1. 增量同步流程
整体数据同步整体方案见下图,数据同步基于 binlog ,独立的中间服务做同步,对业务代码无侵入。
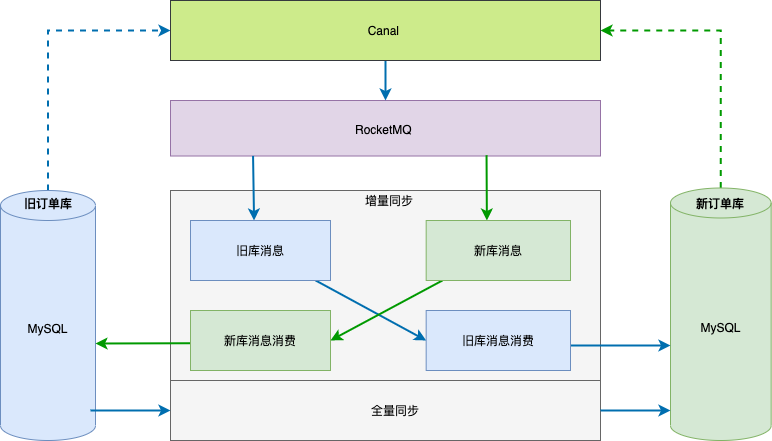
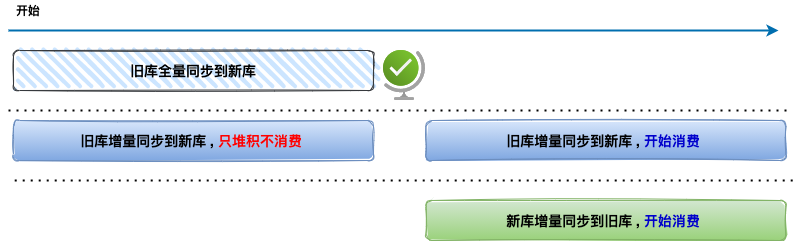
当历史全量数据同步完成后,然后开启消费 RocketMQ 消息进行增量数据同步(提高全量同步效率减少积压也是关键的一环),这样来保证迁移数据过程中的数据一致。
2. Canal监听旧订单库
Canal 使用 zookeeper 高可用配置 ,配置 canal.properties :
1 | #集群模式 zk地址 |
Canal 使用的模式是 RocketMQ ,我们定义了两个 instance 列表 old-order、new-order ,它们分别代表了「监听旧订单库」、「监听新订单库四个分片」。
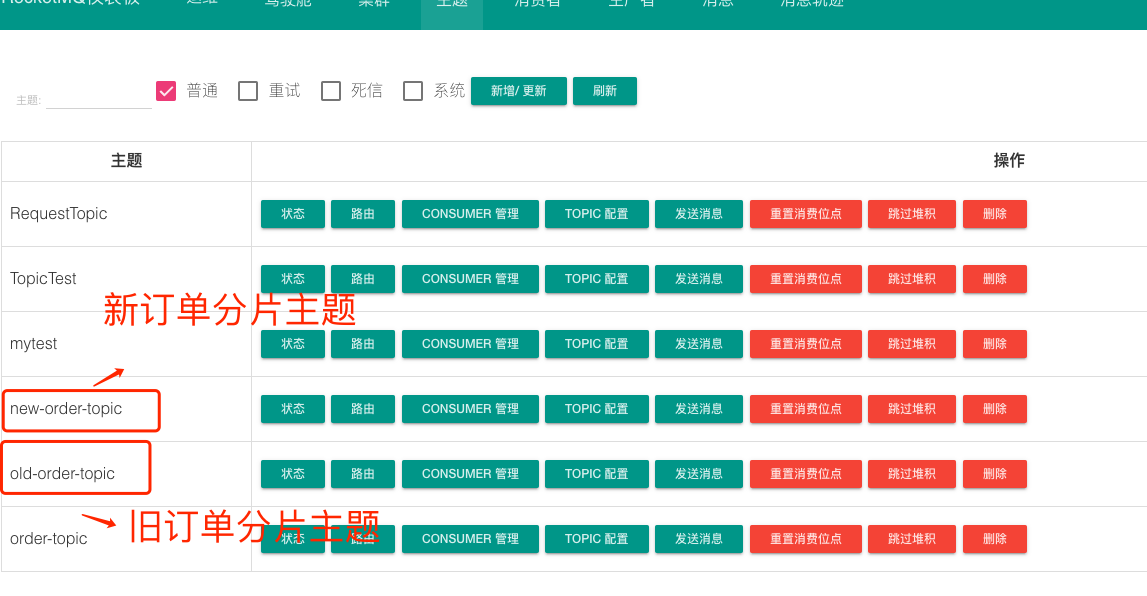
同时通过 RocketMQ DashBoard 创建两个主题:
1 | # 按需修改成自己的数据库信息 |
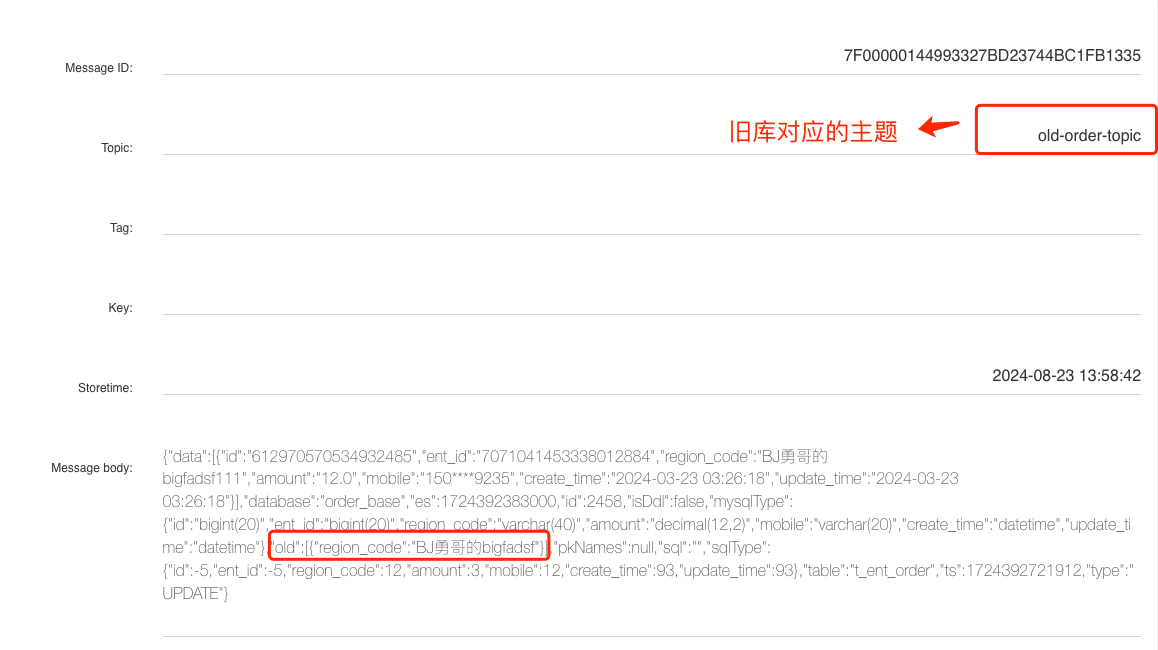
修改一条订单表 t_ent_order 的记录,查看 RocketMQ 控制台即可查询到 Binlog 消息:
3. Canal监听4个新订单分片
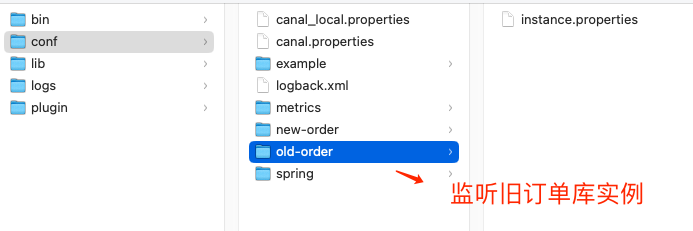
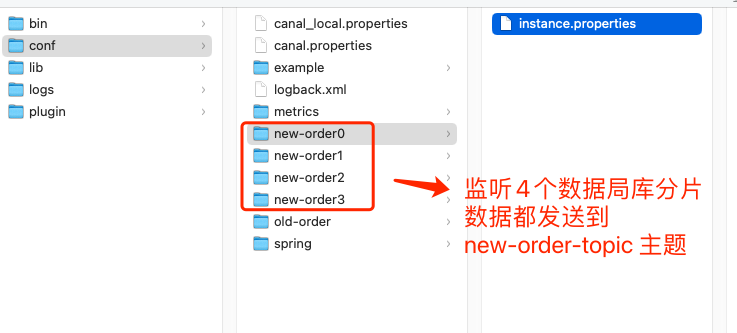
我们在 Canal 的安装目录 Conf 目录下创建四个目录:
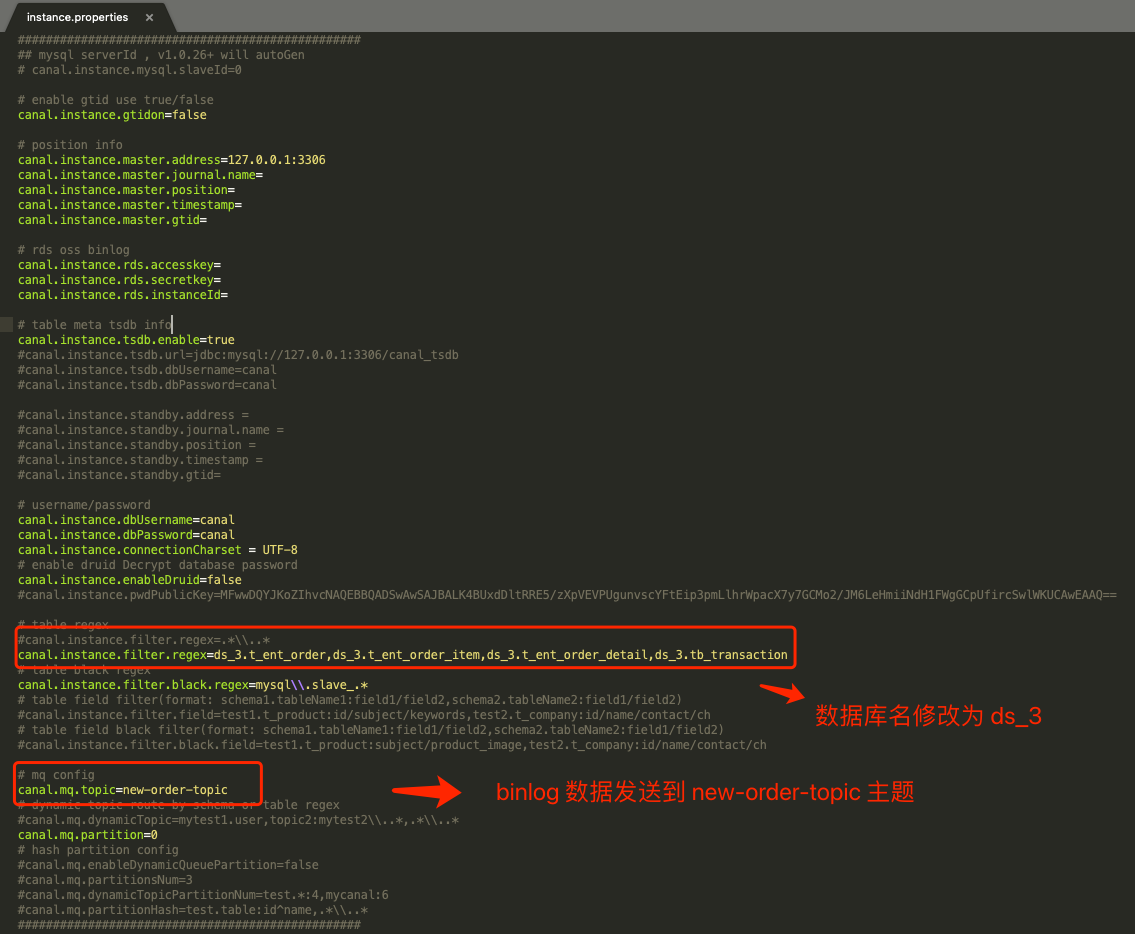
接下来,我们同样修改新订单分片 ds_3 订单表的一条记录,从 RocketMQ 控制台即可查询出该条 Binlog 消息:

4. 双向同步架构&代码解析
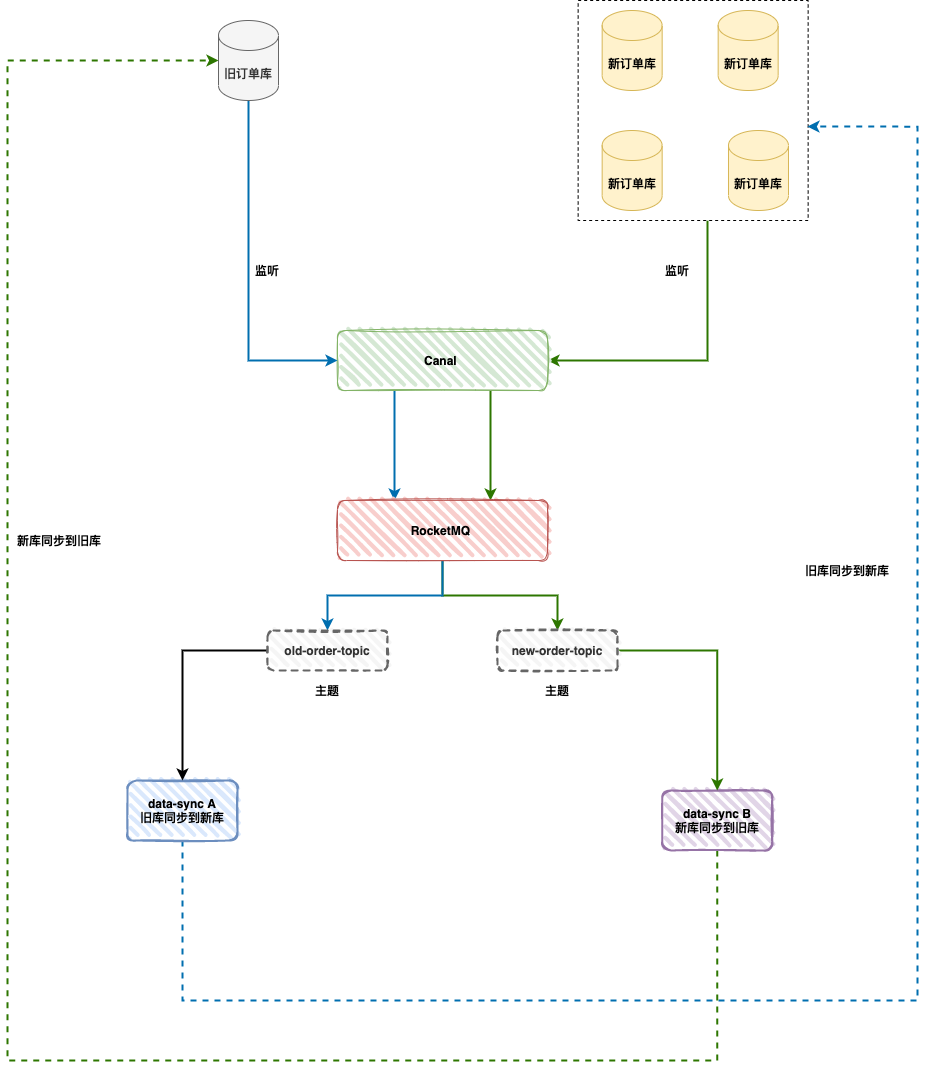
接下来,我们来看如何设计同步服务 B 「新库同步到旧库」:
1、配置文件

- 目标数据库信息( JDBC URL、用户名、密码)
- 同步哪些表(过滤作用)
- 监听 RocketMQ 主题 、RocketMQ 名字服务
2、启动消费者监听器
- 我们启动了一个 RocketMQ 消费者 DefaultLitePullConsumer ,它是一个拉取模式的消费者,可以指定每次最大拉取数量。
- 为了便于灵活控制消费进度,我们采用手工提交消费偏移量的方式。
- 定义了一个单独的执行线程用于处理消息。
3、消费流程
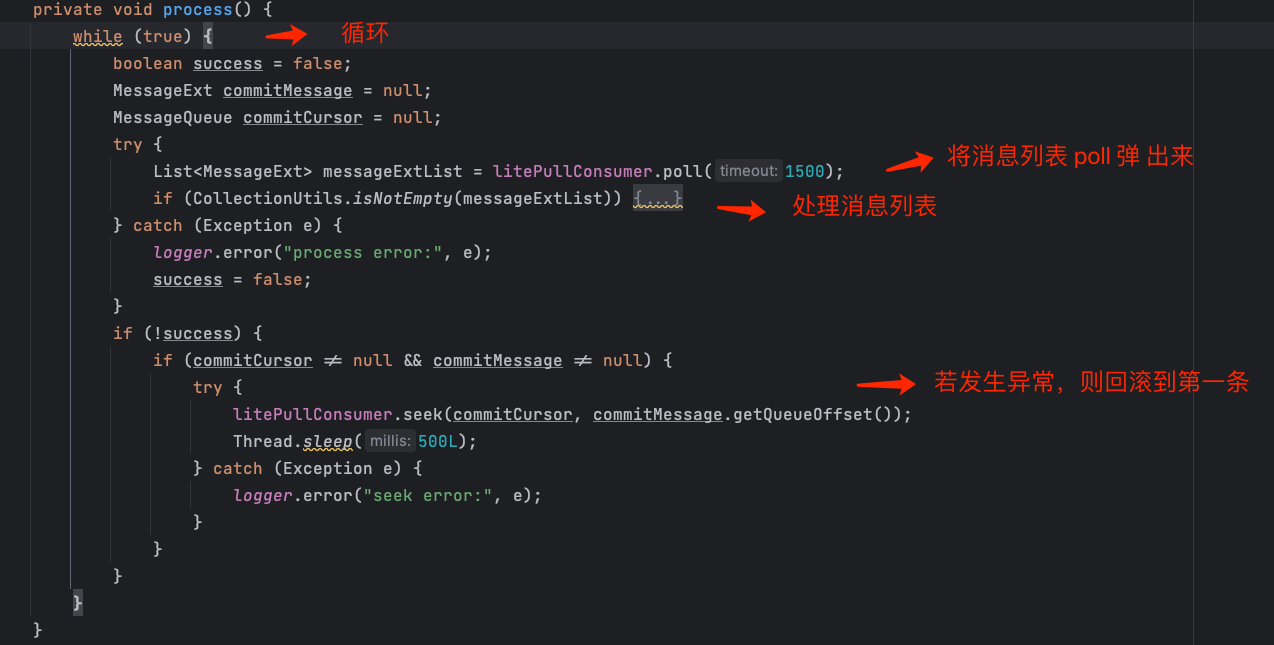
- 开启单线程循环;
- 调用 DefaultLitePullConsumer 对象的 poll 方法 ,将消息列表弹出来 ;
- 处理消息列表。
4、处理消息列表
首先将消息做过滤,按照表名做一个分组,过滤掉染色消息。
染色消息是为了解决消息无限循环问题,业务写一条数据到旧实例的一张表,于是产生了一条 binlog;data-sync 中间件接到 binlog 后,将该记录写入到新实例,于是在新实例也产生了一条 binlog;此时 data-sync 中间件又接到了该 binlog…… 不断循环,消息越来越多,数据顺序也被打乱。
怎么解决该问题呢?
我们采用数据染色方案,只要能够标识写入到数据库中的数据是 data-sync 中间件写入而非业务写入,当下次接收到该 binlog 数据的时候就不需要进行再次消息流转。
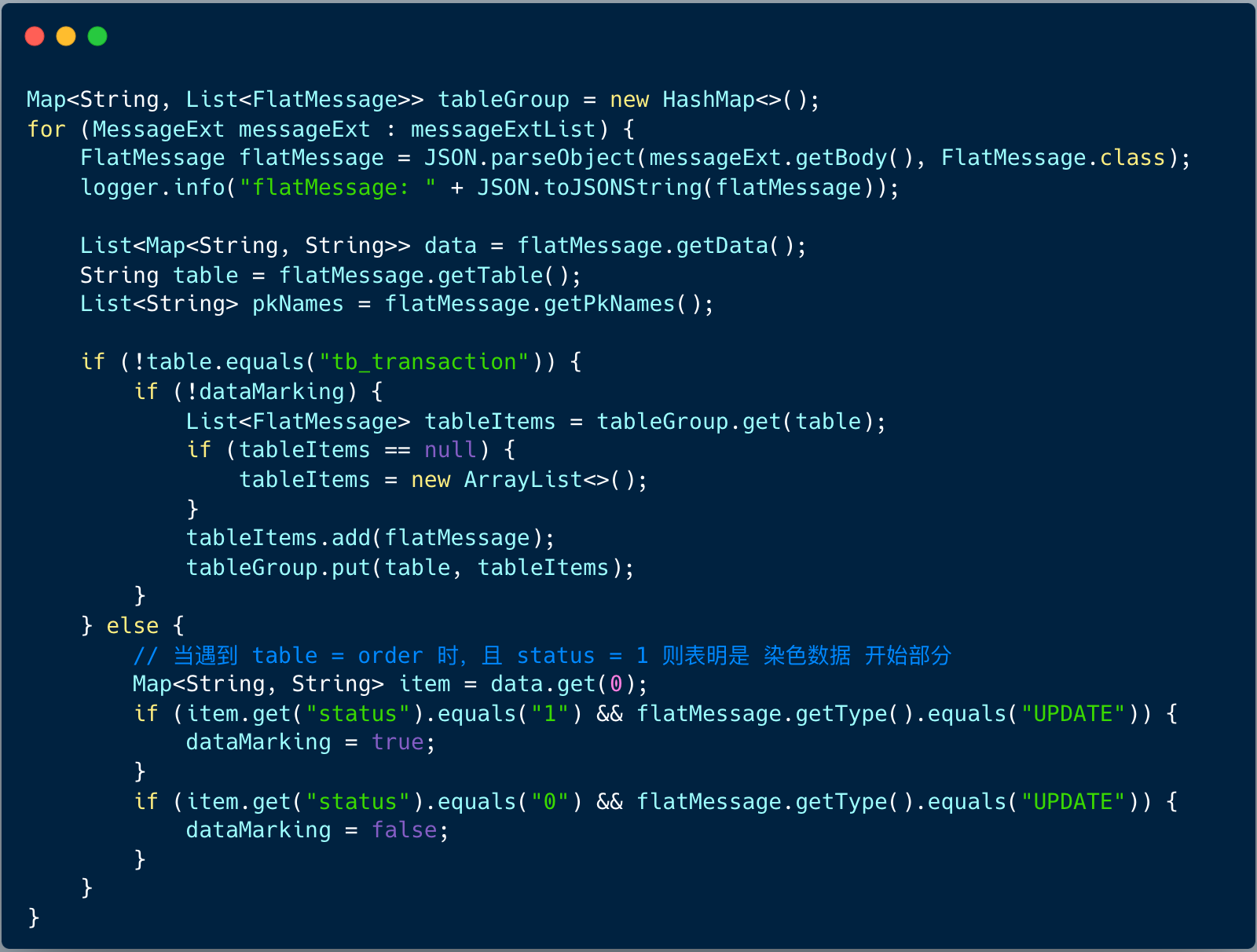
当消费过滤之后,就可以对这些真正需要对这些分组消息进行同步操作了。
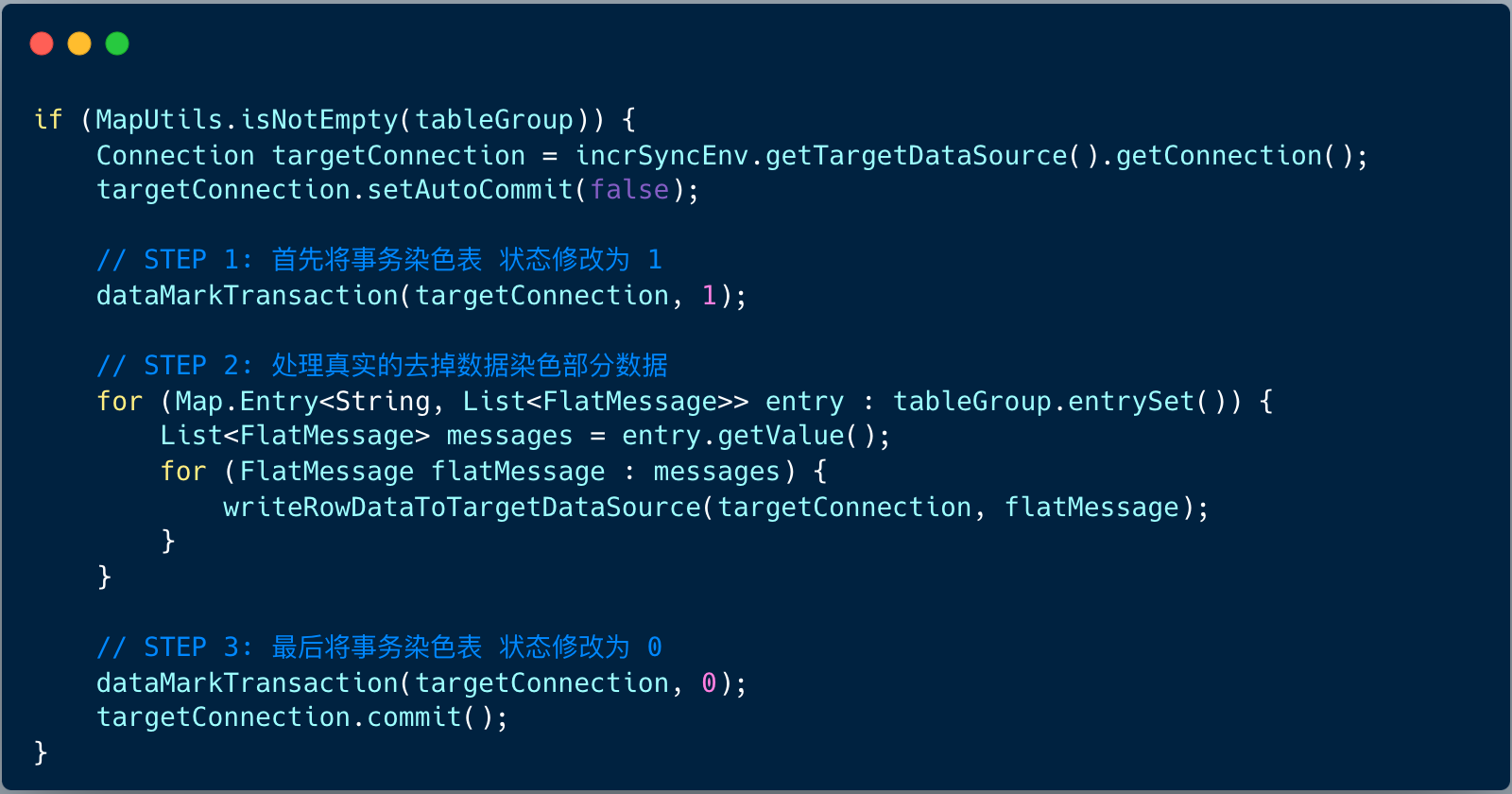
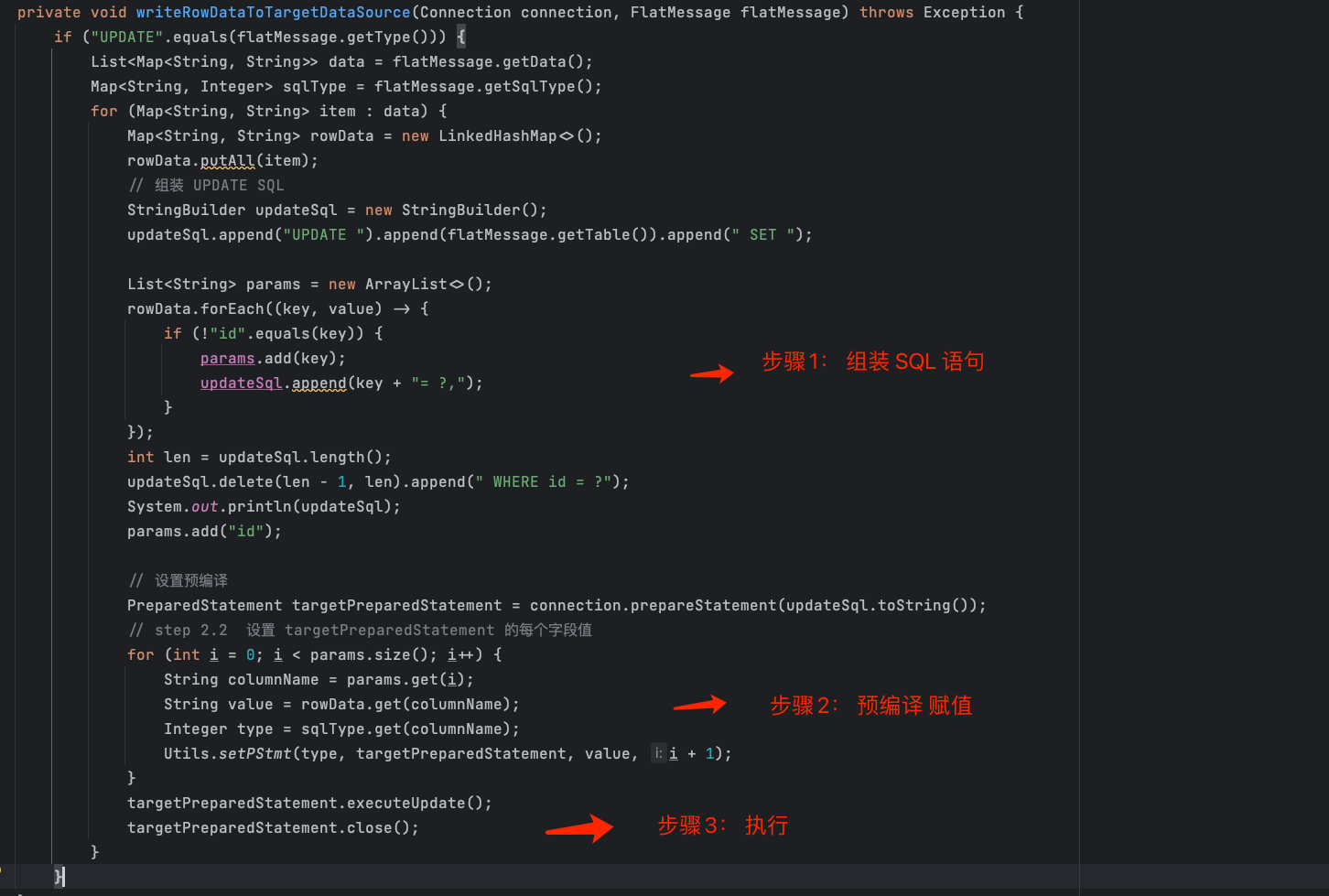
对每条消息的处理流程分为三个步骤 :
- 步骤 1 :组装 SQL 语句 ;
- 步骤 2 :预编译赋值;
- 步骤 3 :执行 SQL 语句 。
5. 效果演示
首先在订单分片 ds3 执行如下 SQL 。
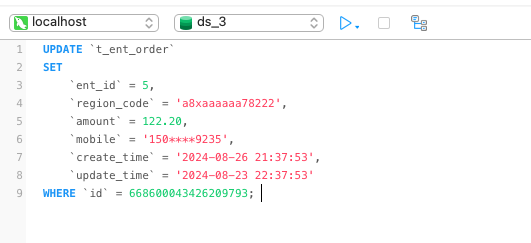

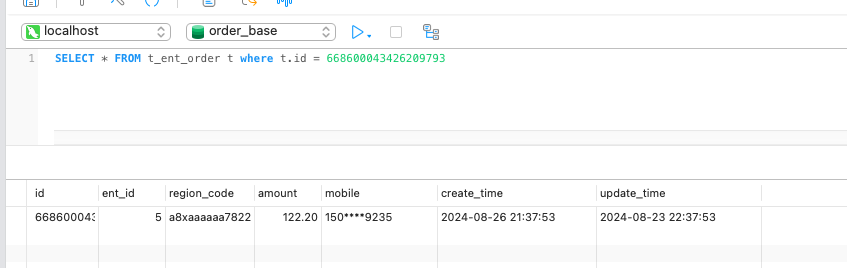
设想一种场景,业务系统向旧实例中的一张表写入一条数据,从而产生了一条 binlog。data-sync 中间件接收到该 binlog 后,将这条记录写入新实例,这样新实例也产生了一条 binlog。此时 data-sync 中间件又接收到该 binlog …… 如此循环往复,消息数量不断增加,数据的顺序也逐渐被打乱。
解决方案是: 数据染色,所谓数据染色,即:标识写入到数据库中的数据是 data-sync 中间件写入的而不是业务写入,当下次接收到该 binlog 数据的时候就不需要进行再次消息流转。
数据同步有两种方案:染色事务表和业务数据染色。接下来,我们重点剖析这两种实现方式以及优缺点 。
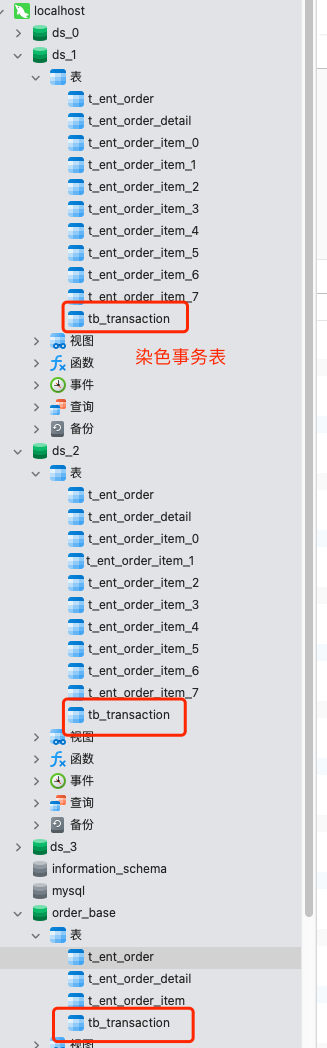
6. 染色事务表
每个数据库实例中创建一个事务表,该事务表 tb_transaction 只有 id、tablename、status、create_time、update_time 几个字段,其中 status 默认为 0。
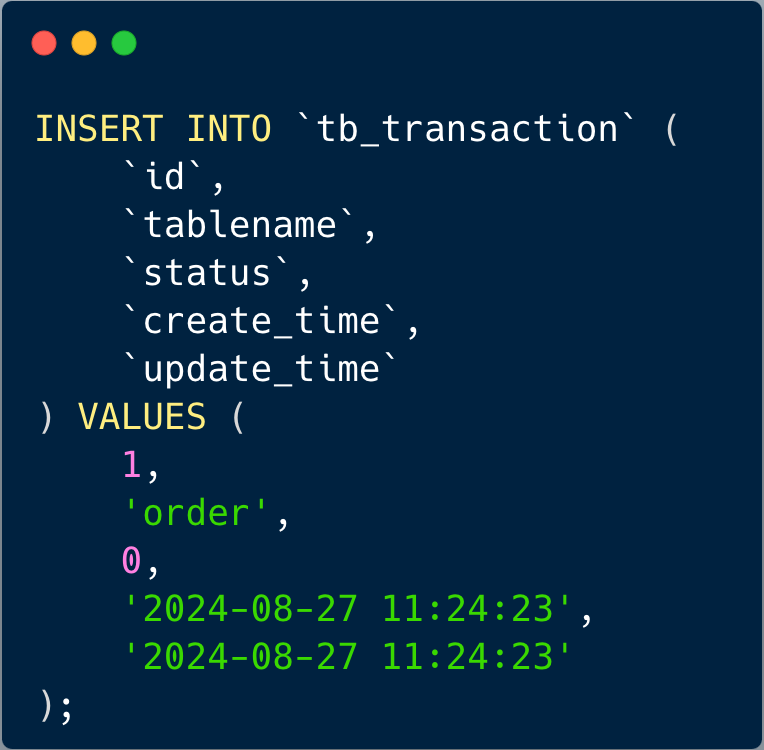
执行完成后,旧订单库实例新增了染色事务表。
业务写一条数据到旧实例的一张表,于是产生了一条 binlog,data-sync 中间件接到 binlog 后,如下操作:

此时,data-sync 中间件会将上述所有语句打包后提交到新实例,新实例在更新数据后,也会生成对应的 binlog。
当 data-sync 中间件再次接收到这些 binlog 时,只需判断是否遇到 tb_transaction 表中 status = 1 的数据标记为起始点,此后所有数据将被直接丢弃,直到遇到 status = 0 的数据标记为止,才继续接收数据。通过这种方式,就可以确保 data-sync 中间件只会处理由业务系统产生的消息。
接下来,我们讲解下工程实现 :
1、data-sync 作为 MQ 消费者启动之后,首先从中心存储中查询当前任务是否处于染色中。

之所以我们会将任务是否染色状态,因为每次获取的消息列表可能存在类似于 TCP 数据包里的粘包和拆包问题。
- 场景1 :染色数据包完整

- 场景2 :染色数据包不完整,有截断

2、假如当前任务是染色状态,则过滤掉接下来的数据包,直到遇到 status = 0的消息包
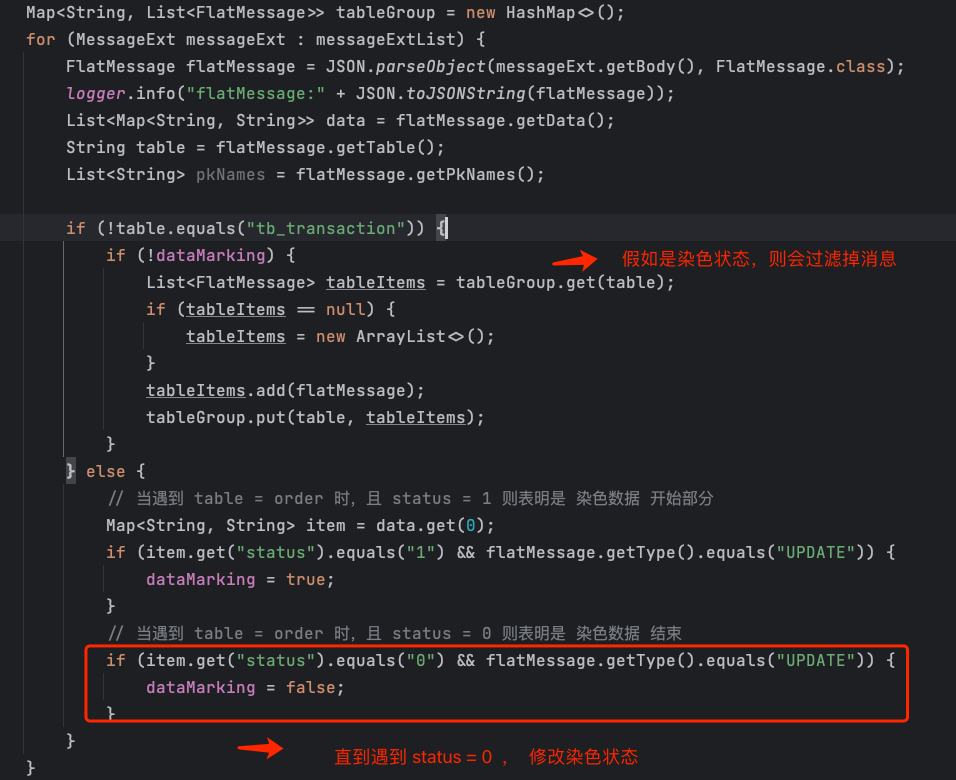
3、处理业务消息,转换成 SQL语句,并执行
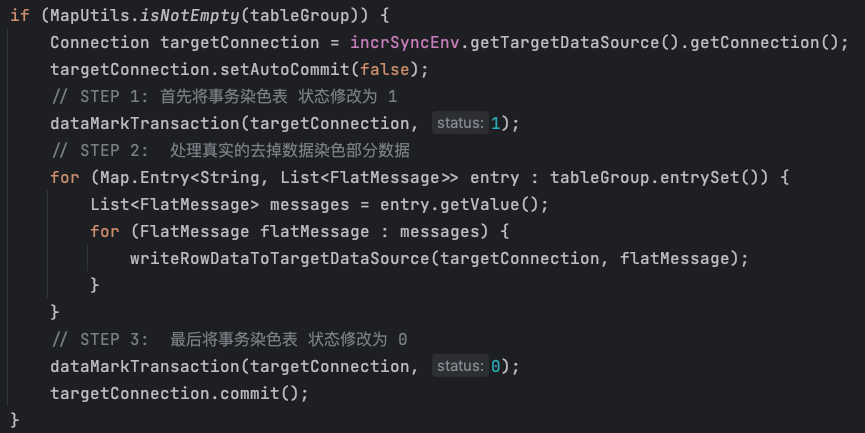
4、将染色数据保存到数据库,并手工提交消费者 offset
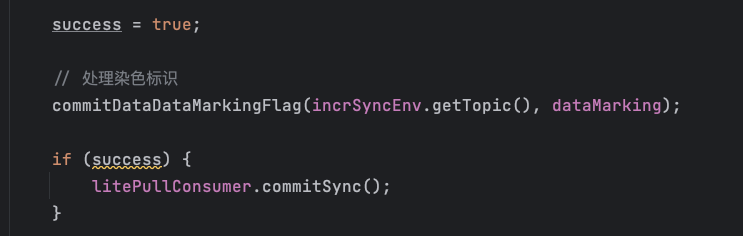
这个例子里使用的是 DefaultLitePullConsumer , 当出现异常时,我们会重置消费位点到当前批次的第一条消息,重新开始消费。
假如我们使用 DefaultMQPushConsumer ,默认情况下,会自动重试,就算业务数据处理了一次,也会达到最终一致性。
7. 业务数据染色
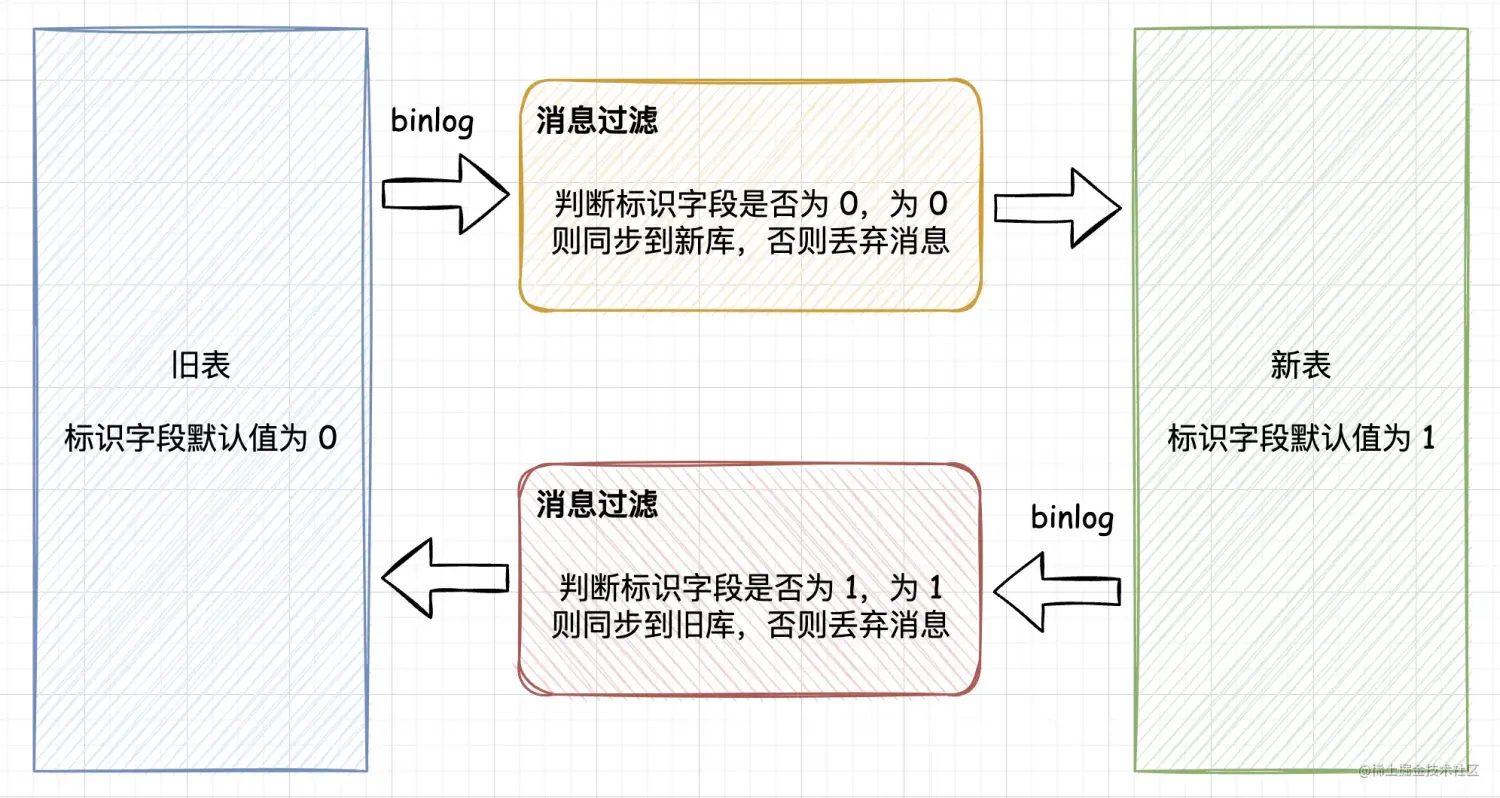
业务数据染色是指:在业务表中,添加一个标识字段说明数据来源,比如订单表 t_ent_order 添加一个来源字段 source ,旧订单库该字段默认值是 0 。
而新订单库订单表 t_ent_order 也会新增同样的来源字段 source,该字段默认值为 1 。标识字段一定要指定默认值,这样业务代码就不需要改动了。
如下图,当旧库向新库同步时,消息过滤组件会判断标识字段是否为 0,如果为 0 则说明是旧库产生的数据,就同步到新库,否则就会丢弃消息。
新库向旧库同步也是如此,只不过新库的标识字段为 1。这样就解决了数据双向同步产生的消息循环问题了。
我们使用顺序消费模拟业务数据染色数据处理流程:
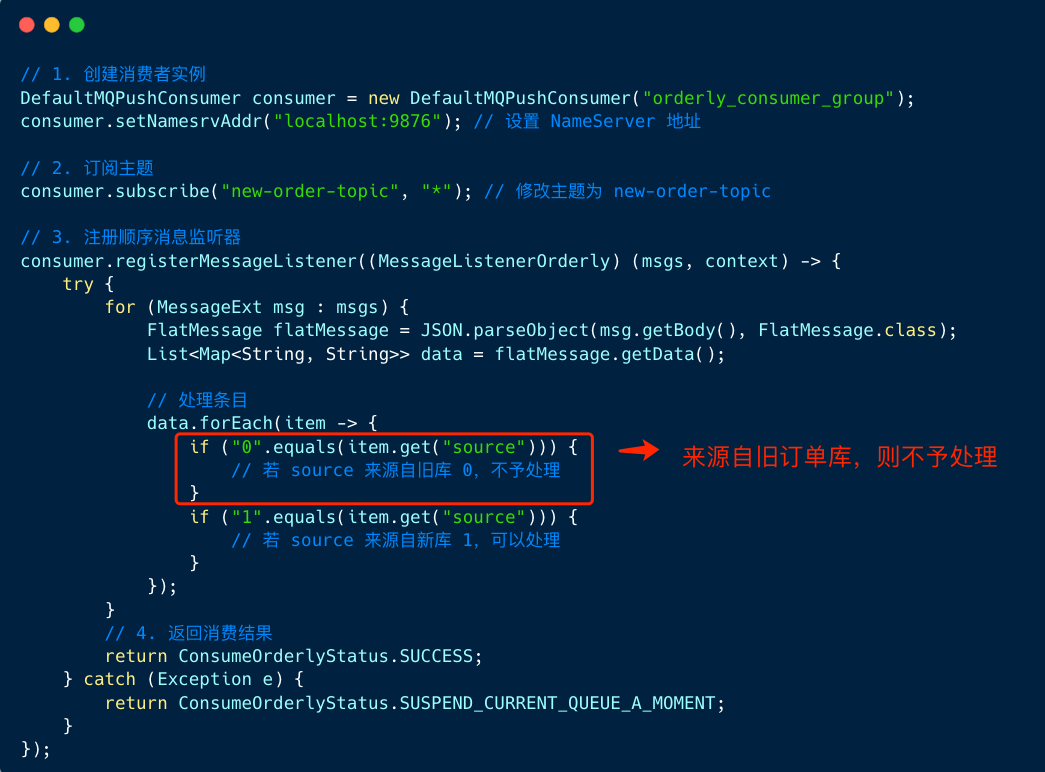
图中,我们定义了顺序消费者,遍历消息列表,先将消息解析成 FlatMessage ,处理 FlatMessage 的 data 对象, 遍历 data 对象的条目,解析 source 字段,若 source 和当前库一致(都为 0 ),则不予处理。
8. 染色事务表VS业务数据染色
染色事务表要点如下:
1、需要在每个业务库中添加一个染色事务表 tb_transaction ,该事务表 tb_transaction 只有 id、tablename、status、create_time、update_time 几个字段,其中 status 默认为 0。
2、data-sync 中间件接到 binlog 后,遇到 「status =1」 直到 「status =0」之间的染色数据则不予处理,同时将正常业务数据包按照如下的 SQL 执行:
3、类似 TCP 的粘包和拆包问题,我们也会遇到「染色数据包不完整,有截断 」的问题,因此我们需要在消费逻辑内部的最后添加保存是否当前任务是否染色中的状态。
业务数据染色要点如下:
1、不管旧库、新库每张业务表中添加来源字段,旧库默认值为 0 ,新库默认值为 1 。
2、顺序消费时,只需要判断 source 字段是否和当前操作库一致,若一致,则不予处理,过滤掉。
3、不需要保存当前任务是否数据染色中,实现容易。
写到这里,我们发现业务数据染色的实现相比染色事务表实现起来更加容易,但同时业务数据染色这种模式对于业务的侵入性非常强。
有什么方式可以减少这种侵入性吗 ? 我们可以使用类似基因法的模式,比如 主键 ID 内置数据库来源信息,也就是基因法。

如图,可以将序号从12位调整为10位,另外 2 位用于设置数据来源,我们只需要从订单系列表的主键解析出数据来源即可判断当前数据是否来自本身。