1. 原理
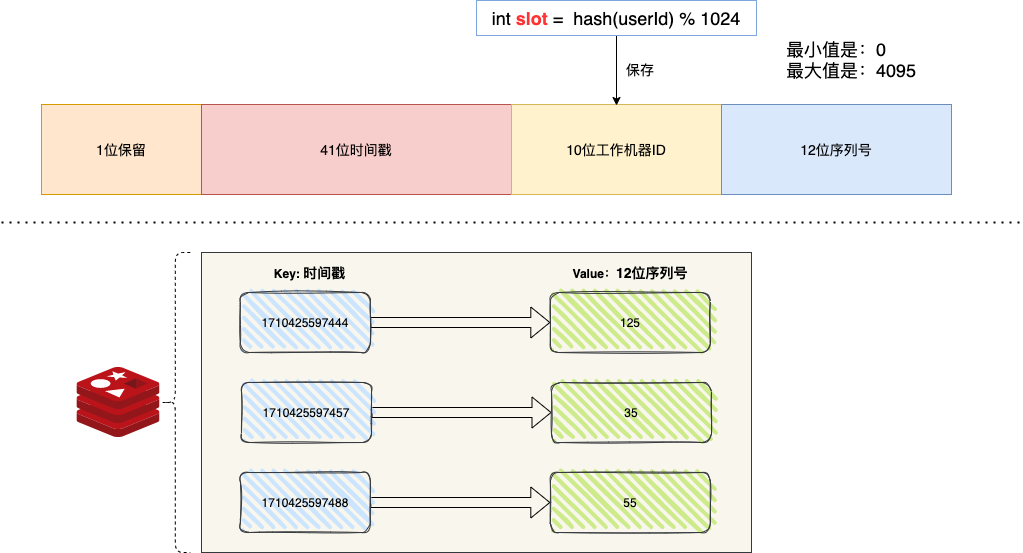
分布式场景里,为了保证主键的唯一性,我们可以将 key 设置为时间戳,value 为 12 位序列号,应用调用 Redis String 类型的 incr 自增命令 ,自增命令是原子操作,因为 41 位时间戳 + 12位序列号的组合不可能重复,所以理论来讲,Redis + 雪花算法生成分布式 ID不会重复。
2. 流程
下图展示了订单 ID 使用雪花算法的生成过程,生成的编号会携带企业用户 ID 信息。

1、查看并发队列是否有可用的序列号
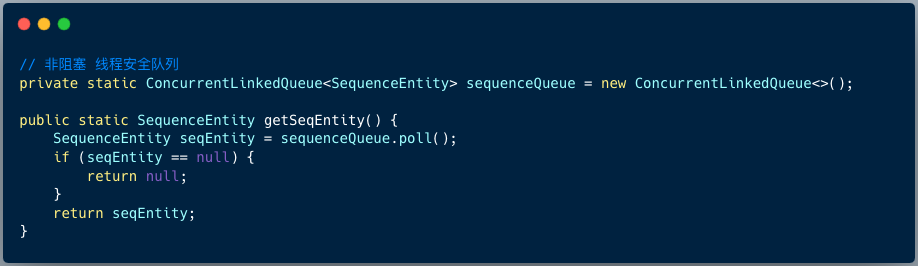
使用并发队列 ConcurrentLinkedQueue ,是为了减少对 Redis 的网络 IO ,同时加一层缓冲,相对提升系统的可用性。
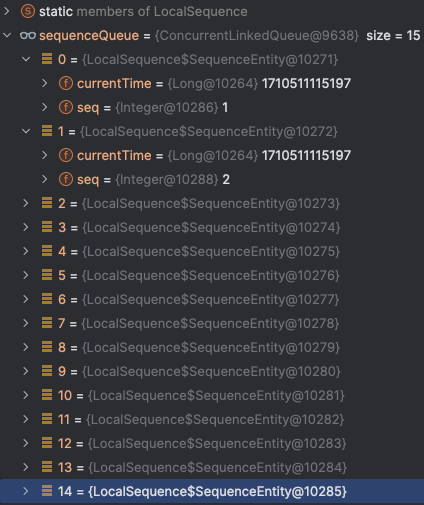
2、调用 redis incr 自增命令,每次自增一个步长,默认是15

Redis ID 生成器第一次执行后, 当前时间戳对应的序列号如下图:

3、将每一个步长的序号加入到并发队列

4、使用雪花算法组装编号

3. 时钟回拨
雪花算法对时间非常敏感,当发生时间回拨时,有一定几率生成重复的 ID。
时钟回拨是指:时间被调整回到了之前的时间,由于雪花算法重度依赖机器的当前时间,所以一旦发生时间回拨,将有可能导致生成的 ID 可能与此前已经生成的某个 ID 重复。
引起时钟回拨一般有三个原因:
3.1 网络时间自动校准
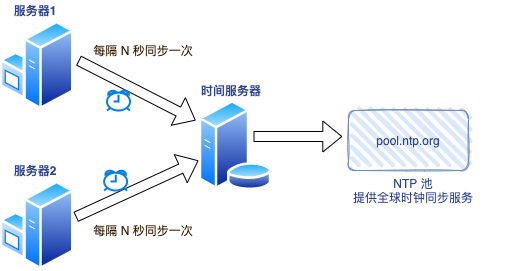
导致时钟回拨是机器本地时钟因为各种原因发生不准导致,其实网络中有NTP(NTP为Network Time Protocol的缩写,即网络时间协议)服务来提供时间校准。
通过时间校准让客户端和服务器之间进行时钟同步,提供高精准度的时间校正,NTP服务器从权威时钟源(例如原子钟、GPS)接收精确的协调世界时UTC,因为NTP Pool是绝大多数主流 Linux 发行版和许多网络设备的默认“时间服务器”。
3.2 人工设置时间
假如服务器的时间不相同,运维人员或者开发者直接修改服务器的时间。
3.3 闰秒
闰秒,是指为保持协调世界时接近于世界时时刻,由国际计量局统一规定在年底或年中(也可能在季末)对协调世界时增加或减少1秒的调整。
由于地球自转的不均匀性和长期变慢性(主要由潮汐摩擦引起的),会使世界时(民用时)和原子时之间相差超过到±0.9秒时,就把协调世界时向前拨1秒(负闰秒,最后一分钟为59秒)或向后拨1秒(正闰秒,最后一分钟为61秒);
当遇到时钟回拨的问题,RedisIdGeneratorService 能否避免这个问题呢 ?我们来模拟一下。
1、时间戳对应的 Redis ID key 存在
假设时钟回拨到时间戳 1710593308053 ,该时间戳对应的 Redis ID key 没有过期。

图中,通过 Redis 的 incr 命令自增了两个步长,此时依然有非常多的序列号可供使用,理论来讲,时钟回拨并不会有太多影响。
但假如应用过多,同一时间戳 incr 命令自增步长次数过多,导致没有可用的序列号了,此时生成 ID 会报异常,当然同一时间戳触发这种场景的概率相对较低。
2、时间戳对应的 Redis ID key 不存在
时钟回拨到时间戳 1710593308053 ,该时间戳对应的 Redis ID key 并不存在(可能是因为过期了),那么可使用的序列号从 1 开始了,可能[1710593308053,1] 这个组合已经被使用过了,那么有大的概率会生成一个重复的 ID 。
综上,我们可以尽量延迟时间戳对应的 Redis ID key 的过期时间尽量规避时钟回拨带来的风险。
4. 思维升级
写到了这里,我们思考下 RedisIdGeneratorService 还有哪些优化的空间 , 笔者想到了两点:
1、细粒度的分层 Redis ID Key
我们可以将每张表映射一个 Redis ID Key ,拼接格式如下图:

2、参考美团Leaf 自研一个服务端的 ID 生成器
我们在时钟回拨这一节提到:
假如应用过多,同一时间戳 incr 命令自增步长次数过多,导致没有可用的序列号了,此时生成 ID 会报异常,当然同一时间戳触发这种场景的概率相对较低。
同时,RedisIdGeneratorService 是客户端的模式,假如多团队需要接入,随着接入应用的增加,那么同一时间戳触发这种场景的概率就会越来越高。
因此,我们可以参考美团Leaf 自研一个服务端的 ID 生成器,就能够规避上面的风险,同时对接大规模的应用。