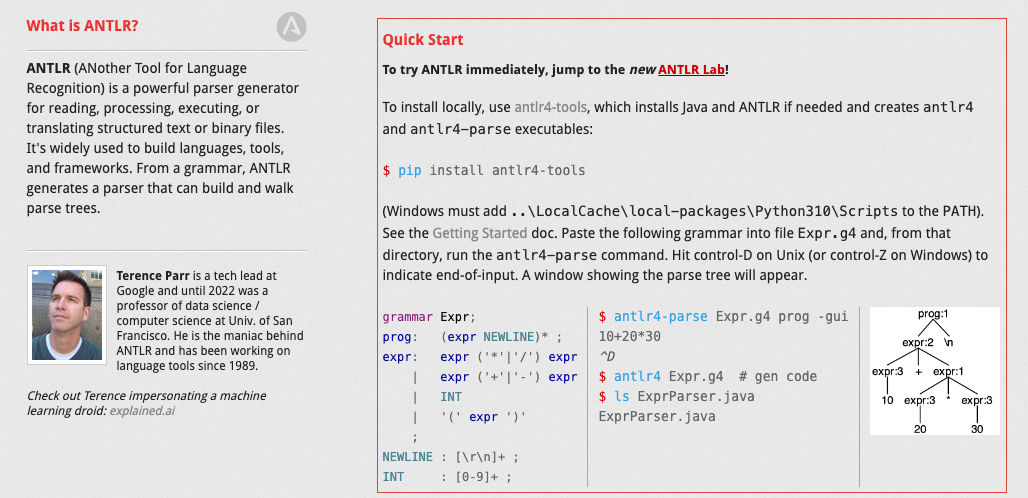
1. 什么是ANTLR
ANTLR 是一款强大的语法分析器生成工具,可用于读取、处理、执行或者翻译结构化文本或二进制文件。
ANTLR 根据语法,可以生成对应的语法分析器,并自动构建语法分析树(一种描述语法和输入文本匹配关系的数据结构),通过自动生成的语法分析树的遍历器,用户可以方便地执行自定义的业务逻辑代码。
ANTLR 被广泛应用于学术及工业领域,是众多语言、工具及框架的基石。Hive、ShardingSphere 使用 ANTLR 实现 SQL 的词法和语法解析,Hibernate 框架使用 ANTLR 来处理 HQL 语言。
除了这些著名的项目之外,还可以用 ANTLR 来构建各种实用的工具,例如:配置文件读取工具、历史代码转换工具、JSON 解析器等。
2. 安装ANTLR
ANTLR 由 Java 语言编写,因此在安装之前需要先安装 Java,ANTLR 运行需要的 Java 版本为 1.6 及以上。
安装 ANTLR 分为两个步骤:
- 下载最新的 JAR 包 antlr-4.8-complete.jar ;
- 设置环境变量
1 | cd /usr/local/lib |
配置完成后,可以通过如下的两种方式来检查 ANTLR 是否正确安装 :
1 | # 第一种:java -jar 直接运行 ANTLR 的 jar 包 |
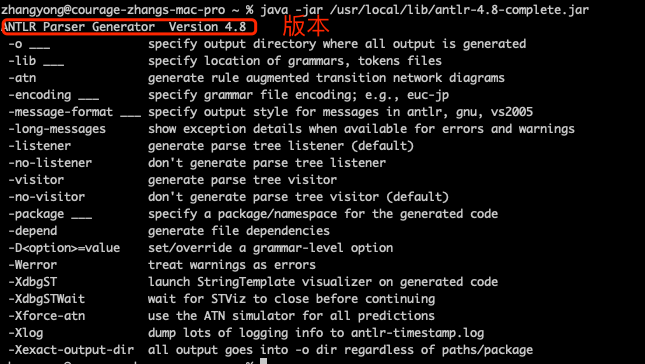
为了简化执行命令,可以设置如下别名,以后使用 antlr4 命令即可:
1 | alias antlr4='java -Xmx500M -cp "/usr/local/lib/antlr-4.8-complete.jar:$CLASSPATH" org.antlr.v4.Tool' |
3. helloWorld例子
首先来编写一个简单的 Hello World 例子来初步认识 ANTLR。
首先,需要创建一个语法文件HelloWorld.g4,用来描述基本的语法规范,文件内容如下:
1 | grammar HelloWorld; // 定义一个名为HelloWorld的语法 |
文件开头的 grammar HelloWorld 定义了语法名,ANTLR 中规定语法名必须和文件名保持一致。
r 为语法规则,必须以小写字母开头。ID 和 WS 为词法规则,必须以大写字母开头。定义好语法文件之后,需要使用前文定义的 antlr4 命令来生成词法分析器和语法分析器:
1 | # 生成词法分析器和语法分析器 |
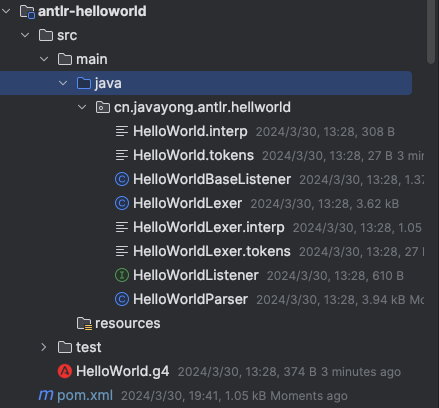
在 ANTLR 生成的所有文件中,主要作用如下:
1、词法分析器类 HelloWorldLexer.java
词法分析此阶段从左向右扫描源文件,将其字符流分割成一个个的词( token ) 。
所谓 token ,就是源文件中不可再进一步分割的一串字符,类似于英语中单词,或汉语中的词。
2、语法分析器类 HelloWorldParser.java
词法分析完成后,字符流就被转换为 token 流了,接下来根据语言的语法规则来解析这个 token 流,被称为语法分析。
语法分析的过程就是不断的将语法规则应用于源程序,将源程序解析成一颗抽象语法树( parser tree ),该树记录了语法分析器识别语句结构的过程;
3、HelloWorld.tokens
ANTLR 会给我们定义的词法符号指定一个数字形式的类型,然后将他们的对应关系存储到该文件中,通过 tokens 中的内容,ANTLR 可以在多个小型语法间同步全部的词法符号类型,tokens 内容如下:
1 | T__0=1 |
4、HelloWorldListener.java
ANTLR 默认会生成语法规则对应的语法分析树,在遍历语法分析树时,会触发一系列事件,并通知 HelloWorldListener 监听器对象。
我们编写一个 Main 函数来测试:
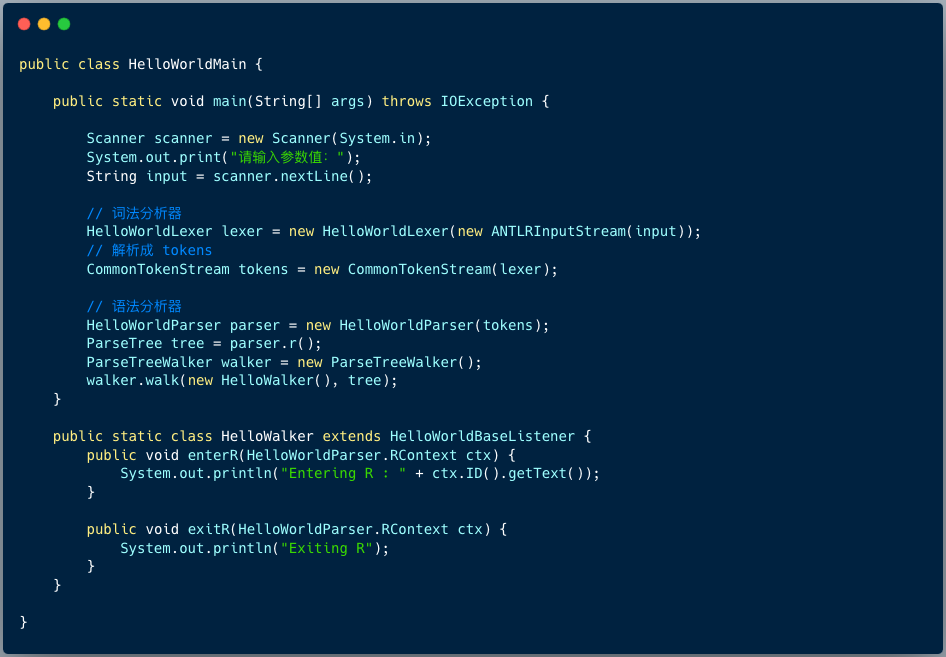
当输入正确的字符串 hello world 时,会显示如下图:
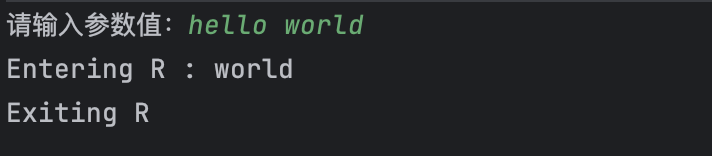
当我们输入不正确的字符串 mylife , 会显示如下图:
我们也可以安装 IDEA ANTLR 插件来验证,下图:
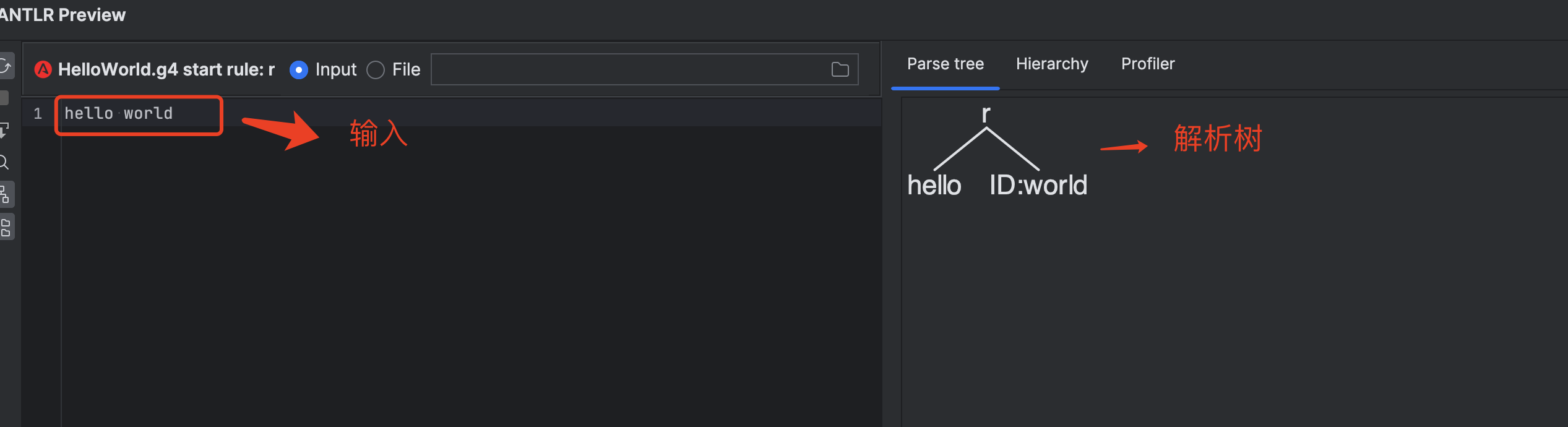
点击左下角的预览按钮,输入 hello world , 右侧的 panel 显示解析树。
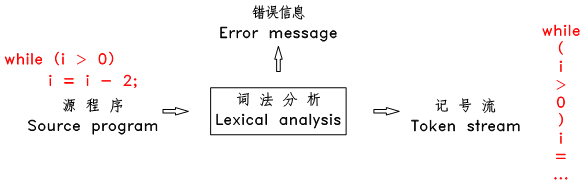
4. 词法分析器原理
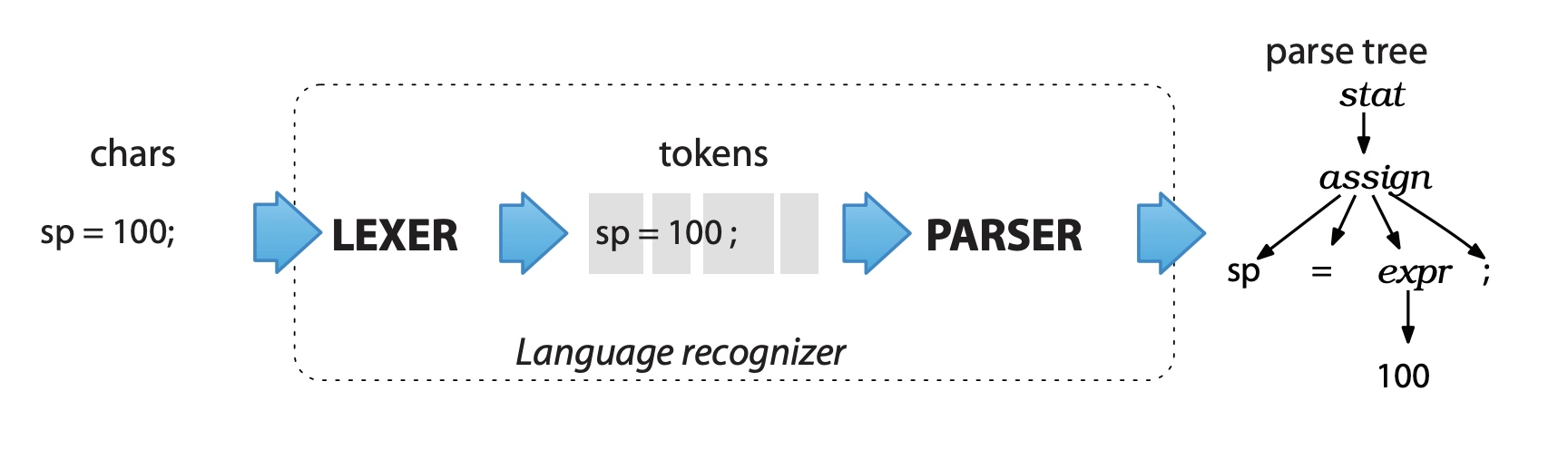
以赋值语句 sp = 100; 为例,ANTLR 会根据如下的语法规则生成词法分析器和语法分析器:
assign : ID ‘=’ expr ‘;’ ;
整个语法分析的过程如下:
ANTLR 工具根据前文定义的 assign 语法规则,会生成一个递归下降的语法分析器(recursive-descent parsers)。递归下降的语法分析器实际是若干递归方法的集合,每个方法对应一条规则,下降的过程就是从语法分析树的根节点开始,朝着叶子节点(词法符号)进行解析的过程。
ANTLR 根据 assign 规则生成的的方法大致实现如下:
1 | // assign : ID '=' expr ';' ; |
assign() 方法主要验证词汇符号是否存在,以及是否满足语法规定的顺序。调用 match() 方法则对应语法分析树的叶子节点。通过stat()、assign() 和 expr() 的调用描述出的调用路线图可以很好地映射到语法分析树的节点上。
在 ANTLR 中,assign 语法规则对应的语法分析树,可以映射成如下类型:
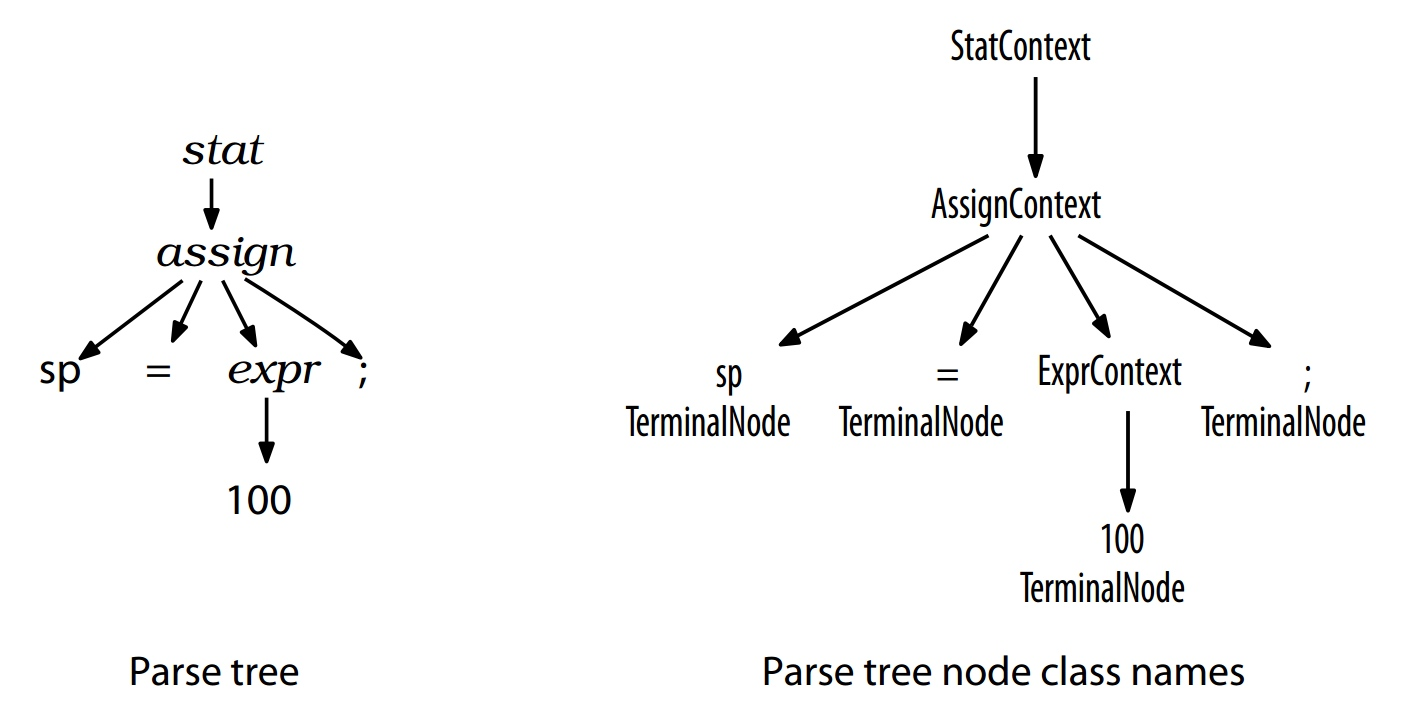
左图中 stat、assign、expr 代表的是规则节点(RuleNode),对应 ANTLR 语法定义中的规则名称,sp、100 对应的是终端节点(TerminalNode),即词法符号。
我们可以手动编写出访问语法分析树的代码,来访问 Context 和 TerminalNode 中存储的信息,从而实现结果计算、数据结构更新、打印输出等功能。但实际上,ANTLR 已经自动生成了语法分析树的遍历器,可以直接供我们使用。
接下来 我们就来了解下 ANTLR 提供的两种遍历树的机制。
1、Listener 监听器
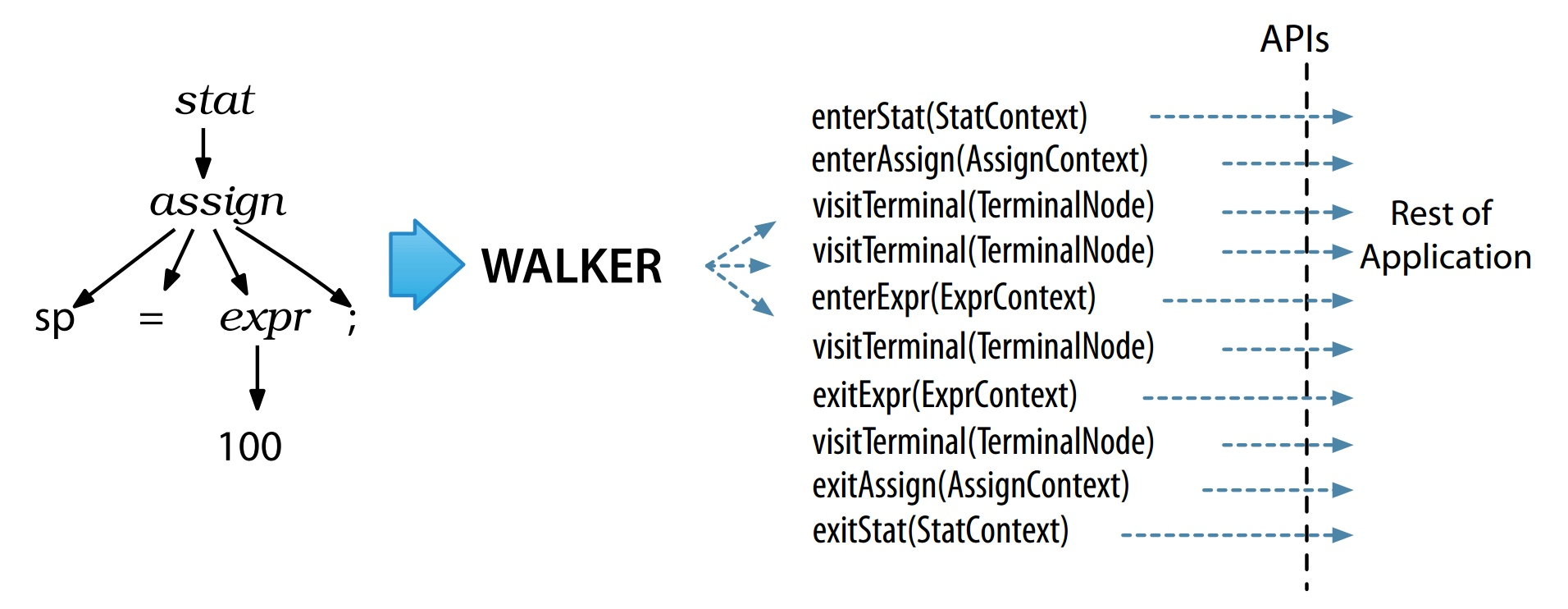
ANTLR 默认会生成语法分析树监听器,内置的 ParseTreeWalker 类会进行深度优先遍历(如下图所示),遍历树的不同节点时,会触发不同的事件,语法分析树监听器会对不同的事件作出相应的处理。
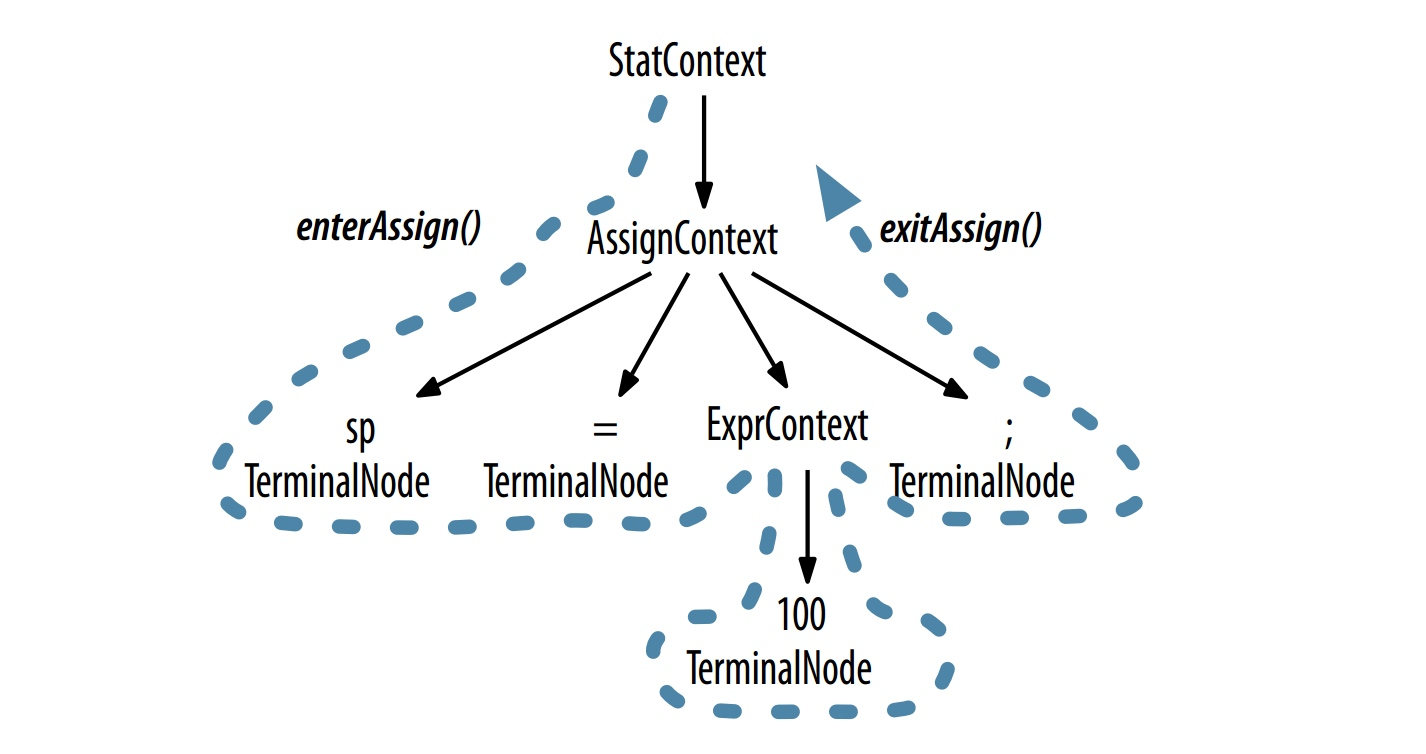
ANTLR 默认为每个语法文件生成了一个 ParseTreeListener 的子类,语法中的每条规则都有对应的 enter 和 exit 方法,用户可以自行实现 ParseTreeListener 接口,来实现自己的业务逻辑。
ParseTreeWalker 类对 ParseTreeListener 接口完整的调用流程如下图:
2、visitor 访问器
用户希望控制遍历语法分析树的过程,想要显示地访问子节点,那么可以使用语法分析树访问器。
通常,visitor 访问器对树的遍历过程如下:
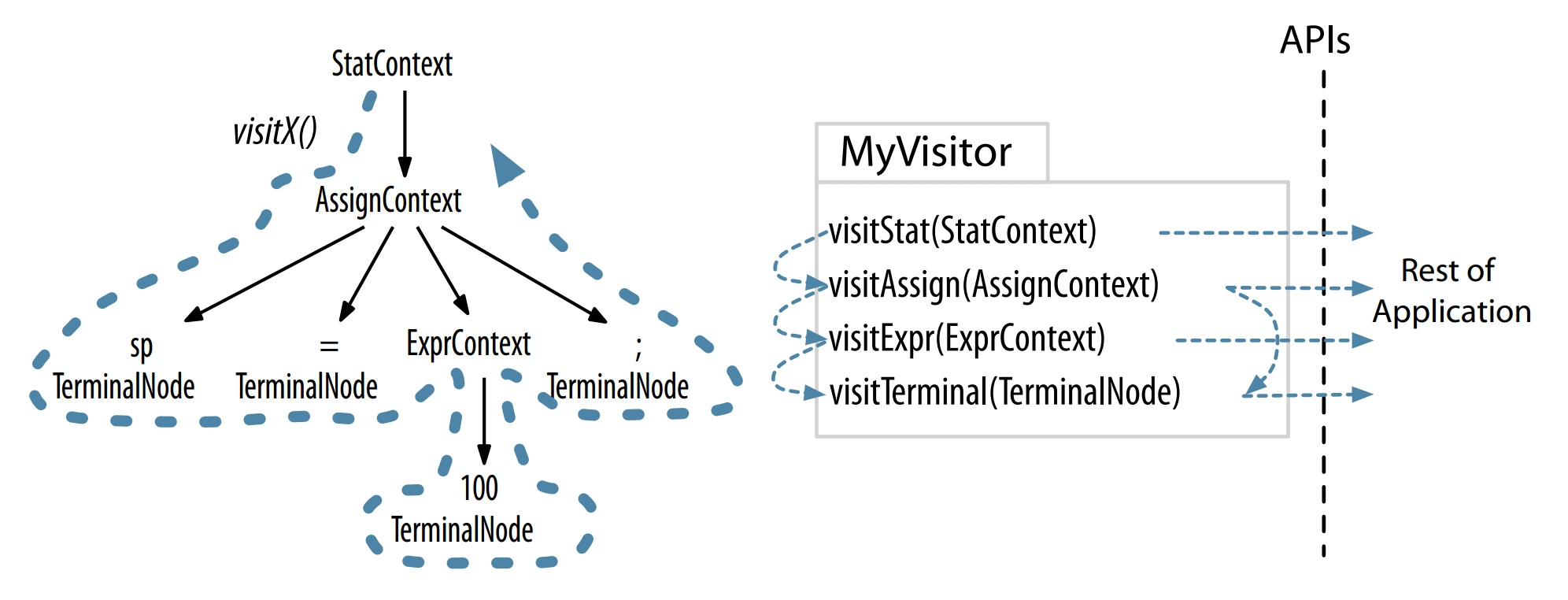
ANTLR 默认会提供访问器接口及一个默认实现类,用户只需要实现自己感兴趣的方法即可。
5. 最后
这篇文章,我们写了一个 HelloWorld 带大家入门 ANTLR ,下一篇,我们重点分析 shardingsphere parser 如何编写 ANTLR 语法描述文件以及重写 visitor 访问器。