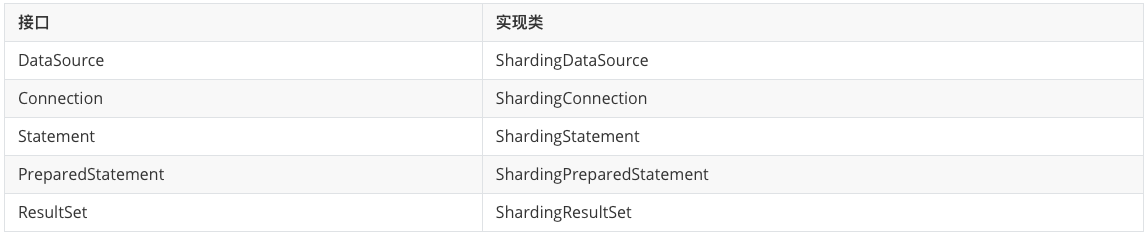
1. 数据源DataSource接口
1 | public interface DataSource extends CommonDataSource, Wrapper { |
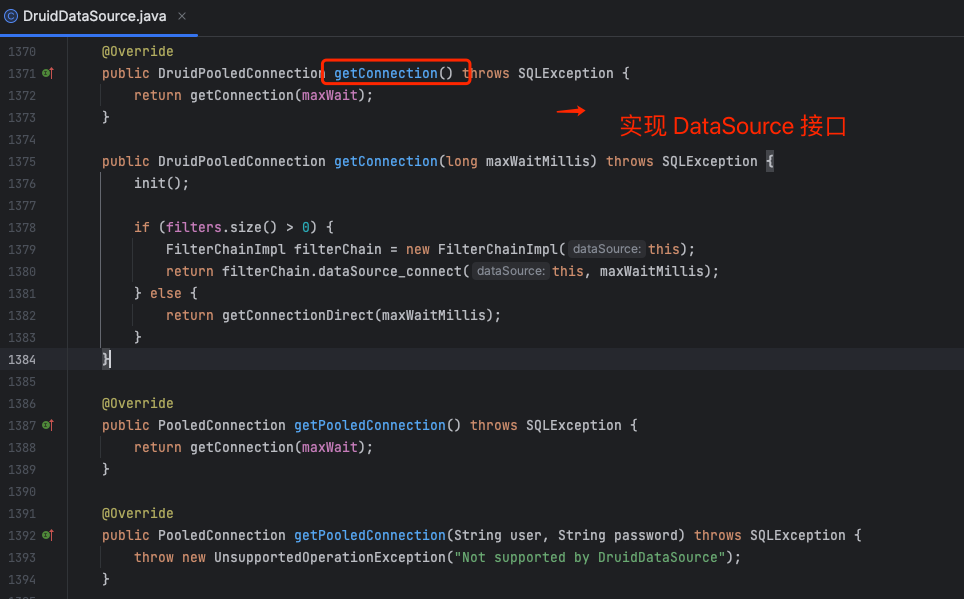
图中 Druid 连接池实现了 DataSource 的两个核心接口(获取连接), 因此我们可以非常简单获取连接并执行 JDBC 操作。
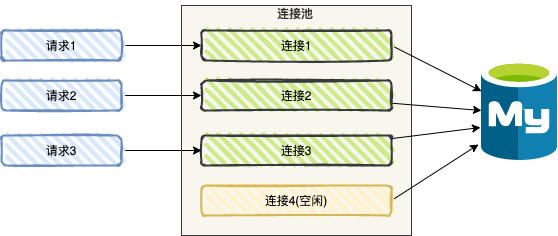
2. shardingsphere-JDBC本质是一个数据源连接池
下图展示了 shardingsphere jdbc 4.X 源码:
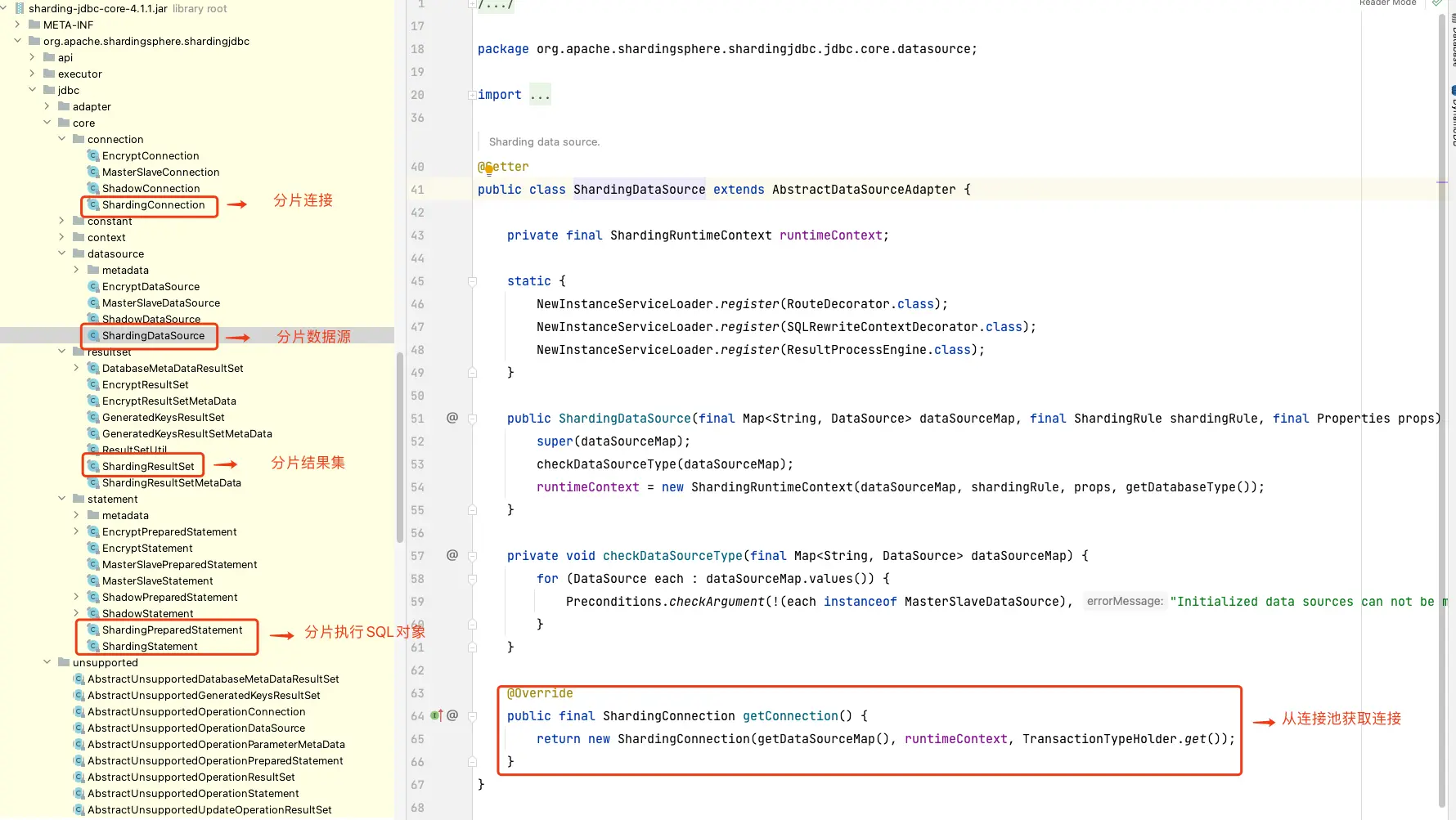
和 Druid 一样,shardingsphere-JDBC 本质是一个数据源连接池 ,只不过它可以管理多个数据源,同时配置分片规则,当执行 SQL 时,根据分片规则,路由到相应分片,并执行,当然它的内部机制实现相比之下更复杂而已。
3. 使用shardingsphere-JDBC原生API编写一个入门例子
需求:一个库中有 2 个订单表,按照订单 id 取模,将数据路由到指定的表。
1 | drop database if exists sj_ds0; |
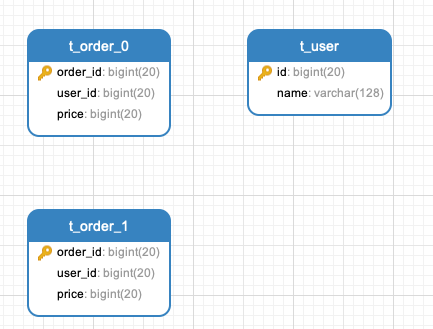
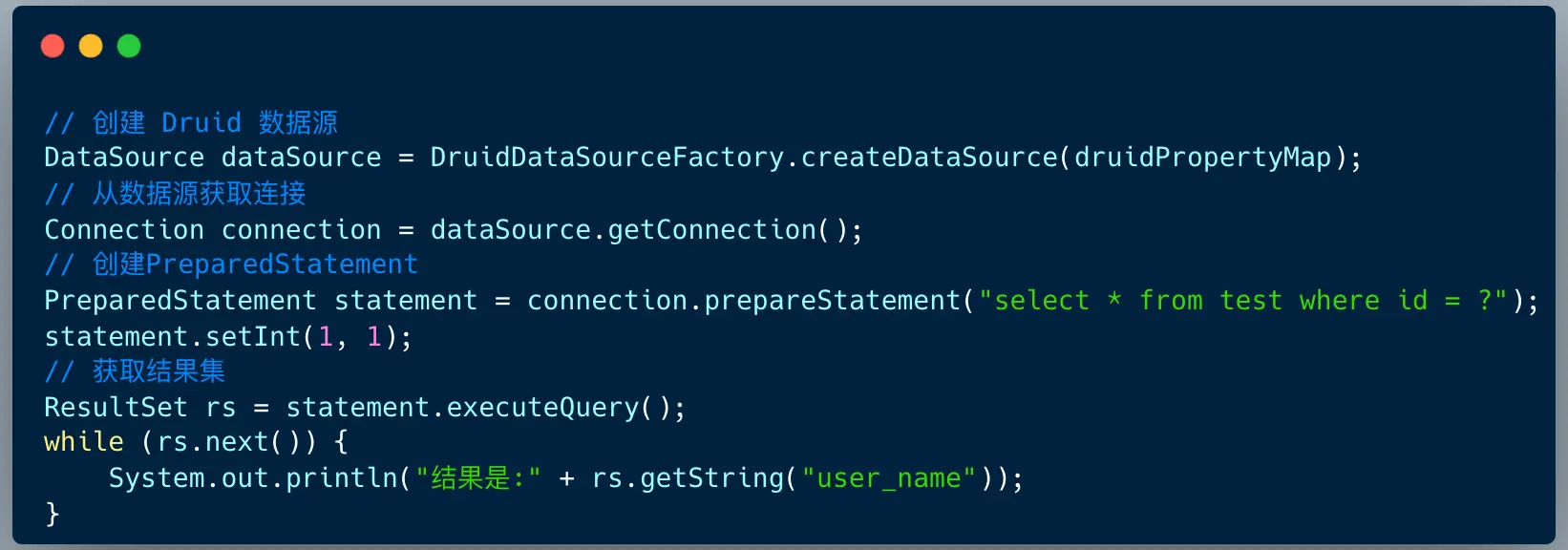
演示代码如下:
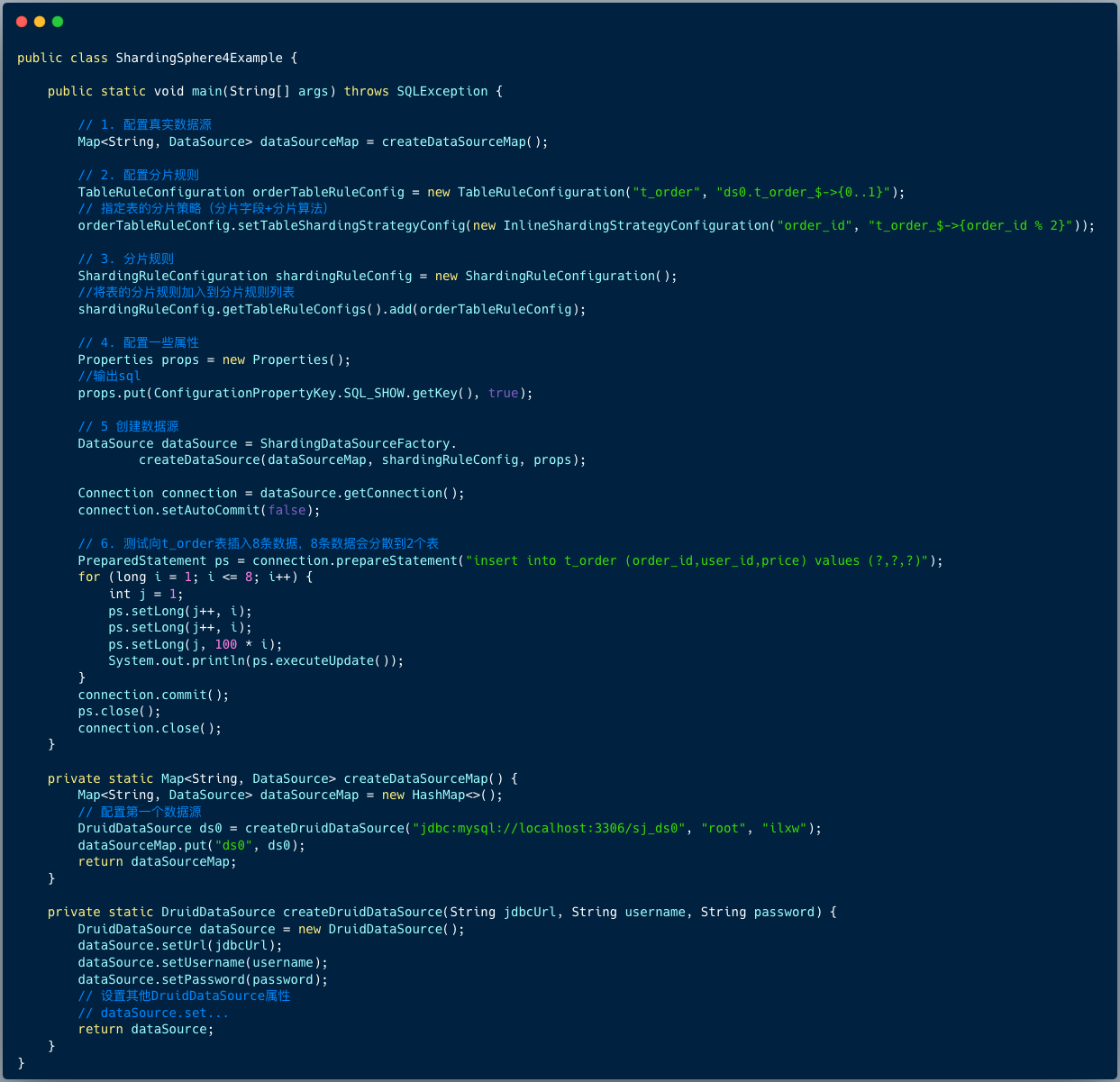
代码逻辑流程:
1、配置真实数据源
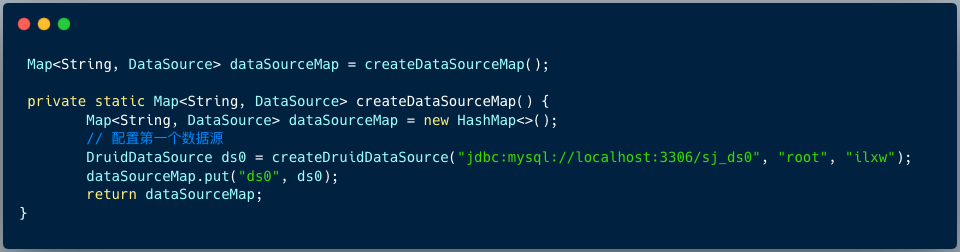
2、 配置分表规则

首先,定义分表规则 ,逻辑表名叫 t_order , ds0.t_order_$->{0..1} 是 grovvy 表达式,它对应的真实表是 ds0.t_order_0, ds0.t_order_1 ,
接着,内置的分片算法,分片字段是 order_id , 规则是:orderId % 2的结果就是将orderId除以2所得的余数,它的取值范围是 0或 1 。
3、 将分表规则添加到分片规则列表

4、 配置属性

建议在调试/开发阶段输出分片执行日志,方便调试。
5、 创建数据源

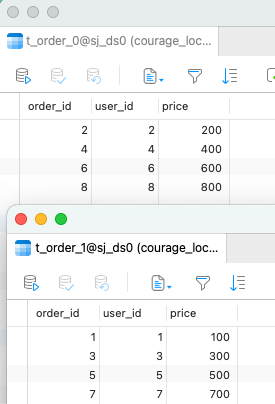
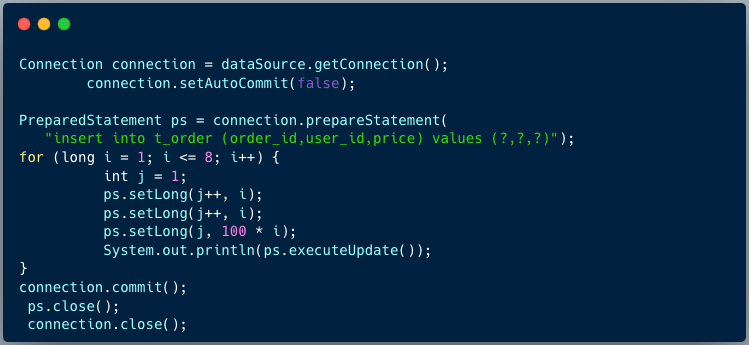
6、 获取连接,测试向t_order表插入8条数据,8条数据会分散到2个表
启动应用后,控制台显示如下:
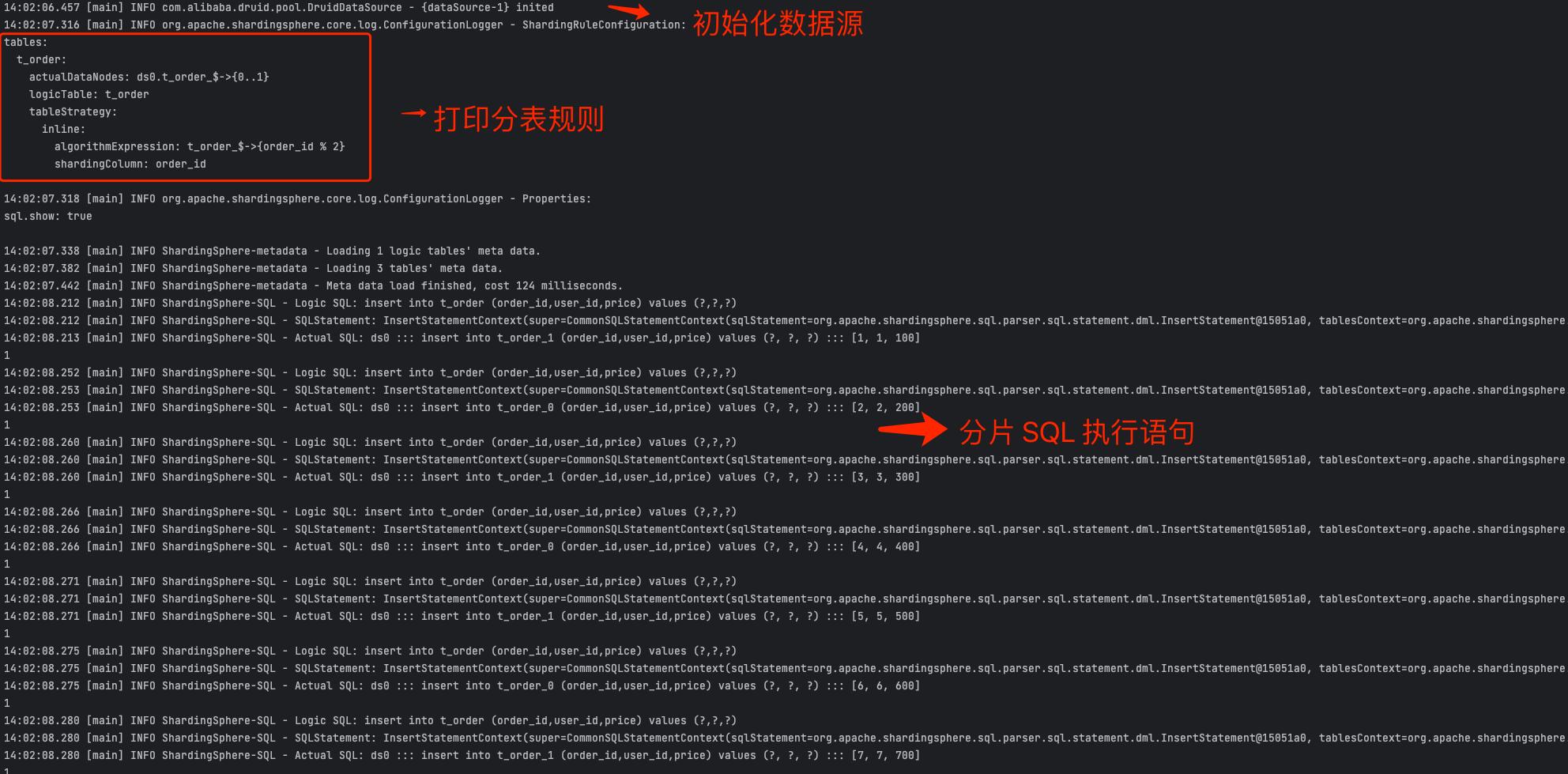
查看数据库表,发现 8 条数据均匀分布到两张订单表里。