订单分库分表完成之后,用户可以在 C 端查询自己的订单 ,每次操作数据库时,分片键是用户 ID ,可以快速定位到对应的分片,执行数据库操作。
但是这里面有一个非常有意思的问题: 假如运营端想查看所有的订单,显示分页列表,那么如何设计呢 ?
1. 分库中间件聚合分页
使用分库分表中间件 shardingsphere-jdbc 实现分库分表之后,我们的第一反应:可不可以使用现成的中间件实现聚合分页 ?
传统的分页组件一般包括两项:
- 查询分页数据
- 为了展示页码,查询总的记录数
我们做一个简单的测试:查询全量订单主表的第三页,以及订单总数。
1 | # 全量订单表 分页逻辑 SQL |
执行逻辑 SQL 如下 :
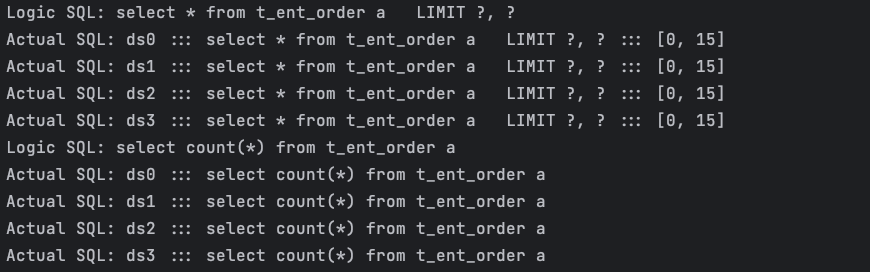
2、shardingsphere-jdbc 对分页 SQL 进行了改写,原来 limit 10 , 5 修改成了 0 , 15 即:取出所有前三页数据,再结合排序条件计算出正确的数据。
有的同学可能会问了,为什么会将 limit 10 , 5 改写成 0 , 15 呢 ?
因为从多个分片获取分页数据与单个分片的场景是不同的,我们举个简单的l例子说明,若 SQL 为:
1 | SELECT score FROM t_score ORDER BY score DESC LIMIT 1, 2; |
下图展示了不进行 SQL 的改写的分页执行结果:
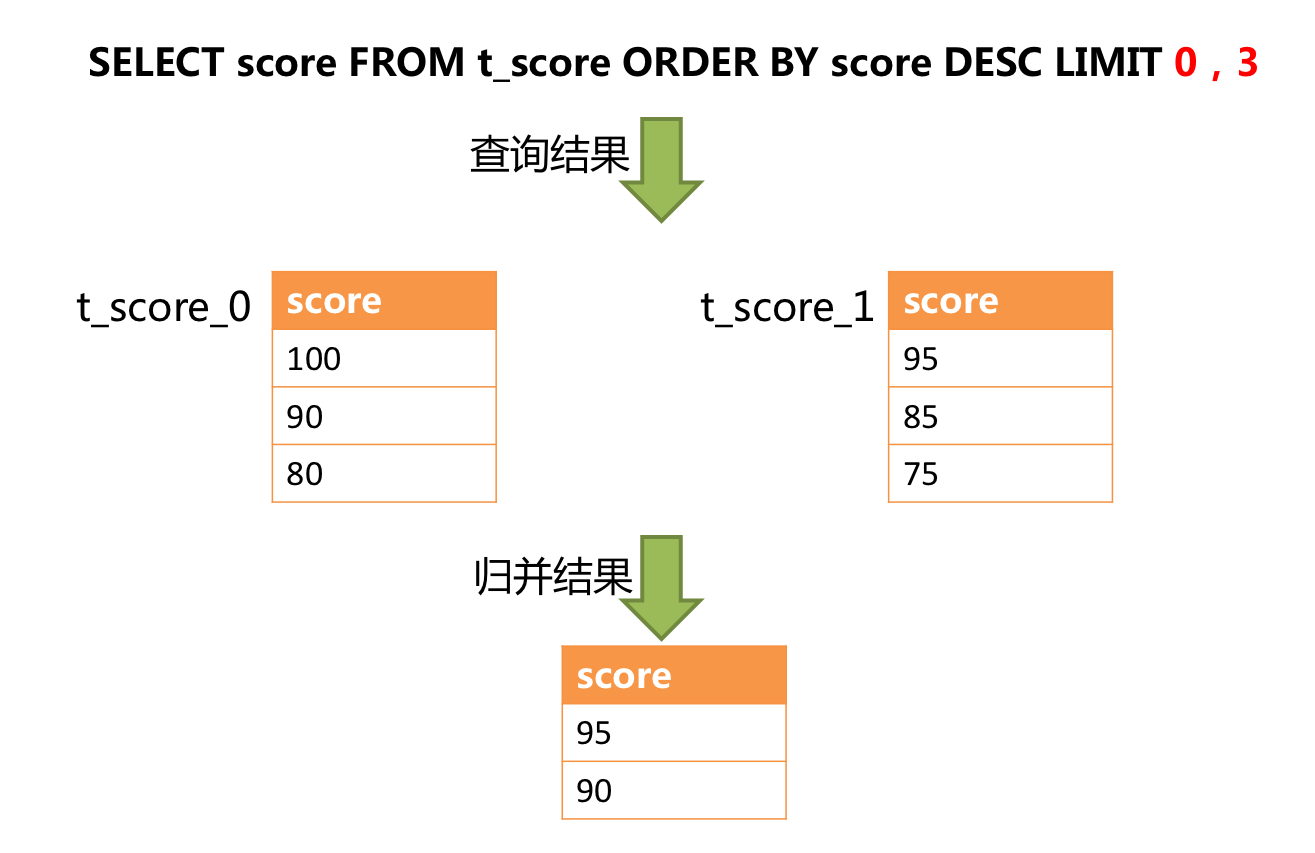
通过图中所示,想要取得两个表中共同的按照分数排序的第 2 条和第 3 条数据,应该是 95 和 90。
由于执行的 SQL 只能从每个表中获取第 2 条和第 3 条数据,即从 t_score_0 表中获取的是 90 和 80;从 t_score_1 表中获取的是 85 和 75。
因此进行结果归并时,只能从获取的 90,80,85 和 75 之中进行归并,那么结果归并无论怎么实现,都不可能获得正确的结果。
正确的做法是将分页条件改写为LIMIT 0, 3,取出所有前两页数据,再结合排序条件计算出正确的数据。
下图展示了进行 SQL 改写之后的分页执行结果:
其实,通过流式归并的原理可知,会将数据全部加载到内存中的只有内存分组归并这一种情况。而通常来说,进行 OLAP 的分组 SQL 不会产生大量的结果数据,它更多的是用于大量的计算,以及少量结果产出的场景。
除了内存分组归并这种情况之外,其他情况都通过流式归并获取数据结果集,因此 ShardingSphere 会通过结果集的 next 方法将无需取出的数据全部跳过,并不会将其存入内存。
但同时需要注意的是,由于排序的需要,大量的数据仍然需要传输到 ShardingSphere 的内存空间。因此,采用 LIMIT 这种方式分页,并非最佳实践。
由于 LIMIT 并不能通过索引查询数据,因此如果可以保证 ID 的连续性,通过 ID 进行分页是比较好的解决方案。
1 | SELECT * FROM t_order WHERE id > 100000 AND id <= 100010 ORDER BY id; |
或通过记录上次查询结果的最后一条记录的ID进行下一页的查询,例如:
1 | SELECT * FROM t_order WHERE id > 10000000 LIMIT 10; |
综上,使用 shardingsphere 聚合分页特点如下 :
- 越获取偏移量位置靠后数据,使用 LIMIT分 页方式的效率就越低。
- 如果可以保证 ID 的连续性,通过 ID 进行分页( between )提升分页效率或者可以通过记录上次查询结果的最后一调记录的 ID 进行下一次查询 。
- 分片数越多,执行的逻辑 SQL 数会越大 ,延迟越高。
但是在生产环境中,笔者很少看到运营端使用中间件实现分页,笔者认为原因有几点:
1、运营端可能包含数据统计,数据导出等复杂 SQL ,而 shardingsphere 对于复杂的 SQL 并不是完全可以覆盖 。
2、数据层各司其职,N 个分片数据库负责前端访问 , 而异构的数据库负责运营端访问 。
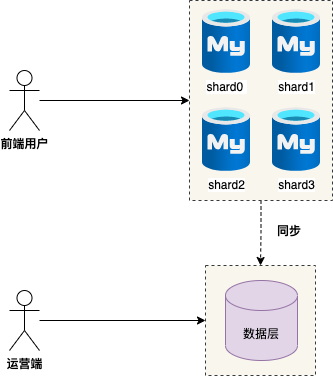
接下来,笔者介绍三种用于运营端查询异构数据层:
- 异构到全量 MySQL
- 异构到 ElasticSearch 集群
- 异构到 Tidb 集群
2. 异构到全量Mysql订单库
笔者曾经服务于神州专车订单团队,分库分表之后,架构团队构建了一个全量订单库(MySQL),该数据库用于运营端查询。
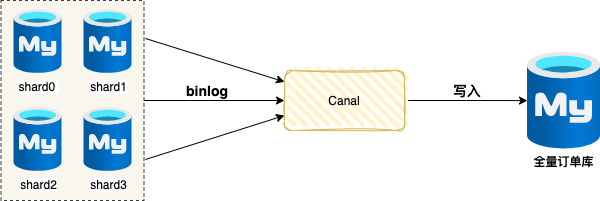
该全量订单库包含所有订单数据,也支持各种复杂查询。但因为它是一个计算单点,同时随着时间的推进,数据量越来越大,极其容易出现性能瓶颈。
比如,分页页面经常需要展示订单总数,当订单主表数据达到 1亿时,count(1) 竟然会达到 1分钟 ,这样影响前端的体验。
1 | select count(1) from t_ent_order |
为了规避这个问题,订单团队临时在页面屏蔽了显示订单总数,那么如何解决这个问题呢 ?
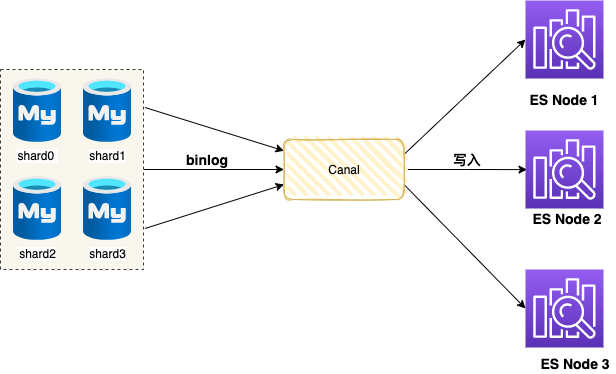
接下来,订单团队引入了 ElasticSearch ,即将订单数据异构到 ElasticSearch 集群。
3. 异构到ElasticSearch集群
Elasticsearch 是一个非常著名的开源搜索和分析系统,目前被广泛应用于互联网的多个领域中,尤其在以下三个领域中表现尤为突出:
1. 搜索领域
Elasticsearch 相对于 Solr,可以被视为真正的后起之秀,成为很多搜索系统的不二之选。它提供了强大的全文搜索功能,并. 且易于扩展,支持分布式架构。
2. JSON 文档数据库
相对于 MongoDB,Elasticsearch 的读写性能更佳,并且支持更丰富的地理位置查询,以及数字、文本的混合查询等功能,使其成为处理复杂查询场景的理想选择。
3. 时序数据分析处理
Elasticsearch 在日志处理、监控数据的存储、分析和可视化方面做得非常出色,可以说是该领域的引领者。它不仅能够高效地处理大量的时序数据,还支持多种分析和可视化工具,非常适合实时监控和数据分析的需求。
因此,Elasticsearch 集群非常适合运营端检索场景,当面对订单分页场景(分页数据 + 订单总数)都可以轻松应付。异构到 ElasticSearch 同样需要全量同步和增量同步两种模式配合实现。
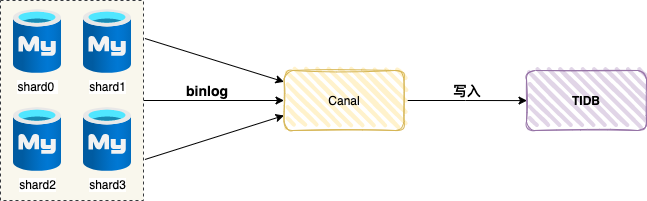
4. 异构到Tidb集群
TiDB 是一款开源分布式关系型数据库,可以同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP) 的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性,支持在本地和云上部署。
因为 TIDB 兼容 MySQL 5.7 协议 ,我们可以把 TiDB 当做一个可以自动扩缩容的 MySQL 。TIDB 存储所有订单数据的全集,同步方案大同小异,都是全量同步 + 增量同步。