1. 通用唯一标识符
UUID 是通用唯一标识符(Universally Unique Identifier)的缩写。UUID 是一种用于标识信息的标准化方法,其目的是确保在分布式系统中不同节点生成的标识符是唯一的。
UUID 是一个 128 位的数字,通常表示为 32 个十六进制数字,形如 “550e8400-e29b-41d4-a716-446655440000”。它是由以下几部分组成:
- 当前时间戳: 60 位。通常是自1582年10月15日至今的100纳秒间隔的数量,以格林尼治标准时间(GMT)表示。
- 时钟序列: 14 位。通常是一个随机或伪随机数字,以防止同一节点在同一时间生成多个 UUID。
- 节点标识: 48 位。通常是设备的硬件地址,或者在没有硬件地址的情况下,可以使用其他唯一标识符。
- 保留位:2位
- 版本:4位
下图展示 Java 应用中如何生成 UUID 。
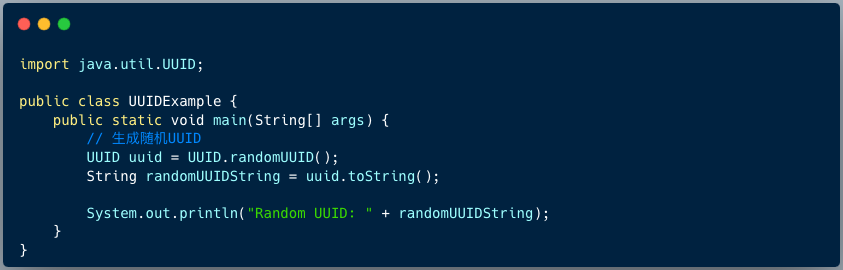
由于 UUID 的设计目标是在分布式系统中确保唯一性,因此可以用于生成唯一的标识符,而不必在全局范围内协调标识符的分配。它常被用于数据库、网络通信协议、操作系统等各种场景中,以确保生成的标识符不会冲突。
笔者一般会将 UUID 做为唯一请求的标识,而不是用来做为数据库表的主键 ID 。
如果将 UUID 用作数据库主键,可能会出现一些问题。
1、生成的 UUID 不具备单调递增性,即不是有序的。在系统设计中,有序的主键通常有其优势,尤其是当主键可能成为排序字段时。
2、另一个原因在于 ID 有序也会提升数据的写入性能。
我们知道 MySQL InnoDB 存储引擎使用 B+ 树 存储索引数据,而主键也是一种索引。
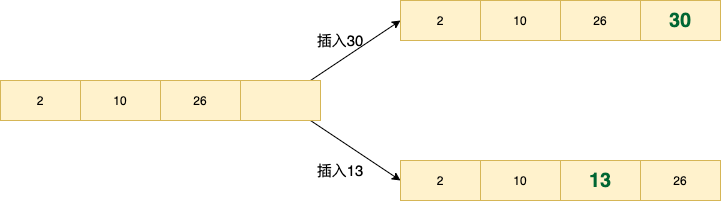
索引数据在 B+ 树 中是有序排列的,就像下面这张图一样,图中 2,10,26 都是记录的 ID,也是索引数据。

这时,当插入的下一条记录的 ID 是递增的时候,比如插入 30 时,数据库只需要把它追加到后面就好了。但是如果插入的数据是无序的,比如 ID 是 13,那么数据库就要查找 13 应该插入的位置,再挪动 13 后面的数据,这就造成了多余的数据移动的开销。
在机械磁盘上进行随机写入时,必须首先进行「寻道」操作,以定位到要写入的位置,即让磁头找到相应的磁道。这一寻道的过程通常是相当耗时的。
相比之下,顺序写入则无需进行寻道操作,从而极大提高了索引的写入性能。
3、UUID 不具备业务含义。
现实世界中使用的许多 ID 都包含了一些有意义的信息,这些信息通常出现在 ID 的特定位置上。
举例来说,身份证的前六位表示地区编号,接下来的八位表示持有人的生日;不同城市的电话号码区号也是不同的;手机号的前三位可以用于确定所属运营商。这种设计使得ID不仅仅是一个唯一标识符,还包含了一定的可读信息。
如果生成的 ID 可以被反解,也就是从 ID 中提取出有意义的信息,那么我们可以对 ID 进行验证。通过反解,我们可以获取 ID 的生成时间、发号器所在的机房、为哪个业务服务等信息。这对于问题的排查和追溯提供了一定的帮助。
4、 UUID 是由 32 个 16 进制数字组成的字符串,如果作为数据库主键使用比较耗费空间。
正因为 UUID 方案存在一些明显的局限性 ,接下来笔者将介绍 Twitter 提出的雪花 Snowflake 算法,它能够弥补UUID的不足。
雪花算法不仅实现简单,而且满足了 ID 需要的全局唯一性和单调递增性,同时还包含了一定的业务上的意义。
2. 原生雪花算法
雪花算法的核心思想是将 64bit 的二进制数字分成若干部分,每一部分都存储有特定含义的数据,比如说时间戳、机器 ID、序列号等等,最终生成全局唯一的有序 ID。
它的标准算法是这样的:

上图中我们可以看到,41 位的时间戳假如从 0 开始计算大概可以支撑 pow(2,41)/1000/60/60/24/365 年,约等于 69 年,对于一个系统是足够了。但如果以当前时间开始算, 则可用的只有不到 20 年了( 69-(2019-1970) ),实现时可以不以 1970 年为基准时间。
如果你的系统部署在多个机房,那么 10 位的机器 ID 可以继续划分为 2~3 位的 IDC 标示(可以支撑 4 个或者 8 个 IDC 机房)和 7~8 位的机器 ID(支持 128-256 台机器);12 位的序列号代表着每个节点每毫秒最多可以生成 4096 的 ID(2的12次方)。
3. 定制雪花算法
不同公司也会依据自身业务的特点对雪花算法做一些改造,比如说减少序列号的位数增加机器 ID 的位数以支持单 IDC 更多的机器,也可以在其中加入业务 ID 字段来区分不同的业务。
比方: 1 位兼容位恒为 0 + 41 位时间信息 + 6 位 IDC 信息(支持 64 个 IDC)+ 6 位业务信息(支持 64 个业务)+ 10 位自增信息(每毫秒支持 1024 个号)。
通过这种方式,可以将业务信息嵌入到雪花算法生成的 ID 里,通过 ID 也可以反解出哪个业务生成的编号。
了解了雪花算法的原理之后,我们如何把它工程化,来为业务生成全局唯一的 ID 呢。
1、嵌入到业务代码里,也就是分布在业务服务器中。
这种方案的好处是业务代码在使用的时候不需要跨网络调用,性能上会好一些,但是就需要更多的机器 ID 位数来支持更多的业务服务器。另外,由于业务服务器的数量很多,我们很难保证机器 ID 的唯一性,所以就需要引入 ZooKeeper 等分布式一致性组件来保证每次机器重启时都能获得唯一的机器 ID。
2、作为独立的服务部署,这也就是我们常说的发号器服务。
业务在使用发号器的时候就需要多一次的网络调用,但是内网的调用对于性能的损耗有限,却可以减少机器 ID 的位数,如果发号器以主备方式部署,同时运行的只有一个发号器,那么机器 ID 可以省略,这样可以留更多的位数给最后的自增信息位。即使需要机器 ID,因为发号器部署实例数有限,那么就可以把机器 ID 写在发号器的配置文件里,这样即可以保证机器 ID 唯一性,也无需引入第三方组件了。
雪花算法的设计非常简单而巧妙,性能也相当高效,它能够生成具有全局唯一性、单调递增性,并且带有业务含义的ID。
然而,它也存在一些缺点,其中最显著的就是对系统时间戳的依赖。一旦系统时间不准确,就有可能生成重复的 ID。因此,如果发现系统时钟不准确,可以让发号器暂时拒绝发号,直到时钟同步为止。
此外,如果请求发号器的 QPS 不高,比如每毫秒只发一个 ID,可能导致生成的 ID 的末位始终是1。这在分库分表时,如果将 ID 用作分区键,就可能导致库表分配不均匀。在实际项目中,解决方法主要有两个:
- 记录时间戳时不记录毫秒,而是记录秒,这样在一个时间区间内可以生成多个ID,避免在分库分表时数据分配不均匀。
- 对生成的序列号的起始号进行随机化,例如这一秒是 21 ,下一秒是 30 ,这样可以尽量均衡分配。
其他发号器: