1. 基本原理
解析过程分为词法解析和语法解析。
- 词法解析器用于将 SQL 拆解为不可再分的原子符号,称为 Token,并根据不同数据库方言所提供的字典,将其归类为关键字,表达式,字面量和操作符。
- 使用语法解析器将词法解析器的输出转换为抽象语法树。
例如,以下 SQL:
1 | SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18 |
解析之后的为抽象语法树见下图:
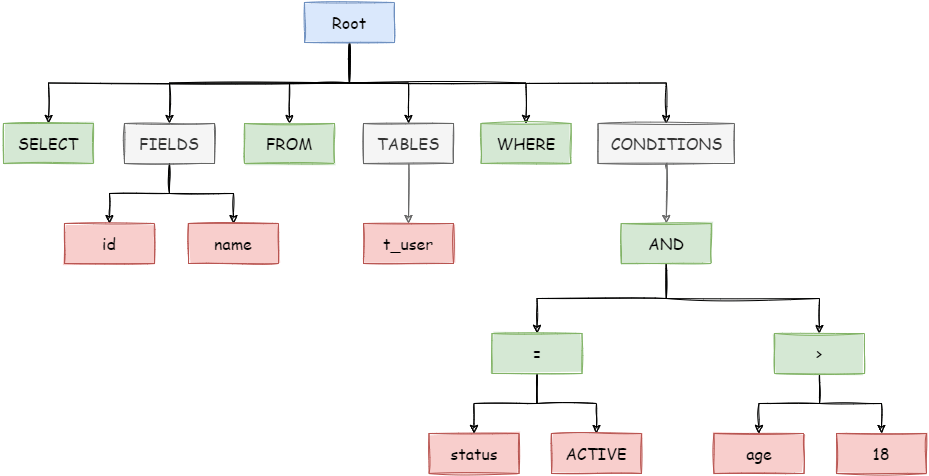
为了便于理解,抽象语法树中的关键字的 Token 用绿色表示,变量的 Token 用红色表示,灰色表示需要进一步拆分。
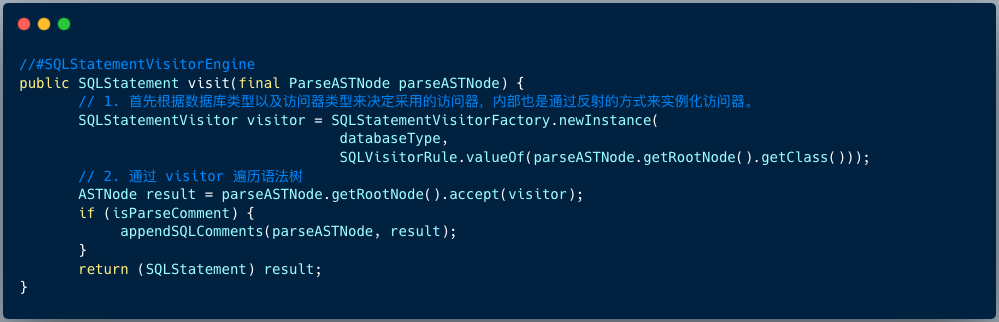
最后,通过 visitor 对抽象语法树遍历构造域模型,通过域模型(SQLStatement)去提炼分片所需的上下文,并标记有可能需要改写的位置。
供分片使用的解析上下文包含查询选择项(Select Items)、表信息(Table)、分片条件(Sharding Condition)、自增主键信息(Auto increment Primary Key)、排序信息(Order By)、分组信息(Group By)以及分页信息(Limit、Rownum、Top)。
SQL 的一次解析过程是不可逆的,一个个 Token 按 SQL 原本的顺序依次进行解析,性能很高。
ShardingSphere 使用 ANTLR 作为 SQL 解析引擎的生成器,并采用 Visit 的方式从 AST 中获取域模型 SQLStatement。
从 5.0.x 版本开始,解析引擎的架构已完成重构调整, 同时通过将第一次解析得到的 AST 放入缓存,方便下次直接获取相同 SQL 的解析结果,来提高解析效率。因此建议用户采用 PreparedStatement 这种 SQL 预编译的方式来提升性能。
shardingsphere 提供独立的 SQL 解析功能、可以非常方便的对语法规则进行扩充和修改(使用了 ANTLR),同时支持多种方言的 SQL 解析。
既然 SQL 解析最终的产物是:域模型 SQLStatement , 我们来看下 shardingsphere 有哪些 SQLStatement ?
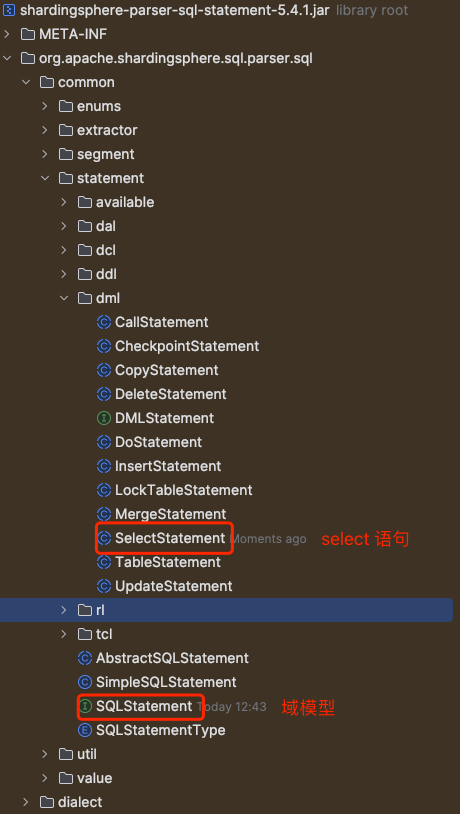
当我们有不同的 SQL 语句,根据类型不同,解析成如图 dml 包下不同的域模型 SQLStatement 。
2. 解析流程
我们从 shardingsphere jdbc 的例子入手 , 来串联解析流程。
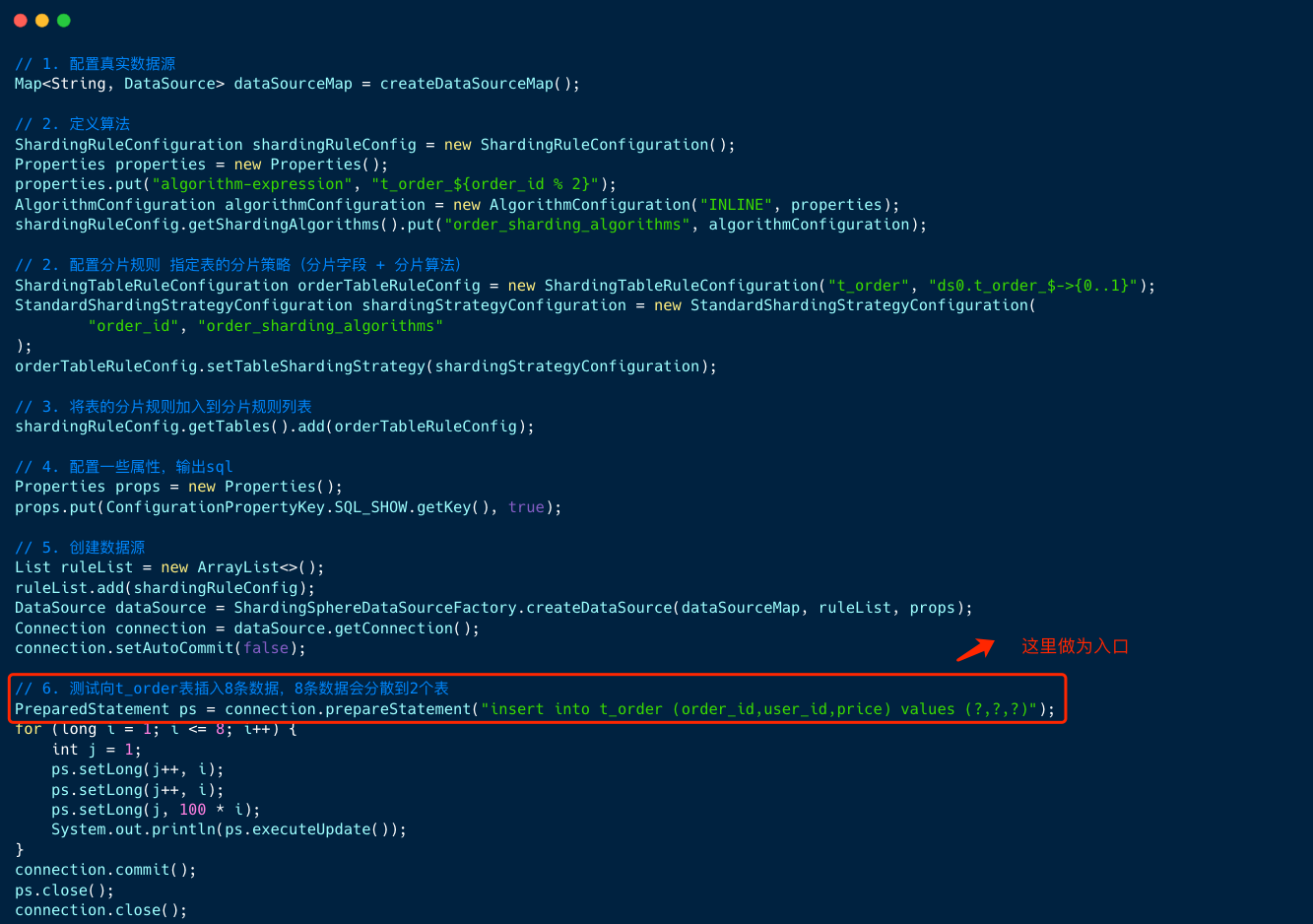
1、当创建数据源 DataSource 之后,调用 getConnection 方法获取连接 , 然后通过连接创建 SQL 预编译。

2、ShardingSpherePreparedStatement 构造函数
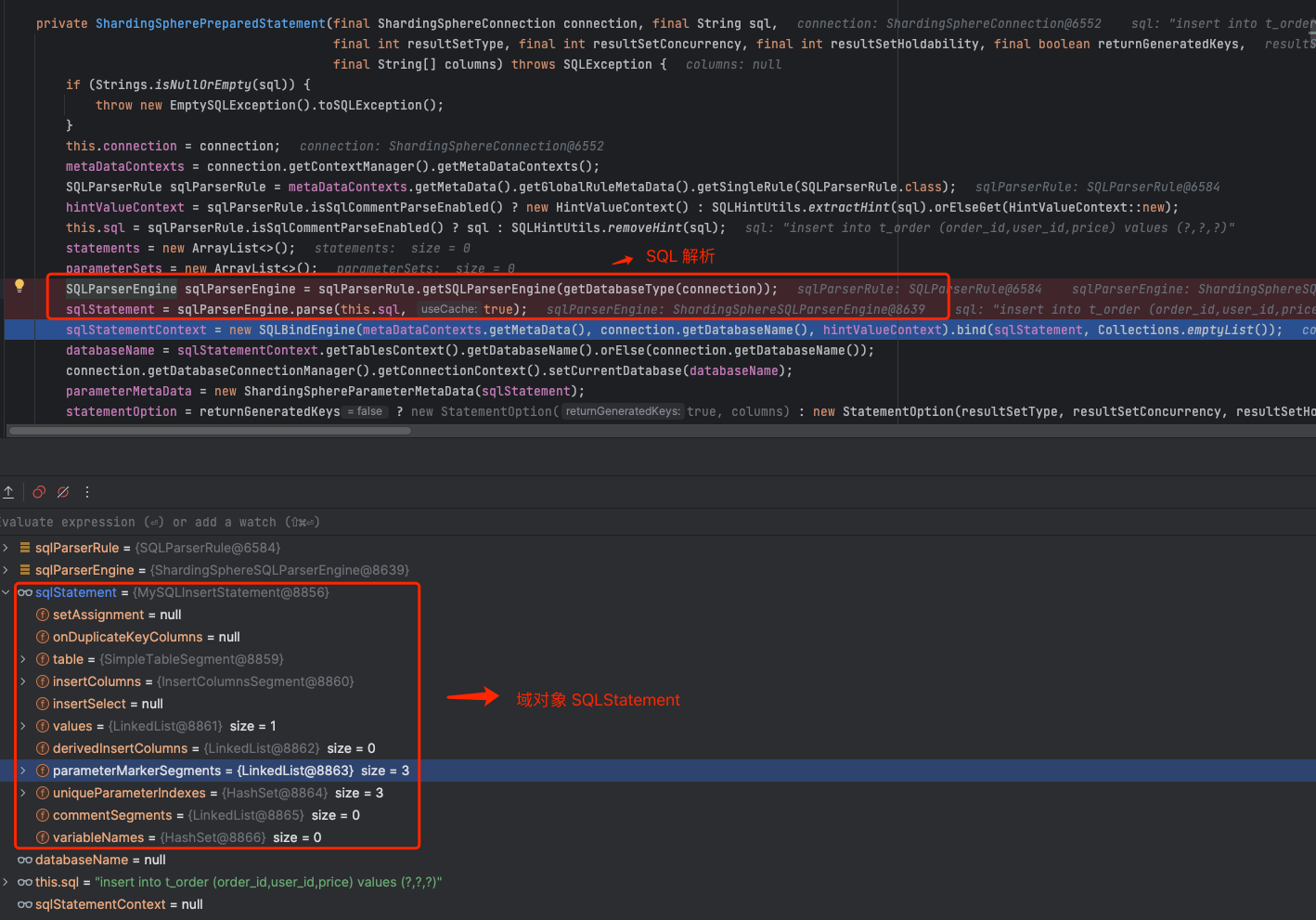
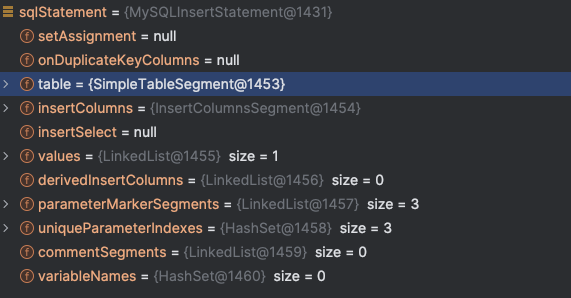
图中,ShardingSpherePreparedStatement 的构造函数内部完成了 SQL 解析 , 域对象是 MySQLInsertStatement 。
跟踪代码,发现解析引擎真正解析的类是 SQLStatementParserExecutor 。
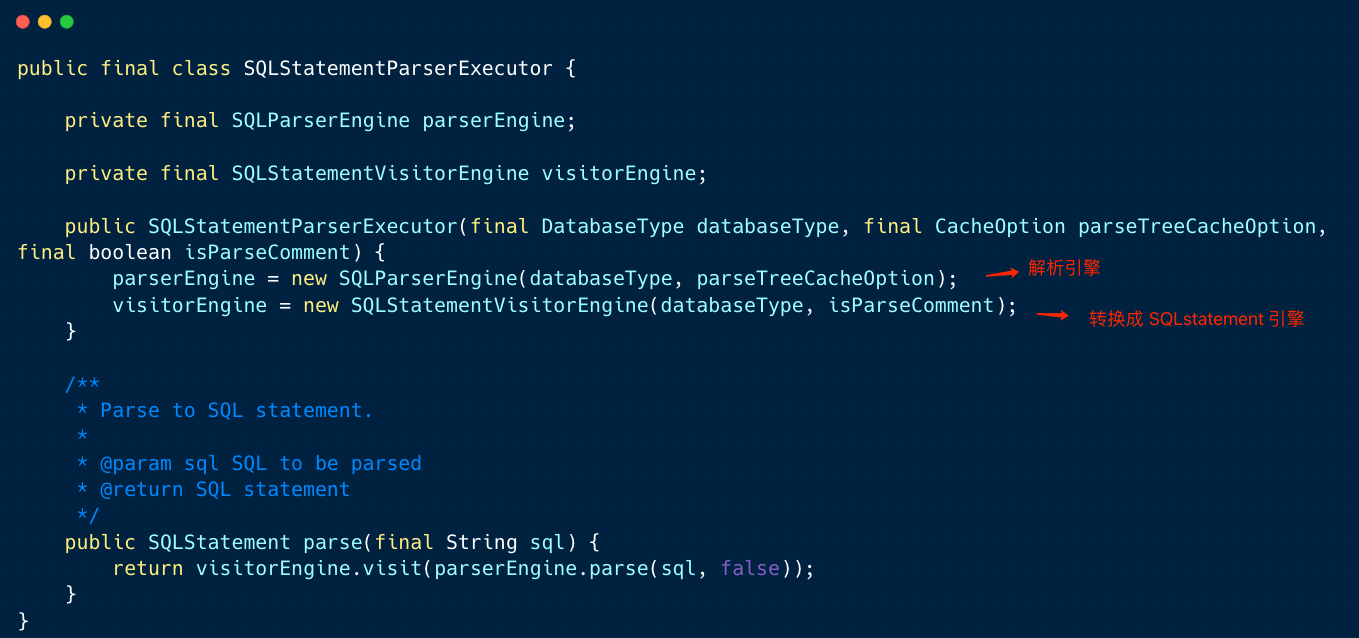
解析执行器内部创建了两个对象分别是:SQL 解析引擎和 SQL 访问引擎。
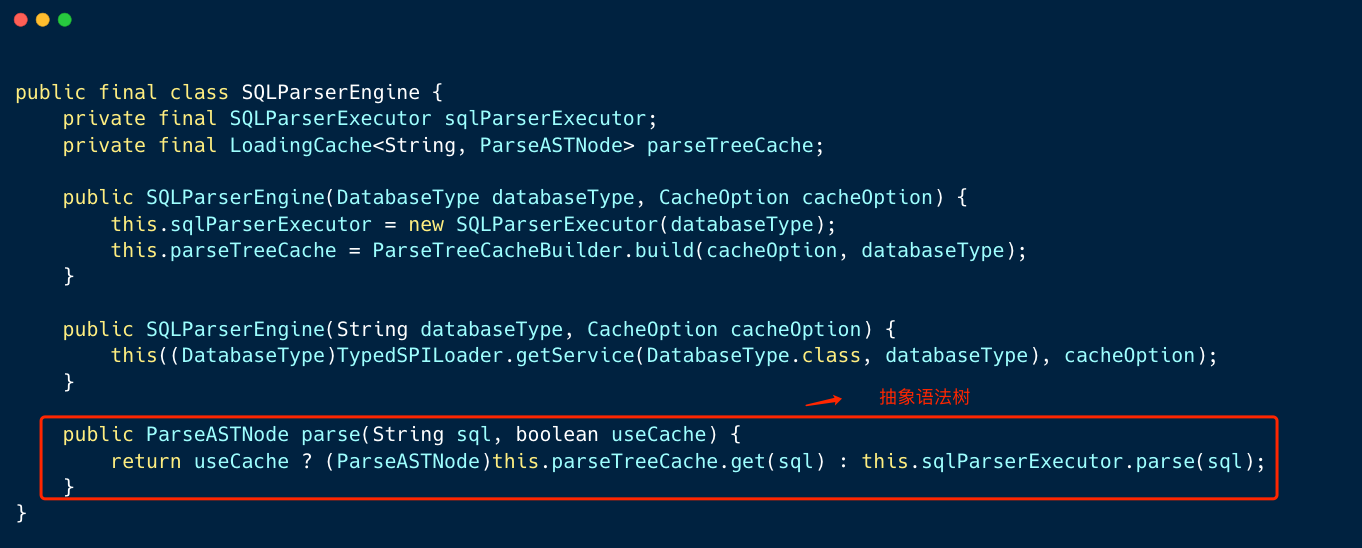
1、SQL 解析引擎负责将 SQL 转换成抽象语法树 AST
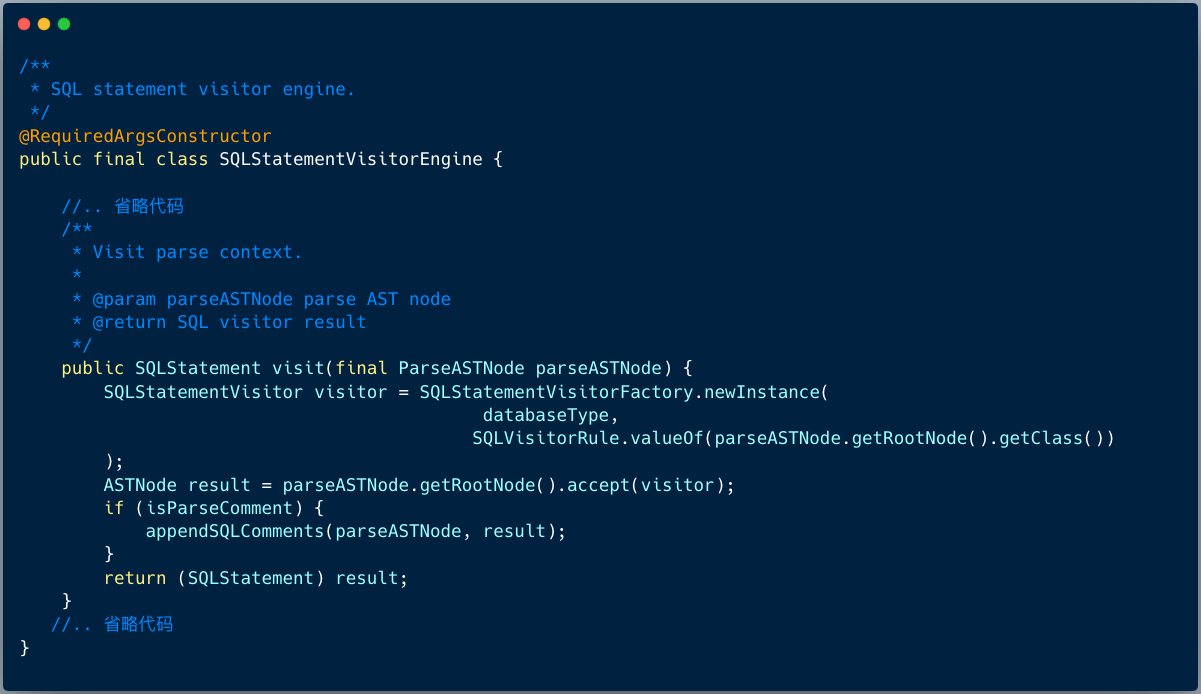
2、SQL 访问引擎负责将抽象语法树转换成域模型 SQLStatement
3. 核心源码
笔者将 SQL 解析流程做点简化,无非是如下的代码:
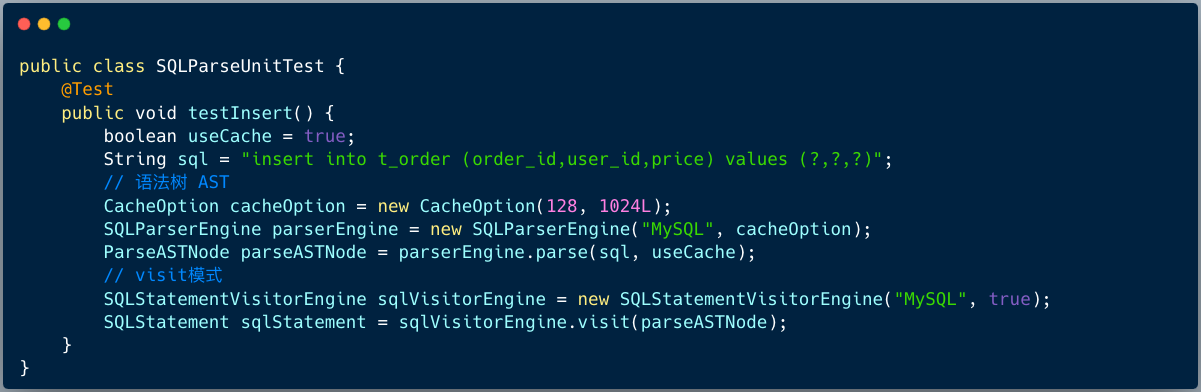
步骤一、生成语法树
Apache ShardingSphere 的 SQLParserEngine 是对 ANTLR4 解析的封装和抽象,它会通过 SPI 的方式来加载数据库方言的解析器,用户可以通过 SPI 扩展点对数据方言进行进一步扩展。另外内部还增加了缓存机制,用来提高性能。
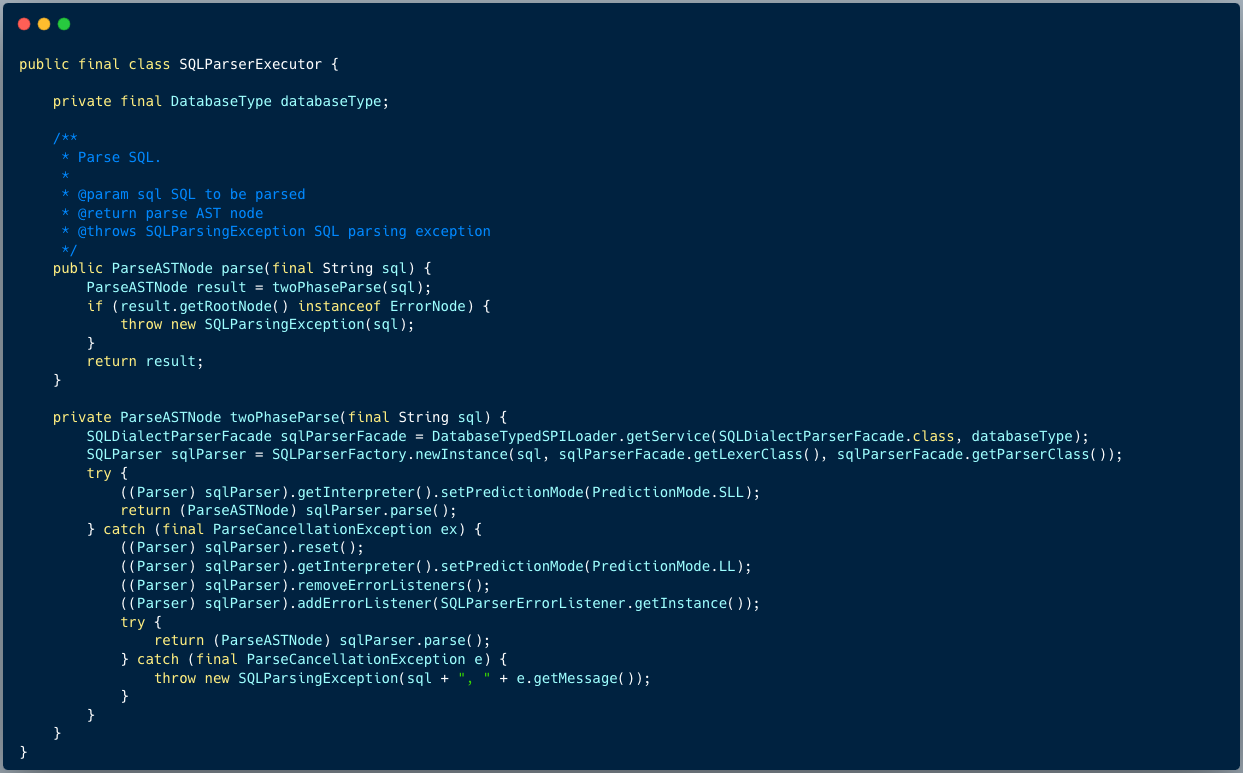
twoPhaseParse 是解析的核心,首先会根据数据库类型加载到对应解析类,接着通过反射机制,生成 ANTLR4 的解析器实例。
然后通过 ANTLR4 官方提供的两种解析方式,首先进行快速解析,快速解析失败,会进行常规解析,大部分 SQL 都能够通过快速解析得到结果从而提高解析性能。解析过后,我们便得到了解析树。
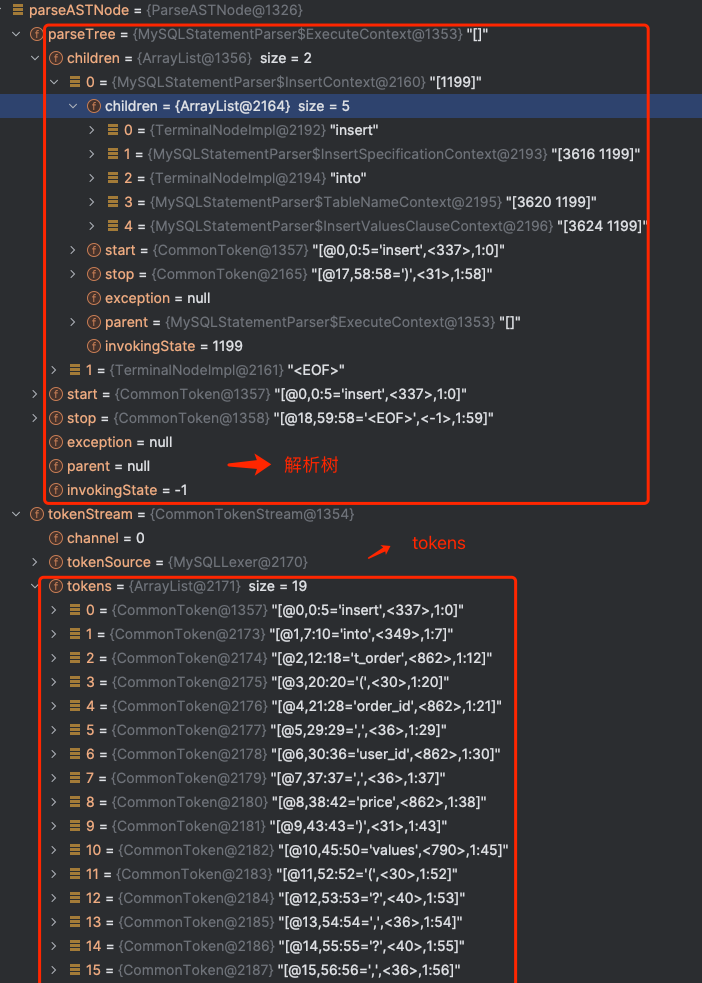
下图是调试抽象语法树对象 ParseASTNode :
接下来,我们通过 IDEA ANTLR4 插件查看 SQL 生成的语法树。
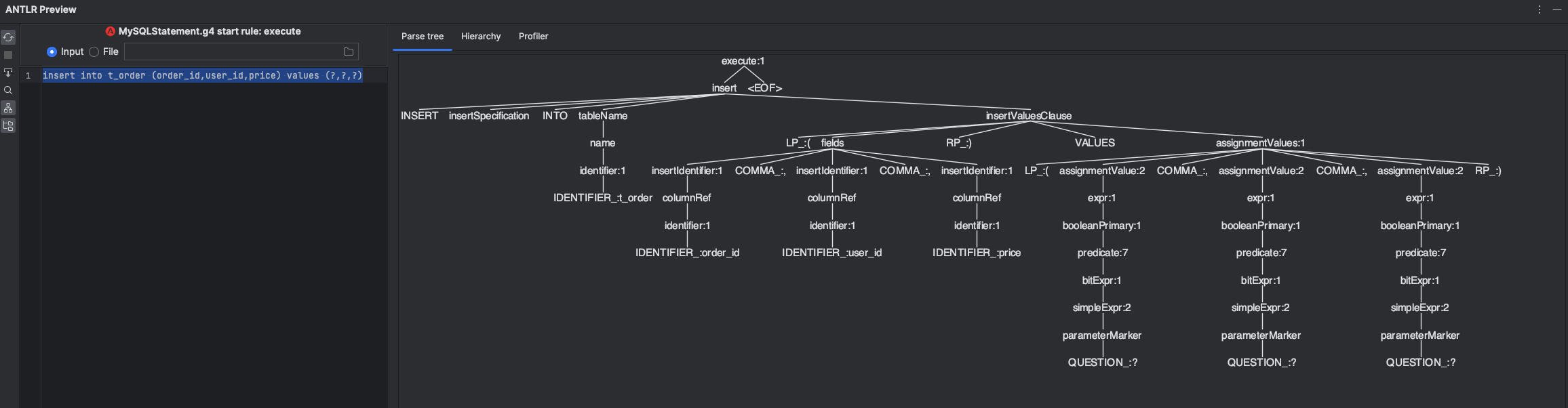
这两张图中,明显可以看到 Java 对象 parseTree 的子节点 和 ANTLR4 插件生成的语法树可以一一对应。
步骤二、生成域模型 SQLStatement

ANTLR4 提供了两种访问语法树的方式,包括 Listener 和 Visitor ,ShardingSphere 采用 Visitor 的方式来访问语法树。
参考文档:
https://shardingsphere.apache.org/document/5.4.1/cn/reference/sharding/parse/