:TableTokenGenerator 和 ShardingInsertValuesTokenGenerator 。
最后,遍历 SQLToken 列表 ,一条一条执行 generateSQLToken 方法 ,生成一条一条 SQLToken 对象。
4. 构建改写引擎对象,并调用改写方法
下图是 SQL 改写结果 DEBUG 图:

改写结果存储在一个 LinkedHashMap 中 ,见下图:

即: 一个路由单元映射一个 SQL 改写单元 。
改写引擎的改写核心方法如下:
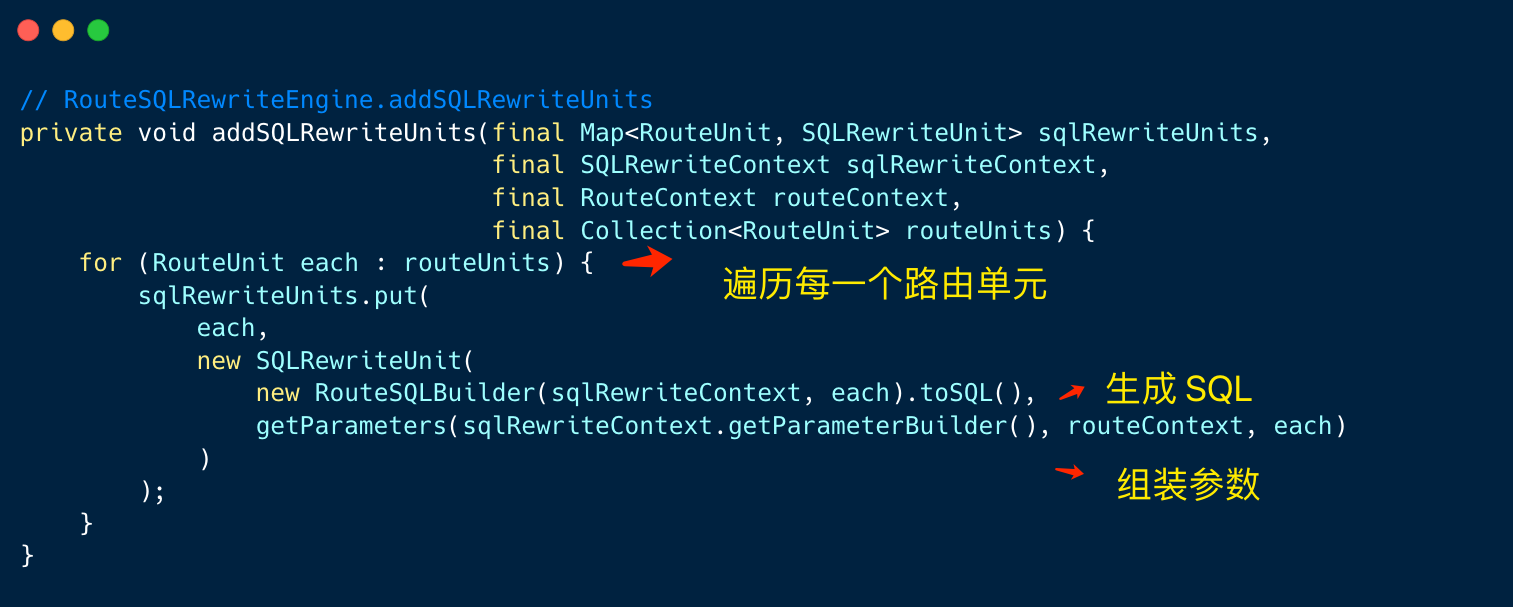
路由单元和组装参数非常容易获取,但生成真实的 SQL是其中最关键的点。
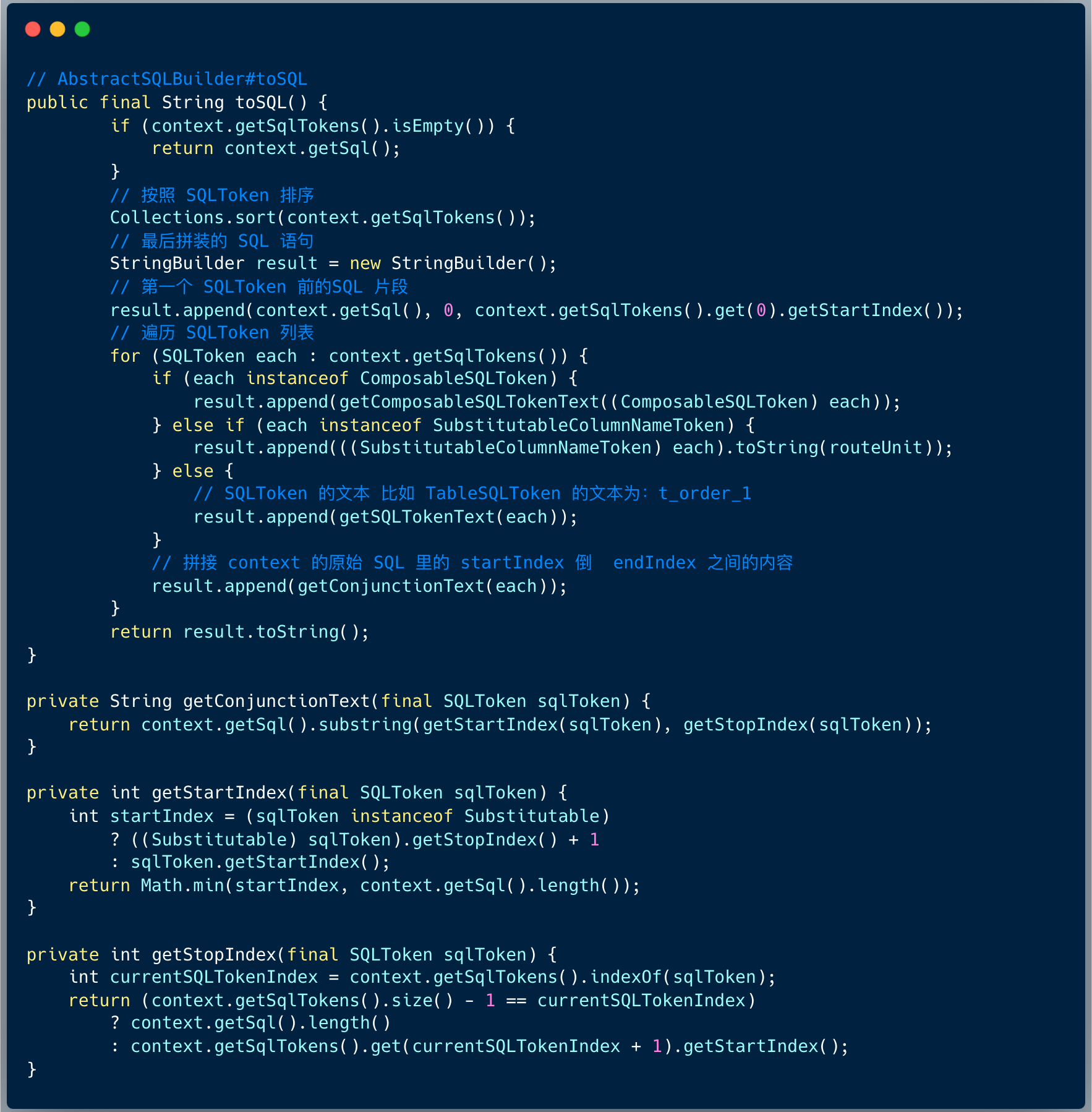
拼接真实的 SQL 思路如下:
- 按照 SQLToken 排序 ;
- 组装第一个 SQLToken 前的 SQL 片段 ;
- 遍历 SQLToken 列表 ,拼接 SQLToken 的文本,比如 TableSQLToken 的文本为:t_order_1 ;
- 拼接下一个 SQLToken 之间的 SQL 片段
- 循环结束之后,组装成功。
示例拼接流程见下图:

5. 总结
改写引擎的实现原理是:
- 创建 「SQL 改写上下文」SQLRewriteContext对象 :
- SQLToken 列表 : 分别是 TableToken 和 ShardingInsertValuesToken 。
- SQLToken 生成器:用于生成 TableToken 、ShardingInsertValuesToken 。
- 遍历每一个路由单元,通过 SQLToken 以及原始 SQL 拼接成最终执行的真实 SQL 。
写到这里,当真实 SQL 拼接成功,同时路由单元都已保存时,就可以执行 SQL了。